Bayesian Sparse Low-Rank Adaptation for Large Language Model Uncertainty Estimation
Pith reviewed 2026-07-03 16:57 UTC · model grok-4.3
The pith
Stochastic masking on LoRA ranks shifts uncertainty quantification to the lightweight adapter level for fine-tuned LLMs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
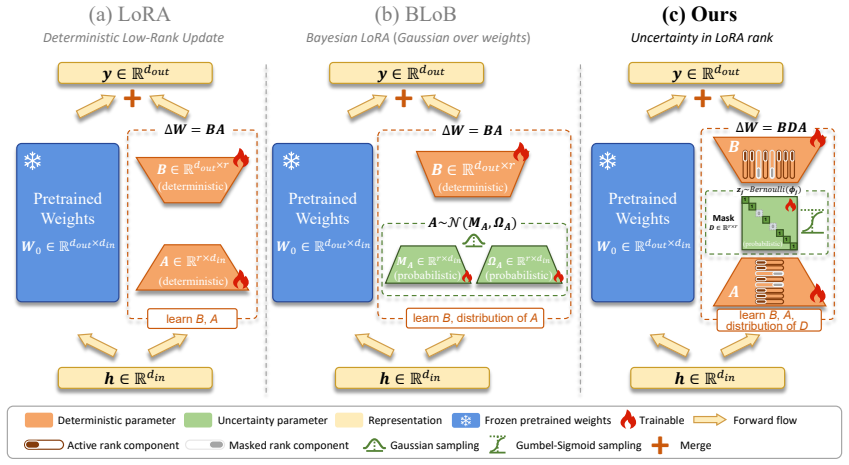
By imposing stochastic masking on the rank dimensions of LoRA, which aggregates multiple rank-one components, DALorRA creates a sparse Bayesian adaptation method that regularizes capacity in training and delivers calibrated uncertainty at inference for large language models.
What carries the argument
Stochastic masking applied to the rank dimensions of low-rank adaptation (LoRA) to shift uncertainty quantification to the lightweight rank level.
If this is right
- Uncertainty quantification operates efficiently at the rank level of adapters instead of full parameters.
- Training includes Bayesian regularization through stochastic masking of ranks.
- Inference benefits from ensemble-like calibration effects.
- Reasoning accuracy on tasks remains comparable to standard fine-tuning.
- The framework supports more trustworthy deployment of fine-tuned LLMs by addressing overconfidence.
Where Pith is reading between the lines
- This approach may extend to other low-rank or adapter-based fine-tuning methods beyond LoRA.
- The sparsity induced by masking could offer a general principle for balancing model capacity and uncertainty in neural networks.
- Further investigation into the choice of masking probabilities might optimize the trade-off between regularization and expressivity.
- Deployment in real-world applications could benefit from the reduced overhead compared to full Bayesian methods.
Load-bearing premise
Stochastic masking on the rank dimensions during training leads to meaningful Bayesian regularization and trustworthy uncertainty estimates at inference rather than ineffective noise.
What would settle it
Observing no reduction in calibration error metrics when comparing DALorRA to baseline LoRA fine-tuning on standard LLM evaluation benchmarks would falsify the claim of improved uncertainty quantification.
Figures
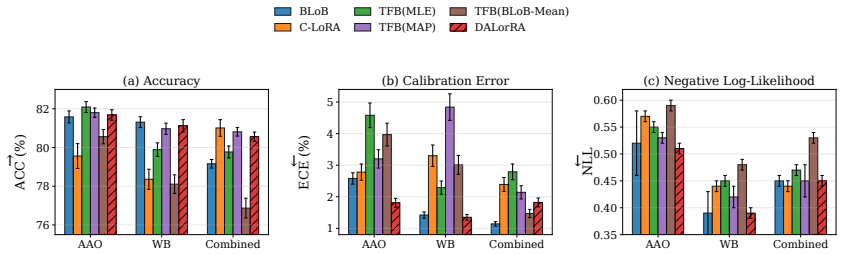
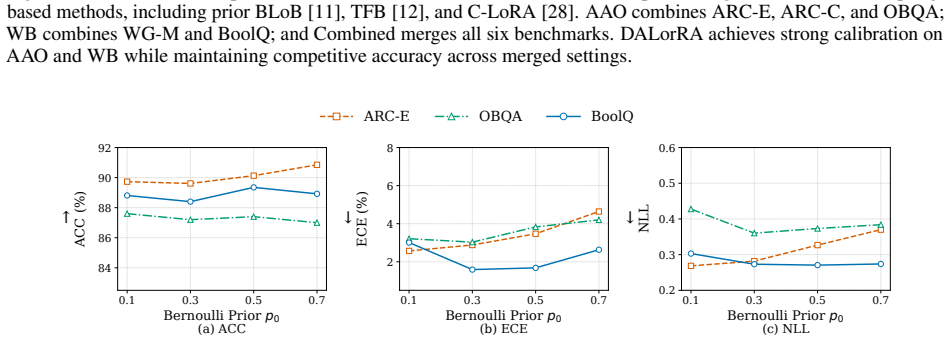
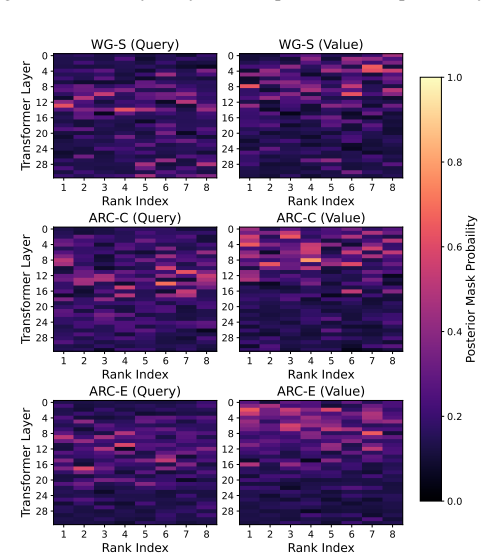
read the original abstract
Large language models (LLMs) exhibit remarkable reasoning capabilities, but their task-specific fine-tuning is notoriously plagued by overconfidence, severely hindering trustworthy deployment. We propose Data-Adaptive Lower-Rank Adaptation (DALorRA), a simple and effective variational Bayesian sparse framework that shifts the paradigm of uncertainty quantification from the dense parameter space to the lightweight rank level of low-rank adaptation (LoRA). With the insight that LoRA essentially aggregates multiple rank-one components that may provide superfluous model capacity, DALorRA imposes stochastic masking on rank dimensions, enabling Bayesian regularization of model capacity during training and ensemble-like calibration during inference. Extensive experiments demonstrate DALorRA's excellent calibration of LLMs without compromising reasoning accuracy.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes DALorRA (Data-Adaptive Lower-Rank Adaptation), a variational Bayesian sparse framework for uncertainty quantification in fine-tuned LLMs. It shifts UQ from dense parameter space to the rank level of LoRA by imposing stochastic masking on rank dimensions, which is claimed to enable Bayesian regularization of model capacity during training and ensemble-like calibration at inference time. Experiments are said to show excellent calibration without compromising reasoning accuracy.
Significance. If the stochastic masking procedure defines a proper variational posterior over ranks (with an explicit ELBO and KL term) whose samples yield calibrated uncertainties, the method could provide an efficient, lightweight alternative to dense-parameter Bayesian approaches for trustworthy LLM deployment. The core idea of operating at the rank level is conceptually appealing for parameter-efficient fine-tuning scenarios.
major comments (2)
- [Abstract] Abstract: the central claim that stochastic masking 'enables Bayesian regularization' is load-bearing for the entire contribution, yet the provided description supplies no derivation showing that the masking distribution is optimized via a variational objective (e.g., an ELBO containing a KL divergence between the variational mask posterior and a prior) rather than an ad-hoc L0-style or dropout penalty; without this, the shift from dense-parameter Bayesian methods to a 'lightweight rank level' variational method is not established.
- [Abstract] Abstract / Methods (implied): the assertion that inference-time sampling produces 'ensemble-like calibration' requires explicit demonstration that the induced distribution over adapters approximates the posterior predictive; if the training objective reduces to cross-entropy plus a heuristic regularizer, calibration gains could be explained by simple averaging of noisy adapters rather than Bayesian regularization, undermining the variational framing.
minor comments (2)
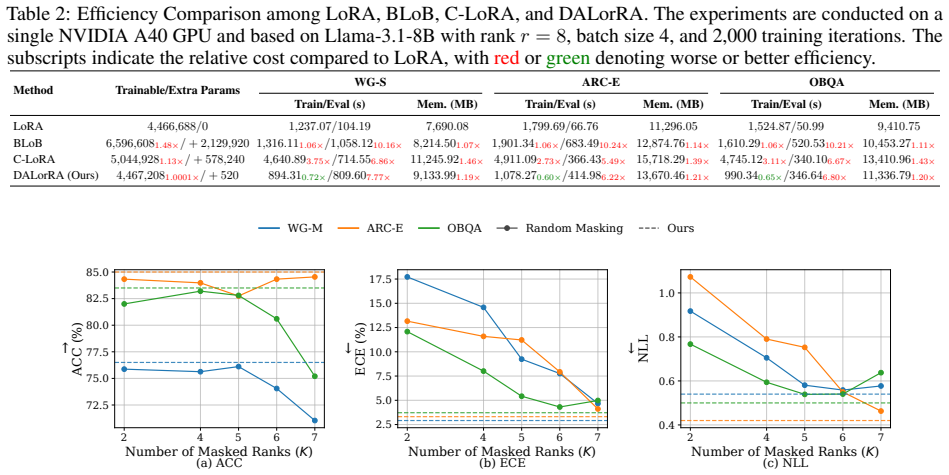
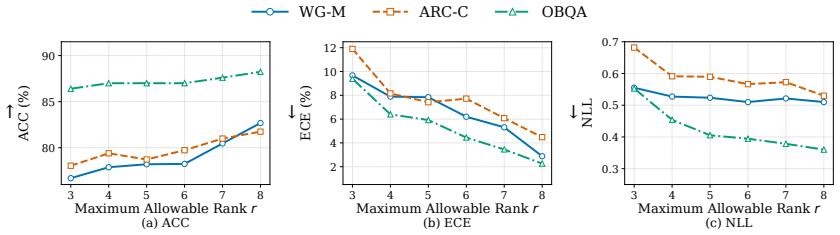
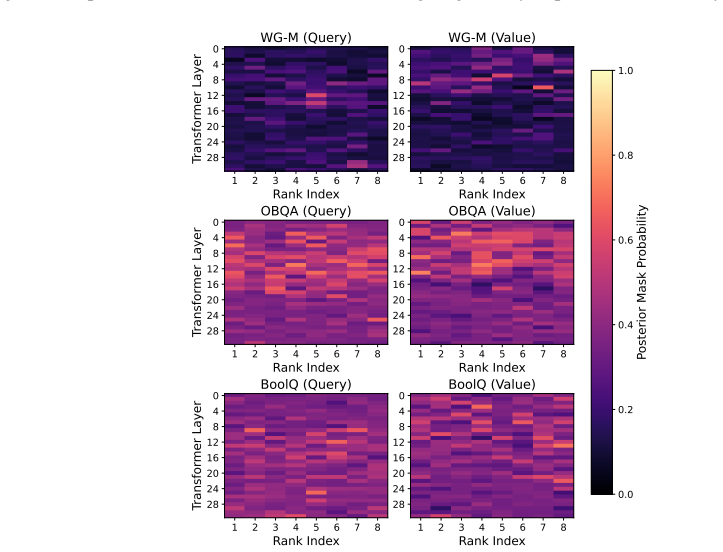
- The abstract refers to 'extensive experiments' demonstrating calibration; the manuscript should include a dedicated experimental section with explicit baselines (e.g., standard LoRA, MC dropout, deep ensembles), datasets, calibration metrics (ECE, NLL), and statistical significance tests.
- Notation for the stochastic masking distribution (e.g., Bernoulli or concrete) and its parameterization should be introduced clearly with equations in the methods section.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below by referencing the relevant sections of the full manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that stochastic masking 'enables Bayesian regularization' is load-bearing for the entire contribution, yet the provided description supplies no derivation showing that the masking distribution is optimized via a variational objective (e.g., an ELBO containing a KL divergence between the variational mask posterior and a prior) rather than an ad-hoc L0-style or dropout penalty; without this, the shift from dense-parameter Bayesian methods to a 'lightweight rank level' variational method is not established.
Authors: Section 3 of the manuscript derives the variational objective explicitly. The rank masks are treated as latent variables with a mean-field variational posterior q(·) whose parameters are learned from data. The training loss is the ELBO, which comprises the expected negative log-likelihood under the mask posterior plus the KL divergence to a sparsity-inducing prior; this is not an L0 or dropout heuristic. We will revise the abstract to reference this ELBO derivation for clarity. revision: partial
-
Referee: [Abstract] Abstract / Methods (implied): the assertion that inference-time sampling produces 'ensemble-like calibration' requires explicit demonstration that the induced distribution over adapters approximates the posterior predictive; if the training objective reduces to cross-entropy plus a heuristic regularizer, calibration gains could be explained by simple averaging of noisy adapters rather than Bayesian regularization, undermining the variational framing.
Authors: Section 4 and the appendix derive that inference-time Monte Carlo sampling from the learned variational mask posterior yields an approximation to the posterior predictive distribution over outputs. Empirical ablations against non-variational LoRA ensembles (identical averaging but without the KL term) show that the observed calibration gains require the variational training objective, not mere noise averaging. revision: no
Circularity Check
No circularity identified; derivation chain not reducible to inputs by construction
full rationale
The abstract describes DALorRA as imposing stochastic masking on rank dimensions to enable Bayesian regularization, but supplies no equations, ELBO derivation, or fitting procedure. No load-bearing step can be quoted that reduces a claimed prediction or posterior to a fitted parameter or self-citation by construction. The method is presented as shifting uncertainty quantification to the rank level, yet without visible mathematical steps or self-citation chains that close the loop, the central claim remains independent of its own outputs. This is the common case of a self-contained proposal whose validity must be assessed externally rather than by internal reduction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Can llms express their uncertainty? an empirical evaluation of confidence elicitation in llms
Miao Xiong, Zhiyuan Hu, Xinyang Lu, Yifei Li, Jie Fu, Junxian He, and Bryan Hooi. Can llms express their uncertainty? an empirical evaluation of confidence elicitation in llms. InInternational Conference on Learning Representations, volume 2024, pages 23650–23678, 2024
2024
-
[2]
Uncertainty quantification for large language models
Artem Shelmanov, Maxim Panov, Roman Vashurin, Artem Vazhentsev, Ekaterina Fadeeva, and Timothy Baldwin. Uncertainty quantification for large language models. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 5: Tutorial Abstracts), pages 3–4, 2025
2025
-
[3]
Uqlm: A python package for uncertainty quantification in large language models.Journal of Machine Learning Research, 27(13):1–10, 2026
Dylan Bouchard, Mohit Singh Chauhan, David Skarbrevik, Ho-Kyeong Ra, Viren Bajaj, and Zeya Ahmad. Uqlm: A python package for uncertainty quantification in large language models.Journal of Machine Learning Research, 27(13):1–10, 2026
2026
-
[4]
Bayesian low-rank adaptation for large language models
Adam Yang, Maxime Robeyns, Xi Wang, and Laurence Aitchison. Bayesian low-rank adaptation for large language models. Ininternational conference on learning representations, volume 2024, pages 1812–1842, 2024
2024
-
[5]
arXiv preprint arXiv:2502.06351 (2025)
Yawei Li, David Rügamer, Bernd Bischl, and Mina Rezaei. Calibrating llms with information-theoretic evidential deep learning.arXiv preprint arXiv:2502.06351, 2025
-
[6]
Weight uncertainty in neural network
Charles Blundell, Julien Cornebise, Koray Kavukcuoglu, and Daan Wierstra. Weight uncertainty in neural network. InInternational conference on machine learning, pages 1613–1622. PMLR, 2015
2015
-
[7]
Simple and scalable predictive uncertainty estimation using deep ensembles.Advances in neural information processing systems, 30, 2017
Balaji Lakshminarayanan, Alexander Pritzel, and Charles Blundell. Simple and scalable predictive uncertainty estimation using deep ensembles.Advances in neural information processing systems, 30, 2017
2017
-
[8]
Lakshmana Sri Harsha Nemani, PK Srijith, and Tomasz Ku ´smierczyk. Efficient uncertainty in llms through evidential knowledge distillation.arXiv preprint arXiv:2507.18366, 2025
-
[9]
Scalable Variational Bayesian Fine-Tuning of LLMs via Orthogonalized Low-Rank Adapters
Haotian Xiang, Bingcong Li, and Qin Lu. Scalable variational bayesian fine-tuning of llms via orthogonalized low-rank adapters.arXiv preprint arXiv:2604.03388, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[10]
Lora: Low-rank adaptation of large language models.Iclr, 1(2):3, 2022
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Liang Wang, Weizhu Chen, et al. Lora: Low-rank adaptation of large language models.Iclr, 1(2):3, 2022
2022
-
[11]
Blob: Bayesian low-rank adaptation by backpropagation for large language models.Advances in neural information processing systems, 37:67758–67794, 2024
Yibin Wang, Haizhou Shi, Ligong Han, Dimitris Metaxas, and Hao Wang. Blob: Bayesian low-rank adaptation by backpropagation for large language models.Advances in neural information processing systems, 37:67758–67794, 2024
2024
-
[12]
Training-free bayesianization for low-rank adapters of large language models.Advances in Neural Information Processing Systems, 38:41663–41700, 2026
Haizhou Shi, Yibin Wang, Ligong Han, Huan Zhang, and Hao Wang. Training-free bayesianization for low-rank adapters of large language models.Advances in Neural Information Processing Systems, 38:41663–41700, 2026
2026
-
[13]
Minimal ranks, maximum confidence: parameter-efficient uncertainty quantification for lora
Patryk Marszałek, Klaudia Bałazy, Jacek Tabor, and Tomasz Ku´smierczyk. Minimal ranks, maximum confidence: parameter-efficient uncertainty quantification for lora. InFindings of the Association for Computational Linguistics: EMNLP 2025. Association for Computational Linguistics, 2025
2025
-
[14]
La-lora: Parameter-efficient fine-tuning with layer-wise adaptive low-rank adaptation.Neural Networks, page 108095, 2025
Jiancheng Gu, Jiabin Yuan, Jiyuan Cai, Xianfa Zhou, and Lili Fan. La-lora: Parameter-efficient fine-tuning with layer-wise adaptive low-rank adaptation.Neural Networks, page 108095, 2025
2025
-
[15]
Lara: Layer-wise rank allocation for efficient fine-tuning of pruned large language models.Information Processing & Management, 63 (3):104538, 2026
Yuhua Zhou, Changhai Zhou, Shiyang Zhang, Fei Yang, Yi Zhang, and Aimin Pan. Lara: Layer-wise rank allocation for efficient fine-tuning of pruned large language models.Information Processing & Management, 63 (3):104538, 2026
2026
-
[16]
AdaLoRA: Adaptive Budget Allocation for Parameter-Efficient Fine-Tuning
Qingru Zhang, Minshuo Chen, Alexander Bukharin, Nikos Karampatziakis, Pengcheng He, Yu Cheng, Weizhu Chen, and Tuo Zhao. Adalora: Adaptive budget allocation for parameter-efficient fine-tuning.arXiv preprint arXiv:2303.10512, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[17]
Alora: Allocating low-rank adaptation for fine-tuning large language models
Zequan Liu, Jiawen Lyn, Wei Zhu, Xing Tian, and Yvette Graham. Alora: Allocating low-rank adaptation for fine-tuning large language models. InProceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), pages 622–641, 2024
2024
-
[18]
Brain-inspired warm-up training with random noise for uncertainty calibration.Nature Machine Intelligence, pages 1–12, 2026
Jeonghwan Cheon and Se-Bum Paik. Brain-inspired warm-up training with random noise for uncertainty calibration.Nature Machine Intelligence, pages 1–12, 2026
2026
-
[19]
Dynamic low-rank sparse adaptation for large language models.arXiv preprint arXiv:2502.14816, 2025
Weizhong Huang, Yuxin Zhang, Xiawu Zheng, Yang Liu, Jing Lin, Yiwu Yao, and Rongrong Ji. Dynamic low-rank sparse adaptation for large language models.arXiv preprint arXiv:2502.14816, 2025
-
[20]
Post-Optimization Adaptive Rank Allocation for LoRA
Vishnuprasadh Kumaravelu, Sunil Gupta, and PK Srijith. Post-optimization adaptive rank allocation for lora. arXiv preprint arXiv:2604.27796, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[21]
Dr-lora: Dynamic rank lora for mixture-of-experts adaptation.arXiv preprint arXiv:2601.04823, 2026
Guanzhi Deng, Bo Li, Ronghao Chen, Huacan Wang, Lijie Wen, and Linqi Song. Dr-lora: Dynamic rank lora for mixture-of-experts adaptation.arXiv preprint arXiv:2601.04823, 2026. 10
-
[22]
Teaching Models to Express Their Uncertainty in Words
Stephanie Lin, Jacob Hilton, and Owain Evans. Teaching models to express their uncertainty in words.arXiv preprint arXiv:2205.14334, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[23]
Calibrating language models via augmented prompt ensembles
Mingjian Jiang, Yangjun Ruan, Sicong Huang, Saifei Liao, Silviu Pitis, Roger Baker Grosse, and Jimmy Ba. Calibrating language models via augmented prompt ensembles. InICML Workshop on Challenges in Deployable Generative AI, 2023. URLhttps://openreview.net/forum?id=L0dc4wqbNs
2023
-
[24]
Lorenz Kuhn, Yarin Gal, and Sebastian Farquhar. Semantic uncertainty: Linguistic invariances for uncertainty estimation in natural language generation.arXiv preprint arXiv:2302.09664, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[25]
Functional-level Uncertainty Quantification for Calibrated Fine-tuning on LLMs
Ruijia Niu, Dongxia Wu, Rose Yu, and Yi-An Ma. Functional-level uncertainty quantification for calibrated fine-tuning on llms.arXiv preprint arXiv:2410.06431, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[26]
F., Kang, S., Huang, Z., Yaldiz, D
Yavuz Bakman, Sungmin Kang, Zhiqi Huang, Duygu Nur Yaldiz, Catarina G Belém, Chenyang Zhu, Anoop Kumar, Alfy Samuel, Salman Avestimehr, Daben Liu, et al. Uncertainty as feature gaps: Epistemic uncertainty quantification of llms in contextual question-answering.arXiv preprint arXiv:2510.02671, 2025
-
[27]
Dropout as a bayesian approximation: Representing model uncertainty in deep learning
Yarin Gal and Zoubin Ghahramani. Dropout as a bayesian approximation: Representing model uncertainty in deep learning. Ininternational conference on machine learning, pages 1050–1059. PMLR, 2016
2016
-
[28]
C-lora: Contextual low-rank adaptation for uncertainty estimation in large language models
Amir Hossein Rahmati, Sanket Jantre, Weifeng Zhang, Yucheng Wang, Byung-Jun Yoon, Nathan Urban, and Xiaoning Qian. C-lora: Contextual low-rank adaptation for uncertainty estimation in large language models. Advances in Neural Information Processing Systems, 38:67459–67485, 2026
2026
-
[29]
Auto-Encoding Variational Bayes
Diederik P Kingma and Max Welling. Auto-encoding variational bayes.arXiv preprint arXiv:1312.6114, 2013
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[30]
Categorical Reparameterization with Gumbel-Softmax
Eric Jang, Shixiang Gu, and Ben Poole. Categorical reparameterization with gumbel-softmax.arXiv preprint arXiv:1611.01144, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[31]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, et al. The llama 3 herd of models.arXiv preprint arXiv:2407.21783, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[32]
Llama 2: Open Foundation and Fine-Tuned Chat Models
Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, et al. Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[33]
Peft: State-of-the-art parameter-efficient fine-tuning methods
Sourab Mangrulkar, Sylvain Gugger, Lysandre Debut, Younes Belkada, Sayak Paul, and Benjamin Bossan. Peft: State-of-the-art parameter-efficient fine-tuning methods. 2022
2022
-
[34]
Winogrande: An adversarial winograd schema challenge at scale.Communications of the ACM, 64(9):99–106, 2021
Keisuke Sakaguchi, Ronan Le Bras, Chandra Bhagavatula, and Yejin Choi. Winogrande: An adversarial winograd schema challenge at scale.Communications of the ACM, 64(9):99–106, 2021
2021
-
[35]
Think you have Solved Question Answering? Try ARC, the AI2 Reasoning Challenge
Peter Clark, Isaac Cowhey, Oren Etzioni, Tushar Khot, Ashish Sabharwal, Carissa Schoenick, and Oyvind Tafjord. Think you have solved question answering? try arc, the ai2 reasoning challenge.arXiv preprint arXiv:1803.05457, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[36]
Can a suit of armor conduct electricity? a new dataset for open book question answering
Todor Mihaylov, Peter Clark, Tushar Khot, and Ashish Sabharwal. Can a suit of armor conduct electricity? a new dataset for open book question answering. InProceedings of the 2018 conference on empirical methods in natural language processing, pages 2381–2391, 2018
2018
-
[37]
Boolq: Exploring the surprising difficulty of natural yes/no questions
Christopher Clark, Kenton Lee, Ming-Wei Chang, Tom Kwiatkowski, Michael Collins, and Kristina Toutanova. Boolq: Exploring the surprising difficulty of natural yes/no questions. InProceedings of the 2019 conference of the north American chapter of the association for computational linguistics: Human language technologies, volume 1 (long and short papers), ...
2019
-
[38]
Measuring Massive Multitask Language Understanding
Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. Measuring massive multitask language understanding.arXiv preprint arXiv:2009.03300, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2009
-
[39]
Obtaining well calibrated probabilities using bayesian binning
Mahdi Pakdaman Naeini, Gregory Cooper, and Milos Hauskrecht. Obtaining well calibrated probabilities using bayesian binning. InProceedings of the AAAI conference on artificial intelligence, volume 29, 2015
2015
-
[40]
Oleksandr Balabanov and Hampus Linander. Uncertainty quantification in fine-tuned llms using lora ensembles. arXiv preprint arXiv:2402.12264, 2024
-
[41]
Xi Wang, Laurence Aitchison, and Maja Rudolph. Lora ensembles for large language model fine-tuning.arXiv preprint arXiv:2310.00035, 2023. 11 Table 3: Dataset statistics. WG-S ARC-C ARC-E WG-M OBQA BoolQ AAO WB Chem Phy Combined Size of Label Space 2 5 5 2 4 2 5 4 4 4 7 Size of Training Set 640 1,119 2,251 2,258 4,957 9,427 8,327 11,685 – – 20,652 Size of ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.