Cross-Domain Conditional Generative Adversarial Networks for Stereoscopic Hyperrealism in Surgical Training
Pith reviewed 2026-05-25 16:50 UTC · model grok-4.3
The pith
A cross-domain conditional GAN generates consistent stereo pairs for hyperrealistic surgical training images.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We propose a cross-domain conditional generative adversarial network approach that generates more consistent stereo pairs from surgical training phantoms, yielding substantial improvements in depth perception and realism over the baseline as evaluated by domain experts and medical students.
What carries the argument
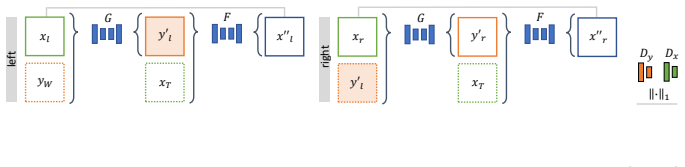
Cross-domain conditional GAN that learns mappings from phantom frames to realistic endoscopic images while enforcing consistency between stereo views.
If this is right
- Uniform phantom textures are replaced by heterogeneous tissue appearances without introducing stereo artifacts.
- Depth perception improves when the generated pairs are viewed in augmented reality on 3D monitors.
- The outputs receive higher or equal subjective ratings than the baseline in 84 of 90 evaluations.
- Phantoms become usable for more realistic endoscopic training scenarios that require accurate stereo vision.
Where Pith is reading between the lines
- The same cross-domain conditioning principle could be tested on video sequences to maintain consistency across time.
- Adding an explicit term for stereo disparity in the loss function might strengthen consistency beyond what the current architecture achieves.
- The method could be applied to other paired medical imaging tasks where left-right or multi-view alignment is required.
Load-bearing premise
Subjective preference ratings from only six evaluators on ninety image pairs reliably indicate genuine improvements in stereo consistency and depth perception.
What would settle it
An objective test that measures average disparity error between the generated left and right images using a stereo matching algorithm and compares the error to the baseline method.
Figures




read the original abstract
Phantoms for surgical training are able to mimic cutting and suturing properties and patient-individual shape of organs, but lack a realistic visual appearance that captures the heterogeneity of surgical scenes. In order to overcome this in endoscopic approaches, hyperrealistic concepts have been proposed to be used in an augmented reality-setting, which are based on deep image-to-image transformation methods. Such concepts are able to generate realistic representations of phantoms learned from real intraoperative endoscopic sequences. Conditioned on frames from the surgical training process, the learned models are able to generate impressive results by transforming unrealistic parts of the image (e.g.\ the uniform phantom texture is replaced by the more heterogeneous texture of the tissue). Image-to-image synthesis usually learns a mapping $G:X~\to~Y$ such that the distribution of images from $G(X)$ is indistinguishable from the distribution $Y$. However, it does not necessarily force the generated images to be consistent and without artifacts. In the endoscopic image domain this can affect depth cues and stereo consistency of a stereo image pair, which ultimately impairs surgical vision. We propose a cross-domain conditional generative adversarial network approach (GAN) that aims to generate more consistent stereo pairs. The results show substantial improvements in depth perception and realism evaluated by 3 domain experts and 3 medical students on a 3D monitor over the baseline method. In 84 of 90 instances our proposed method was preferred or rated equal to the baseline.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a cross-domain conditional generative adversarial network (cGAN) to transform phantom endoscopic images into hyperrealistic surgical scenes while aiming to preserve stereo consistency for better depth perception. Conditioned on training phantom frames, the model learns mappings from real intraoperative sequences; evaluation by 3 domain experts and 3 medical students on a 3D monitor shows the proposed method preferred or rated equal to baseline in 84 of 90 instances.
Significance. If the stereo-consistency improvements are substantiated, the approach could meaningfully advance AR-based surgical training by replacing uniform phantom textures with heterogeneous tissue appearance without degrading binocular cues. The cross-domain conditioning and human preference protocol are standard for image-to-image tasks, but the absence of any quantitative stereo metric leaves the core technical contribution unanchored.
major comments (1)
- [Abstract] Abstract: the claim that the method generates 'more consistent stereo pairs' and improves 'depth perception' rests entirely on subjective preference counts (84/90) from six raters; no left-right disparity error, no stereo-matching consistency term, no SSIM/PSNR on corresponding pairs, and no stereo-specific baseline are reported, so the central technical assertion lacks quantitative support.
minor comments (1)
- [Abstract] Abstract: the evaluation protocol (how pairs were presented, whether raters were blinded, statistical testing of the 84/90 count) is not described.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. The main concern is the lack of quantitative metrics supporting the claims of improved stereo consistency and depth perception. We respond to this point below and propose revisions to address it where appropriate.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that the method generates 'more consistent stereo pairs' and improves 'depth perception' rests entirely on subjective preference counts (84/90) from six raters; no left-right disparity error, no stereo-matching consistency term, no SSIM/PSNR on corresponding pairs, and no stereo-specific baseline are reported, so the central technical assertion lacks quantitative support.
Authors: We agree that the evaluation is based on subjective preferences from six raters viewing stereo pairs on a 3D monitor. This approach was chosen because it directly measures the impact on depth perception in a manner relevant to surgical training. In the cross-domain conditional GAN setting, quantitative metrics such as left-right disparity error are not straightforward to compute due to the absence of corresponding 3D ground truth between the phantom inputs and the real target domain images. Metrics like SSIM or PSNR on generated pairs would assess image quality but not necessarily binocular consistency. No stereo-specific baseline was included as the goal was to compare against standard image-to-image translation methods. We will revise the abstract and discussion sections to better contextualize the evaluation and include any feasible quantitative analyses in the revised version. revision: partial
Circularity Check
No significant circularity; central claim rests on external human evaluation
full rationale
The paper describes a cross-domain cGAN for stereo-consistent image synthesis and supports its claim of improved depth perception solely via preference ratings from six independent human evaluators on 90 image pairs. No equations, fitted parameters, self-citations, or uniqueness theorems appear in the abstract or description that would reduce any prediction or result to a tautology by construction. The evaluation is performed by external raters on a 3D monitor and is therefore independent of the model's internal quantities, satisfying the criteria for a self-contained, non-circular derivation.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
S. Engelhardt, R. De Simone, P. M. Full, M. Karck, and I. Wolf, “Improving surgi- cal training phantoms by hyperrealism: Deep unpaired image-to-image translation from real surgeries,” in Medical Image Computing and Computer Assisted Inter- vention – MICCAI 2018 , 2018, pp. 747–755
work page 2018
-
[2]
A taxonomy of mixed reality visual displays,
P. Milgram and F. Kishino, “A taxonomy of mixed reality visual displays,” IEICE Trans Inf Syst , vol. 77, no. 12, pp. 1321–1329, 1994
work page 1994
-
[3]
Surreal: enhancing surgical simulation realism using style transfer,
I. Luengo, E. Flouty, P. Giataganas, P. Wisanuvej, J. Nehme, and D. Stoyanov, “Surreal: enhancing surgical simulation realism using style transfer,” inBritish Ma- chine Vision Conference 2018, BMVC 2018, Northumbria University, Newcastle, UK, September 3-6, 2018 , 2018, p. 116
work page 2018
-
[4]
Unpaired image-to-image trans- lation using cycle-consistent adversarial networks,
J. Y. Zhu, T. Park, P. Isola, and A. A. Efros, “Unpaired image-to-image trans- lation using cycle-consistent adversarial networks,” in 2017 IEEE International Conference on Computer Vision (ICCV) , 2017, pp. 2242–2251
work page 2017
-
[5]
Stereoscopic neural style transfer,
D. Chen, L. Yuan, J. Liao, N. Yu, and G. Hua, “Stereoscopic neural style transfer,” in The IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , June 2018, pp. 6654–6663
work page 2018
-
[6]
Conditional Generative Adversarial Nets
M. Mirza and S. Osindero, “Conditional Generative Adversarial Nets,” arXiv:1411.1784, Nov. 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[7]
Image-to-Image Translation with Conditional Adversarial Networks
P. Isola, J.-Y. Zhu, T. Zhou, and A. A. Efros, “Image-to-Image Translation with Conditional Adversarial Networks,” arXiv:1611.07004, Nov. 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[8]
DualGAN: Unsupervised Dual Learning for Image-To-Image Translation,
Z. Yi, H. Zhang, P. Tan, and M. Gong, “DualGAN: Unsupervised Dual Learning for Image-To-Image Translation,” inThe IEEE International Conference on Computer Vision (ICCV) , Oct 2017, pp. 2868–2876
work page 2017
-
[9]
S. Engelhardt, S. Sauerzapf, B. Preim, M. Karck, I. Wolf, and R. De Simone, “Flex- ible and Comprehensive Patient-Specific Mitral Valve Silicone Models with Chor- dae Tendinae Made From 3D-Printable Molds,”International Journal of Computer Assisted Radiology and Surgery (IPCAI Special Issue) , vol. 14, no. 7, 2019
work page 2019
-
[10]
S. Engelhardt, S. Sauerzapf, A. Bri, M. Karck, I. Wolf, and R. De Simone, “Repli- cated mitral valve models from real patients offer training opportunities for mini- mally invasive mitral valve repair,” Interact Cardiovasc Thorac Surg. , 2019
work page 2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.