Regime-Aware Peer Specialization for Robust RAG under Heterogeneous Knowledge Conflicts
Pith reviewed 2026-06-30 06:03 UTC · model grok-4.3
The pith
RAPS-DA disentangles learning signals for RAG conflicts by training regime-specific peer specialists and routing samples accordingly.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
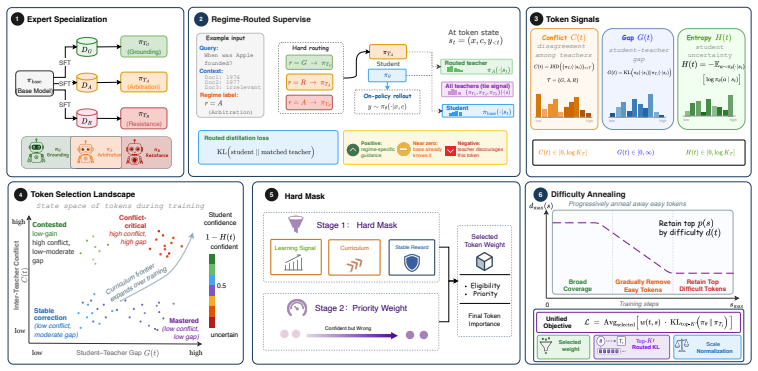
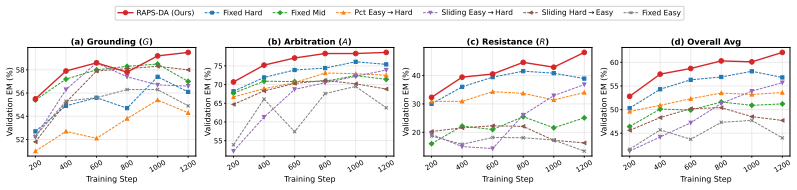
RAPS-DA divides knowledge conflicts into Grounding, Arbitration, and Resistance regimes, trains one same-scale peer specialist per regime, hard-routes samples to the regime-matched peer for on-policy reverse-KL supervision, and applies a dual-layer token selector based on inter-teacher disagreement, student-teacher divergence, and student entropy to filter and upweight tokens. This yields a student that surpasses prompting, decoding, fine-tuning, RL, and single-teacher baselines on five conflict scenarios and two out-of-distribution benchmarks, with gains from specialization rather than stronger teachers.
What carries the argument
The regime-aware peer specialization framework with hard-routing to three regime-matched peers and a dual-layer selector for token supervision.
If this is right
- Specialization at fixed model scale produces better robustness than single-teacher training.
- The deployed model needs no regime labels or access to peers.
- Token-level filtering gradually focuses on high-conflict tokens as training progresses.
- Performance gains hold on out-of-distribution benchmarks beyond the training conflict scenarios.
Where Pith is reading between the lines
- Similar regime partitioning could help in other areas where training signals vary in reliability, such as instruction tuning with noisy data.
- The approach might scale to more than three regimes if finer conflict distinctions prove useful.
- Since peers are discarded after training, the method could be combined with distillation techniques for even smaller final models.
Load-bearing premise
Conflicts can be accurately partitioned into the three regimes so that routing to matched peers creates disentangled beneficial signals instead of new inconsistencies.
What would settle it
Training a model with this regime-aware routing and finding it performs no better than a single-teacher baseline on the same conflict scenarios would falsify the benefit of the specialization.
Figures


read the original abstract
Retrieval-augmented generation (RAG) improves language models by grounding generation in external context. However, it can be fragile when the retrieved context conflicts with the model's parametric knowledge. Such conflicts span a reliability spectrum, ranging from reliable and partially reliable evidence to adversarial context. Existing remedies often handle such heterogeneous conflicts with regime-agnostic supervision, which can conflate incompatible learning signals across reliability regimes. To disentangle these signals, we propose RAPS-DA, a regime-aware peer specialization framework that addresses conflict at two complementary granularities. At the sample level, conflicts are divided into three regimes, including Grounding, Arbitration, and Resistance, with one same-scale peer specialist trained per regime from a shared base model. Each sample is then hard-routed to its regime-matched peer for on-policy reverse-KL supervision. At the token level, a dual-layer selector uses inter-teacher disagreement, student-teacher divergence, and student entropy to filter uninformative or unstable tokens, upweight confidently misaligned ones, and gradually focus supervision on high-conflict tokens as the student matures. Gains stem from specialization at a fixed model scale, not from a stronger teacher, and the peer specialists exist only during training, so the deployed student requires no regime labels or peer access. Experiments on five conflict scenarios and two out-of-distribution benchmarks show RAPS-DA surpasses all prompting, decoding, fine-tuning, RL, and single-teacher baselines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes RAPS-DA, a regime-aware peer specialization method for robust RAG under heterogeneous knowledge conflicts. Conflicts are partitioned into three regimes (Grounding, Arbitration, Resistance); one same-scale peer is trained per regime from a shared base; each sample is hard-routed to its matched peer for on-policy reverse-KL supervision. A dual-layer token selector filters tokens using inter-teacher disagreement, student-teacher divergence, and student entropy. The deployed model requires no regime labels or peers. Experiments on five conflict scenarios plus two OOD benchmarks claim superiority over prompting, decoding, fine-tuning, RL, and single-teacher baselines.
Significance. If the regime partitioning and hard-routing mechanism can be shown to produce net-positive disentangled signals rather than misrouting artifacts, the approach would offer a training-only specialization strategy that improves conflict robustness at fixed inference scale. The dual-layer selector and reverse-KL formulation are technically coherent extensions of existing distillation ideas, but their interaction with regime routing remains unverified.
major comments (3)
- [§3.2] §3.2 (Regime Definition and Classifier): The three regimes are defined and a classifier is introduced, yet no accuracy, precision-recall, or inter-regime overlap statistics are reported for the regime predictor on the training or validation splits. Without these numbers it is impossible to confirm that hard-routing actually delivers regime-matched supervision rather than noise.
- [§4.3] §4.3 and Table 3 (Ablation Studies): Performance tables show gains over baselines, but the manuscript contains no ablation that replaces regime-matched routing with random routing or a single shared peer while freezing the dual-layer token selector. Consequently the central claim that specialization (rather than the selector or other factors) drives the reported improvements cannot be isolated.
- [§5.1] §5.1 (Token Selector Interaction): The dual-layer selector is motivated by disagreement and entropy signals, yet no analysis quantifies how often the selector and regime router disagree on high-conflict tokens or whether selector up-weighting amplifies misrouted samples. This interaction is load-bearing for the “disentangled signals” argument.
minor comments (2)
- [§3.3] Notation for the reverse-KL objective and the dual-layer selector weights is introduced without an explicit equation reference in the main text; a numbered equation would improve traceability.
- [Figure 2] Figure 2 (regime distribution) lacks error bars or per-scenario breakdowns; adding these would clarify stability across the five conflict scenarios.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. The comments highlight important aspects of validating the regime routing and component interactions. We address each major comment below and will incorporate additional analyses and ablations in the revised manuscript.
read point-by-point responses
-
Referee: [§3.2] §3.2 (Regime Definition and Classifier): The three regimes are defined and a classifier is introduced, yet no accuracy, precision-recall, or inter-regime overlap statistics are reported for the regime predictor on the training or validation splits. Without these numbers it is impossible to confirm that hard-routing actually delivers regime-matched supervision rather than noise.
Authors: We agree that the regime classifier performance metrics are necessary to substantiate the hard-routing mechanism. The current manuscript does not report these statistics. In the revision we will add accuracy, precision-recall, and F1 scores together with a confusion matrix for the regime predictor evaluated on both the training and validation splits. revision: yes
-
Referee: [§4.3] §4.3 and Table 3 (Ablation Studies): Performance tables show gains over baselines, but the manuscript contains no ablation that replaces regime-matched routing with random routing or a single shared peer while freezing the dual-layer token selector. Consequently the central claim that specialization (rather than the selector or other factors) drives the reported improvements cannot be isolated.
Authors: This point is well taken; an explicit random-routing ablation with the selector held fixed would strengthen isolation of the specialization effect. While single-teacher baselines are present, we did not include the requested random-routing control. We will run and report this ablation in the revised version, comparing regime-matched routing against random peer assignment under identical selector conditions. revision: yes
-
Referee: [§5.1] §5.1 (Token Selector Interaction): The dual-layer selector is motivated by disagreement and entropy signals, yet no analysis quantifies how often the selector and regime router disagree on high-conflict tokens or whether selector up-weighting amplifies misrouted samples. This interaction is load-bearing for the “disentangled signals” argument.
Authors: We acknowledge the value of quantifying the selector-router interaction. The manuscript currently lacks this analysis. In the revision we will add measurements of disagreement frequency between the token selector and regime router on high-conflict tokens, as well as an examination of whether selector up-weighting influences any misrouted samples. revision: yes
Circularity Check
No circularity: procedural method with no self-referential derivations
full rationale
The provided abstract and description define RAPS-DA as a new training procedure involving regime partitioning (Grounding/Arbitration/Resistance), per-regime peer training, hard-routing for reverse-KL, and a dual-layer token selector based on disagreement/divergence/entropy. No equations, fitted parameters renamed as predictions, or self-citations invoking uniqueness theorems appear. The central claims rest on experimental comparisons to baselines rather than any reduction of outputs to inputs by construction. This matches the reader's note that no derivations are present and the procedure introduces new components without visible circular reduction. Per rules, absent any quotable self-definitional or fitted-input steps, the finding is no circularity.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
On-policy distillation of language models: Learning from self-generated mistakes
Rishabh Agarwal, Nino Vieillard, Piotr Stanczyk, Sabela Ramos, Matthieu Geist, and Olivier Bachem. On-policy distillation of language models: Learning from self-generated mistakes. InInt. Conf. Learn. Represent., 2024
2024
-
[2]
SCOPE: Signal-Calibrated On-Policy Distillation Enhancement with Dual-Path Adaptive Weighting
Anonymous. Scope: Correctness-based dual-path token weighting for on-policy distillation. arXiv preprint arXiv:2604.10688, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[3]
Anonymous. Srpo: Self-refined policy optimization via correctness-aware routing.arXiv preprint arXiv:2604.02288, 2026
-
[4]
TIP: Token Importance in On-Policy Distillation
Anonymous. Tip: Token importance profiling for efficient on-policy distillation.arXiv preprint arXiv:2604.14084, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[5]
Self-rag: Learning to retrieve, generate, and critique through self-reflection
Akari Asai, Zeqiu Wu, Yizhong Wang, Avi Sil, and Hannaneh Hajishirzi. Self-rag: Learning to retrieve, generate, and critique through self-reflection. InInt. Conf. Learn. Represent., 2024. 15
2024
-
[6]
Parameters vs
Baolong Bi, Shenghua Liu, Yiwei Wang, Yilong Xu, Junfeng Fang, Lingrui Mei, and Xueqi Cheng. Parameters vs. context: Fine-grained control of knowledge reliance in language mod- els, 2025
2025
-
[7]
Dola: Decoding by contrasting layers improves factuality in large language models
Yung-Sung Chuang, Yujia Xie, Hongyin Luo, Yoon Kim, James Glass, and Pengcheng He. Dola: Decoding by contrasting layers improves factuality in large language models. InInt. Conf. Learn. Represent., 2024
2024
-
[8]
Hanxing Ding, Liang Pang, Zihao Wei, Huawei Shen, and Xueqi Cheng. Retrieve only when it needs: Adaptive retrieval augmentation for hallucination mitigation in large language models. arXiv preprint arXiv:2402.10612, 2024
-
[9]
Enhancing noise robustness of retrieval-augmented language models via RAAT
Yucheng Fang, Ruochen Wang, Kun Qian, Yansong Feng, Diyi Yang, and He He. Enhancing noise robustness of retrieval-augmented language models via RAAT. InProc. Annu. Meet. Assoc. Comput Linguist., 2024
2024
-
[10]
Revisiting On-Policy Distillation: Empirical Failure Modes and Simple Fixes
Yao Fu et al. Revisiting on-policy distillation: Three failure modes and top-k truncated reverse- kl.arXiv preprint arXiv:2603.25562, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[11]
Minillm: Knowledge distillation of large language models
Yuxian Gu, Li Dong, Furu Wei, and Minlie Huang. Minillm: Knowledge distillation of large language models. InInt. Conf. Learn. Represent., 2024
2024
-
[12]
Deepseek-r1 incentivizes reasoning in LLMs through reinforcement learning.Nature, 645(8081):633–638, sep 2025
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, et al. Deepseek-r1 incentivizes reasoning in LLMs through reinforcement learning.Nature, 645(8081):633–638, sep 2025
2025
-
[13]
REALM: Retrieval-augmented language model pre-training
Kelvin Guu, Kenton Lee, Zora Tung, Panupong Pasupat, and Ming-Wei Chang. REALM: Retrieval-augmented language model pre-training. InProceedings of the 37th International Conference on Machine Learning (ICML), pages 3929–3938, 2020
2020
-
[14]
Retrieving, rethinking and revising: The chain-of-verification can improve retrieval augmented generation
Bolei He, Nuo Chen, Xinran He, Lingyong Yan, Zhenkai Wei, Jinchang Luo, and Zhen-Hua Ling. Retrieving, rethinking and revising: The chain-of-verification can improve retrieval augmented generation. InConf. Empir. Methods Nat. Lang. Process., pages 10371–10393, 2024
2024
-
[15]
Distilling the Knowledge in a Neural Network
Geoffrey Hinton, Oriol Vinyals, and Jeff Dean. Distilling the knowledge in a neural network. arXiv preprint arXiv:1503.02531, 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[16]
Search-R1: Training LLMs to Reason and Leverage Search Engines with Reinforcement Learning
Bowen Jin, Hansi Zeng, Zhenrui Yue, Jinsung Yoon, Sercan Arik, Dong Wang, Hamed Za- mani, and Jiawei Han. Search-r1: Training llms to reason and leverage search engines with reinforcement learning.arXiv preprint arXiv:2503.09516, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[17]
Tug-of-war between knowledge: Exploring and resolving knowledge conflicts in retrieval-augmented language models
Zhuoran Jin, Pengfei Cao, Yubo Chen, Kang Liu, Xiaojian Jiang, Jiexin Xu, Li Qiuxia, and Jun Zhao. Tug-of-war between knowledge: Exploring and resolving knowledge conflicts in retrieval-augmented language models. InInt. Conf. Comput. Linguist., Lang. Resour. Eval., pages 16867–16878, 2024
2024
-
[18]
Jongwoo Ko, Sungmin Park, and Joohyung Kim. Reopold: Reward-based on-policy distillation with mixture-based reward clipping.arXiv preprint arXiv:2603.11137, 2026
-
[19]
Retrieval-augmented generation for knowledge-intensive NLP tasks
Patrick Lewis, Ethan Perez, Aleksandara Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, Sebastian Riedel, and Douwe Kiela. Retrieval-augmented generation for knowledge-intensive NLP tasks. InAd- vances in Neural Information Processing Systems (NeurIPS), volume 33, pages 9459–9474, 2020
2020
-
[20]
Xiaoyu Li, Hao Zhang, and Zhiyuan Wang. Knowledge-aware fine-tuning for robust retrieval- augmented generation.arXiv preprint arXiv:2407.12854, 2024
-
[21]
Truthfulqa: Measuring how models mimic human falsehoods
Stephanie Lin, Jacob Hilton, and Owain Evans. Truthfulqa: Measuring how models mimic human falsehoods. InProceedings of the 60th Annual Meeting of the Association for Compu- tational Linguistics (ACL), pages 3214–3252, 2022. 16
2022
-
[22]
Zhen Lin, Yifei Wang, Hao Chen, and Zhiyuan Liu. Knowledgeable-r1: Reinforcement learn- ing for knowledge-conflict resolution in rag.arXiv preprint arXiv:2503.12345, 2025
-
[23]
Demystifying OPD: Length Inflation and Stabilization Strategies for Large Language Models
Haoran Luo et al. Stable on-policy distillation: Mitigating length inflation in llm training. arXiv preprint arXiv:2604.08527, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[24]
Privileged Information Distillation for Language Models
Emiliano Penaloza, Dheeraj Vattikonda, Nicolas Gontier, Alexandre Lacoste, Laurent Charlin, and Massimo Caccia. Privileged information distillation for language models.arXiv preprint arXiv:2602.04942, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[25]
Qwen2.5 technical report, 2025
Qwen, :, An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Haoran Wei, Huan Lin, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jingren Zhou, Junyang Lin, Kai Dang, Keming Lu, Keqin Bao, Kexin Yang, Le Yu, Mei Li, Mingfeng Xue, Pei Zhang, Qin Zhu, Rui Men, Runji Lin, Tianhao Li,...
2025
-
[26]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[27]
Trusting your evidence: Hallucinate less with context-aware decoding
Weijia Shi, Xiaochuang Han, Mike Lewis, Yulia Tsvetkov, Luke Zettlemoyer, and Scott Wen- tau Yih. Trusting your evidence: Hallucinate less with context-aware decoding. InProc. Conf. North American Chapter Assoc. Comput. Linguist., pages 783–800, 2024
2024
-
[28]
Conflictbank: a benchmark for evaluating knowledge conflicts in large language models
Zhaochen Su, Jun Zhang, Xiaoye Qu, Tong Zhu, Yanshu Li, Jiashuo Sun, Juntao Li, Min Zhang, and Yu Cheng. Conflictbank: a benchmark for evaluating knowledge conflicts in large language models. InAdv. Neural Inform. Process. Syst., pages 103242–103268, 2024
2024
-
[29]
Sainbayar Sukhbaatar, Naman Goyal, Gabriel Synnaeve, and Guillaume Lample. Branch- train-mix: Mixing expert llms into a mixture-of-experts llm.arXiv preprint arXiv:2403.07816, 2024
-
[30]
Knowledge fusion of large language models
Fanqi Wan, Xinting Huang, Deng Cai, Xiaojun Quan, Wei Bi, and Shuming Shi. Knowledge fusion of large language models. InInt. Conf. Learn. Represent., 2024
2024
-
[31]
Astute rag: Over- coming imperfect retrieval augmentation and knowledge conflicts for large language models
Fei Wang, Xingchen Wan, Ruoxi Sun, Jiefeng Chen, and Sercan Ö Arık. Astute rag: Over- coming imperfect retrieval augmentation and knowledge conflicts for large language models. Proc. Annu. Meet. Assoc. Comput Linguist., 2025
2025
-
[32]
Retrieval-augmented gen- eration with conflicting evidence
Han Wang, Archiki Prasad, Elias Stengel-Eskin, and Mohit Bansal. Retrieval-augmented gen- eration with conflicting evidence. InConference on Language Modeling, 2025
2025
-
[33]
Resolving knowledge conflicts in large language models.Conference on Language Modeling, 2024
Yike Wang, Shangbin Feng, Heng Wang, Weijia Shi, Vidhisha Balachandran, Tianxing He, and Yulia Tsvetkov. Resolving knowledge conflicts in large language models.Conference on Language Modeling, 2024
2024
-
[34]
Chengyue Wu et al. Lightning on-policy distillation: Teacher consistency is all you need. arXiv preprint arXiv:2604.13010, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[35]
Adaptive chameleon or stubborn sloth: Revealing the behavior of large language models in knowledge conflicts
Jian Xie, Kai Zhang, Jiangjie Chen, Renze Lou, and Yu Su. Adaptive chameleon or stubborn sloth: Revealing the behavior of large language models in knowledge conflicts. InInt. Conf. Learn. Represent., 2024
2024
-
[36]
Chenliang Xu, Jiaxin Guo, Yiwei Wang, and Shenghua Liu. Info-rag: Information-filtered on-policy retrieval-augmented generation.arXiv preprint arXiv:2406.19009, 2024
-
[37]
Knowledge conflicts for llms: A survey
Rongwu Xu, Zehan Qi, Zhijiang Guo, Cunxiang Wang, Hongru Wang, Yue Zhang, and Wei Xu. Knowledge conflicts for llms: A survey. InConf. Empir. Methods Nat. Lang. Process., pages 8541–8565, 2024
2024
-
[38]
Learning beyond Teacher: Generalized On-Policy Distillation with Reward Extrapolation
Zichun Yang et al. G-opd: Generalized on-policy distillation as dense kl-constrained reinforce- ment learning.arXiv preprint arXiv:2602.12125, 2026. 17
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[39]
On-Policy Context Distillation for Language Models
Tianzhu Ye, Li Dong, Xun Wu, Shaohan Huang, and Furu Wei. On-policy context distillation for language models.arXiv preprint arXiv:2602.12275, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[40]
Confidence-aware multi-teacher knowledge dis- tillation.arXiv preprint arXiv:2201.00007, 2022
Hailin Zhang, Defang Chen, and Can Wang. Confidence-aware multi-teacher knowledge dis- tillation.arXiv preprint arXiv:2201.00007, 2022
-
[41]
Xueying Zhang, Yanqiu Chen, and Yongkang Li. Dynamic contrastive decoding for knowledge conflict resolution in large language models.arXiv preprint arXiv:2405.13183, 2024. 18
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.