On the Utility and Factual Reliability of Pruned Mixture-of-Experts Models in the Biomedical Domain
Pith reviewed 2026-07-03 21:11 UTC · model grok-4.3
The pith
Moderate pruning of MoE models preserves biomedical utility and reliability until extreme ratios.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
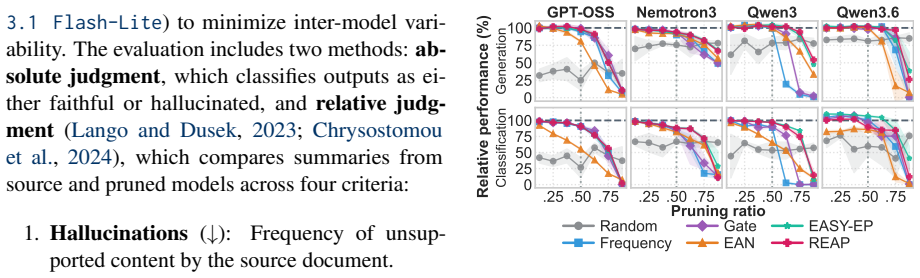
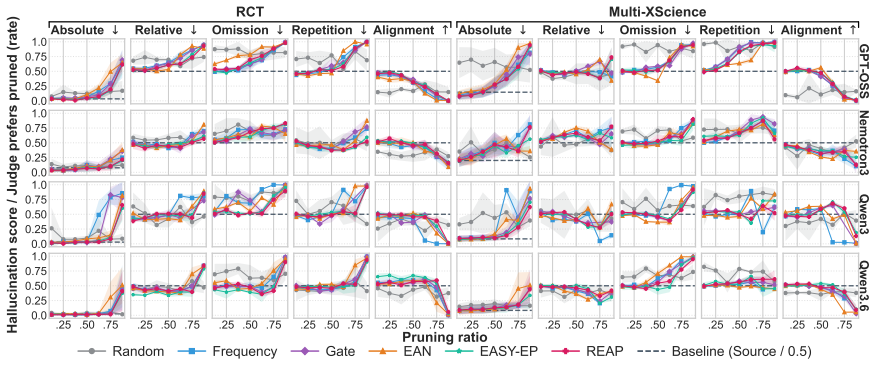
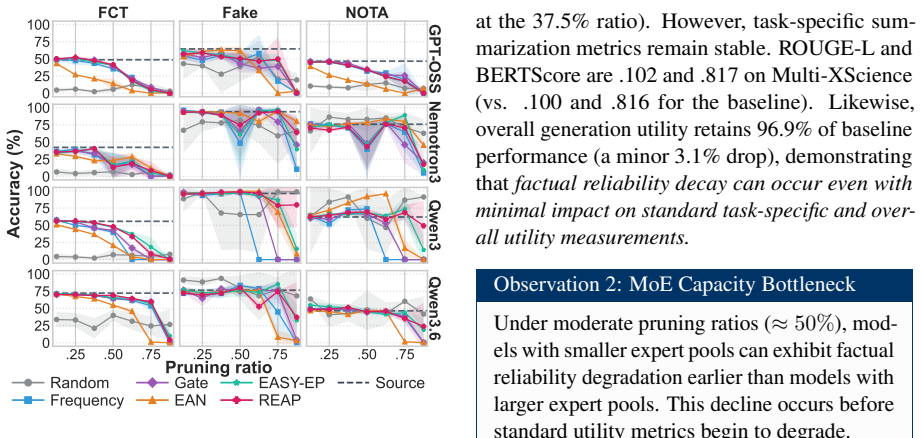
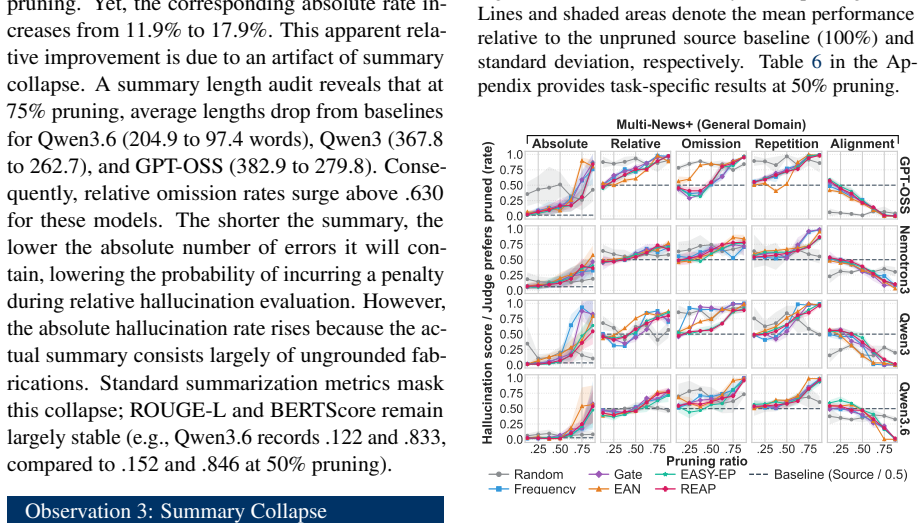
Structured expert pruning allows moderate compression of MoE models while preserving in-domain utility on biomedical generation and classification tasks without immediate reliability decline, although hallucination risks increase at extreme pruning ratios. Cross-domain transfer to the general domain leads to rapid degradation in both utility and reliability, indicating that safe compression is task- and domain-dependent and that utility evaluation alone is inadequate without reliability assessment.
What carries the argument
structured expert pruning of Mixture-of-Experts models, evaluated on utility metrics for generation and classification tasks plus reliability metrics including hallucination detection, across in-domain biomedical and cross-domain general settings.
If this is right
- Moderate pruning ratios can reduce memory costs for biomedical MoE deployments while keeping utility and reliability stable.
- Extreme pruning ratios should be avoided in biomedical applications due to rising hallucination risks.
- Pruned MoE models cannot be directly transferred to general domain tasks without expecting losses in both utility and reliability.
- Reliability evaluation must accompany utility evaluation for high-stakes biomedical deployments of pruned models.
- Domain and task specificity must be considered when determining safe pruning levels for MoE models.
Where Pith is reading between the lines
- Domain-specific pruning approaches may be required to ensure safety across different specialized fields.
- Real-world clinical deployment tests could validate whether benchmark findings hold under actual high-stakes conditions.
- Combining pruning with other compression methods might extend the range of safe ratios.
- The rapid cross-domain degradation pattern could guide pruning decisions in other expert-based models.
Load-bearing premise
The chosen biomedical tasks, models, and reliability metrics including hallucination detection are representative of real high-stakes deployment and that observed differences are caused by pruning rather than other experimental factors.
What would settle it
Finding that moderate pruning immediately increases hallucination rates or reduces reliability on biomedical tasks or different MoE models would contradict the preservation claim.
Figures


read the original abstract
Mixture-of-Experts (MoE) models offer inference speedups via selective activation but impose substantial memory requirements because the whole network must remain loaded. Structured expert pruning is a practical approach for reducing deployment costs in resource-constrained settings. However, prior studies primarily evaluate benchmark utility, leaving the effect of pruning on factual reliability underexplored, particularly in high-stakes domains such as biomedicine. In this paper, we investigate how domain-specific expert pruning affects both utility and reliability. We assess four MoE models, six pruning methods, and multiple pruning ratios across generation and classification tasks under in-domain (biomedical) and cross-domain settings. Results reveal that moderate pruning preserves in-domain utility without immediate reliability decline, although hallucination risks increase at extreme pruning ratios. When shifting to the general domain, both utility and reliability degrade rapidly. These findings indicate that safe compression depends heavily on the task and domain. Evaluating pruned MoE models solely on utility is inadequate for high-stakes deployment without reliability assessment.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript reports an empirical evaluation of structured expert pruning on four MoE models using six pruning methods across multiple ratios. Experiments cover generation and classification tasks in biomedical (in-domain) and general (cross-domain) settings. The central claim is that moderate pruning preserves in-domain utility without immediate factual-reliability decline, while extreme ratios increase hallucination risk and cross-domain transfer causes rapid degradation of both utility and reliability. The authors conclude that utility-only evaluation is inadequate for high-stakes biomedical deployment.
Significance. If the directional findings prove robust, the work supplies practical guidance for memory-constrained deployment of MoE models in biomedicine and underscores the necessity of joint utility-reliability assessment. The breadth of the experimental matrix (four models, six methods, multiple ratios, in- versus cross-domain) is a clear strength of the study.
major comments (1)
- [Abstract] Abstract and results sections: directional claims of 'no immediate reliability decline' and 'hallucination risks increase at extreme ratios' are presented without statistical significance tests, error bars, or exact metric values, preventing verification that observed differences are attributable to pruning rather than experimental variability.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for recommending major revision. We address the major comment point by point below.
read point-by-point responses
-
Referee: [Abstract] Abstract and results sections: directional claims of 'no immediate reliability decline' and 'hallucination risks increase at extreme ratios' are presented without statistical significance tests, error bars, or exact metric values, preventing verification that observed differences are attributable to pruning rather than experimental variability.
Authors: We agree that the abstract presents directional claims in summary form and that the results would be strengthened by explicit statistical support. The full results sections contain tables reporting exact metric values for all models, methods, and ratios; however, we did not include error bars from repeated runs or formal significance tests. In the revised manuscript we will (1) add exact values to the abstract where space allows, (2) include error bars on all relevant figures and tables, and (3) report paired statistical tests (e.g., Wilcoxon signed-rank) comparing pruned versus unpruned performance to confirm that observed differences exceed experimental variability. These changes will be made without altering the reported trends. revision: yes
Circularity Check
No significant circularity
full rationale
This is a purely empirical comparison study evaluating four MoE models under six pruning methods and multiple ratios on generation and classification tasks in in-domain vs. cross-domain settings. No derivations, equations, or first-principles predictions are present that could reduce to fitted inputs or self-citations by construction. All claims rest on reported experimental outcomes rather than any internal definitional or predictive loop.
Axiom & Free-Parameter Ledger
free parameters (1)
- pruning ratios
Reference graph
Works this paper leans on
-
[1]
Evaluating Large Language Models Trained on Code
Evaluating large lan- guage models trained on code.arXiv preprint, arXiv:2107.03374. Tianyu Chen, Shaohan Huang, Yuan Xie, Binxing Jiao, Daxin Jiang, Haoyi Zhou, Jianxin Li, and Furu Wei
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Yuanteng Chen, Yuantian Shao, Peisong Wang, and Jian Cheng
Task-specific expert pruning for sparse mixture-of-experts.arXiv preprint, arXiv:2206.00277. Yuanteng Chen, Yuantian Shao, Peisong Wang, and Jian Cheng. 2025b. EAC-MoE: Expert-selection aware compressor for mixture-of-experts large language models. InProceedings of the 63rd Annual Meeting of the Association for Compu- tational Linguistics (Volume 1: Long ...
-
[3]
InProceedings of the 2024 Confer- ence on Empirical Methods in Natural Language Processing, pages 15–29, Miami, Florida, USA
Multi-news+: Cost- efficient dataset cleansing via LLM-based data annotation. InProceedings of the 2024 Confer- ence on Empirical Methods in Natural Language Processing, pages 15–29, Miami, Florida, USA. Association for Computational Linguistics. George Chrysostomou, Zhixue Zhao, Miles Williams, and Nikolaos Aletras
2024
-
[4]
Training verifiers to solve math word problems.arXiv preprint, arXiv:2110.14168. Tri Dao
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
In Proceedings of the Eleventh International Con- ference on Learning Representations
OPTQ: Accurate quantiza- tion for generative pre-trained transformers. In Proceedings of the Eleventh International Con- ference on Learning Representations. Yao Fu, Runchao Li, Xianxuan Long, Haotian Yu, Xiaotian Han, Yu Yin, and Pan Li. 2025a. Prun- ing weights but not truth: Safeguarding truth- fulness while pruning LLMs. InFindings of the Association ...
2025
-
[6]
InFindings of the Asso- ciation for Computational Linguistics: EMNLP 2024, pages 8221–8240, Miami, Florida, USA
MedINST: Meta dataset of biomedical instructions. InFindings of the Asso- ciation for Computational Linguistics: EMNLP 2024, pages 8221–8240, Miami, Florida, USA. Association for Computational Linguistics. Shwai He, Run-Ze Fan, Liang Ding, Li Shen, Tianyi Zhou, and Dacheng Tao
2024
-
[7]
InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 14685– 14691, Singapore
Merg- ing experts into one: Improving computational efficiency of mixture of experts. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 14685– 14691, Singapore. Association for Computa- tional Linguistics. Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt
2023
-
[8]
Finding fantastic experts in moes: A unified study for ex- pert dropping strategies and observations.arXiv preprint, arXiv:2504.05586. Ziwei Ji, Nayeon Lee, Rita Frieske, Tiezheng Yu, Dan Su, Yan Xu, Etsuko Ishii, Ye Jin Bang, An- drea Madotto, and Pascale Fung
-
[9]
Pub- MedQA: A dataset for biomedical research ques- tion answering. InProceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Process- ing (EMNLP-IJCNLP), pages 2567–2577, Hong Kong, China. Association for Computational Linguistics. Young Jin Kim, Ammar Ahmad Awa...
2019
-
[10]
arXiv preprint arXiv:2109.10465 , year=
Scalable and efficient MoE training for multitask multilingual models.arXiv preprint, arXiv:2109.10465. Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph Gonzalez, Hao Zhang, and Ion Stoica
-
[11]
InProceedings of the 2023 Conference on Empirical Methods in Nat- ural Language Processing, pages 2853–2862, Singapore
Critic- driven decoding for mitigating hallucinations in data-to-text generation. InProceedings of the 2023 Conference on Empirical Methods in Nat- ural Language Processing, pages 2853–2862, Singapore. Association for Computational Lin- guistics. Mike Lasby, Ivan Lazarevich, Nish Sinnadu- rai, Sean Lie, Yani Ioannou, and Vithursan Thangarasa
2023
-
[12]
Datasets: A community library for natural language processing. InProceed- ings of the 2021 Conference on Empirical Meth- ods in Natural Language Processing: System Demonstrations, pages 175–184, Online and Punta Cana, Dominican Republic. Association for Computational Linguistics. Pingzhi Li, Xiaolong Jin, Zhen Tan, Yu Cheng, and Tianlong Chen. 2024a. Quan...
-
[13]
EvoESAP: Non-Uniform Expert Pruning for Sparse MoE
EvoE- SAP: Non-uniform expert pruning for sparse moe.arXiv preprint, arXiv:2603.06003. Xudong Lu, Qi Liu, Yuhui Xu, Aojun Zhou, Siyuan Huang, Bo Zhang, Junchi Yan, and Hongsheng Li
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
InProceedings of the 2020 Confer- ence on Empirical Methods in Natural Language Processing (EMNLP), pages 8068–8074, Online
Multi-XScience: A large-scale dataset for ex- treme multi-document summarization of scien- tific articles. InProceedings of the 2020 Confer- ence on Empirical Methods in Natural Language Processing (EMNLP), pages 8068–8074, Online. Association for Computational Linguistics. Michael Moor, Oishi Banerjee, Zahra Shakeri Hos- sein Abad, Harlan M. Krumholz, Ju...
2020
-
[15]
SEER-MoE: Sparse expert efficiency through regularization for mixture-of-experts.arXiv preprint, arXiv:2404.05089. NVIDIA, Aaron Blakeman, Aaron Grattafiori, Aarti Basant, Abhibha Gupta, Abhinav Khat- tar, Adi Renduchintala, Aditya Vavre, Akanksha Shukla, Akhiad Bercovich, Aleksander Ficek, Aleksandr Shaposhnikov, Alex Kondratenko, Alexander Bukharin, Ale...
-
[16]
NVIDIA Nemotron 3: Efficient and Open Intelligence
NVIDIA Nemotron 3: Efficient and open intelligence. arXiv preprint, arXiv:2512.20856. OpenAI, Sandhini Agarwal, Lama Ahmad, Ja- son Ai, Sam Altman, Andy Applebaum, Ed- win Arbus, Rahul K. Arora, Yu Bai, Bowen Baker, Haiming Bao, Boaz Barak, Ally Bennett, Tyler Bertao, Nivedita Brett, Eugene Brevdo, Greg Brockman, Sebastien Bubeck, Che Chang, Kai Chen, Mar...
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
gpt-oss-120b & gpt-oss-20b Model Card
gpt-oss- 120b & gpt-oss-20b model card.arXiv preprint, arXiv:2508.10925. Ankit Pal, Logesh Kumar Umapathi, and Malaikan- nan Sankarasubbu
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
Olmo 3.arXiv preprint, arXiv:2512.13961. Byron C. Wallace, Sayantan Saha, Frank Soboczen- ski, and Iain J. Marshall
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
Can large language models still explain themselves? investigating the im- pact of quantization on self-explanations.arXiv preprint, arXiv:2601.00282. Laura Weidinger, Jonathan Uesato, Maribeth Rauh, Conor Griffin, Po-Sen Huang, John Mellor, Amelia Glaese, Myra Cheng, Borja Balle, Atoosa Kasirzadeh, Courtney Biles, Sasha Brown, Zac Kenton, Will Hawkins, To...
-
[20]
InProceedings of the 2022 ACM Conference on Fairness, Accountability, and Transparency, FAccT ’22, page 214–229, New York, NY , USA
Taxonomy of risks posed by language models. InProceedings of the 2022 ACM Conference on Fairness, Accountability, and Transparency, FAccT ’22, page 214–229, New York, NY , USA. Association for Computing Machinery. Miles Williams, George Chrysostomou, and Niko- laos Aletras
2022
-
[21]
Self-calibration for language model quantization and pruning. InProceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Com- putational Linguistics: Human Language Tech- nologies (Volume 1: Long Papers), pages 10149– 10167, Albuquerque, New Mexico. Association for Computational Linguistics. Miles Williams, George C...
2025
-
[22]
Transformers: State-of-the-art natural language processing. InProceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demon- strations, pages 38–45, Online. Association for Computational Linguistics. An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv,...
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[23]
InFindings of the Association for Computational Linguistics: EMNLP 2024, pages 10456–10466, Miami, Florida, USA
MoE-i2: Com- pressing mixture of experts models through inter- expert pruning and intra-expert low-rank decom- position. InFindings of the Association for Computational Linguistics: EMNLP 2024, pages 10456–10466, Miami, Florida, USA. Associa- tion for Computational Linguistics. Jinluan Yang, Dingnan Jin, Anke Tang, Li Shen, Didi Zhu, Zhengyu Chen, Ziyu Zh...
2024
-
[24]
InFindings of the Association for Computational Linguistics: ACL 2025, pages 86–102, Vienna, Austria
Diversifying the expert knowledge for task-agnostic pruning in sparse mixture-of-experts. InFindings of the Association for Computational Linguistics: ACL 2025, pages 86–102, Vienna, Austria. Associa- tion for Computational Linguistics. Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, E...
2025
-
[25]
Instruction-Following Evaluation for Large Language Models
Instruction-following evaluation for large language models.arXiv preprint, arXiv:2311.07911. Yixiao Zhou, Ziyu Zhao, Dongzhou Cheng, Zhil- iang Wu, Jie Gui, Yi Yang, Fei Wu, Yu Cheng, and Hehe Fan
work page internal anchor Pith review Pith/arXiv arXiv
-
[26]
reason":
Dropping experts, re- combining neurons: Retraining-free pruning for sparse mixture-of-experts LLMs. InFindings of the Association for Computational Linguistics: EMNLP 2025, pages 15169–15186, Suzhou, China. Association for Computational Linguis- tics. A Implementation Details Software.We utilize Hugging Face (HF) datasets (Lhoest et al., 2021, v3.6.0) fo...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.