From World Models to World Action Models: A Concise Tutorial for Robotics
Pith reviewed 2026-07-02 11:24 UTC · model grok-4.3
The pith
World models are action-conditioned predictors of future observations or states, and world action models connect those predictions to executable robot actions via four paradigms.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
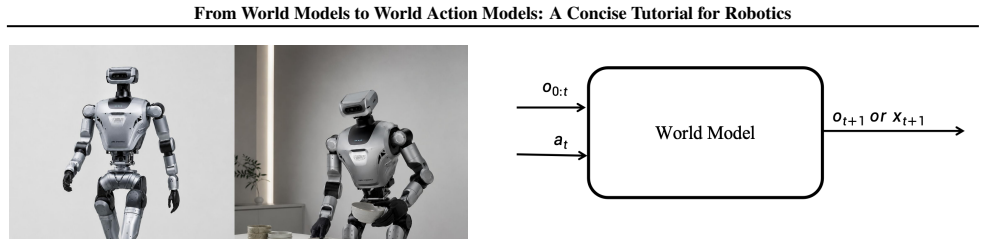
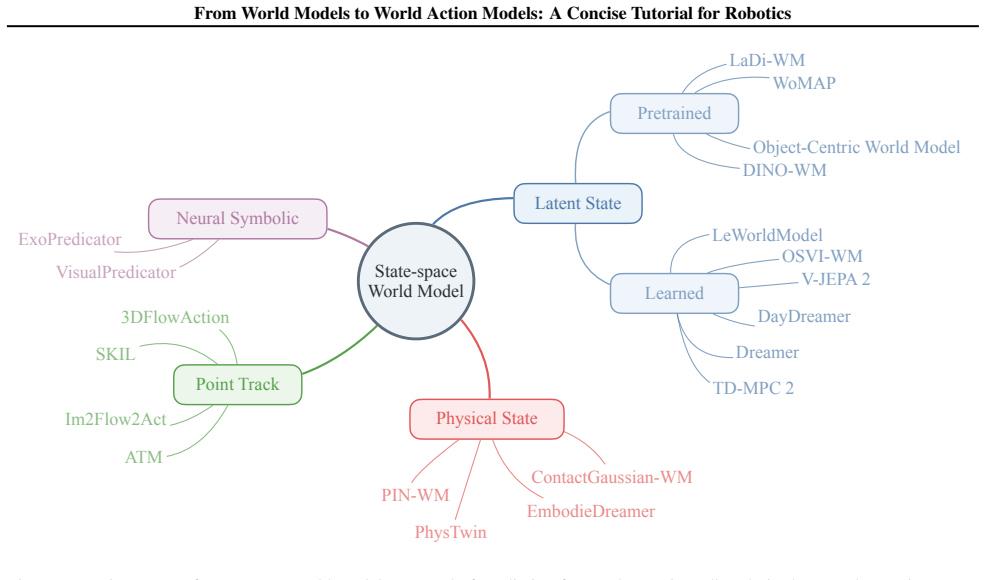
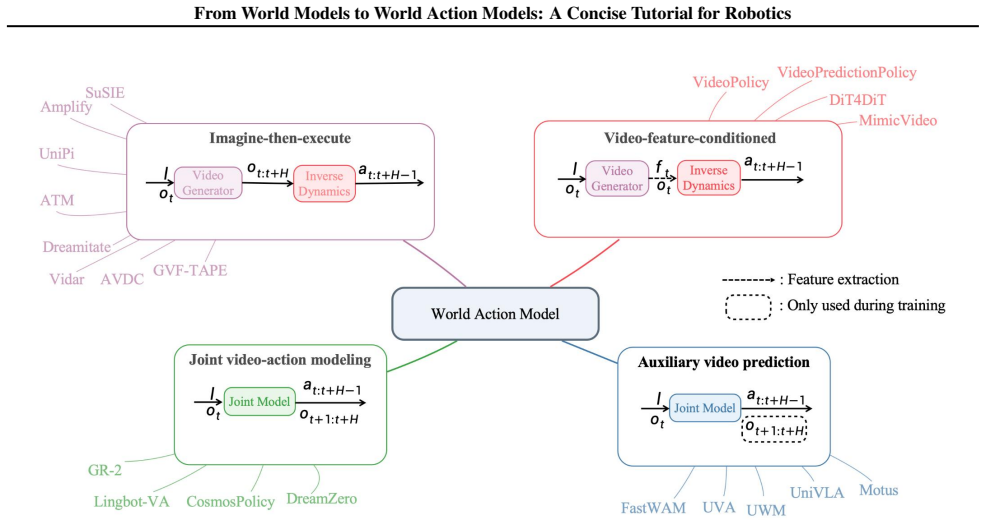
World models are action-conditioned predictive models that estimate the future evolution of task-relevant observations or states. Methods are split into observation-space world models that work with raw sensory data and state-space world models that operate on structured representations. World action models then connect these predicted futures to executable robot actions through four paradigms: imagine-then-execute, video-feature-conditioned action prediction, joint video-action modeling, and auxiliary video prediction for policy learning.
What carries the argument
The taxonomy dividing world models into observation-space versus state-space categories and the four paradigms that link predicted futures to robot actions in world action models.
If this is right
- Observation-space models trade higher visual fidelity for lower physical interpretability compared with state-space models.
- The imagine-then-execute paradigm lets a robot simulate futures before choosing actions.
- Joint video-action modeling predicts observations and actions together in one model.
- Auxiliary video prediction supplies extra signals that improve policy learning without direct action modeling.
- The taxonomy clarifies how predictive models can be chosen or combined for different robotics control tasks.
Where Pith is reading between the lines
- The taxonomy could be used to spot missing hybrids that combine visual fidelity with physical structure.
- Benchmarking the four paradigms on the same robot tasks would test whether the distinctions hold in practice.
- Extending the same categories to multi-robot coordination might expose new links between prediction and joint actions.
- The design-space view could guide curriculum design for teaching embodied prediction methods.
Load-bearing premise
That the division into observation-space and state-space world models together with the four listed paradigms forms a useful and reasonably complete design-space taxonomy for the field.
What would settle it
Discovery of a world model or action-connection method that cannot be placed into either the observation-space or state-space category and does not match any of the four paradigms would show the taxonomy is incomplete.
Figures


read the original abstract
World models are increasingly used in embodied intelligence and generative simulation, yet their scope remains ambiguous across communities. This tutorial presents a design-space view of world models as action-conditioned predictive models that estimate the future evolution of task-relevant observations or states. We categorize existing methods into observation-space and state-space world models, comparing their trade-offs in visual fidelity, spatial structure, physical interpretability, and control usability. We further introduce world action models, which connect predicted futures with executable robot actions, and summarize four representative paradigms: imagine-then-execute, video-feature-conditioned action prediction, joint video-action modeling, and auxiliary video prediction for policy learning. The goal of this tutorial is to clarify the conceptual scope of world (action) models and provide a structured taxonomy for embodied prediction and control.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper is a tutorial that defines world models as action-conditioned predictive models estimating the future evolution of task-relevant observations or states. It categorizes methods into observation-space and state-space world models, comparing trade-offs in visual fidelity, spatial structure, physical interpretability, and control usability. It introduces world action models and summarizes four paradigms: imagine-then-execute, video-feature-conditioned action prediction, joint video-action modeling, and auxiliary video prediction for policy learning, with the aim of clarifying the conceptual scope and providing a structured taxonomy for embodied prediction and control.
Significance. If the taxonomy holds as a clarifying view, the paper offers a structured design-space perspective that could help organize literature on world models in robotics. Its contribution is conceptual framing and categorization rather than new derivations, theorems, or empirical results; the explicit disclaimer that the taxonomy is not claimed to be exhaustive or optimal reduces overclaim risk.
Simulated Author's Rebuttal
We thank the referee for their accurate summary of the manuscript and for recommending acceptance. The review correctly identifies the paper's focus on conceptual framing and taxonomy rather than new empirical results. No major comments were raised in the report.
Circularity Check
No significant circularity; purely descriptive tutorial with no derivations or fitted results
full rationale
The paper is a tutorial that offers definitional framing of world models as action-conditioned predictive models and a design-space categorization into observation- vs. state-space models plus four paradigms (imagine-then-execute, video-feature-conditioned action prediction, joint video-action modeling, auxiliary video prediction). No equations, formal derivations, empirical fits, or load-bearing self-citations appear; the taxonomy is explicitly presented as a clarifying view rather than an exhaustive claim or derived result. The content is therefore self-contained with no reduction of outputs to inputs by construction.
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.