Recognition: unknown
SCOPE: Signal-Calibrated On-Policy Distillation Enhancement with Dual-Path Adaptive Weighting
Pith reviewed 2026-05-10 15:17 UTC · model grok-4.3
The pith
SCOPE improves on-policy distillation for LLM reasoning by routing supervision into correctness-based dual paths with perplexity-weighted adjustments.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper claims that routing on-policy rollouts into two paths according to correctness, then weighting the KL distillation loss by teacher perplexity on incorrect trajectories and the MLE loss by student perplexity on correct trajectories, with group-level normalization to account for prompt difficulty variance, produces more effective token-level supervision than uniform application and yields consistent performance lifts on reasoning tasks.
What carries the argument
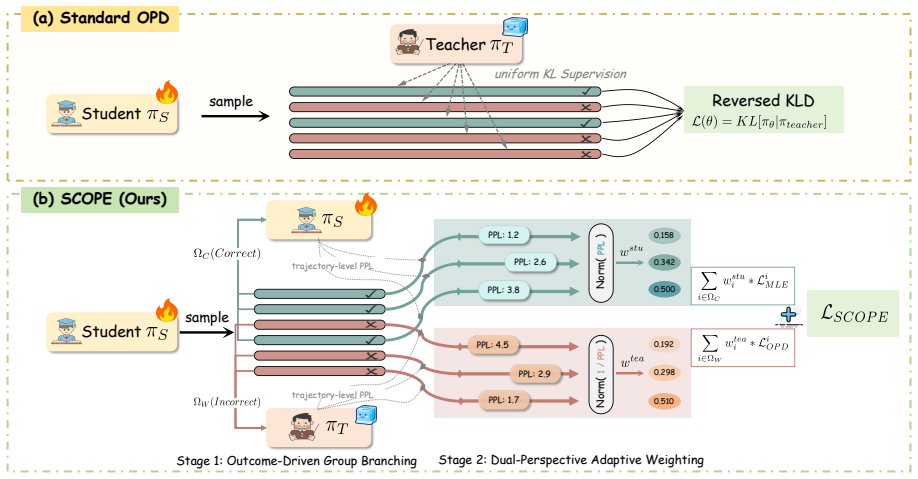
Dual-path adaptive weighting that separates teacher-perplexity-weighted KL distillation for incorrect trajectories from student-perplexity-weighted MLE for correct trajectories, both calibrated by group-level normalization.
If this is right
- More effective token-level credit assignment within on-policy reinforcement learning for language model reasoning.
- Prioritization of high-quality corrective signals from the teacher on flawed trajectories.
- Focused reinforcement on low-confidence yet correct samples near the model's capability boundary.
- Adaptive weight calibration that accounts for intrinsic difficulty differences across prompts.
- Consistent outperformance over uniform distillation baselines on multiple reasoning benchmarks.
Where Pith is reading between the lines
- The separation of supervision by trajectory outcome could be tested in other distillation or preference-tuning pipelines where signal reliability varies.
- Perplexity-based weighting may interact with scaling behaviors, suggesting experiments that vary model size while holding the dual-path structure fixed.
- Group normalization might generalize to other grouping strategies such as difficulty estimation from prompt embeddings.
- The approach implies that outcome correctness can serve as a cheap auxiliary signal to improve efficiency in alignment training without extra human labels.
Load-bearing premise
Perplexity of the teacher on incorrect trajectories and of the student on correct trajectories serve as reliable proxies for signal quality without introducing selection biases.
What would settle it
An ablation experiment that disables the dual-path routing and perplexity weighting, replacing them with uniform KL or MLE supervision across all rollouts, and measures whether the reported gains on the six reasoning benchmarks disappear.
Figures



read the original abstract
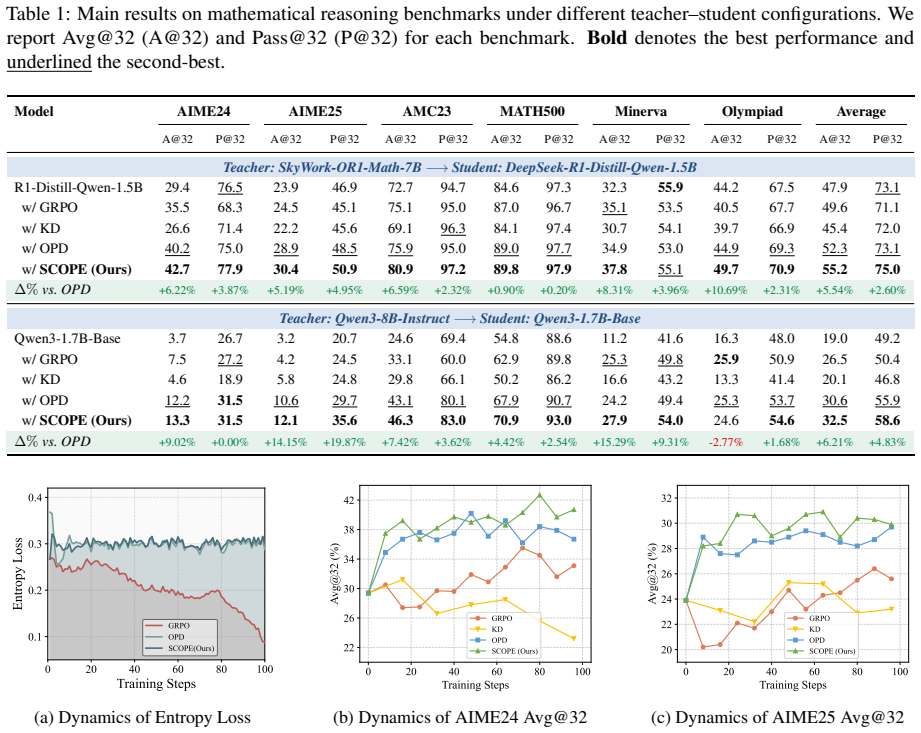
On-policy reinforcement learning has become the dominant paradigm for reasoning alignment in large language models, yet its sparse, outcome-level rewards make token-level credit assignment notoriously difficult. On-Policy Distillation (OPD) alleviates this by introducing dense, token-level KL supervision from a teacher model, but typically applies this supervision uniformly across all rollouts, ignoring fundamental differences in signal quality. We propose Signal-Calibrated On-Policy Distillation Enhancement (SCOPE), a dual-path adaptive training framework that routes on-policy rollouts by correctness into two complementary supervision paths. For incorrect trajectories, SCOPE performs teacher-perplexity-weighted KL distillation to prioritize instances where the teacher demonstrates genuine corrective capability, while down-weighting unreliable guidance. For correct trajectories, it applies student-perplexity-weighted MLE to concentrate reinforcement on low-confidence samples at the capability boundary rather than over-reinforcing already mastered ones. Both paths employ a group-level normalization to adaptively calibrate weight distributions, accounting for the intrinsic difficulty variance across prompts. Extensive experiments on six reasoning benchmarks show that SCOPE achieves an average relative improvement of 11.42% in Avg@32 and 7.30% in Pass@32 over competitive baselines, demonstrating its consistent effectiveness.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes SCOPE, a dual-path adaptive training framework for on-policy distillation in LLMs to improve reasoning alignment. It routes incorrect on-policy rollouts to teacher-perplexity-weighted KL distillation (to prioritize corrective capability) and correct rollouts to student-perplexity-weighted MLE (to focus on capability boundaries), applying group-level normalization in both paths to account for prompt difficulty variance. Experiments on six reasoning benchmarks report average relative improvements of 11.42% in Avg@32 and 7.30% in Pass@32 over competitive baselines.
Significance. If the empirical gains prove robust and attributable to the proposed signal calibration rather than incidental factors, SCOPE offers a practical advance in addressing sparse outcome-level rewards and uniform supervision in on-policy RL for LLMs. The dual-path routing with perplexity-based adaptive weighting is a targeted engineering idea that could enhance token-level credit assignment efficiency, but its broader significance depends on validation that the proxies isolate genuine signal quality without introducing selection biases.
major comments (3)
- [§3] §3 (Method): The central claim that routing by teacher perplexity on incorrect trajectories and student perplexity on correct trajectories 'calibrates supervision to higher-quality signals' lacks supporting analysis. Perplexity measures average log-probability on a fixed sequence but does not quantify corrective capability or proximity to decision boundaries; no correlation studies, counterfactual weightings, or ablations isolating the proxy from the path split are referenced.
- [§4] §4 (Experiments): The reported improvements (11.42% Avg@32, 7.30% Pass@32) are presented without sufficient protocol details, including baseline definitions, statistical significance tests, number of seeds/runs, or ablation tables isolating the dual-path weighting, group normalization, and perplexity proxies from simpler alternatives such as uniform KL or single-path variants.
- [§4.3] §4.3 or ablation subsection: Without explicit ablations or sensitivity analysis on the weighting scheme, it remains possible that gains arise from the path split or implicit regularization rather than the claimed signal-quality calibration, undermining the load-bearing assumption in the abstract.
minor comments (2)
- Clarify the exact mathematical formulation of the group-level normalization and the adaptive weight computation (including any temperature or scaling hyperparameters) to aid reproducibility.
- List all six benchmarks, model sizes, and exact baseline methods explicitly in the experimental setup section rather than referring to 'competitive baselines.'
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment point-by-point below, committing to revisions where the concerns are valid and providing clarifications on the design rationale. All changes will be incorporated in the revised version.
read point-by-point responses
-
Referee: [§3] §3 (Method): The central claim that routing by teacher perplexity on incorrect trajectories and student perplexity on correct trajectories 'calibrates supervision to higher-quality signals' lacks supporting analysis. Perplexity measures average log-probability on a fixed sequence but does not quantify corrective capability or proximity to decision boundaries; no correlation studies, counterfactual weightings, or ablations isolating the proxy from the path split are referenced.
Authors: We appreciate this critique. The design rationale is that teacher perplexity on incorrect rollouts serves as a proxy for the reliability of corrective guidance (lower perplexity implying the teacher assigns higher probability to the correct continuation), while student perplexity on correct rollouts identifies boundary cases for reinforcement. However, we acknowledge that the current manuscript does not include explicit correlation analyses, counterfactual experiments, or ablations that isolate the perplexity proxy from the correctness-based path split. In the revision, we will add these elements to §3, including plots correlating perplexity with downstream gains and ablations replacing perplexity with uniform or alternative proxies. revision: yes
-
Referee: [§4] §4 (Experiments): The reported improvements (11.42% Avg@32, 7.30% Pass@32) are presented without sufficient protocol details, including baseline definitions, statistical significance tests, number of seeds/runs, or ablation tables isolating the dual-path weighting, group normalization, and perplexity proxies from simpler alternatives such as uniform KL or single-path variants.
Authors: We agree that additional protocol details are required for full reproducibility and to strengthen the empirical claims. The current version reports aggregate relative gains but omits explicit baseline hyperparameter tables, seed counts, variance estimates, and significance testing. In the revised §4, we will expand the experimental setup to specify all baseline configurations, report results over multiple random seeds (with standard deviations), include statistical significance tests, and provide comprehensive ablation tables comparing the full SCOPE framework against uniform KL, single-path, and non-normalized variants. revision: yes
-
Referee: [§4.3] §4.3 or ablation subsection: Without explicit ablations or sensitivity analysis on the weighting scheme, it remains possible that gains arise from the path split or implicit regularization rather than the claimed signal-quality calibration, undermining the load-bearing assumption in the abstract.
Authors: This is a fair point regarding attribution. The manuscript presents the dual-path design with perplexity weighting and group normalization as the core contribution but does not contain dedicated sensitivity analyses or ablations that rule out contributions from the mere act of path splitting or regularization effects. We will revise the ablation subsection (expanding §4.3) to include new experiments: (i) variants with uniform weighting within paths, (ii) single-path baselines, (iii) alternative weighting schemes (e.g., based on rollout length or reward magnitude), and (iv) sensitivity sweeps over the group normalization parameters, to isolate the effect of the proposed signal calibration. revision: yes
Circularity Check
No significant circularity; empirical engineering contribution with independent experimental validation
full rationale
The paper presents SCOPE as a procedural dual-path framework that routes rollouts by correctness and applies perplexity-based weighting for KL and MLE losses plus group normalization. No equations, derivations, or first-principles claims appear in the provided text that reduce any result to its inputs by construction. Perplexity proxies are defined as direct computations on trajectories and used as weighting factors without self-referential fitting or renaming of known results. No self-citation chains, uniqueness theorems, or ansatzes are invoked as load-bearing. The reported gains (11.42% Avg@32, 7.30% Pass@32) are positioned as outcomes of benchmark experiments rather than tautological predictions, rendering the method self-contained against external evaluation.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 3 Pith papers
-
Rubric-based On-policy Distillation
Rubric-based on-policy distillation allows training student models using only teacher responses by generating scoring rubrics from contrasts and using them for on-policy optimization, achieving superior performance an...
-
SOD: Step-wise On-policy Distillation for Small Language Model Agents
SOD reweights on-policy distillation strength step-by-step using divergence to stabilize tool use in small language model agents, yielding up to 20.86% gains and 26.13% on AIME 2025 for a 0.6B model.
-
UniSD: Towards a Unified Self-Distillation Framework for Large Language Models
UniSD unifies complementary self-distillation mechanisms for autoregressive LLMs and achieves up to +5.4 point gains over base models and +2.8 over baselines across six benchmarks and six models.
Reference graph
Works this paper leans on
-
[1]
Process Reinforcement through Implicit Rewards
Reward hacking mitigation using verifiable composite rewards. InProceedings of the 16th ACM International Conference on Bioinformatics, Com- putational Biology, and Health Informatics, pages 1–6. Ganqu Cui, Lifan Yuan, Zefan Wang, Hanbin Wang, Yuchen Zhang, Jiacheng Chen, Wendi Li, Bingxiang He, Yuchen Fan, Tianyu Yu, and 1 others. 2025. Pro- cess reinfor...
work page internal anchor Pith review arXiv 2025
-
[2]
Agentic entropy-balanced policy optimization.arXiv preprint arXiv:2510.14545,
Agentic entropy-balanced policy optimization. arXiv preprint arXiv:2510.14545. Xiaoliang Fu, Jiaye Lin, Yangyi Fang, Binbin Zheng, Chaowen Hu, Zekai Shao, Cong Qin, Lu Pan, Ke Zeng, and Xunliang Cai. 2026a. Maspo: Unifying gradient utilization, probability mass, and signal reli- ability for robust and sample-efficient llm reasoning. arXiv preprint arXiv:2...
-
[3]
Beyond pass@ 1: Self-play with variational problem synthesis sustains rlvr.arXiv preprint arXiv:2508.14029. Hunter Lightman, Vineet Kosaraju, Yuri Burda, Harri- son Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, and Karl Cobbe
-
[4]
Let’s verify step by step. InThe twelfth inter- national conference on learning representations. Kevin Lu and Thinking Machines Lab. 2025. On- policy distillation.Thinking Machines Lab: Con- nectionism. Https://thinkingmachines.ai/blog/on- policy-distillation. MAA. 2023. American mathematics competitions - amc. Accessed: 2023. MAA. 2024. American invitati...
-
[5]
Qwen3 technical report.arXiv preprint arXiv:2505.09388. Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xiaochen Zuo, Yu Yue, Weinan Dai, Tiantian Fan, Gaohong Liu, Lingjun Liu, and 1 others. 2025. Dapo: An open-source llm reinforcement learning system at scale.arXiv preprint arXiv:2503.14476. Xiaoyang Yuan, Yujuan Ding, Yi Bin, Wenqi Shao, Jinyu Cai, Ji...
work page internal anchor Pith review Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.