Self Multi-Head Attention for Speaker Recognition
Pith reviewed 2026-05-25 17:12 UTC · model grok-4.3
The pith
Self multi-head attention on CNN speech features acts as a pooling layer that selects the most discriminative segments for utterance-level speaker embeddings.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
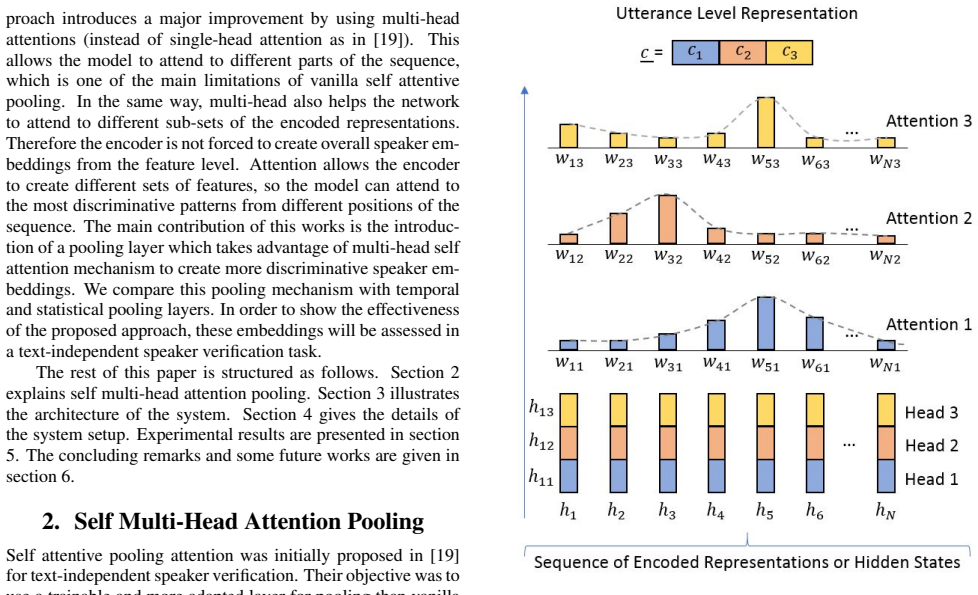
The self multi-head attention model produces multiple alignments from different subsegments of the CNN encoded states, functioning as a pooling layer which decides the most discriminative features over the sequence to obtain an utterance level representation.
What carries the argument
self multi-head attention model that produces multiple alignments from different subsegments of the CNN encoded states
If this is right
- The attention pooling handles variable-length utterances without requiring fixed-length inputs or simple averaging.
- Multiple attention heads allow the model to focus on separate regions of the sequence simultaneously.
- The approach yields measurable gains on the standard VoxCeleb1 verification benchmark over both pooling baselines and i-vector+PLDA.
Where Pith is reading between the lines
- The same attention pooling could be swapped into other CNN-based audio embedding pipelines that currently rely on mean or statistical pooling.
- The heads may learn to emphasize complementary acoustic cues such as formant structure versus prosody, though this is not measured in the paper.
- Performance on datasets recorded under different conditions would test whether the learned selection generalizes without retuning.
Load-bearing premise
The self multi-head attention will reliably identify the most discriminative subsegments across utterances without the need for explicit regularization or dataset-specific tuning.
What would settle it
Evaluating the trained model on a second corpus such as VoxCeleb2 and measuring whether the 18 percent relative EER reduction over standard pooling still appears.
Figures


read the original abstract
Most state-of-the-art Deep Learning (DL) approaches for speaker recognition work on a short utterance level. Given the speech signal, these algorithms extract a sequence of speaker embeddings from short segments and those are averaged to obtain an utterance level speaker representation. In this work we propose the use of an attention mechanism to obtain a discriminative speaker embedding given non fixed length speech utterances. Our system is based on a Convolutional Neural Network (CNN) that encodes short-term speaker features from the spectrogram and a self multi-head attention model that maps these representations into a long-term speaker embedding. The attention model that we propose produces multiple alignments from different subsegments of the CNN encoded states over the sequence. Hence this mechanism works as a pooling layer which decides the most discriminative features over the sequence to obtain an utterance level representation. We have tested this approach for the verification task for the VoxCeleb1 dataset. The results show that self multi-head attention outperforms both temporal and statistical pooling methods with a 18\% of relative EER. Obtained results show a 58\% relative improvement in EER compared to i-vector+PLDA.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a CNN encoder for short-term speaker features from spectrograms, followed by a self multi-head attention module that produces multiple alignments over subsegments of the encoded sequence. This attention is presented as a pooling layer that selects the most discriminative features to form an utterance-level embedding. On the VoxCeleb1 verification task the model is reported to outperform temporal and statistical pooling by 18% relative EER and i-vector+PLDA by 58% relative EER.
Significance. If the gains are reproducible under broader testing, the work supplies concrete evidence that multi-head self-attention can function as a data-driven pooling operator for variable-length speaker utterances, offering an interpretable alternative to fixed temporal or statistical aggregation. The use of a public benchmark supports direct comparison with prior pooling baselines.
major comments (2)
- [Experiments] Experiments section: all reported results, including the 18% relative EER gain, are obtained exclusively on VoxCeleb1. Because the central claim is that the self multi-head attention reliably identifies speaker-discriminative subsegments without dataset-specific tuning, the absence of evaluation on at least one additional corpus (e.g., VoxCeleb2) leaves the generalization of the pooling interpretation untested.
- [Model description] Model description (attention module): the number of attention heads and attention-layer dimensions are free parameters, yet no ablation or sensitivity analysis is provided. Without such controls it is impossible to determine whether the observed EER improvement is attributable to the multi-head mechanism itself or to hyper-parameter choices that may be tuned to VoxCeleb1 statistics.
minor comments (1)
- [Abstract] Abstract: the phrasing 'with a 18% of relative EER' is grammatically awkward and should be revised to 'with an 18% relative reduction in EER' for clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below and propose revisions where appropriate to strengthen the experimental validation of the self multi-head attention pooling approach.
read point-by-point responses
-
Referee: [Experiments] Experiments section: all reported results, including the 18% relative EER gain, are obtained exclusively on VoxCeleb1. Because the central claim is that the self multi-head attention reliably identifies speaker-discriminative subsegments without dataset-specific tuning, the absence of evaluation on at least one additional corpus (e.g., VoxCeleb2) leaves the generalization of the pooling interpretation untested.
Authors: We agree that testing on an additional corpus is required to support claims of generalization for the attention-based pooling. We will add results on VoxCeleb2 using the same experimental protocol in the revised manuscript. revision: yes
-
Referee: [Model description] Model description (attention module): the number of attention heads and attention-layer dimensions are free parameters, yet no ablation or sensitivity analysis is provided. Without such controls it is impossible to determine whether the observed EER improvement is attributable to the multi-head mechanism itself or to hyper-parameter choices that may be tuned to VoxCeleb1 statistics.
Authors: We acknowledge the absence of ablation studies on the number of heads and attention dimensions. We will include a sensitivity analysis varying these hyperparameters while keeping other factors fixed, to isolate the contribution of the multi-head mechanism. revision: yes
Circularity Check
No circularity; empirical comparison on external benchmark
full rationale
The paper proposes a CNN + self multi-head attention architecture for utterance-level speaker embeddings and reports EER improvements versus temporal/statistical pooling and i-vector+PLDA on the public VoxCeleb1 verification task. No equations define a quantity in terms of itself, no fitted parameters are relabeled as predictions, and no load-bearing premise rests on self-citation chains. The central claim is an experimental result obtained by training and testing on an external dataset, making the derivation self-contained against independent benchmarks.
Axiom & Free-Parameter Ledger
free parameters (2)
- number of attention heads
- attention layer dimensions
axioms (2)
- domain assumption CNN encodes short-term speaker features from spectrogram input
- domain assumption Multiple attention heads produce complementary alignments useful for speaker discrimination
Reference graph
Works this paper leans on
-
[1]
Introduction Recently there have been several attempts to apply Deep Learn- ing (DL) in order to build speaker embeddings. Speaker em- bedding is often referred to a single low dimensional vector representation of the speaker characteristics from a speech sig- nal extracted using a Neural Network (NN) model. For text- independent Speaker Recognition (SR),...
work page internal anchor Pith review Pith/arXiv arXiv 1906
-
[2]
The concluding remarks and some future works are given in section 6
-
[3]
Self Multi-Head Attention Pooling Self attentive pooling attention was initially proposed in [19] for text-independent speaker verification. Their objective was to use a trainable and more adapted layer for pooling than vanilla temporal average. Given a sequence of encoded hidden states from a network, temporal pooling averages these representa- tions over...
-
[4]
System Description Figure 2 shows the overall architecture used for this work. The proposed neural network is a CNN based encoder and an atten- tion based pooling layer followed by a set of dense layers. The network is fed with variable length mel-spectrogram features. These features are then mapped into a sequence of speaker rep- resentations trough a CN...
-
[5]
Experimental Setup The proposed system in this work will be tested on V oxCeleb1 [23]. This corpus is a large multimedia database that contains over 100, 00 utterances for 1, 251 celebrities, extracted from videos uploaded to Youtube. For each person in the corpus there is an average of 18 videos. Each of these videos has been split into approximately 123...
-
[6]
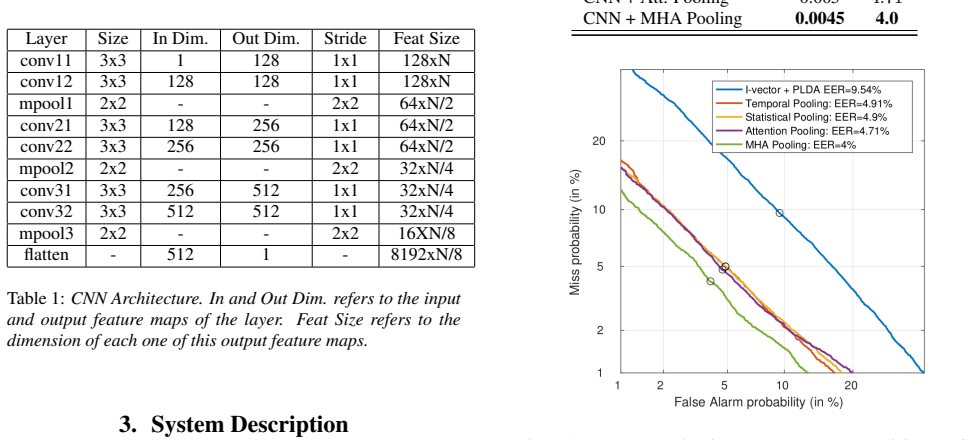
Results The proposed attention pooling layer has been evaluated with different approaches in the V oxCeleb1 text-independent verifi- cation task and presented in Table 2. Performance is evaluated using the Equal Error Rate (EER) and the minimum Decision Cost Function (DCF) calculated using CF A = 1, CM = 1, and PT = 0.01. MHA Pooling refers to the best sel...
-
[7]
Conclusions In this paper we have applied a self multi-head attention mech- anism to obtain speaker embeddings at level utterance by pool- ing short-term features. This pooling layer have been tested in a neural network based on a CNN that maps spectrograms into sequences of speaker vectors. These vectors are then input to the pooling layer, which output ...
-
[8]
Acknowledgements This work was supported in part by the Spanish Project Deep- V oice (TEC2015-69266-P)
-
[9]
Deep neural networks for small footprint text- dependent speaker verification,
E. Variani, X. Lei, E. McDermott, I. L. Moreno, and J. Gonzalez- Dominguez, “Deep neural networks for small footprint text- dependent speaker verification,” in2014 IEEE International Con- ference on Acoustics, Speech and Signal Processing (ICASSP) . IEEE, 2014, pp. 4052–4056
work page 2014
-
[10]
Deep neural network embeddings for text-independent speaker verification,
D. Snyder, D. Garcia-Romero, D. Povey, and S. Khudanpur, “Deep neural network embeddings for text-independent speaker verification,” inInterspeech, 2017, pp. 999–1003
work page 2017
-
[11]
Speaker recognition by means of deep belief networks,
V . Vasilakakis, S. Cumani, P. Laface, and P. Torino, “Speaker recognition by means of deep belief networks,” Proc. Biometric Technologies in Forensic Science, 2013
work page 2013
-
[12]
From fea- tures to speaker vectors by means of restricted boltzmann ma- chine adaptation,
P. Safari, O. Ghahabi, and F. J. Hernando Peric ´as, “From fea- tures to speaker vectors by means of restricted boltzmann ma- chine adaptation,” in ODYSSEY 2016-The Speaker and Language Recognition Workshop, 2016, pp. 366–371
work page 2016
-
[13]
Deep speaker em- beddings for short-duration speaker verification,
G. Bhattacharya, M. J. Alam, and P. Kenny, “Deep speaker em- beddings for short-duration speaker verification,” in Interspeech, 2017, pp. 1517–1521
work page 2017
-
[14]
X-vectors: Robust dnn embeddings for speaker recognition,
D. Snyder, D. Garcia-Romero, G. Sell, D. Povey, and S. Khudan- pur, “X-vectors: Robust dnn embeddings for speaker recognition,” in 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2018, pp. 5329–5333
work page 2018
-
[15]
Full-info training for deep speaker feature learning,
L. Li, Z. Tang, D. Wang, and T. F. Zheng, “Full-info training for deep speaker feature learning,” in 2018 IEEE International Con- ference on Acoustics, Speech and Signal Processing (ICASSP) . IEEE, 2018, pp. 5369–5373
work page 2018
-
[16]
Deep neural network-based speaker embeddings for end-to-end speaker verification,
D. Snyder, P. Ghahremani, D. Povey, D. Garcia-Romero, Y . Carmiel, and S. Khudanpur, “Deep neural network-based speaker embeddings for end-to-end speaker verification,” in2016 IEEE Spoken Language Technology Workshop (SLT) . IEEE, 2016, pp. 165–170
work page 2016
-
[17]
Front-end factor analysis for speaker verification,
N. Dehak, P. J. Kenny, R. Dehak, P. Dumouchel, and P. Ouellet, “Front-end factor analysis for speaker verification,” IEEE Trans- actions on Audio, Speech, and Language Processing , vol. 19, no. 4, pp. 788–798, 2011
work page 2011
-
[18]
On deep speaker embeddings for text-independent speaker recognition
S. Novoselov, A. Shulipa, I. Kremnev, A. Kozlov, and V . Shchemelinin, “On deep speaker embeddings for text-independent speaker recognition,” arXiv preprint arXiv:1804.10080, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[19]
Gaussian-Constrained training for speaker verification
L. Li, Z. Tang, Y . Shi, and D. Wang, “Gaussian-constrained train- ing for speaker verification,” arXiv preprint arXiv:1811.03258 , 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[20]
How to Improve Your Speaker Embeddings Extractor in Generic Toolkits
H. Zeinali, L. Burget, J. Rohdin, T. Stafylakis, and J. Cernocky, “How to improve your speaker embeddings extractor in generic toolkits,” arXiv preprint arXiv:1811.02066, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[21]
Angular softmax for short- duration text-independent speaker verification,
Z. Huang, S. Wang, and K. Yu, “Angular softmax for short- duration text-independent speaker verification,” Proc. Inter- speech, Hyderabad, 2018
work page 2018
-
[22]
Neural Machine Translation by Jointly Learning to Align and Translate
D. Bahdanau, K. Cho, and Y . Bengio, “Neural machine trans- lation by jointly learning to align and translate,” arXiv preprint arXiv:1409.0473, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[23]
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin, “Attention is all you need,” in Advances in Neural Information Processing Systems, 2017, pp. 5998–6008
work page 2017
-
[24]
W. Chan, N. Jaitly, Q. V . Le, and O. Vinyals, “Listen, attend and spell,” arXiv preprint arXiv:1508.01211, 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[25]
End-to-end at- tention based text-dependent speaker verification,
S.-X. Zhang, Z. Chen, Y . Zhao, J. Li, and Y . Gong, “End-to-end at- tention based text-dependent speaker verification,” in 2016 IEEE Spoken Language Technology Workshop (SLT). IEEE, 2016, pp. 171–178
work page 2016
-
[26]
Attention-Based Models for Text-Dependent Speaker Verification
F. Chowdhury, Q. Wang, I. L. Moreno, and L. Wan, “Attention- based models for text-dependent speaker verification,” arXiv preprint arXiv:1710.10470, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[27]
W. Cai, J. Chen, and M. Li, “Exploring the encoding layer and loss function in end-to-end speaker and language recognition system,” in Proc. Odyssey 2018 The Speaker and Language Recognition Workshop, 2018, pp. 74–81
work page 2018
-
[28]
State- of-the-art speech recognition with sequence-to-sequence models,
C.-C. Chiu, T. N. Sainath, Y . Wu, R. Prabhavalkar, P. Nguyen, Z. Chen, A. Kannan, R. J. Weiss, K. Rao, E. Goninaet al., “State- of-the-art speech recognition with sequence-to-sequence models,” in 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2018, pp. 4774–4778
work page 2018
-
[29]
M. Dehghani, S. Gouws, O. Vinyals, J. Uszkoreit, and Ł. Kaiser, “Universal transformers,” arXiv preprint arXiv:1807.03819 , 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[30]
T. Hori, S. Watanabe, Y . Zhang, and W. Chan, “Advances in joint ctc-attention based end-to-end speech recognition with a deep cnn encoder and rnn-lm,” arXiv preprint arXiv:1706.02737, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[31]
V oxceleb: a large- scale speaker identification dataset,
A. Nagrani, J. S. Chung, and A. Zisserman, “V oxceleb: a large- scale speaker identification dataset,” inINTERSPEECH, 2017
work page 2017
-
[32]
V oxceleb2: Deep speaker recognition,
J. S. Chung, A. Nagrani, and A. Zisserman, “V oxceleb2: Deep speaker recognition,” in INTERSPEECH, 2018
work page 2018
-
[33]
Probabilistic linear discriminant anal- ysis for inferences about identity,
S. J. Prince and J. H. Elder, “Probabilistic linear discriminant anal- ysis for inferences about identity,” in 2007 IEEE 11th Interna- tional Conference on Computer Vision. IEEE, 2007, pp. 1–8
work page 2007
-
[34]
B. McFee, M. McVicar, S. Balke, V . Lostanlen, C. Thom, C. Raffel, D. Lee, K. Lee, O. Nieto, F. Zalkow, D. Ellis, E. Battenberg, R. Yamamoto, J. Moore, Z. Wei, R. Bittner, K. Choi, nullmightybofo, P. Friesch, F.-R. Stter, Thassilo, M. V ollrath, S. K. Golu, nehz, S. Waloschek, Seth, R. Naktinis, D. Repetto, C. F. Hawthorne, and C. Carr, “librosa/librosa: ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.