Visually Grounded Self-Reflection for Vision-Language Models via Reinforcement Learning
Pith reviewed 2026-07-03 14:15 UTC · model grok-4.3
The pith
Reinforcement learning with masked prefixes and replay buffers trains vision-language models to ground self-reflection in visual inputs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
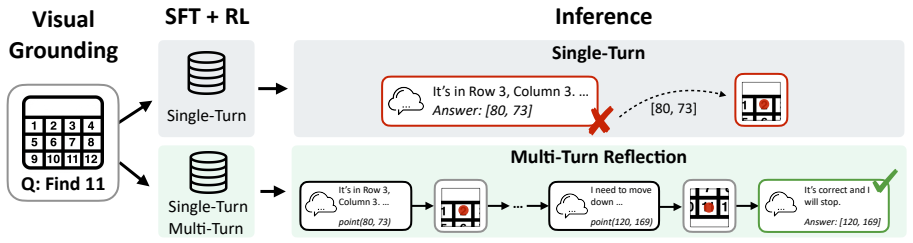
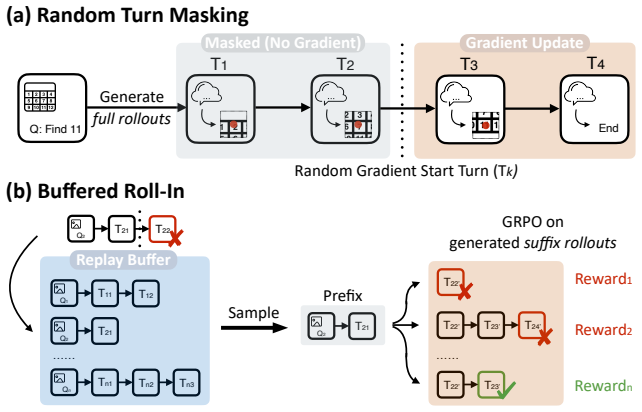
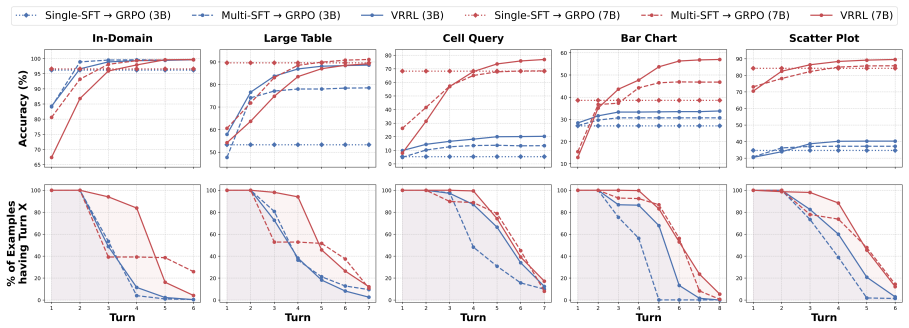
The central claim is that a reinforcement learning training framework called VRRL, using randomly masked trajectory prefixes and buffered roll-ins from an experience replay buffer, elicits visually grounded self-reflection in vision-language models and thereby substantially improves average out-of-distribution accuracy over standard RL and reflection-oriented fine-tuning baselines on visual grounding tasks.
What carries the argument
VRRL, the reinforcement learning framework that randomly masks trajectory prefixes to emphasize recovery from incorrect predictions and samples from an experience replay buffer to expose the model to diverse failure states.
If this is right
- Models will translate feedback into corrections grounded in the actual image content rather than text patterns.
- Accuracy on table, chart, and spatial navigation tasks will remain higher when images come from a shifted distribution.
- Off-the-shelf and conventionally fine-tuned models will continue to degrade under shift while VRRL-trained models improve.
- Self-reflection will become a mechanism for grounded error recovery instead of ungrounded textual revision.
Where Pith is reading between the lines
- The same masking and replay approach could be tested on other multimodal reasoning settings such as diagram-based math or video question answering.
- If the method works by increasing visual attention, it might combine with attention-regularization losses for further gains.
- The technique could reduce the amount of in-distribution data needed to maintain performance on new image styles.
- Failure cases where the model still ignores the image would point to limits in how much replay alone can enforce grounding.
Load-bearing premise
Randomly masking prefixes and sampling from a replay buffer will cause the model to attend to visual inputs during reflection rather than learning textual recovery patterns.
What would settle it
Measure visual attention during the reflection phase on out-of-distribution images; if VRRL models show no higher visual attention or no accuracy gain over baselines, the claim fails.
Figures
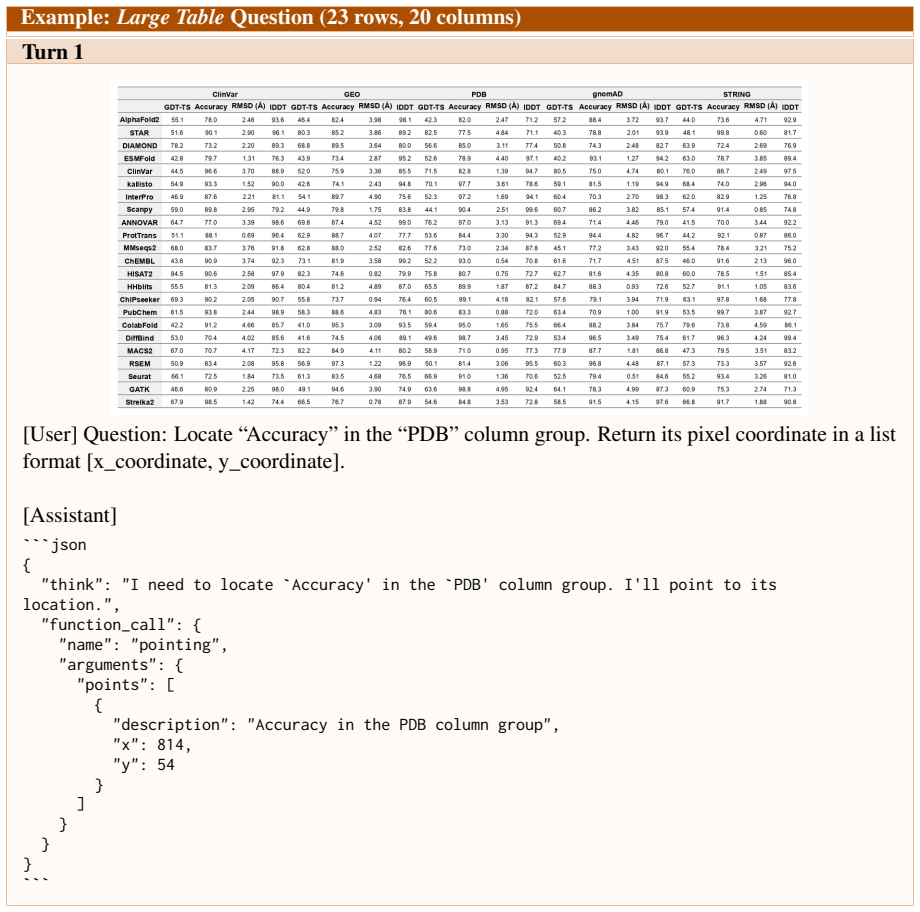

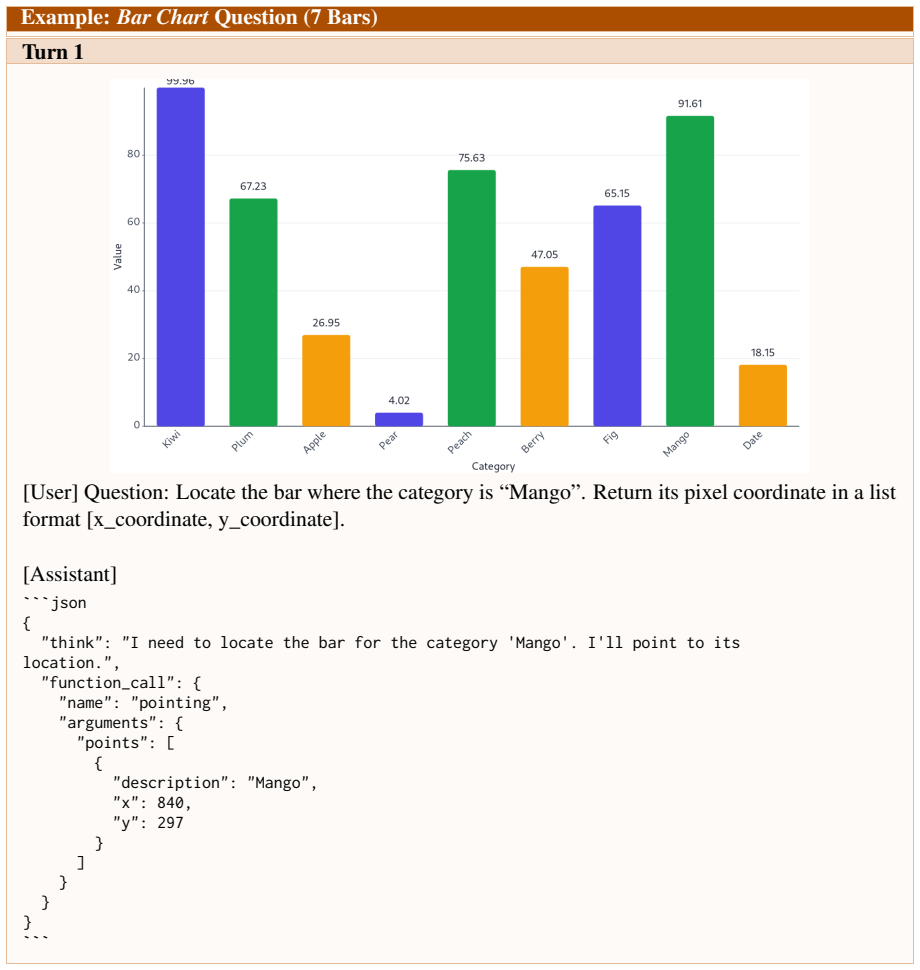


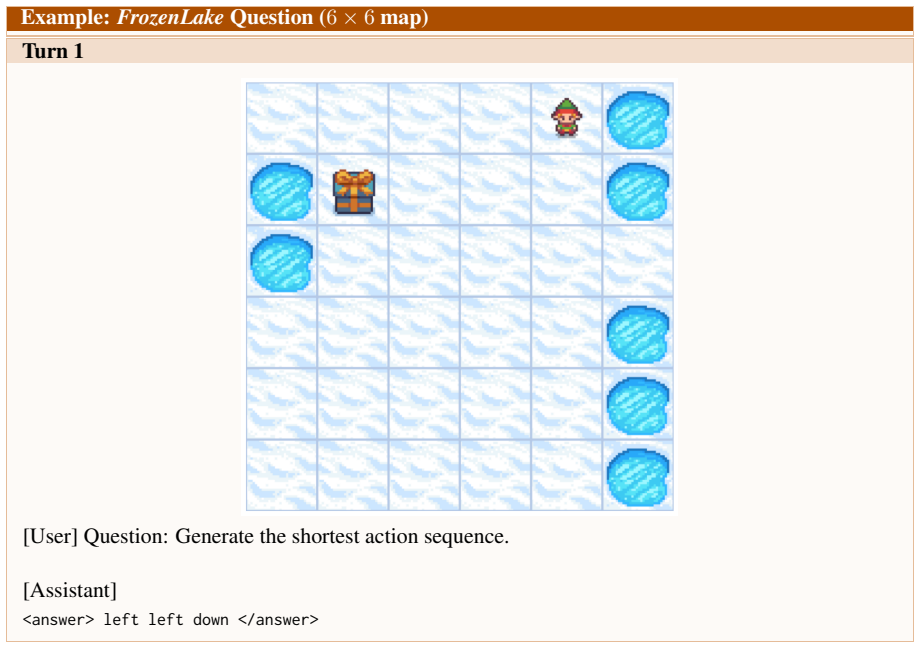
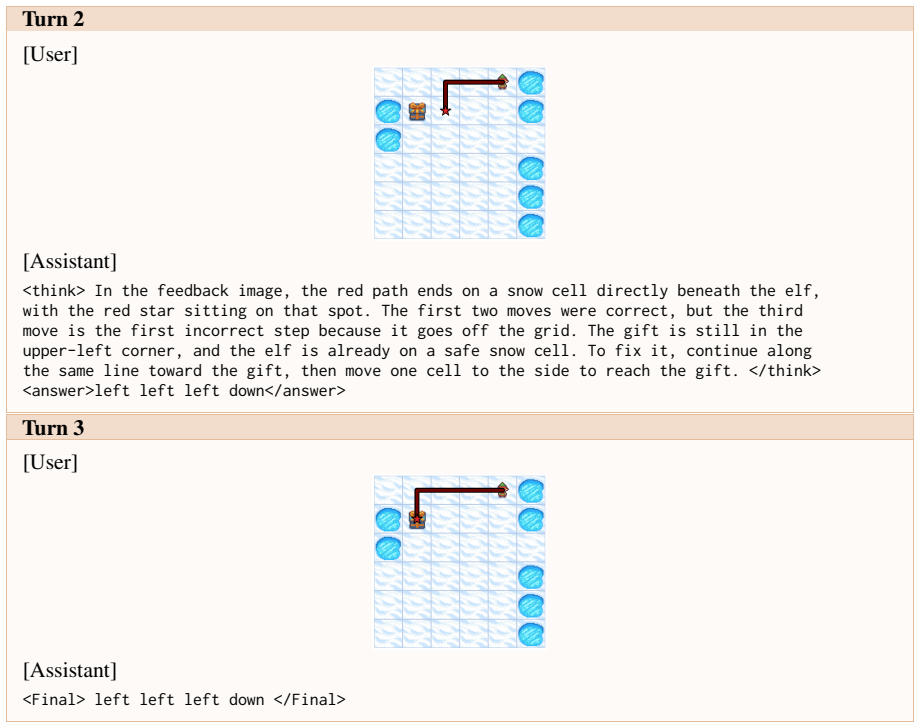
read the original abstract
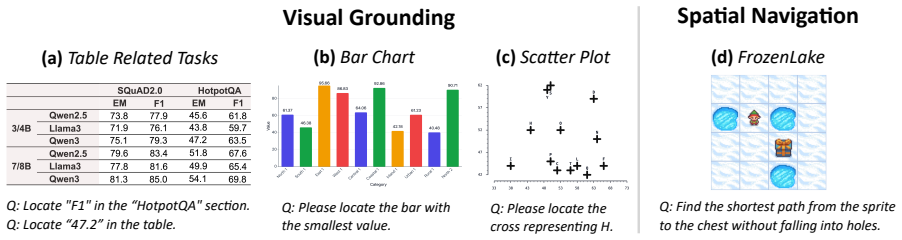
Large vision-language models can reason over multimodal inputs by generating textual chains of thought (CoT). A key capability exhibited in CoT reasoning is self-reflection: revisiting earlier decisions and correcting previous errors. However, existing LVLMs often fail to properly attend to visual inputs during reflection, limiting their ability to translate feedback into grounded corrections, especially for out-of-distribution images. To address this issue, we propose a novel reinforcement learning training framework VRRL, with two components explicitly designed to elicit visually grounded self-reflection. First, we randomly mask trajectory prefixes during training to emphasize recovery from incorrect intermediate predictions rather than making early mistakes. Second, we introduce buffered roll-ins from an experience replay buffer to expose the model to diverse failure states that it must learn to correct. We evaluate our approach on visual grounding tasks involving tables and charts, as well as spatial navigation benchmarks. While off-the-shelf and conventionally fine-tuned models degrade substantially under distribution shift, our method substantially improves average out-of-distribution accuracy over standard RL and reflection-oriented fine-tuning baselines by using self-reflection effectively.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes VRRL, a reinforcement learning framework for vision-language models to elicit visually grounded self-reflection. It introduces two components: random masking of trajectory prefixes to emphasize recovery from incorrect intermediate predictions, and buffered roll-ins from an experience replay buffer to expose the model to diverse failure states. The approach is evaluated on visual grounding tasks involving tables/charts and spatial navigation benchmarks, with the claim that it substantially improves average out-of-distribution accuracy over standard RL and reflection-oriented fine-tuning baselines by using self-reflection effectively.
Significance. If the OOD gains are shown to result specifically from visually grounded reflection (rather than textual recovery heuristics), the work could help address robustness limitations in current VLMs under distribution shift for multimodal reasoning. The RL-based training procedure with explicit recovery mechanisms is a direct response to observed failures in CoT-style reflection.
major comments (2)
- [Abstract] Abstract: The central claim of 'substantially improves average out-of-distribution accuracy ... by using self-reflection effectively' is presented without any quantitative metrics, dataset sizes, statistical significance tests, or ablation results. This makes it impossible to assess the magnitude or reliability of the reported gains.
- [Method and Experimental Evaluation] Method (training procedure) and Experimental Evaluation: The prefix-masking and replay-buffer mechanisms are compatible with purely textual error-recovery learning. No ablation is described that removes or corrupts visual features specifically during the reflection phase, no attention-map analysis compares visual vs. textual focus during reflection, and no text-only trajectory control is reported. Without such isolation, the OOD gains cannot be attributed to visual grounding rather than textual heuristics.
minor comments (1)
- [Abstract] Abstract: The statement that 'off-the-shelf and conventionally fine-tuned models degrade substantially under distribution shift' lacks specific baseline names or degradation magnitudes.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address the major comments point by point below.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim of 'substantially improves average out-of-distribution accuracy ... by using self-reflection effectively' is presented without any quantitative metrics, dataset sizes, statistical significance tests, or ablation results. This makes it impossible to assess the magnitude or reliability of the reported gains.
Authors: We agree that the abstract should include quantitative details to support the central claim. In the revised version, we will update the abstract to report the specific average OOD accuracy gains (with percentages), evaluation dataset sizes, and references to statistical significance and ablations from the main text. revision: yes
-
Referee: [Method and Experimental Evaluation] Method (training procedure) and Experimental Evaluation: The prefix-masking and replay-buffer mechanisms are compatible with purely textual error-recovery learning. No ablation is described that removes or corrupts visual features specifically during the reflection phase, no attention-map analysis compares visual vs. textual focus during reflection, and no text-only trajectory control is reported. Without such isolation, the OOD gains cannot be attributed to visual grounding rather than textual heuristics.
Authors: We acknowledge this is a valid point and a limitation of the current experiments. The mechanisms could in principle apply to text-only settings, and we lack explicit isolations of the visual modality during reflection. We will add the requested elements in revision: an ablation corrupting visual features during reflection, attention-map comparisons of visual vs. textual focus, and a text-only control where feasible. These will be used to better attribute gains to visual grounding. revision: yes
Circularity Check
No circularity: empirical RL procedure with no derivations or load-bearing self-citations
full rationale
The paper proposes VRRL, an RL training framework using random prefix masking and experience replay buffer roll-ins to elicit visually grounded self-reflection. No equations, mathematical derivations, or parameter-fitting steps are present. Central claims rest on reported OOD accuracy improvements versus baselines, framed as experimental outcomes rather than reductions to inputs by construction. No self-citation chains or uniqueness theorems are invoked to justify the method. The derivation chain is self-contained as an empirical contribution.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Attention is All you Need , url =
Vaswani, Ashish and Shazeer, Noam and Parmar, Niki and Uszkoreit, Jakob and Jones, Llion and Gomez, Aidan N and Kaiser, ukasz and Polosukhin, Illia , booktitle =. Attention is All you Need , url =
-
[2]
2025 , eprint=
Qwen3-VL Technical Report , author=. 2025 , eprint=
2025
-
[3]
2025 , eprint=
Towards Understanding Visual Grounding in Visual Language Models , author=. 2025 , eprint=
2025
-
[4]
ArXiv , year=
Exploring Grounding Potential of VQA-oriented GPT-4V for Zero-shot Anomaly Detection , author=. ArXiv , year=
-
[5]
The Fourteenth International Conference on Learning Representations , year=
Grounding Computer Use Agents on Human Demonstrations , author=. The Fourteenth International Conference on Learning Representations , year=
-
[6]
Proceedings of the Asian Conference on Computer Vision , pages=
Vision language models are blind , author=. Proceedings of the Asian Conference on Computer Vision , pages=
-
[7]
2026 , eprint=
OfficeQA Pro: An Enterprise Benchmark for End-to-End Grounded Reasoning , author=. 2026 , eprint=
2026
-
[8]
VisualWebBench: How Far Have Multimodal
Junpeng Liu and Yifan Song and Bill Yuchen Lin and Wai Lam and Graham Neubig and Yuanzhi Li and Xiang Yue , booktitle=. VisualWebBench: How Far Have Multimodal. 2024 , url=
2024
-
[9]
Navigating the Digital World as Humans Do: Universal Visual Grounding for
Boyu Gou and Ruohan Wang and Boyuan Zheng and Yanan Xie and Cheng Chang and Yiheng Shu and Huan Sun and Yu Su , booktitle=. Navigating the Digital World as Humans Do: Universal Visual Grounding for. 2025 , url=
2025
-
[10]
2025 , eprint=
GTA1: GUI Test-time Scaling Agent , author=. 2025 , eprint=
2025
-
[11]
S ee C lick: Harnessing GUI Grounding for Advanced Visual GUI Agents
Cheng, Kanzhi and Sun, Qiushi and Chu, Yougang and Xu, Fangzhi and YanTao, Li and Zhang, Jianbing and Wu, Zhiyong. S ee C lick: Harnessing GUI Grounding for Advanced Visual GUI Agents. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2024. doi:10.18653/v1/2024.acl-long.505
-
[12]
Proceedings of the 33rd ACM International Conference on Multimedia , pages =
Li, Kaixin and Meng, Ziyang and Lin, Hongzhan and Luo, Ziyang and Tian, Yuchen and Ma, Jing and Huang, Zhiyong and Chua, Tat-Seng , title =. Proceedings of the 33rd ACM International Conference on Multimedia , pages =. 2025 , isbn =. doi:10.1145/3746027.3755688 , abstract =
-
[13]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =
Zhang, Xingxuan and Li, Jiansheng and Chu, Wenjing and hai, junjia and Xu, Renzhe and Yang, Yuqing and Guan, Shikai and Xu, Jiazheng and Jing, Liping and Cui, Peng , title =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =. 2025 , pages =
2025
-
[14]
Thirty-seventh Conference on Neural Information Processing Systems , year=
Self-Refine: Iterative Refinement with Self-Feedback , author=. Thirty-seventh Conference on Neural Information Processing Systems , year=
-
[15]
Thirty-seventh Conference on Neural Information Processing Systems , year=
Reflexion: language agents with verbal reinforcement learning , author=. Thirty-seventh Conference on Neural Information Processing Systems , year=
-
[16]
Zhang, Haoyu and Wu, Yuwei and Li, Pengxiang and Zhang, Xintong and Gao, Zhi and Gao, Rui and Gao, Mingyang and Sun, Che and Jia, Yunde , journal=
-
[17]
2025 , eprint=
High-Resolution Visual Reasoning via Multi-Turn Grounding-Based Reinforcement Learning , author=. 2025 , eprint=
2025
-
[18]
The Twelfth International Conference on Learning Representations , year=
Large Language Models Cannot Self-Correct Reasoning Yet , author=. The Twelfth International Conference on Learning Representations , year=
-
[19]
Thinking with Images for Multimodal Reasoning: Foundations, Methods, and Future Frontiers
Thinking with Images for Multimodal Reasoning: Foundations, Methods, and Future Frontiers , author=. arXiv preprint arXiv:2506.23918 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
2026 , url=
Mingyuan Wu and Jingcheng Yang and Jize Jiang and Meitang Li and Kaizhuo Yan and Hanchao Yu and Minjia Zhang and ChengXiang Zhai and Klara Nahrstedt , booktitle=. 2026 , url=
2026
-
[21]
Yang, Shuo and Niu, Yuwei and Liu, Yuyang and Ye, Yang and Lin, Bin and Yuan, Li , journal=
-
[22]
2025 , eprint=
v1: Learning to Point Visual Tokens for Multimodal Grounded Reasoning , author=. 2025 , eprint=
2025
-
[23]
2025 , url=
Zhongwei Wan and Zhihao Dou and Che Liu and Yu Zhang and Dongfei Cui and Qinjian Zhao and Hui Shen and Jing Xiong and Yi Xin and Yifan Jiang and Chaofan Tao and Yangfan He and Mi Zhang and Shen Yan , booktitle=. 2025 , url=
2025
-
[24]
2024 , url=
Zhibin Gou and Zhihong Shao and Yeyun Gong and yelong shen and Yujiu Yang and Nan Duan and Weizhu Chen , booktitle=. 2024 , url=
2024
-
[25]
The Thirty-eighth Annual Conference on Neural Information Processing Systems , year=
Fine-Tuning Large Vision-Language Models as Decision-Making Agents via Reinforcement Learning , author=. The Thirty-eighth Annual Conference on Neural Information Processing Systems , year=
-
[26]
Learning to Refine with Fine-Grained Natural Language Feedback
Wadhwa, Manya and Zhao, Xinyu and Li, Junyi Jessy and Durrett, Greg. Learning to Refine with Fine-Grained Natural Language Feedback. Findings of the Association for Computational Linguistics: EMNLP 2024. 2024. doi:10.18653/v1/2024.findings-emnlp.716
-
[27]
2025 , eprint=
Kimi k1.5: Scaling Reinforcement Learning with LLMs , author=. 2025 , eprint=
2025
-
[28]
CharXiv: Charting Gaps in Realistic Chart Understanding in Multimodal
Zirui Wang and Mengzhou Xia and Luxi He and Howard Chen and Yitao Liu and Richard Zhu and Kaiqu Liang and Xindi Wu and Haotian Liu and Sadhika Malladi and Alexis Chevalier and Sanjeev Arora and Danqi Chen , booktitle=. CharXiv: Charting Gaps in Realistic Chart Understanding in Multimodal. 2024 , url=
2024
-
[29]
2025 , eprint=
Mind the Gap: Benchmarking Spatial Reasoning in Vision-Language Models , author=. 2025 , eprint=
2025
-
[30]
Wu, Qiucheng and Zhao, Handong and Saxon, Michael and Bui, Trung and Wang, William Yang and Zhang, Yang and Chang, Shiyu , booktitle=
-
[31]
The Fourteenth International Conference on Learning Representations , year=
Visual Planning: Let's Think Only with Images , author=. The Fourteenth International Conference on Learning Representations , year=
-
[32]
2024 , url=
Jiayu Wang and Yifei Ming and Zhenmei Shi and Vibhav Vineet and Xin Wang and Yixuan Li and Neel Joshi , booktitle=. 2024 , url=
2024
-
[33]
Zheng, Mingyu and Feng, Zhifan and Wang, Jia and Wang, Lanrui and Lin, Zheng and Yang, Hao and Wang, Weiping. T able D reamer: Progressive and Weakness-guided Data Synthesis from Scratch for Table Instruction Tuning. Findings of the Association for Computational Linguistics: ACL 2025. 2025. doi:10.18653/v1/2025.findings-acl.381
-
[34]
Long, Hui and Yu, Haoli and Wang, Jingqiao and Long, Jian and Fang, Changxin , title =. Proceedings of the 2025 2nd International Conference on Virtual Reality, Image and Signal Processing , pages =. 2025 , isbn =. doi:10.1145/3772128.3772169 , abstract =
-
[35]
Vision-Language Models Can Self-Improve Reasoning via Reflection
Cheng, Kanzhi and YanTao, Li and Xu, Fangzhi and Zhang, Jianbing and Zhou, Hao and Liu, Yang. Vision-Language Models Can Self-Improve Reasoning via Reflection. Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers). 2025. doi:10.18653/v...
-
[36]
CVPR , year=
Generation and Comprehension of Unambiguous Object Descriptions , author=. CVPR , year=
-
[37]
R efer I t G ame: Referring to Objects in Photographs of Natural Scenes
Kazemzadeh, Sahar and Ordonez, Vicente and Matten, Mark and Berg, Tamara. R efer I t G ame: Referring to Objects in Photographs of Natural Scenes. Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing ( EMNLP ). 2014. doi:10.3115/v1/D14-1086
-
[38]
IJCV , volume=
Flickr30K Entities: Collecting Region-to-Phrase Correspondences for Richer Image-to-Sentence Models , author=. IJCV , volume=
-
[39]
, booktitle=
Yu, Licheng and Lin, Zhe and Shen, Xiaohui and Yang, Jimei and Lu, Xin and Bansal, Mohit and Berg, Tamara L. , booktitle=. MAttNet: Modular Attention Network for Referring Expression Comprehension , year=
-
[40]
2025 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
COUNTS: Benchmarking Object Detectors and Multimodal Large Language Models under Distribution Shifts , author=. 2025 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
2025
-
[41]
Guo, Daya and Yang, Dejian and Zhang, Haowei and Song, Junxiao and Wang, Peiyi and Zhu, Qihao and Xu, Runxin and Zhang, Ruoyu and Ma, Shirong and Bi, Xiao and Zhang, Xiaokang and Yu, Xingkai and Wu, Yu and Wu, Z. F. and Gou, Zhibin and Shao, Zhihong and Li, Zhuoshu and Gao, Ziyi and Liu, Aixin and Xue, Bing and Wang, Bingxuan and Wu, Bochao and Feng, Bei ...
-
[42]
Revisor: Beyond textual reflection, towards multimodal introspective reasoning in long-form video understanding , author=. arXiv preprint arXiv:2511.13026 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[43]
The Thirty-eighth Annual Conference on Neural Information Processing Systems , year=
Visual Sketchpad: Sketching as a Visual Chain of Thought for Multimodal Language Models , author=. The Thirty-eighth Annual Conference on Neural Information Processing Systems , year=
-
[44]
2024 , url=
Hao Shao and Shengju Qian and Han Xiao and Guanglu Song and Zhuofan Zong and Letian Wang and Yu Liu and Hongsheng Li , booktitle=. 2024 , url=
2024
-
[45]
Su, Zhaochen and Li, Linjie and Song, Mingyang and Hao, Yunzhuo and Yang, Zhengyuan and Zhang, Jun and Chen, Guanjie and Gu, Jiawei and Li, Juntao and Qu, Xiaoye and others , journal=
-
[46]
2026 , url=
Jiacong Wang and Zijian Kang and Haochen Wang and LiangXiao and Ya Wang and Jiawen Li and Bohong Wu and Ran Jiao and Haiyong Jiang and ChaoFeng and Jun Xiao , booktitle=. 2026 , url=
2026
-
[47]
arXiv preprint arXiv:2512.08511 , year=
Thinking with Images via Self-Calling Agent , author=. arXiv preprint arXiv:2512.08511 , year=
-
[48]
2025 , url=
Penghao Wu and Shengnan Ma and Bo Wang and Jiaheng Yu and Lewei Lu and Ziwei Liu , booktitle=. 2025 , url=
2025
-
[49]
2026 , url=
Yan Yang and Dongxu Li and Yutong Dai and Yuhao Yang and Ziyang Luo and Zirui Zhao and Zhiyuan Hu and JUNZHE HUANG and Amrita Saha and Zeyuan Chen and Ran Xu and Liyuan Pan and Caiming Xiong and Junnan Li , booktitle=. 2026 , url=
2026
-
[50]
2025 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
Your Large Vision-Language Model Only Needs A Few Attention Heads For Visual Grounding , author=. 2025 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
2025
-
[51]
Greg Brockman and Vicki Cheung and Ludwig Pettersson and Jonas Schneider and John Schulman and Jie Tang and Wojciech Zaremba , year=. 1606.01540 , archivePrefix=
work page internal anchor Pith review Pith/arXiv arXiv
-
[52]
2026 , eprint=
OpenAI GPT-5 System Card , author=. 2026 , eprint=
2026
-
[53]
2026 , url=
Qiying Yu and Zheng Zhang and Ruofei Zhu and Yufeng Yuan and Xiaochen Zuo and YuYue and Weinan Dai and Tiantian Fan and Gaohong Liu and Juncai Liu and LingJun Liu and Xin Liu and Haibin Lin and Zhiqi Lin and Bole Ma and Guangming Sheng and Yuxuan Tong and Chi Zhang and Mofan Zhang and Ru Zhang and Wang Zhang and Hang Zhu and Jinhua Zhu and Jiaze Chen and ...
2026
-
[54]
Look Again, Think Slowly: Enhancing Visual Reflection in Vision-Language Models
Jian, Pu and Wu, Junhong and Sun, Wei and Wang, Chen and Ren, Shuo and Zhang, Jiajun. Look Again, Think Slowly: Enhancing Visual Reflection in Vision-Language Models. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. 2025. doi:10.18653/v1/2025.emnlp-main.470
-
[55]
2026 , url=
Haozhe Wang and Chao Qu and Zuming Huang and Wei Chu and Fangzhen Lin and Wenhu Chen , booktitle=. 2026 , url=
2026
-
[56]
2026 , url=
Penghao Wu and Shengnan Ma and Bo Wang and Jiaheng Yu and Lewei Lu and Ziwei Liu , booktitle=. 2026 , url=
2026
-
[57]
The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
Latent Chain-of-Thought for Visual Reasoning , author=. The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
-
[58]
2026 , eprint=
Ground-R1: Incentivizing Grounded Visual Reasoning via Reinforcement Learning , author=. 2026 , eprint=
2026
-
[59]
The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
Grounded Reinforcement Learning for Visual Reasoning , author=. The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
-
[60]
The Thirty-ninth Annual Conference on Neural Information Processing Systems Datasets and Benchmarks Track , year=
Scaling Computer-Use Grounding via User Interface Decomposition and Synthesis , author=. The Thirty-ninth Annual Conference on Neural Information Processing Systems Datasets and Benchmarks Track , year=
-
[61]
Proceedings of the AAAI Conference on Artificial Intelligence (AAAI) , year=
GUI-G ^2 : Gaussian Reward Modeling for GUI Grounding , author=. Proceedings of the AAAI Conference on Artificial Intelligence (AAAI) , year=
-
[62]
arXiv preprint arXiv:2505.14231 , year=
UniVG-R1: Reasoning Guided Universal Visual Grounding with Reinforcement Learning , author=. arXiv preprint arXiv:2505.14231 , year=
-
[63]
Shao, Zhihong and Wang, Peiyi and Zhu, Qihao and Xu, Runxin and Song, Junxiao and Bi, Xiao and Zhang, Haowei and Zhang, Mingchuan and Li, YK and Wu, Yang and others , journal=
-
[64]
Qwen2.5-VL Technical Report , author=. arXiv preprint arXiv:2502.13923 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[65]
Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities , author=. arXiv preprint arXiv:2507.06261 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[66]
Visual Instruction Tuning , url =
Liu, Haotian and Li, Chunyuan and Wu, Qingyang and Lee, Yong Jae , booktitle =. Visual Instruction Tuning , url =
-
[67]
2025 , url=
Dongzhi Jiang and Renrui Zhang and Ziyu Guo and Yanwei Li and Yu Qi and Xinyan Chen and Liuhui Wang and Jianhan Jin and Claire Guo and Shen Yan and Bo Zhang and Chaoyou Fu and Peng Gao and Hongsheng Li , booktitle=. 2025 , url=
2025
-
[68]
Better Eyes, Better Thoughts: Why Vision Chain-of-Thought Fails in Medicine
Better Eyes, Better Thoughts: Why Vision Chain-of-Thought Fails in Medicine , author=. arXiv preprint arXiv:2603.06665 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[69]
Wu, Xueqing and Ding, Yuheng and Li, Bingxuan and Lu, Pan and Yin, Da and Chang, Kai-Wei and Peng, Nanyun , booktitle=
-
[70]
The Thirty-ninth Annual Conference on Neural Information Processing Systems Datasets and Benchmarks Track , year=
ChartMuseum: Testing Visual Reasoning Capabilities of Large Vision-Language Models , author=. The Thirty-ninth Annual Conference on Neural Information Processing Systems Datasets and Benchmarks Track , year=
-
[71]
Zayne Sprague and Jack Lu and Manya Wadhwa and Sedrick Keh and Mengye Ren and Greg Durrett , booktitle =
-
[72]
C hart QAP ro: A More Diverse and Challenging Benchmark for Chart Question Answering
Masry, Ahmed and Islam, Mohammed Saidul and Ahmed, Mahir and Bajaj, Aayush and Kabir, Firoz and Kartha, Aaryaman and Laskar, Md Tahmid Rahman and Rahman, Mizanur and Rahman, Shadikur and Shahmohammadi, Mehrad and Thakkar, Megh and Parvez, Md Rizwan and Hoque, Enamul and Joty, Shafiq. C hart QAP ro: A More Diverse and Challenging Benchmark for Chart Questi...
-
[73]
2026 , eprint=
Aha Moment Revisited: Are VLMs Truly Capable of Self Verification in Inference-time Scaling? , author=. 2026 , eprint=
2026
-
[74]
The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
Sherlock: Self-Correcting Reasoning in Vision-Language Models , author=. The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
-
[75]
2025 , eprint=
Limits and Gains of Test-Time Scaling in Vision-Language Reasoning , author=. 2025 , eprint=
2025
-
[76]
The Fourteenth International Conference on Learning Representations , year=
Vision Language Models are Biased , author=. The Fourteenth International Conference on Learning Representations , year=
-
[77]
The Thirty-eighth Annual Conference on Neural Information Processing Systems , year=
Bridge the Modality and Capability Gaps in Vision-Language Model Selection , author=. The Thirty-eighth Annual Conference on Neural Information Processing Systems , year=
-
[78]
Transactions on Machine Learning Research , issn=
Multimodal Chain-of-Thought Reasoning in Language Models , author=. Transactions on Machine Learning Research , issn=. 2024 , url=
2024
-
[79]
Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , month =
Luo, Tiange and Logeswaran, Lajanugen and Johnson, Justin and Lee, Honglak , title =. Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , month =. 2025 , pages =
2025
-
[80]
arXiv preprint arXiv:2603.27201 , year=
Understanding and Mitigating Hallucinations in Multimodal Chain-of-Thought Models , author=. arXiv preprint arXiv:2603.27201 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.