Uncertainty-aware Model-based Policy Optimization
Pith reviewed 2026-05-25 16:14 UTC · model grok-4.3
The pith
An uncertainty-aware dynamics model lets agents optimize policies by differentiating gradients through the model itself.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper claims that jointly learning an uncertainty-aware dynamics model and optimizing a policy via automatic differentiation through the model produces policies whose sample complexity is markedly lower than that of state-of-the-art baselines while asymptotic performance remains competitive.
What carries the argument
Uncertainty-aware dynamics model whose gradients are back-propagated by automatic differentiation to update the policy parameters.
If this is right
- An explicit policy is obtained, enabling transfer to new tasks without re-planning.
- Decision-time computation drops because model-predictive control is no longer required.
- Model bias is reduced by propagating uncertainty information into the policy update.
- The same learned model can be reused for multiple policies.
Where Pith is reading between the lines
- The approach could be combined with model-free fine-tuning once a good policy has been obtained from the model.
- Extending the framework to partially observable settings would require propagating uncertainty over belief states rather than single observations.
- If the uncertainty model can be made cheap to evaluate, the method might scale to higher-dimensional control problems where MPC becomes prohibitive.
Load-bearing premise
The uncertainty estimates produced by the learned dynamics model are accurate enough that policy gradients computed through the model do not exploit model errors and therefore generalize to the true environment.
What would settle it
An experiment in which the same training procedure is run on a task where the model’s uncertainty estimates are deliberately made too narrow, then measuring whether sample efficiency and final performance collapse to the levels of ordinary model-based methods.
Figures


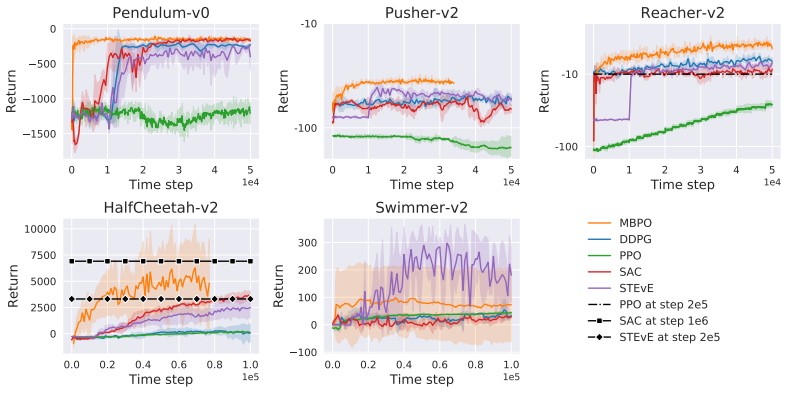
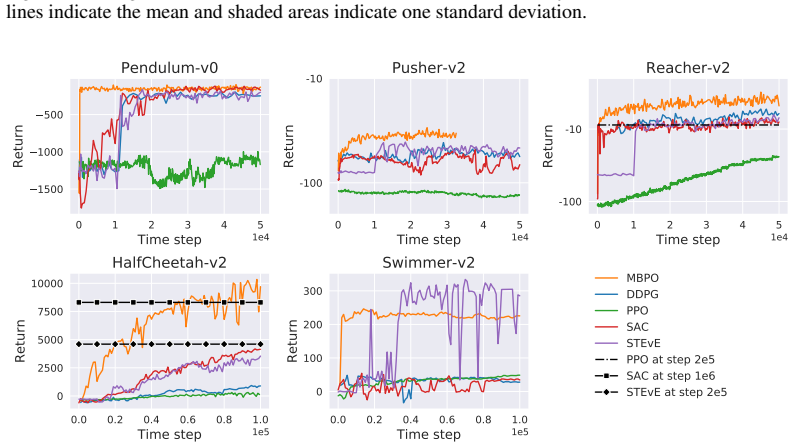
read the original abstract
Model-based reinforcement learning has the potential to be more sample efficient than model-free approaches. However, existing model-based methods are vulnerable to model bias, which leads to poor generalization and asymptotic performance compared to model-free counterparts. In addition, they are typically based on the model predictive control (MPC) framework, which not only is computationally inefficient at decision time but also does not enable policy transfer due to the lack of an explicit policy representation. In this paper, we propose a novel uncertainty-aware model-based policy optimization framework which solves those issues. In this framework, the agent simultaneously learns an uncertainty-aware dynamics model and optimizes the policy according to these learned models. In the optimization step, the policy gradient is computed by automatic differentiation through the models. With respect to sample efficiency alone, our approach shows promising results on challenging continuous control benchmarks with competitive asymptotic performance and significantly lower sample complexity than state-of-the-art baselines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes an uncertainty-aware model-based policy optimization framework for reinforcement learning. The agent learns an uncertainty-aware dynamics model while optimizing a policy whose gradients are obtained by automatic differentiation through the learned model. The central empirical claim is that the method achieves competitive asymptotic performance on continuous control benchmarks while exhibiting significantly lower sample complexity than state-of-the-art baselines.
Significance. If the empirical results hold under rigorous evaluation, the work would be of moderate significance: it attempts to combine uncertainty-aware modeling with end-to-end differentiable policy optimization, potentially mitigating model bias while retaining the sample-efficiency advantages of model-based methods and enabling explicit policy transfer. The absence of parameter-free derivations or machine-checked proofs limits the strength of the theoretical contribution.
minor comments (1)
- The abstract asserts empirical improvements but supplies no information on the form of the uncertainty model, the precise gradient computation, the experimental protocol, the choice of baselines, or statistical significance testing; these details are required to evaluate the central claim.
Simulated Author's Rebuttal
We thank the referee for their time and for summarizing our contribution. We note that the report lists no specific major comments to address. We are available to provide clarifications or additional experiments if requested by the editor.
Circularity Check
No significant circularity; empirical claims rest on benchmark results
full rationale
The paper's central claim is an empirical statement about sample efficiency on continuous control tasks. The abstract and provided description outline a framework that learns an uncertainty-aware dynamics model and computes policy gradients via autodiff through the model. No derivation chain, fitted parameter renamed as prediction, self-citation load-bearing premise, or ansatz smuggled via citation is visible. The method is presented as a novel combination of existing ideas (model-based RL with uncertainty and policy optimization), with performance evaluated externally on standard benchmarks. This is self-contained against external benchmarks and does not reduce any result to its inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
An application of rein- forcement learning to aerobatic helicopter flight
Pieter Abbeel, Adam Coates, Morgan Quigley, and Andrew Y Ng. An application of rein- forcement learning to aerobatic helicopter flight. In Advances in neural information processing systems, pages 1–8, 2007. 8
work page 2007
-
[2]
Greg Brockman, Vicki Cheung, Ludwig Pettersson, Jonas Schneider, John Schulman, Jie Tang, and Wojciech Zaremba. Openai gym. arXiv preprint arXiv:1606.01540, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[3]
Sample- efficient reinforcement learning with stochastic ensemble value expansion
Jacob Buckman, Danijar Hafner, George Tucker, Eugene Brevdo, and Honglak Lee. Sample- efficient reinforcement learning with stochastic ensemble value expansion. In Advances in Neural Information Processing Systems, pages 8224–8234, 2018
work page 2018
-
[4]
Deep reinforcement learning in a handful of trials using probabilistic dynamics models
Kurtland Chua, Roberto Calandra, Rowan McAllister, and Sergey Levine. Deep reinforcement learning in a handful of trials using probabilistic dynamics models. In Advances in Neural Information Processing Systems, pages 4754–4765, 2018
work page 2018
-
[5]
Model-Based Reinforcement Learning via Meta-Policy Optimization
Ignasi Clavera, Jonas Rothfuss, John Schulman, Yasuhiro Fujita, Tamim Asfour, and Pieter Abbeel. Model-based reinforcement learning via meta-policy optimization. arXiv preprint arXiv:1809.05214, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[6]
Pilco: A model-based and data-efficient approach to policy search
Marc Deisenroth and Carl E Rasmussen. Pilco: A model-based and data-efficient approach to policy search. In Proceedings of the 28th International Conference on machine learning (ICML-11), pages 465–472, 2011
work page 2011
-
[7]
Learning and Policy Search in Stochastic Dynamical Systems with Bayesian Neural Networks
Stefan Depeweg, José Miguel Hernández-Lobato, Finale Doshi-Velez, and Steffen Udluft. Learning and policy search in stochastic dynamical systems with bayesian neural networks. arXiv preprint arXiv:1605.07127, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[8]
Dropout as a bayesian approximation: Representing model uncertainty in deep learning
Yarin Gal and Zoubin Ghahramani. Dropout as a bayesian approximation: Representing model uncertainty in deep learning. Ininternational conference on machine learning, pages 1050–1059, 2016
work page 2016
-
[9]
Improving pilco with bayesian neural network dynamics models
Yarin Gal, Rowan McAllister, and Carl Edward Rasmussen. Improving pilco with bayesian neural network dynamics models. In Data-Efficient Machine Learning workshop, ICML , volume 4, 2016
work page 2016
-
[10]
A comprehensive survey on safe reinforcement learning
Javier Garcıa and Fernando Fernández. A comprehensive survey on safe reinforcement learning. Journal of Machine Learning Research, 16(1):1437–1480, 2015
work page 2015
-
[11]
Soft Actor-Critic: Off-Policy Maximum Entropy Deep Reinforcement Learning with a Stochastic Actor
Tuomas Haarnoja, Aurick Zhou, Pieter Abbeel, and Sergey Levine. Soft actor-critic: Off- policy maximum entropy deep reinforcement learning with a stochastic actor. arXiv preprint arXiv:1801.01290, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[12]
Data-Efficient Reinforcement Learning with Probabilistic Model Predictive Control
Sanket Kamthe and Marc Peter Deisenroth. Data-efficient reinforcement learning with proba- bilistic model predictive control. arXiv preprint arXiv:1706.06491, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[13]
Model-Ensemble Trust-Region Policy Optimization
Thanard Kurutach, Ignasi Clavera, Yan Duan, Aviv Tamar, and Pieter Abbeel. Model-ensemble trust-region policy optimization. arXiv preprint arXiv:1802.10592, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[14]
Simple and scalable predictive uncertainty estimation using deep ensembles
Balaji Lakshminarayanan, Alexander Pritzel, and Charles Blundell. Simple and scalable predictive uncertainty estimation using deep ensembles. In Advances in Neural Information Processing Systems, pages 6402–6413, 2017
work page 2017
-
[15]
Sergey Levine and Vladlen Koltun. Guided policy search. In International Conference on Machine Learning, pages 1–9, 2013
work page 2013
-
[16]
Continuous control with deep reinforcement learning
Timothy P Lillicrap, Jonathan J Hunt, Alexander Pritzel, Nicolas Heess, Tom Erez, Yuval Tassa, David Silver, and Daan Wierstra. Continuous control with deep reinforcement learning. arXiv preprint arXiv:1509.02971, 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[17]
Harry Markowitz. Portfolio selection. The journal of finance, 7(1):77–91, 1952
work page 1952
-
[18]
Human-level control through deep reinforcement learning
V olodymyr Mnih, Koray Kavukcuoglu, David Silver, Andrei A Rusu, Joel Veness, Marc G Bellemare, Alex Graves, Martin Riedmiller, Andreas K Fidjeland, Georg Ostrovski, et al. Human-level control through deep reinforcement learning. Nature, 518(7540):529, 2015
work page 2015
-
[19]
Neural Network Dynamics for Model-Based Deep Reinforcement Learning with Model-Free Fine-Tuning
Anusha Nagabandi, Gregory Kahn, Ronald S. Fearing, and Sergey Levine. Neural network dynamics for model-based deep reinforcement learning with model-free fine-tuning. CoRR, abs/1708.02596, 2017. URL http://arxiv.org/abs/1708.02596. 9
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[20]
Deep exploration via bootstrapped dqn
Ian Osband, Charles Blundell, Alexander Pritzel, and Benjamin Van Roy. Deep exploration via bootstrapped dqn. In Advances in neural information processing systems, pages 4026–4034, 2016
work page 2016
-
[21]
Nikunj C Oza. Online bagging and boosting. In 2005 IEEE international conference on systems, man and cybernetics, volume 3, pages 2340–2345. Ieee, 2005
work page 2005
-
[22]
Sampling streaming data with replacement
Byung-Hoon Park, George Ostrouchov, and Nagiza F Samatova. Sampling streaming data with replacement. Computational Statistics & Data Analysis, 52(2):750–762, 2007
work page 2007
-
[23]
Efficient Online Bootstrapping for Large Scale Learning
Zhen Qin, Vaclav Petricek, Nikos Karampatziakis, Lihong Li, and John Langford. Efficient online bootstrapping for large scale learning. arXiv preprint arXiv:1312.5021, 2013
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[24]
Td algorithm for the variance of return and mean-variance reinforcement learning
Makoto Sato, Hajime Kimura, and Shibenobu Kobayashi. Td algorithm for the variance of return and mean-variance reinforcement learning. Transactions of the Japanese Society for Artificial Intelligence, 16(3):353–362, 2001
work page 2001
-
[25]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms. arXiv preprint arXiv:1707.06347, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[26]
Taking the human out of the loop: A review of bayesian optimization
Bobak Shahriari, Kevin Swersky, Ziyu Wang, Ryan P Adams, and Nando De Freitas. Taking the human out of the loop: A review of bayesian optimization. Proceedings of the IEEE, 104 (1):148–175, 2015
work page 2015
-
[27]
Mastering the game of go without human knowledge
David Silver, Julian Schrittwieser, Karen Simonyan, Ioannis Antonoglou, Aja Huang, Arthur Guez, Thomas Hubert, Lucas Baker, Matthew Lai, Adrian Bolton, et al. Mastering the game of go without human knowledge. Nature, 550(7676):354, 2017
work page 2017
-
[28]
Dyna, an integrated architecture for learning, planning, and reacting
Richard S Sutton. Dyna, an integrated architecture for learning, planning, and reacting. ACM SIGART Bulletin, 2(4):160–163, 1991
work page 1991
-
[29]
Policy gradient methods for reinforcement learning with function approximation
Richard S Sutton, David A McAllester, Satinder P Singh, and Yishay Mansour. Policy gradient methods for reinforcement learning with function approximation. In Advances in neural information processing systems, pages 1057–1063, 2000
work page 2000
-
[30]
Mujoco: A physics engine for model-based control
Emanuel Todorov, Tom Erez, and Yuval Tassa. Mujoco: A physics engine for model-based control. In 2012 IEEE/RSJ International Conference on Intelligent Robots and Systems, pages 5026–5033. IEEE, 2012
work page 2012
-
[31]
Lecture on the calculus of variations and optimal control theory, volume 304
Laurence Chisholm Young. Lecture on the calculus of variations and optimal control theory, volume 304. American Mathematical Soc., 2000. A Appendix A.1 Why linearly weighted random sampling is a fairer sampling scheme Consider the following online learning process: for each time step, we need to randomly sample an example from the accumulating dataset. Su...
work page 2000
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.