PWM-ArtGen: Part World Model for Articulated Object Generation
Pith reviewed 2026-07-03 15:58 UTC · model grok-4.3
The pith
Coupling action diffusion with image diffusion recovers kinematic structure from single images of articulated objects.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
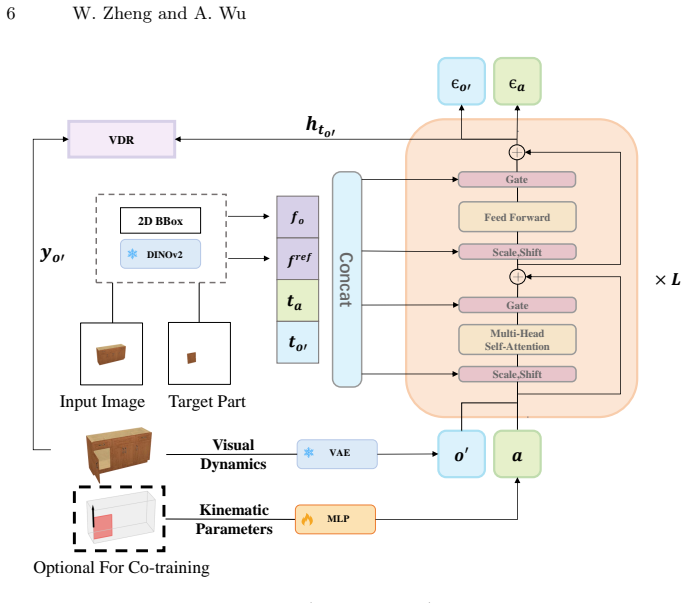
Articulated objects can be treated as dynamic systems whose visual dynamics and kinematic parameters are learned jointly; a unified Part World Model couples action diffusion and image diffusion using independent timesteps to enable co-training on unannotated data, yielding substantially better kinematic recovery than baselines or two-step pipelines.
What carries the argument
Part World Model (PWM-ArtGen) that couples action diffusion and image diffusion with independent diffusion timesteps to support visual-branch co-training on unannotated image pairs.
If this is right
- Kinematic parameters can be recovered directly from the joint distribution rather than from static images or sequential estimation.
- Unannotated photorealistic image pairs become usable for training through independent-timestep co-training.
- Performance improves in the resting state relative to existing baselines.
- Zero-shot generalization extends to out-of-distribution articulated objects.
Where Pith is reading between the lines
- The same coupling mechanism could be tested on video prediction tasks where both appearance and motion parameters must be inferred together.
- If the independent-timestep design scales, it might reduce reliance on fully annotated kinematic datasets across other 3D generation domains.
- The approach suggests that treating generation as joint modeling of dynamics and parameters may apply to non-articulated deformable objects as well.
Load-bearing premise
Coupling action diffusion and image diffusion with independent timesteps on unannotated data will recover accurate kinematic structure without the accumulated errors of two-step methods.
What would settle it
On a held-out test set of articulated objects with known ground-truth joints and part motions, the model produces incorrect part trajectories or joint parameters at rates no better than two-step baselines.
Figures








read the original abstract
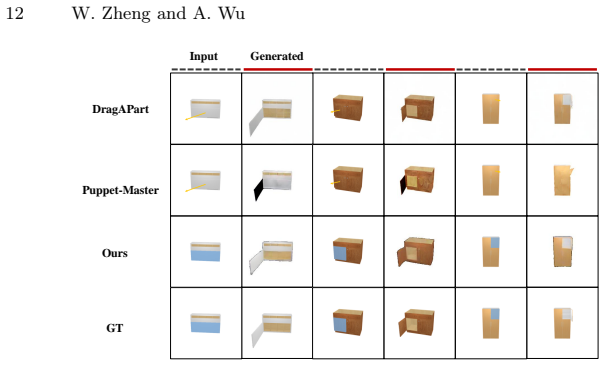
The key challenge in articulated 3D object generation from a single image is accurately predicting the underlying kinematic structure. Existing methods either infer kinematic parameters directly from a static image that lacks dynamic part-level kinematic relationships, or estimate parameters from visual dynamics generated from a single image, which is prone to accumulated errors of two steps. Moreover, the limited scale and diversity of existing annotated datasets further hinder generalization to complex, real-world objects. To overcome these limitations, we propose to learn the joint distribution of visual dynamics and kinematic parameters. Recognizing that articulated objects can be formulated as dynamic systems, we propose a unified Part World Model called PWM-ArtGen. To leverage unannotated data, this model couples action diffusion and image diffusion with independent diffusion timesteps, which enables visual branch co-training. We further curate a photorealistic dataset of 19.7k part-level image pairs without kinematic annotations, to support co-training. Experiments demonstrate that PWM-ArtGen substantially outperforms existing baselines in the resting state and exhibits strong zero-shot generalization to out-of-distribution objects.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes PWM-ArtGen, a Part World Model for articulated 3D object generation from a single image. It addresses limitations of prior methods by learning the joint distribution of visual dynamics and kinematic parameters via a unified model that couples action diffusion and image diffusion using independent timesteps, enabling co-training on a newly curated photorealistic dataset of 19.7k part-level image pairs without kinematic annotations. The central claims are that this yields substantially better performance than baselines in the resting state and strong zero-shot generalization to out-of-distribution objects.
Significance. If the joint-training approach on unannotated data reliably recovers kinematic structure, the work could meaningfully advance single-image articulated generation by sidestepping accumulated errors from two-step pipelines and scaling beyond small annotated datasets. The use of independent-timestep diffusion for co-training is a potentially useful technical device for leveraging larger unannotated corpora.
major comments (2)
- [Abstract] Abstract: The central claim that coupling action diffusion and image diffusion with independent timesteps on unannotated pairs recovers kinematic parameters more reliably than two-step methods is load-bearing for both the performance and zero-shot OOD generalization assertions, yet the description provides no mechanism ensuring that predicted actions are linked to observed image dynamics during co-training; without such linkage the model could fit spurious correlations.
- [Abstract] Abstract: The experiments are said to demonstrate substantial outperformance and strong zero-shot generalization, but no quantitative tables, ablation studies, dataset statistics (e.g., diversity metrics for the 19.7k pairs), or evaluation protocols are supplied, preventing verification that the claimed gains are supported by the data rather than by the unannotated training regime.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We respond point-by-point to the two major comments below, drawing on details from the full manuscript while noting where the abstract can be clarified.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that coupling action diffusion and image diffusion with independent timesteps on unannotated pairs recovers kinematic parameters more reliably than two-step methods is load-bearing for both the performance and zero-shot OOD generalization assertions, yet the description provides no mechanism ensuring that predicted actions are linked to observed image dynamics during co-training; without such linkage the model could fit spurious correlations.
Authors: The abstract is concise by design. Section 3 of the manuscript specifies the linkage: the action diffusion branch is conditioned on the source image and the target image from each training pair (with independent timesteps), and the training objective requires that the predicted action, when applied through the dynamics, reconstructs the observed target image via the image diffusion branch. This direct consistency constraint on paired data prevents fitting to spurious correlations. We will revise the abstract to include a short clause describing this conditioning. revision: yes
-
Referee: [Abstract] Abstract: The experiments are said to demonstrate substantial outperformance and strong zero-shot generalization, but no quantitative tables, ablation studies, dataset statistics (e.g., diversity metrics for the 19.7k pairs), or evaluation protocols are supplied, preventing verification that the claimed gains are supported by the data rather than by the unannotated training regime.
Authors: Abstracts summarize rather than tabulate. The full manuscript contains quantitative comparisons in Tables 1 and 2 (Section 4), ablations in Section 4.3, dataset statistics and diversity metrics for the 19.7k pairs in Section 3.2, and evaluation protocols in Section 4.1. These results support the performance and zero-shot claims. We can expand the abstract's results sentence or add a pointer if the referee prefers. revision: partial
Circularity Check
No circularity; claims rest on data-driven learning from curated pairs
full rationale
The paper frames its core contribution as learning the joint distribution of visual dynamics and kinematic parameters via coupled diffusion models trained on a 19.7k unannotated dataset. No equations, fitted parameters renamed as predictions, or self-citations appear in the provided text that would reduce any claimed result to an input by construction. The independent-timestep coupling and zero-shot generalization are presented as empirical outcomes of co-training rather than tautological definitions or self-referential fits. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Articulated objects can be formulated as dynamic systems
Reference graph
Works this paper leans on
-
[1]
Cosmos World Foundation Model Platform for Physical AI
Agarwal, N., Ali, A., Bala, M., Balaji, Y., Barker, E., Cai, T., Chattopadhyay, P., Chen, Y., Cui, Y., Ding, Y., et al.: Cosmos world foundation model platform for physical ai. arXiv preprint arXiv:2501.03575 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Revisiting Feature Prediction for Learning Visual Representations from Video
Bardes, A., Garrido, Q., Ponce, J., Chen, X., Rabbat, M., LeCun, Y., Assran, M., Ballas, N.: Revisiting feature prediction for learning visual representations from video. arXiv preprint arXiv:2404.08471 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[3]
Brooks, T., Peebles, B., Holmes, C., DePue, W., Guo, Y., Jing, L., Schnurr, D., Taylor, J., Luhman, T., Luhman, E., Ng, C., Wang, R., Ramesh, A.: Video gener- ation models as world simulators (2024),https://openai.com/research/video- generation-models-as-world-simulators, accessed: 29 June 2026
2024
-
[4]
Bruce, J., Dennis, M., Edwards, A., Parker-Holder, J., Shi, Y.J., Hughes, E., Lai, M., Mavalankar, A., Steigerwald, R., Apps, C., Aytar, Y., Bechtle, S., Behbahani, F., Chan, S., Heess, N., Gonzalez, L., Osindero, S., Ozair, S., Reed, S., Zhang, J., Zolna, K., Clune, J., De Freitas, N., Singh, S., Rocktäschel, T.: Genie: generative interactive environment...
2024
-
[5]
In: Proceedings of the SIGGRAPH Asia 2025 Conference Papers (2025)
Chen, C., Liu, I., Wei, X., Su, H., Liu, M.: Freeart3d: Training-free articulated object generation using 3d diffusion. In: Proceedings of the SIGGRAPH Asia 2025 Conference Papers (2025)
2025
-
[6]
In: Proceedings of the SIGGRAPH Asia 2025 Conference Papers (2025)
Chen, H., Lan, Y., Chen, Y., Pan, X.: Artilatent: Realistic articulated 3d object generation via structured latents. In: Proceedings of the SIGGRAPH Asia 2025 Conference Papers (2025)
2025
-
[7]
In: Proceedings of Robotics: Science and Systems (2024)
Chen, Z., Walsman, A., Memmel, M., Mo, K., Fang, A., Vemuri, K., Wu, A., Fox, D., Gupta, A.: Urdformer: A pipeline for constructing articulated simulation environments from real-world images. In: Proceedings of Robotics: Science and Systems (2024)
2024
-
[8]
In: IEEE Conf
Collins, J., Goel, S., Deng, K., Luthra, A., Xu, L., Gundogdu, E., Zhang, X., Vicente, T.F.Y., Dideriksen, T., Arora, H., Guillaumin, M., Malik, J.: Abo: Dataset and benchmarks for real-world 3d object understanding. In: IEEE Conf. Comput. Vis. Pattern Recog. pp. 21094–21104 (2022)
2022
-
[9]
In: IEEE Conf
Geng, H., Xu, H., Zhao, C., Xu, C., Yi, L., Huang, S., Wang, H.: Gapartnet: Cross-category domain-generalizable object perception and manipulation via gen- eralizable and actionable parts. In: IEEE Conf. Comput. Vis. Pattern Recog. pp. 7081–7091 (2023)
2023
-
[10]
Guo, Y., Hu, Y., Zhang, J., Wang, Y.J., Chen, X., Lu, C., Chen, J.: Prediction with action: Visual policy learning via joint denoising process. In: Adv. Neural Inform. Process. Syst. vol. 37, pp. 112386–112410 (2024)
2024
-
[11]
In: IEEE Conf
Heppert, N., Irshad, M.Z., Zakharov, S., Liu, K., Ambrus, R.A., Bohg, J., Valada, A., Kollar, T.: Carto: Category and joint agnostic reconstruction of articulated objects. In: IEEE Conf. Comput. Vis. Pattern Recog. pp. 21201–21210 (2023)
2023
-
[12]
Ho, J., Jain, A., Abbeel, P.: Denoising diffusion probabilistic models. In: Adv. Neural Inform. Process. Syst. vol. 33, pp. 6840–6851 (2020) 16 W. Zheng and A. Wu
2020
-
[13]
ACM Trans
Hu, R., Li, W., Van Kaick, O., Shamir, A., Zhang, H., Huang, H.: Learning to predict part mobility from a single static snapshot. ACM Trans. Graph.36(6), 1–13 (2017)
2017
-
[14]
Hurst, A., Lerer, A., Goucher, A.P., Perelman, A., Ramesh, A., Clark, A., Os- trow, A., Welihinda, A., Hayes, A., Radford, A., et al.: Gpt-4o system card. arXiv preprint arXiv:2410.21276 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[15]
In: Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision
Iliash, D., Jiang, H., Zhang, Y., Savva, M., Chang, A.X.: S2o: Static to openable enhancement for articulated 3d objects. In: Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision. pp. 6785–6795 (2026)
2026
-
[16]
In: IEEE Conf
Jiang, Z., Hsu, C.C., Zhu, Y.: Ditto: Building digital twins of articulated objects from interaction. In: IEEE Conf. Comput. Vis. Pattern Recog. pp. 5616–5626 (2022)
2022
-
[17]
Kirillov, A., Mintun, E., Ravi, N., Mao, H., Rolland, C., Gustafson, L., Xiao, T., Whitehead, S., Berg, A.C., Lo, W.Y., Dollár, P., Girshick, R.: Segment anything. In: Int. Conf. Comput. Vis. (2023)
2023
-
[18]
Le, L., Xie, J., Liang, W., Wang, H.J., Yang, Y., Ma, Y.J., Vedder, K., Krishna, A., Jayaraman, D., Eaton, E.: Articulate-anything: Automatic modeling of articulated objects via a vision-language foundation model. In: Int. Conf. Learn. Represent. (2025)
2025
-
[19]
Lei, J., Deng, C., Shen, W.B., Guibas, L., Daniilidis, K.: Nap: Neural 3d articulated object prior. In: Adv. Neural Inform. Process. Syst. vol. 36, pp. 31878–31894 (2023)
2023
-
[20]
Li, R., Zheng, C., Rupprecht, C., Vedaldi, A.: Dragapart: Learning a part-level motion prior for articulated objects. In: Eur. Conf. Comput. Vis. pp. 165–183. Springer (2024)
2024
-
[21]
Li, R., Zheng, C., Rupprecht, C., Vedaldi, A.: Puppet-master: Scaling interactive video generation as a motion prior for part-level dynamics. In: Int. Conf. Comput. Vis. pp. 13405–13415 (2025)
2025
-
[22]
Liu, J., Iliash, D., Chang, A., Savva, M., Mahdavi Amiri, A.: Singapo: Single image controlled generation of articulated parts in objects. In: Int. Conf. Learn. Represent. (2025)
2025
-
[23]
Liu, J., Mahdavi-Amiri, A., Savva, M.: Paris: Part-level reconstruction and motion analysis for articulated objects. In: Int. Conf. Comput. Vis. pp. 352–363 (2023)
2023
-
[24]
In: IEEE Conf
Liu, J., Tam, H.I.I., Mahdavi-Amiri, A., Savva, M.: Cage: Controllable articulation generation. In: IEEE Conf. Comput. Vis. Pattern Recog. pp. 17880–17889 (2024)
2024
-
[25]
Liu, S., Gupta, S., Wang, S.: Building rearticulable models for arbitrary 3d objects from4dpointclouds.In:IEEEConf.Comput.Vis.PatternRecog.pp.21138–21147 (2023)
2023
-
[26]
arXiv preprint arXiv:2509.17647 (2025)
Liu, Y., Jia, B., Lu, R., Gan, C., Chen, H., Ni, J., Zhu, S.C., Huang, S.: Videoartgs: Building digital twins of articulated objects from monocular video. arXiv preprint arXiv:2509.17647 (2025)
-
[27]
Liu,Y.,Jia,B.,Lu,R.,Ni,J.,Zhu,S.C.,Huang,S.:Buildinginteractablereplicasof complex articulated objects via gaussian splatting. In: Int. Conf. Learn. Represent. (2025)
2025
-
[28]
arXiv preprint arXiv:2507.05763 (2025)
Lu, R., Liu, Y., Tang, J., Ni, J., Wang, Y., Wan, D., Zeng, G., Chen, Y., Huang, S.: Dreamart: Generating interactable articulated objects from a single image. arXiv preprint arXiv:2507.05763 (2025)
-
[29]
In: IEEE Conf
Mo, K., Zhu, S., Chang, A.X., Yi, L., Tripathi, S., Guibas, L.J., Su, H.: Part- net: A large-scale benchmark for fine-grained and hierarchical part-level 3d object understanding. In: IEEE Conf. Comput. Vis. Pattern Recog. pp. 909–918 (2019) PWM-ArtGen: Part World Model for Articulated Object Generation 17
2019
-
[30]
Mu, J., Qiu, W., Kortylewski, A., Yuille, A., Vasconcelos, N., Wang, X.: A-sdf: Learning disentangled signed distance functions for articulated shape representa- tion. In: Int. Conf. Comput. Vis. pp. 13001–13011 (2021)
2021
-
[31]
Oquab, M., Darcet, T., Moutakanni, T., Vo, H., Szafraniec, M., Khalidov, V., Fernandez, P., Haziza, D., Massa, F., El-Nouby, A., et al.: Dinov2: Learning robust visual features without supervision. Trans. Mach. Learn Res. (2024)
2024
-
[32]
In: International Conference on 3D Vision (3DV)
Peng, W., Lv, J., Lu, C., Savva, M.: itaco: Interactable digital twins of articulated objects from casually captured rgbd videos. In: International Conference on 3D Vision (3DV). pp. 520–531 (2026)
2026
-
[33]
In: IEEE/RSJ International Conference on Intelligent Robots and Systems
Shen, B., Xia, F., Li, C., Martín-Martín, R., Fan, L., Wang, G., Pérez-D’Arpino, C., Buch, S., Srivastava, S., Tchapmi, L., et al.: igibson 1.0: A simulation envi- ronment for interactive tasks in large realistic scenes. In: IEEE/RSJ International Conference on Intelligent Robots and Systems. pp. 7520–7527. IEEE (2021)
2021
-
[34]
In: IEEE Conf
Song, C., Wei, J., Foo, C.S., Lin, G., Liu, F.: Reacto: Reconstructing articulated objects from a single video. In: IEEE Conf. Comput. Vis. Pattern Recog. pp. 5384– 5395 (2024)
2024
-
[35]
Song, J., Meng, C., Ermon, S.: Denoising diffusion implicit models. In: Int. Conf. Learn. Represent. (2021)
2021
-
[36]
In: IEEE Conf
Su, J., Feng, Y., Li, Z., Song, J., He, Y., Ren, B., Xu, B.: Artformer: Controllable generation of diverse 3d articulated objects. In: IEEE Conf. Comput. Vis. Pattern Recog. pp. 1894–1904 (2025)
1904
-
[37]
In: International Conference on Robotics and Automa- tion
Tseng, W.C., Liao, H.J., Yen-Chen, L., Sun, M.: Cla-nerf: Category-level articu- lated neural radiance field. In: International Conference on Robotics and Automa- tion. pp. 8454–8460 (2022)
2022
-
[38]
In: IEEE Conf
Wang, X., Zhou, B., Shi, Y., Chen, X., Zhao, Q., Xu, K.: Shape2motion: Joint analysis of motion parts and attributes from 3d shapes. In: IEEE Conf. Comput. Vis. Pattern Recog. pp. 8876–8884 (2019)
2019
-
[39]
In: IEEE Conf
Weng, Y., Wen, B., Tremblay, J., Blukis, V., Fox, D., Guibas, L., Birchfield, S.: Neural implicit representation for building digital twins of unknown articulated objects. In: IEEE Conf. Comput. Vis. Pattern Recog. pp. 3141–3150 (2024)
2024
-
[40]
Wu, C., Li, J., Zhou, J., Lin, J., Gao, K., Yan, K., Yin, S.m., Bai, S., Xu, X., Chen, Y., et al.: Qwen-image technical report. arXiv preprint arXiv:2508.02324 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[41]
Wu, H., Jing, Y., Cheang, C., Chen, G., Xu, J., Li, X., Liu, M., Li, H., Kong, T.: Unleashing large-scale video generative pre-training for visual robot manipulation. In: Int. Conf. Learn. Represent. (2024)
2024
-
[42]
Wu, R., wang, X., Liu.Liu, Guo, C.L., Qiu, J., Li, C., Huang, L., Su, Z., Cheng, M.M.: Dipo: Dual-state images controlled articulated object generation powered by diverse data. In: Adv. Neural Inform. Process. Syst. vol. 38, pp. 108665–108689 (2025)
2025
-
[43]
arXiv preprint arXiv:2603.16806 (2026)
Wu, Y., Lin, Y., Lao, W., Lin, Y., Wei, Y.L., Zheng, W.S., Wu, A.: Dexgrasp-zero: A morphology-aligned policy for zero-shot cross-embodiment dexterous grasping. arXiv preprint arXiv:2603.16806 (2026)
-
[44]
In: IEEE Conf
Xiang, F., Qin, Y., Mo, K., Xia, Y., Zhu, H., Liu, F., Liu, M., Jiang, H., Yuan, Y., Wang, H., Yi, L., Chang, A.X., Guibas, L.J., Su, H.: Sapien: A simulated part- based interactive environment. In: IEEE Conf. Comput. Vis. Pattern Recog. pp. 11094–11104 (2020)
2020
-
[45]
ACM Trans
Yan, Z., Hu, R., Yan, X., Chen, L., Van Kaick, O., Zhang, H., Huang, H.: Rpm-net: recurrent prediction of motion and parts from point cloud. ACM Trans. Graph. 38(6), 1–15 (2019) 18 W. Zheng and A. Wu
2019
-
[46]
Yu, S., Kwak, S., Jang, H., Jeong, J., Huang, J., Shin, J., Xie, S.: Representation alignment for generation: Training diffusion transformers is easier than you think. In: Int. Conf. Learn. Represent. (2025)
2025
-
[47]
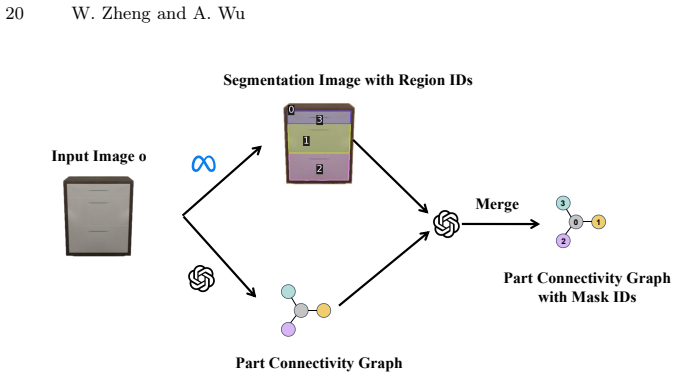
base". • 2) Describe how the parts are connected and then organize them in a part connectivity graph. The
Zhu, C., Yu, R., Feng, S., Burchfiel, B., Shah, P., Gupta, A.: Unified world models: Coupling video and action diffusion for pretraining on large robotic datasets. In: Proceedings of Robotics: Science and Systems (2025) PWM-ArtGen: Part World Model for Articulated Object Generation 19 Our supplementary materials provide comprehensive implementation detail...
2025
-
[48]
A segmentation image with region IDs
-
[49]
base\": [{\
A part connectivity graph (containing only: 'base', 'door', 'drawer') where: - There is exactly one base. - All doors and drawers attach directly to the base. - The child order in the graph already reflects spatial ordering and must be preserved. An example of part connectivity graph: I recognize all the articulated parts in a storage furniture, they are:...
-
[50]
Do NOT create or renumber IDs
Use only region IDs that appear in the segmentation result. Do NOT create or renumber IDs
-
[51]
Each region ID belongs to exactly one part instance (no overlaps)
-
[52]
If a single part spans multiple region IDs, include all of them in that part’s `ids` array. Here is an example of your response: I recognize all the articulated parts of a storage furniture, I recognize all the articulated parts in a storage furniture, they are: base[<ids>], door[<ids>] (attach to base), drawer[<ids>] (attach to base). ```json {"base": {"...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.