Self-GC: Self-Governing Context for Long-Horizon LLM Agents
Pith reviewed 2026-07-02 12:47 UTC · model grok-4.3
The pith
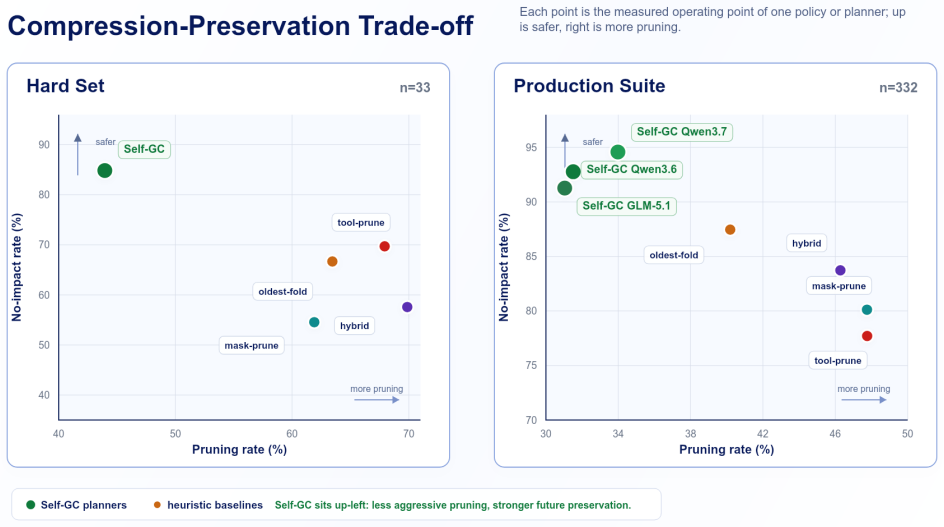
Self-GC indexes agent context as recoverable objects and uses a planner to prune 43.95% of prefix tokens while keeping 84.85% of future continuations unaffected.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
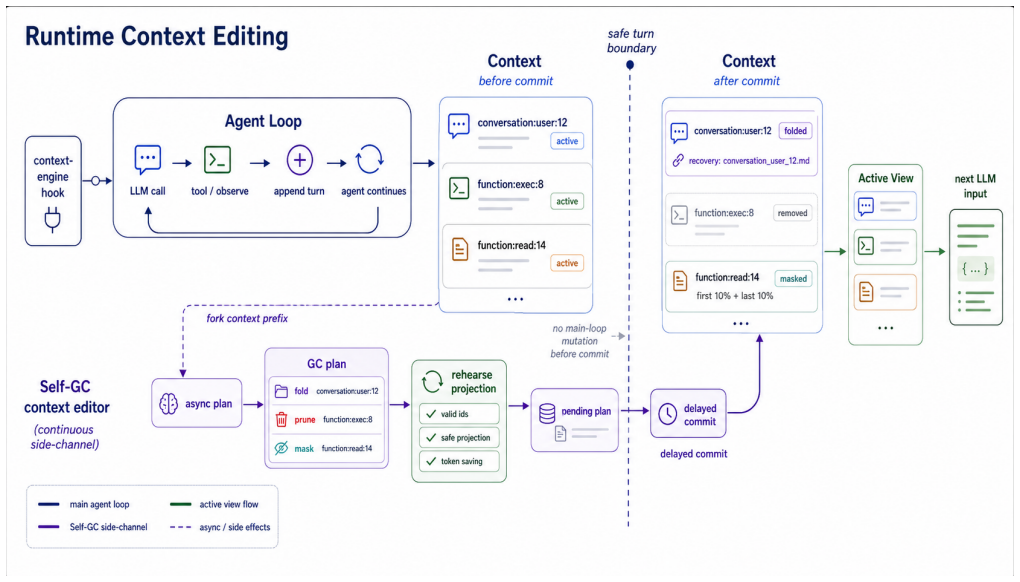
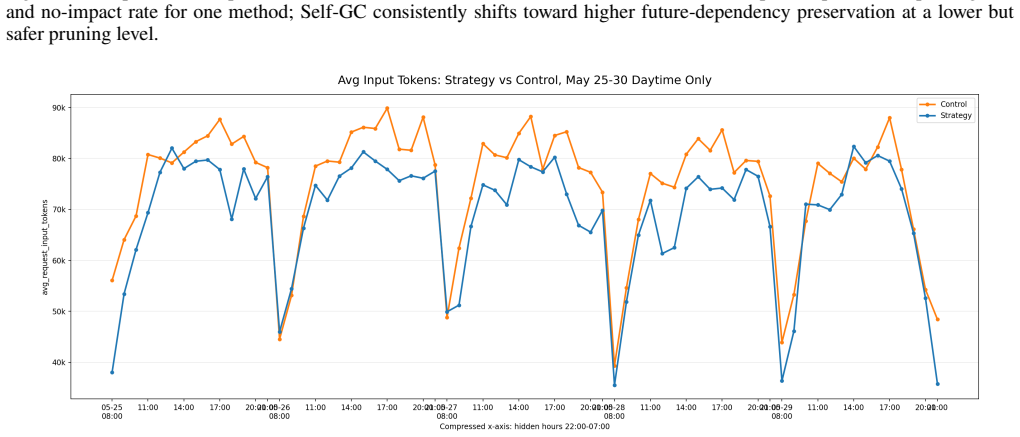
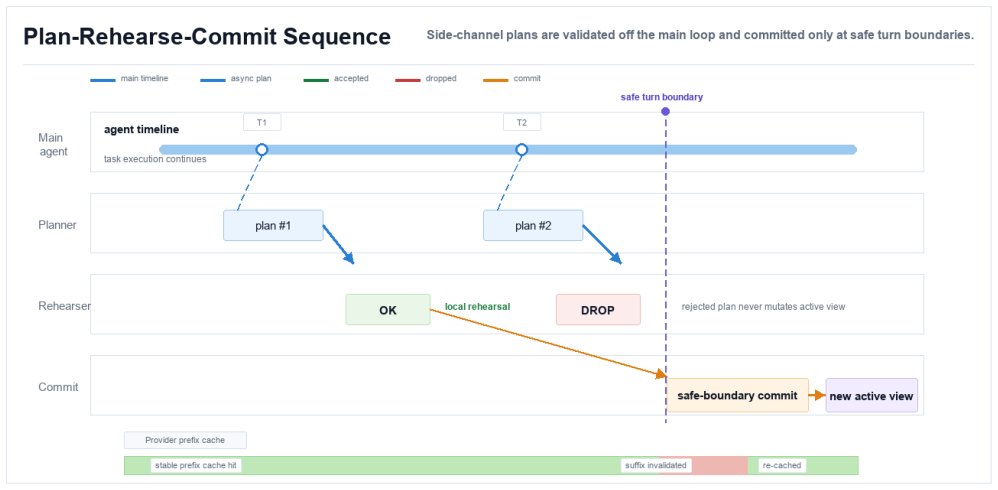
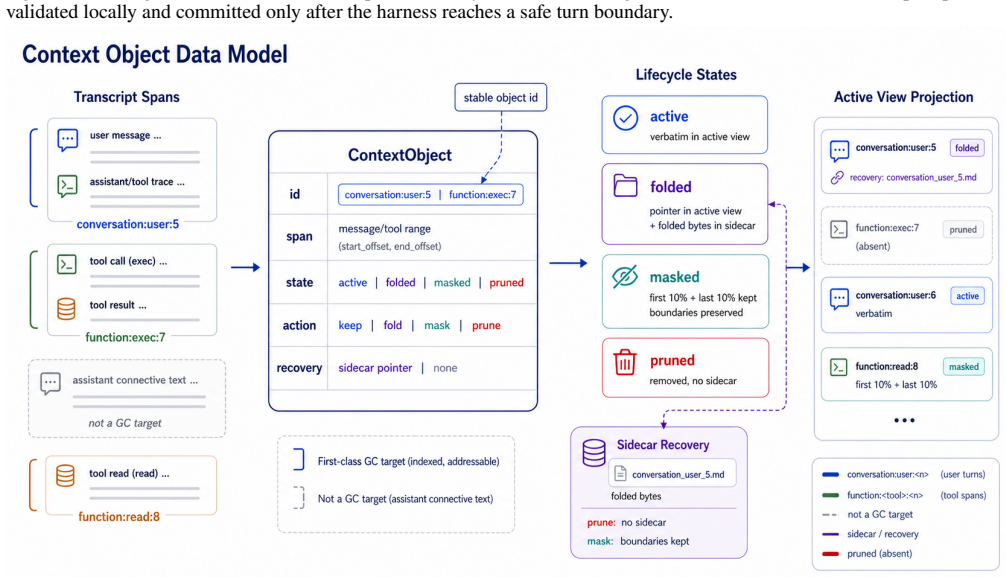
Self-GC turns user turns, tool spans, and skill state into indexed objects; asks a side-channel planner to propose fold, mask, and prune actions; and lets the harness enforce recoverable sidecars, safe commit boundaries, and cache-aware commit. On the 33-session Hard Set this prunes 43.95% of prefix tokens while leaving 84.85% of future continuations unaffected, outperforming heuristic baselines whose no-impact rates range from 54.55% to 69.70%. On the 332-session production-derived suite the three planner backbones reach no-impact rates of 91.27% to 94.58% while baselines stay at 77.71% to 87.46%. In production an online account-level split reduces daytime average input tokens by 10% to 15%
What carries the argument
Side-channel planner that proposes fold, mask, and prune actions on indexed context objects, with harness enforcement of recoverability and commit safety.
If this is right
- Agents can run longer sessions before hitting context limits because prefix tokens are reduced without breaking most continuations.
- Production deployments see consistent 10-15% lower average input token counts during daytime operation.
- Planner-based decisions outperform chronological pruning and tool-output masking on both hard and production-derived session sets.
- Context objects remain recoverable through sidecars, allowing later restoration if a prune proves too aggressive.
Where Pith is reading between the lines
- The same object-indexing approach could be applied to multi-agent systems where one agent's pruned context must stay legible to others.
- If the planner backbone improves, the method might support even longer horizons by combining pruning with selective summarization of non-critical spans.
- Production token savings suggest the technique could be inserted into existing agent runtimes with only modest changes to the harness layer.
Load-bearing premise
That an unaffected future continuation reliably shows all critical context information for task completion has been retained.
What would settle it
Run the 33-session hard set with human annotations of every essential locator, evidence item, and constraint; measure whether Self-GC prunes any annotated item at a materially higher rate than the baselines while still reporting the 84.85% no-impact figure.
Figures


read the original abstract
Long-horizon LLM agents accumulate tool results, files, plans, and user constraints that are too structured to be treated as a disposable text suffix. Current systems mostly rely on in-run heuristics such as chronological pruning and tool-output masking, or on final self-summary near a context limit. Heuristics are cheap but blind to future dependencies; summaries preserve narrative state but often hide exact evidence, locators, and editable artifacts. We present Self-GC, where GC denotes self-governing context while deliberately echoing garbage collection: the system does not merely reclaim unused tokens, but governs the lifecycle of agent context objects. Self-GC turns user turns, tool spans, and skill state into indexed objects; asks a side-channel planner to propose fold, mask, and prune actions; and lets the harness enforce recoverable sidecars, safe commit boundaries, and cache-aware commit. On a 33-session Hard Set, Self-GC prunes 43.95% of prefix tokens while leaving 84.85% of future continuations unaffected, compared with no-impact rates of 54.55% to 69.70% for heuristic baselines. On a 332-session production-derived suite, three planner backbones reach no-impact rates of 91.27% to 94.58%, while baselines remain at 77.71% to 87.46%. In production, an online account-level split reduces daytime average input tokens by 10% to 15%, with peak reductions near 20%. These results point to context management as runtime lifecycle control over indexed, recoverable objects rather than post hoc text cleanup.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Self-GC, a context management framework for long-horizon LLM agents that models user turns, tool spans, and skill state as indexed objects. A side-channel planner proposes fold, mask, and prune actions, which a harness enforces via recoverable sidecars, safe commit boundaries, and cache-aware commits. On a 33-session Hard Set the system prunes 43.95% of prefix tokens while leaving 84.85% of future continuations unaffected (versus 54.55–69.70% for heuristic baselines); on a 332-session production-derived suite three planner backbones reach 91.27–94.58% no-impact rates (baselines 77.71–87.46%); production deployment yields 10–15% average daytime token reduction.
Significance. If the no-impact metric reliably indicates preservation of task-critical information, the work offers a structured alternative to heuristic pruning or late-stage summarization and demonstrates measurable efficiency gains both in controlled suites and live production. The emphasis on recoverable objects and planner-driven lifecycle control is a concrete step beyond post-hoc text cleanup.
major comments (2)
- [§4] §4 (Evaluation): the definition and computation of the 'future continuations unaffected' (no-impact) metric are not provided. The manuscript must specify (a) the exact procedure for generating and comparing continuations, (b) how the 33 Hard Set sessions were selected, and (c) any controls or ablations for delayed dependencies or task-success correlation; without these the 84.85% figure cannot be assessed as evidence that critical context is preserved.
- [§3.2] §3.2 (Planner and Harness): the side-channel planner and recoverable-sidecar mechanisms are central to the claimed advantage over heuristics, yet no ablation isolates their contribution from the underlying LLM backbone or from the commit-boundary logic. A controlled removal of either component on the Hard Set would be required to substantiate that the reported deltas are attributable to the proposed architecture rather than to planner quality alone.
minor comments (2)
- [§1] The abstract and §1 use 'GC' to echo garbage collection; a brief sentence clarifying the analogy (and its limits) would aid readers unfamiliar with the metaphor.
- Table captions and axis labels for the production token-reduction results should explicitly state the time window and account-level split used.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the evaluation metric and the need for component ablations. We address each major comment below and will revise the manuscript to incorporate the requested clarifications and experiments.
read point-by-point responses
-
Referee: [§4] §4 (Evaluation): the definition and computation of the 'future continuations unaffected' (no-impact) metric are not provided. The manuscript must specify (a) the exact procedure for generating and comparing continuations, (b) how the 33 Hard Set sessions were selected, and (c) any controls or ablations for delayed dependencies or task-success correlation; without these the 84.85% figure cannot be assessed as evidence that critical context is preserved.
Authors: We agree that the no-impact metric requires a precise, reproducible definition to support the reported 84.85% figure. The manuscript currently states the outcome but omits the procedural details. In the revised §4 we will add: (a) the exact procedure, consisting of replaying each Hard Set session from the pruned context, generating the next agent continuation with the same backbone, and scoring it as unaffected if it matches the original continuation on task-critical elements (via both automated embedding similarity above a threshold and manual review for dependency preservation); (b) the selection process for the 33 sessions, drawn from production logs as the longest-horizon traces containing at least three cross-turn dependencies; (c) controls consisting of explicit checks that no pruned object is referenced in the subsequent 10 turns and a correlation analysis between no-impact rate and end-to-end task success. These additions will be included in the next version. revision: yes
-
Referee: [§3.2] §3.2 (Planner and Harness): the side-channel planner and recoverable-sidecar mechanisms are central to the claimed advantage over heuristics, yet no ablation isolates their contribution from the underlying LLM backbone or from the commit-boundary logic. A controlled removal of either component on the Hard Set would be required to substantiate that the reported deltas are attributable to the proposed architecture rather than to planner quality alone.
Authors: We acknowledge that the current results compare different planner backbones but do not isolate the side-channel planner or the recoverable-sidecar enforcement from the commit-boundary logic. In the revised manuscript we will add a controlled ablation on the Hard Set that (i) disables the planner entirely and falls back to the strongest heuristic baseline, and (ii) retains the planner but removes recoverable sidecars (forcing immediate non-recoverable commits). The resulting no-impact and token-reduction deltas will be reported to quantify the incremental contribution of each mechanism. revision: yes
Circularity Check
No circularity: purely empirical system evaluation
full rationale
The manuscript describes an agent context-management system (Self-GC) and evaluates it via direct measurements on two fixed test collections (33-session Hard Set, 332-session production suite). Reported figures are pruning percentages and continuation-impact rates obtained by running the system and baselines on those sets; no equations, fitted parameters, or first-principles derivations are present that could reduce to their own inputs. Self-citations, if any, are not load-bearing for any claimed derivation. The evaluation is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption It is possible to represent agent context elements as indexed objects that can be independently acted upon without breaking dependencies.
invented entities (2)
-
side-channel planner
no independent evidence
-
recoverable sidecars
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Xu, Bo and Zhang, Danny and Arunachalam, Rohit , year =
-
[2]
Cassano, Federico and Rush, Sasha , year =
-
[5]
Ye, Rui and Zhang, Zhongwang and Li, Kuan and Yin, Huifeng and Tao, Zhengwei and Zhao, Yida and Su, Liangcai and Zhang, Liwen and Qiao, Zile and Wang, Xinyu and Xie, Pengjun and Huang, Fei and Zhou, Jingren and Chen, Siheng and Jiang, Yong , year =
-
[7]
and Xu, Ruifeng and Wong, Kam-Fai , year=
Du, Yiming and Wang, Bingbing and He, Yang and Liang, Bin and Wang, Baojun and Li, Zhongyang and Gui, Lin and Pan, Jeff Z. and Xu, Ruifeng and Wong, Kam-Fai , year=. MemGuide: Intent-Driven Memory Selection for Goal-Oriented Multi-Session LLM Agents , volume=. Proceedings of the AAAI Conference on Artificial Intelligence , publisher=. doi:10.1609/aaai.v40...
-
[8]
ARTEM: Enhancing Large Language Model Agents with Spatial-Temporal Episodic Memory , volume=
Tan, Cassandra Hui-Ming and Subagdja, Budhitama and Tan, Ah-Hwee , year=. ARTEM: Enhancing Large Language Model Agents with Spatial-Temporal Episodic Memory , volume=. Proceedings of the AAAI Conference on Artificial Intelligence , publisher=. doi:10.1609/aaai.v40i30.39773 , number=
-
[9]
Dai, Renke and Hu, Hebin and Zhang, Jiahui and Kang, Yilin and Tan, Ah-Hwee , year=. MemoryART: Enhancing LLMs via Multi-Memory Models with Adaptive Resonance Theory for Healthcare Agents , volume=. Proceedings of the AAAI Conference on Artificial Intelligence , publisher=. doi:10.1609/aaai.v40i25.39205 , number=
-
[10]
Zhong, Wanjun and Guo, Lianghong and Gao, Qiqi and Ye, He and Wang, Yanlin , year=. MemoryBank: Enhancing Large Language Models with Long-Term Memory , volume=. Proceedings of the AAAI Conference on Artificial Intelligence , publisher=. doi:10.1609/aaai.v38i17.29946 , number=
-
[11]
ExpeL: LLM Agents Are Experiential Learners , volume=
Zhao, Andrew and Huang, Daniel and Xu, Quentin and Lin, Matthieu and Liu, Yong-Jin and Huang, Gao , year=. ExpeL: LLM Agents Are Experiential Learners , volume=. Proceedings of the AAAI Conference on Artificial Intelligence , publisher=. doi:10.1609/aaai.v38i17.29936 , number=
-
[12]
AutoTool: Efficient Tool Selection for Large Language Model Agents , volume=
Jia, Jingyi and Li, Qinbin , year=. AutoTool: Efficient Tool Selection for Large Language Model Agents , volume=. Proceedings of the AAAI Conference on Artificial Intelligence , publisher=. doi:10.1609/aaai.v40i37.40389 , number=
-
[13]
MCP-AgentBench: Evaluating Real-World Language Agent Performance with MCP-Mediated Tools , volume=
Guo, Zikang and Xu, Benfeng and Zhu, Chiwei and Hong, Wentao and Wang, Xiaorui and Mao, Zhendong , year=. MCP-AgentBench: Evaluating Real-World Language Agent Performance with MCP-Mediated Tools , volume=. Proceedings of the AAAI Conference on Artificial Intelligence , publisher=. doi:10.1609/aaai.v40i37.40347 , number=
-
[14]
SparK: Query-Aware Unstructured Sparsity with Recoverable KV Cache Channel Pruning , volume=
Liao, Huanxuan and Xu, Yixing and He, Shizhu and Li, Guanchen and Yin, Xuanwu and Li, Dong and Barsoum, Emad and Zhao, Jun and Liu, Kang , year=. SparK: Query-Aware Unstructured Sparsity with Recoverable KV Cache Channel Pruning , volume=. Proceedings of the AAAI Conference on Artificial Intelligence , publisher=. doi:10.1609/aaai.v40i38.40466 , number=
-
[15]
2024 , eprint=
MemGPT: Towards LLMs as Operating Systems , author=. 2024 , eprint=
2024
-
[16]
2023 , eprint=
Augmenting Language Models with Long-Term Memory , author=. 2023 , eprint=
2023
-
[17]
2025 , eprint=
Mem0: Building Production-Ready AI Agents with Scalable Long-Term Memory , author=. 2025 , eprint=
2025
-
[18]
2025 , eprint=
A-MEM: Agentic Memory for LLM Agents , author=. 2025 , eprint=
2025
-
[19]
2024 , eprint=
HippoRAG: Neurobiologically Inspired Long-Term Memory for Large Language Models , author=. 2024 , eprint=
2024
-
[20]
2026 , eprint=
REMem: Reasoning with Episodic Memory in Language Agent , author=. 2026 , eprint=
2026
-
[21]
2026 , eprint=
TiMem: Temporal-Hierarchical Memory Consolidation for Long-Horizon Conversational Agents , author=. 2026 , eprint=
2026
-
[22]
2020 , eprint=
Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks , author=. 2020 , eprint=
2020
-
[23]
2026 , eprint=
SWE-Pruner: Self-Adaptive Context Pruning for Coding Agents , author=. 2026 , eprint=
2026
-
[24]
2026 , eprint=
ContextBudget: Budget-Aware Context Management for Long-Horizon Search Agents , author=. 2026 , eprint=
2026
-
[25]
2025 , eprint=
ACON: Optimizing Context Compression for Long-horizon LLM Agents , author=. 2025 , eprint=
2025
-
[26]
2023 , eprint=
H _2 O: Heavy-Hitter Oracle for Efficient Generative Inference of Large Language Models , author=. 2023 , eprint=
2023
-
[27]
2023 , eprint=
Efficient Streaming Language Models with Attention Sinks , author=. 2023 , eprint=
2023
-
[28]
2024 , eprint=
SnapKV: LLM Knows What You are Looking for Before Generation , author=. 2024 , eprint=
2024
-
[29]
2024 , eprint=
PyramidKV: Dynamic KV Cache Compression based on Pyramidal Information Funneling , author=. 2024 , eprint=
2024
-
[30]
2023 , eprint=
AgentBench: Evaluating LLMs as Agents , author=. 2023 , eprint=
2023
-
[31]
2024 , eprint=
WebArena: A Realistic Web Environment for Building Autonomous Agents , author=. 2024 , eprint=
2024
-
[32]
2023 , eprint=
JudgeLM: Fine-tuned Large Language Models are Scalable Judges , author=. 2023 , eprint=
2023
-
[33]
2023 , eprint=
G-Eval: NLG Evaluation using GPT-4 with Better Human Alignment , author=. 2023 , eprint=
2023
-
[34]
Cai, Z.; Zhang, Y.; Gao, B.; Liu, Y.; Li, Y.; Liu, T.; Lu, K.; Xiong, W.; Dong, Y.; Hu, J.; and Xiao, W. 2024. PyramidKV: Dynamic KV Cache Compression based on Pyramidal Information Funneling. arXiv:2406.02069
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[35]
Cassano, F.; and Rush, S. 2026. Training Composer for Longer Horizons . Cursor research blog, accessed 2026-06-04
2026
-
[36]
Chhikara, P.; Khant, D.; Aryan, S.; Singh, T.; and Yadav, D. 2025. Mem0: Building Production-Ready AI Agents with Scalable Long-Term Memory. arXiv:2504.19413
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[37]
Chroma . 2026. Chroma Context-1: Training a Self-Editing Search Agent . Research blog, accessed 2026-06-04
2026
-
[38]
Dai, R.; Hu, H.; Zhang, J.; Kang, Y.; and Tan, A.-H. 2026. MemoryART: Enhancing LLMs via Multi-Memory Models with Adaptive Resonance Theory for Healthcare Agents. Proceedings of the AAAI Conference on Artificial Intelligence, 40(25): 20676–20683
2026
-
[39]
DeepSeek-AI . 2025. DeepSeek-V3.2: Pushing the Frontier of Open Large Language Models . arXiv:2512.02556
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[40]
Z.; Xu, R.; and Wong, K.-F
Du, Y.; Wang, B.; He, Y.; Liang, B.; Wang, B.; Li, Z.; Gui, L.; Pan, J. Z.; Xu, R.; and Wong, K.-F. 2026. MemGuide: Intent-Driven Memory Selection for Goal-Oriented Multi-Session LLM Agents. Proceedings of the AAAI Conference on Artificial Intelligence, 40(36): 30584–30592
2026
-
[41]
Guo, Z.; Xu, B.; Zhu, C.; Hong, W.; Wang, X.; and Mao, Z. 2026. MCP-AgentBench: Evaluating Real-World Language Agent Performance with MCP-Mediated Tools. Proceedings of the AAAI Conference on Artificial Intelligence, 40(37): 30888–30896
2026
-
[42]
J.; Shu, Y.; Gu, Y.; Yasunaga, M.; and Su, Y
Gutiérrez, B. J.; Shu, Y.; Gu, Y.; Yasunaga, M.; and Su, Y. 2024. HippoRAG: Neurobiologically Inspired Long-Term Memory for Large Language Models. arXiv:2405.14831
-
[43]
Jia, J.; and Li, Q. 2026. AutoTool: Efficient Tool Selection for Large Language Model Agents. Proceedings of the AAAI Conference on Artificial Intelligence, 40(37): 31265–31273
2026
-
[44]
ACON: Optimizing Context Compression for Long-horizon LLM Agents
Kang, M.; Chen, W.-N.; Han, D.; Inan, H. A.; Wutschitz, L.; Chen, Y.; Sim, R.; and Rajmohan, S. 2025. ACON: Optimizing Context Compression for Long-horizon LLM Agents. arXiv:2510.00615
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[45]
Lewis, P.; Perez, E.; Piktus, A.; Petroni, F.; Karpukhin, V.; Goyal, N.; Küttler, H.; Lewis, M.; tau Yih, W.; Rocktäschel, T.; Riedel, S.; and Kiela, D. 2020. Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks. arXiv:2005.11401
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[46]
Li, K.; Yu, X.; Ni, Z.; Zeng, Y.; Xu, Y.; Zhang, Z.; Li, X.; Sang, J.; Duan, X.; Wang, X.; Liu, C.; and Tan, J. 2026. TiMem: Temporal-Hierarchical Memory Consolidation for Long-Horizon Conversational Agents. arXiv:2601.02845
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[47]
Li, Y.; Huang, Y.; Yang, B.; Venkitesh, B.; Locatelli, A.; Ye, H.; Cai, T.; Lewis, P.; and Chen, D. 2024. SnapKV: LLM Knows What You are Looking for Before Generation. arXiv:2404.14469
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[48]
Liao, H.; Xu, Y.; He, S.; Li, G.; Yin, X.; Li, D.; Barsoum, E.; Zhao, J.; and Liu, K. 2026. SparK: Query-Aware Unstructured Sparsity with Recoverable KV Cache Channel Pruning. Proceedings of the AAAI Conference on Artificial Intelligence, 40(38): 31961–31969
2026
-
[49]
Liu, X.; Yu, H.; Zhang, H.; Xu, Y.; Lei, X.; Lai, H.; Gu, Y.; Ding, H.; Men, K.; Yang, K.; Zhang, S.; Deng, X.; Zeng, A.; Du, Z.; Zhang, C.; Shen, S.; Zhang, T.; Su, Y.; Sun, H.; Huang, M.; Dong, Y.; and Tang, J. 2023 a . AgentBench: Evaluating LLMs as Agents. arXiv:2308.03688
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[50]
Liu, Y.; Iter, D.; Xu, Y.; Wang, S.; Xu, R.; and Zhu, C. 2023 b . G-Eval: NLG Evaluation using GPT-4 with Better Human Alignment. arXiv:2303.16634
work page internal anchor Pith review Pith/arXiv arXiv 2023
- [51]
-
[52]
MemGPT: Towards LLMs as Operating Systems
Packer, C.; Wooders, S.; Lin, K.; Fang, V.; Patil, S. G.; Stoica, I.; and Gonzalez, J. E. 2024. MemGPT: Towards LLMs as Operating Systems. arXiv:2310.08560
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [53]
-
[54]
Shu, Y.; Jonnalagedda, S. P.; Gao, X.; Gutiérrez, B. J.; Qi, W.; Das, K.; Sun, H.; and Su, Y. 2026. REMem: Reasoning with Episodic Memory in Language Agent. arXiv:2602.13530
-
[55]
H.-M.; Subagdja, B.; and Tan, A.-H
Tan, C. H.-M.; Subagdja, B.; and Tan, A.-H. 2026. ARTEM: Enhancing Large Language Model Agents with Spatial-Temporal Episodic Memory. Proceedings of the AAAI Conference on Artificial Intelligence, 40(30): 25753–25760
2026
- [56]
-
[57]
Wang, Y.; Shi, Y.; Yang, M.; Zhang, R.; He, S.; Lian, H.; Chen, Y.; Ye, S.; Cai, K.; and Gu, X. 2026. SWE-Pruner: Self-Adaptive Context Pruning for Coding Agents. arXiv:2601.16746
work page internal anchor Pith review Pith/arXiv arXiv 2026
- [58]
-
[59]
Xiao, G.; Tian, Y.; Chen, B.; Han, S.; and Lewis, M. 2023. Efficient Streaming Language Models with Attention Sinks. arXiv:2309.17453
work page internal anchor Pith review Pith/arXiv arXiv 2023
- [60]
-
[61]
Xu, B.; Zhang, D.; and Arunachalam, R. 2026. From Model to Agent: Equipping the Responses API with a Computer Environment . Engineering blog, accessed 2026-06-04
2026
-
[62]
Xu, W.; Liang, Z.; Mei, K.; Gao, H.; Tan, J.; and Zhang, Y. 2025. A-MEM: Agentic Memory for LLM Agents. arXiv:2502.12110
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[63]
Ye, R.; Zhang, Z.; Li, K.; Yin, H.; Tao, Z.; Zhao, Y.; Su, L.; Zhang, L.; Qiao, Z.; Wang, X.; Xie, P.; Huang, F.; Zhou, J.; Chen, S.; and Jiang, Y. 2026. AgentFold: Long-Horizon Web Agents with Proactive Context Folding . ICLR 2026 Poster
2026
-
[64]
Zhang, Z.; Sheng, Y.; Zhou, T.; Chen, T.; Zheng, L.; Cai, R.; Song, Z.; Tian, Y.; Ré, C.; Barrett, C.; Wang, Z.; and Chen, B. 2023. H _2 O: Heavy-Hitter Oracle for Efficient Generative Inference of Large Language Models. arXiv:2306.14048
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[65]
Zhao, A.; Huang, D.; Xu, Q.; Lin, M.; Liu, Y.-J.; and Huang, G. 2024. ExpeL: LLM Agents Are Experiential Learners. Proceedings of the AAAI Conference on Artificial Intelligence, 38(17): 19632–19642
2024
-
[66]
Zhong, W.; Guo, L.; Gao, Q.; Ye, H.; and Wang, Y. 2024. MemoryBank: Enhancing Large Language Models with Long-Term Memory. Proceedings of the AAAI Conference on Artificial Intelligence, 38(17): 19724–19731
2024
-
[67]
WebArena: A Realistic Web Environment for Building Autonomous Agents
Zhou, S.; Xu, F. F.; Zhu, H.; Zhou, X.; Lo, R.; Sridhar, A.; Cheng, X.; Ou, T.; Bisk, Y.; Fried, D.; Alon, U.; and Neubig, G. 2024. WebArena: A Realistic Web Environment for Building Autonomous Agents. arXiv:2307.13854
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [68]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.