Topic Modeling the Reading and Writing Behavior of Information Foragers
Pith reviewed 2026-05-25 12:17 UTC · model grok-4.3
The pith
LDA topic models of Darwin's reading records and drafts show how individuals build knowledge by balancing exploration against exploitation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
LDA topic modeling applied to the texts each author read and wrote represents the information environment and the cognitive search process. Case studies of Darwin characterize his reading behavior, show its interaction with drafts and revisions of The Origin of Species, and extend the dataset to later work. Analysis of Jefferson's letters broadens the data type beyond books, while neuroscience citations move from individual to collective behavior. Together these studies reveal the interplay between individual and collective phenomena where innovation takes place.
What carries the argument
LDA topic modeling on the texts each author read and wrote, which constructs a representation of the information environment and the balance of exploration against exploitation.
If this is right
- Reading behavior can be tracked quantitatively across years for a single historical figure using the same modeling approach.
- Topic overlap between readings and specific drafts can identify how new ideas enter and shape written work.
- The method extends from book records to correspondence and from single authors to group citation networks.
- Individual foraging patterns contribute measurably to collective innovation processes.
Where Pith is reading between the lines
- Similar modeling could be applied to modern researchers' reading lists and citation histories to study current knowledge construction.
- Digital library systems might incorporate topic-based recommendations that support balanced exploration and exploitation.
- The framework connects individual search strategies to broader economic models of decision-making under incomplete information.
Load-bearing premise
LDA topic modeling on the texts each author read and wrote accurately represents the information environment and the cognitive search process of balancing exploration against exploitation.
What would settle it
If the topics extracted from Darwin's readings and drafts fail to align with the documented sequence of his ideas leading to the Origin of Species, the modeling would not capture the intended search process.
Figures

















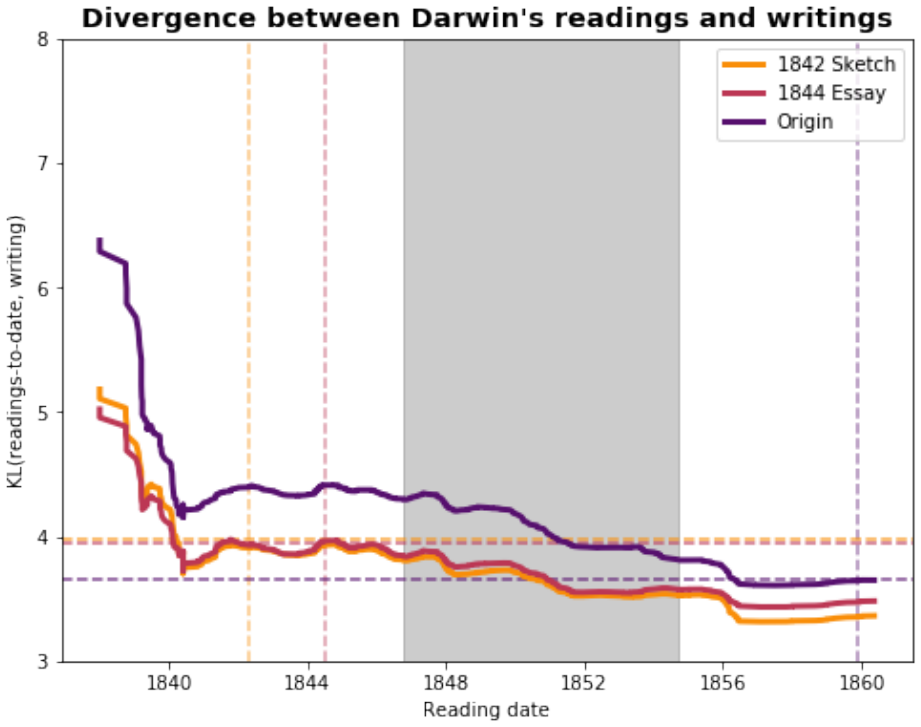
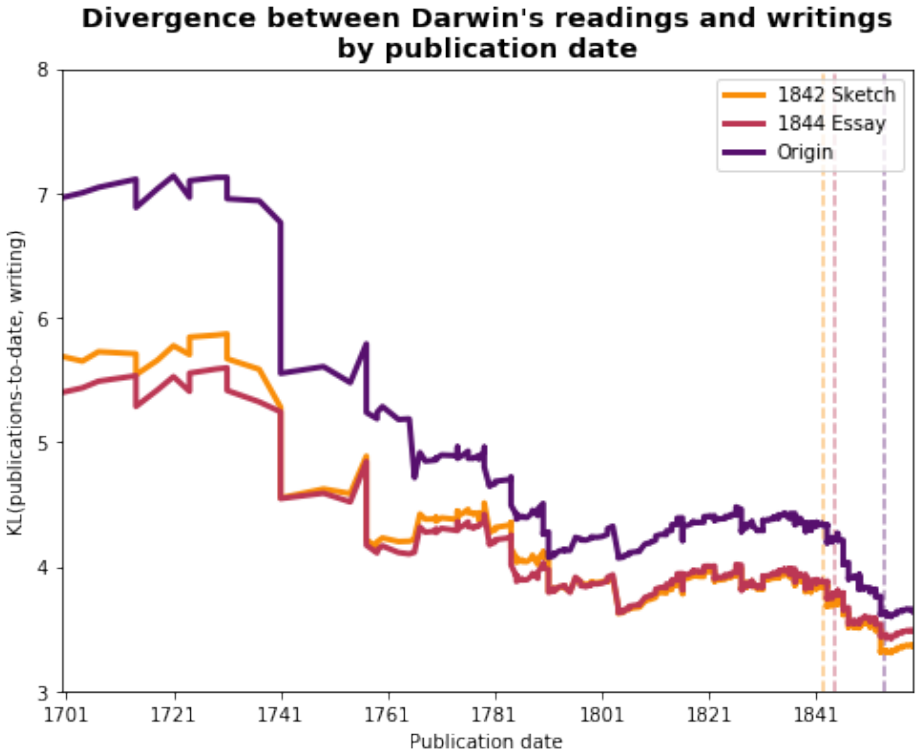
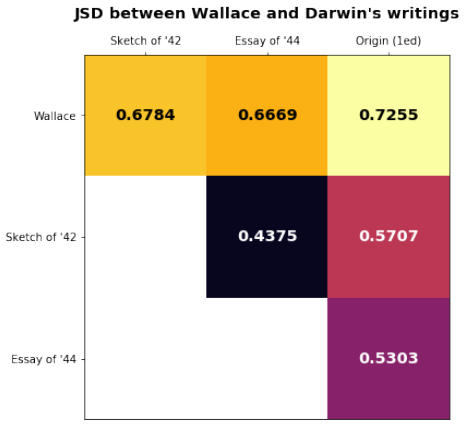





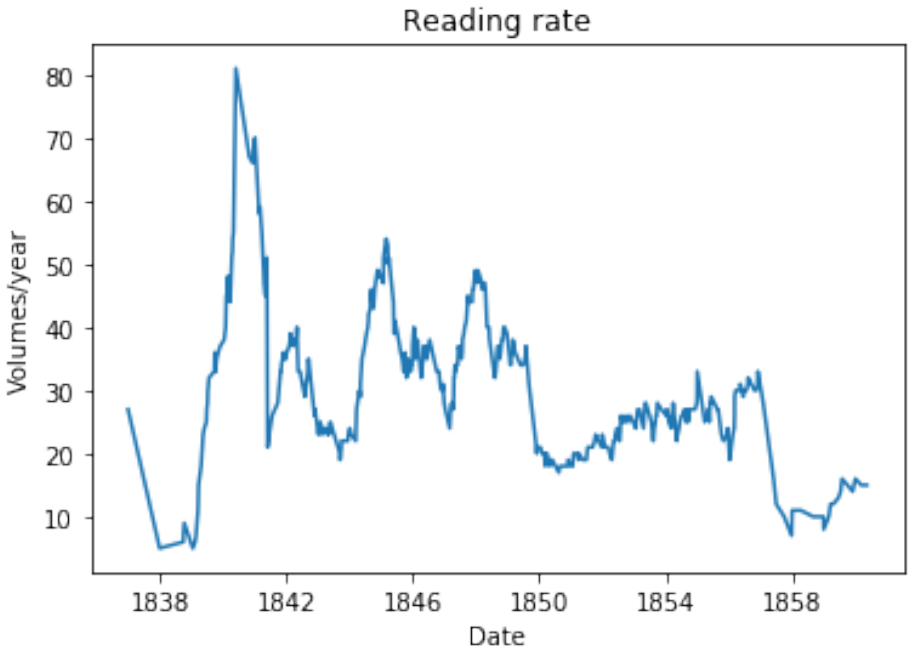





read the original abstract
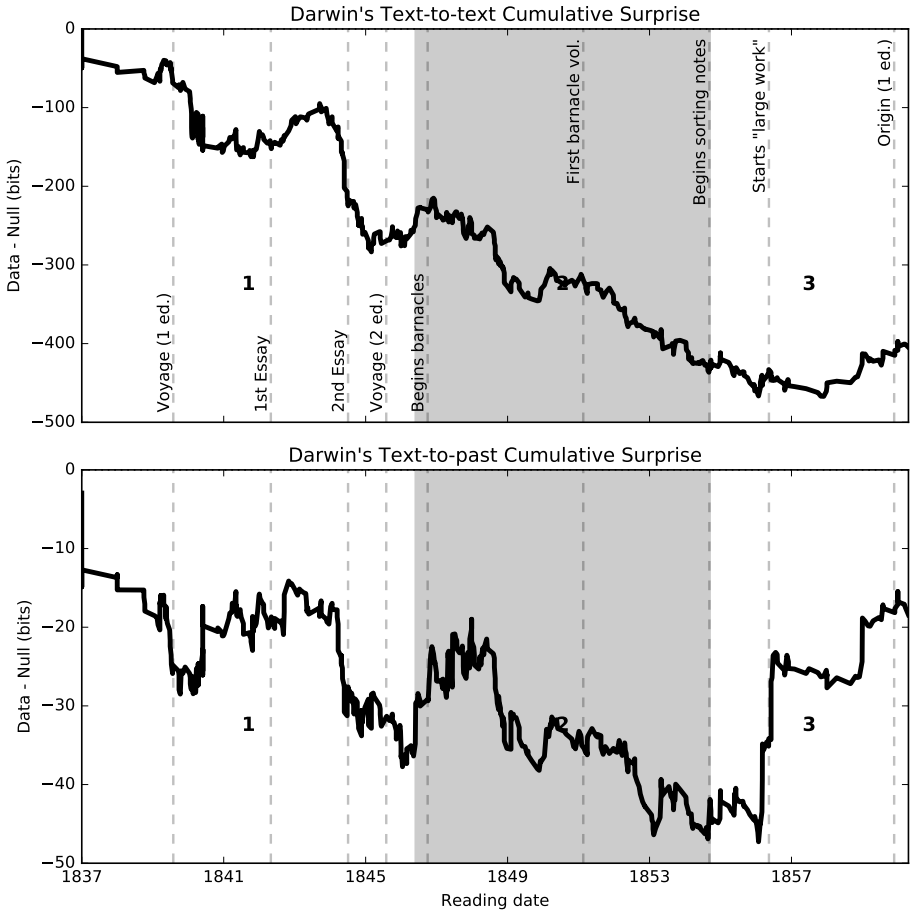
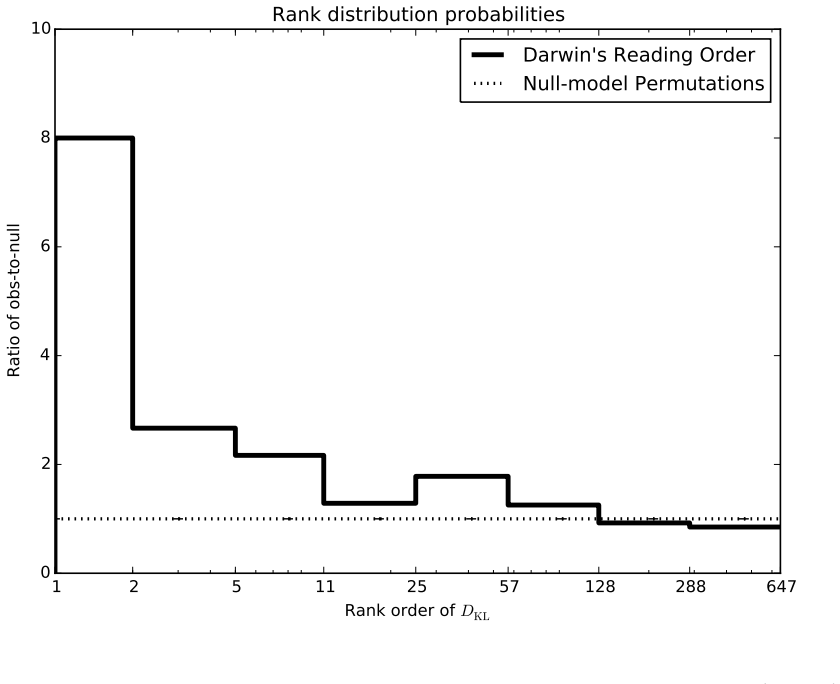
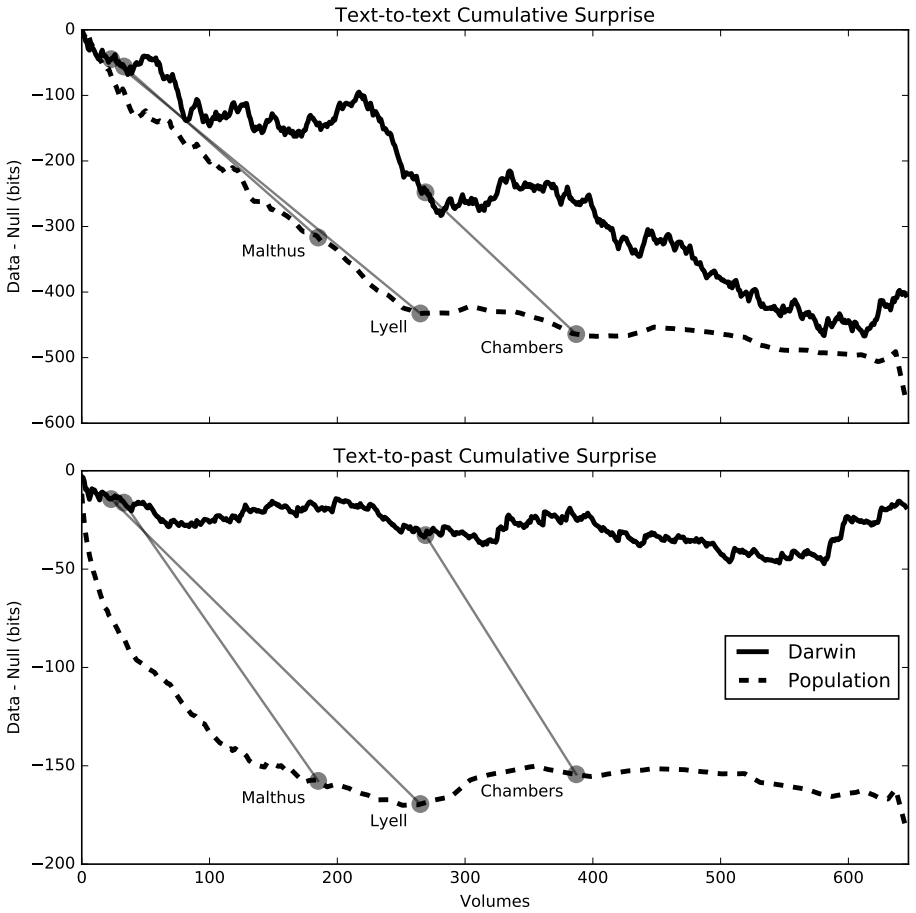
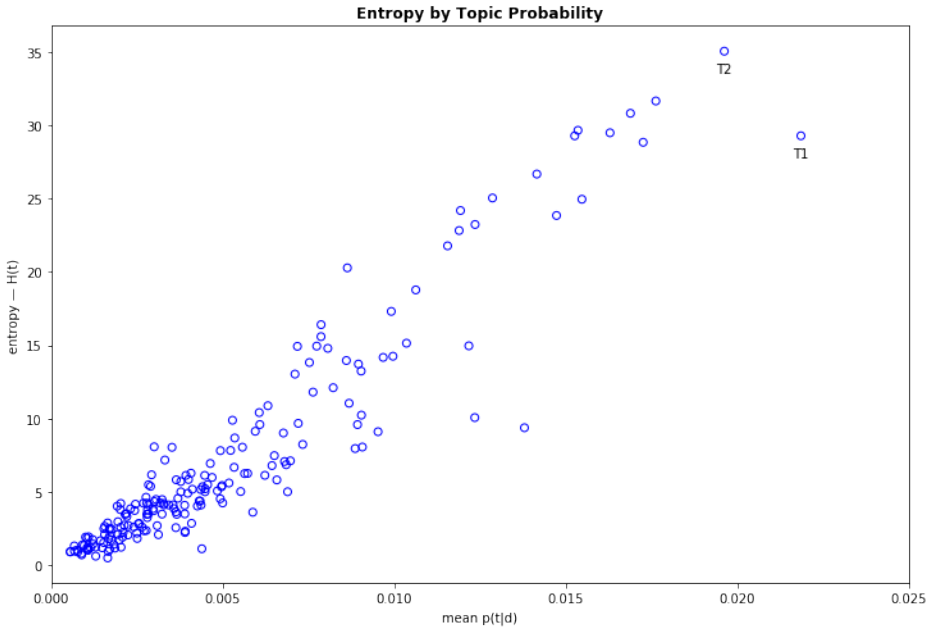
The general problem of "information foraging" in an environment about which agents have incomplete information has been explored in many fields, including cognitive psychology, neuroscience, economics, finance, ecology, and computer science. In all of these areas, the searcher aims to enhance future performance by surveying enough of existing knowledge to orient themselves in the information space. Individuals can be viewed as conducting a cognitive search in which they must balance exploration of ideas that are novel to them against exploitation of knowledge in domains in which they are already expert. In this dissertation, I present several case studies that demonstrate how reading and writing behaviors interact to construct personal knowledge bases. These studies use LDA topic modeling to represent the information environment of the texts each author read and wrote. Three studies revolve around Charles Darwin. Darwin left detailed records of every book he read for 23 years, from disembarking from the H.M.S. Beagle to just after publication of The Origin of Species. Additionally, he left copies of his drafts before publication. I characterize his reading behavior, then show how that reading behavior interacted with the drafts and subsequent revisions of The Origin of Species, and expand the dataset to include later readings and writings. Then, through a study of Thomas Jefferson's correspondence, I expand the study to non-book data. Finally, through an examination of neuroscience citation data, I move from individual behavior to collective behavior in constructing an information environment. Together, these studies reveal "the interplay between individual and collective phenomena where innovation takes place" (Tria et al. 2014).
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents case studies applying LDA topic modeling to Charles Darwin's reading records and drafts (including pre- and post-Origin of Species), Thomas Jefferson's correspondence, and neuroscience citation networks. These are used to characterize individual reading/writing behaviors as cognitive search balancing exploration and exploitation, then to illustrate interactions that construct personal knowledge bases and the interplay between individual and collective phenomena in innovation.
Significance. If the LDA-derived topics can be shown to validly represent information environments and search dynamics, the work would offer a computational lens on knowledge construction across historical and modern datasets; the multi-scale design (individual to collective) is a potential strength, but the absence of validation, quantitative metrics, or error analysis in the described studies limits immediate impact.
major comments (3)
- [Abstract] Abstract and method description: the central claim that LDA topic models of read/written texts accurately represent both the external information environment and the internal cognitive search process (exploration vs. exploitation) is load-bearing for all three case studies, yet no validation against independent measures of novelty, expertise, or search dynamics is described; LDA yields unsupervised co-occurrence clusters whose mapping to cognitive constructs remains untested.
- [Abstract] Abstract: the headline result that the studies reveal 'the interplay between individual and collective phenomena where innovation takes place' rests on descriptive case studies, but the abstract supplies no equations, fitted parameters, quantitative results, error analysis, or statistical tests, preventing verification that the observed patterns support the claimed interplay.
- [Case Studies] Darwin case study (and extension to Jefferson/neuroscience): domain-specific issues such as 19th-century language shift, non-book formats, and citation-text peculiarities are not addressed, yet these directly affect whether the topic clusters can be interpreted as faithful representations of the information environment.
minor comments (2)
- [Abstract] The abstract references expanding the Darwin dataset to later readings/writings but provides no details on how the LDA models were trained, preprocessed, or evaluated across the different corpora.
- [Abstract] Citation to Tria et al. 2014 is used to frame the collective claim, but the manuscript does not specify how the present LDA results quantitatively connect to or extend that prior work.
Simulated Author's Rebuttal
Thank you for the referee's constructive comments. We address each major point below, indicating planned revisions where appropriate to clarify the methodological approach and limitations of the case studies.
read point-by-point responses
-
Referee: [Abstract] Abstract and method description: the central claim that LDA topic models of read/written texts accurately represent both the external information environment and the internal cognitive search process (exploration vs. exploitation) is load-bearing for all three case studies, yet no validation against independent measures of novelty, expertise, or search dynamics is described; LDA yields unsupervised co-occurrence clusters whose mapping to cognitive constructs remains untested.
Authors: The manuscript uses LDA to derive topic distributions as a proxy for the information environment based on textual co-occurrences, with interpretations of exploration/exploitation grounded in alignment with each individual's documented historical activities and outputs. We acknowledge that no independent quantitative validation (e.g., against expert ratings or behavioral metrics) is presented. We will revise the methods and discussion sections to explicitly note the unsupervised nature of the clusters and the interpretive basis for cognitive mapping, while adding a limitations subsection on this point. revision: yes
-
Referee: [Abstract] Abstract: the headline result that the studies reveal 'the interplay between individual and collective phenomena where innovation takes place' rests on descriptive case studies, but the abstract supplies no equations, fitted parameters, quantitative results, error analysis, or statistical tests, preventing verification that the observed patterns support the claimed interplay.
Authors: The work consists of descriptive case studies illustrating patterns across scales rather than a parametric or statistical modeling paper; the abstract therefore provides a high-level summary. The full manuscript details the LDA-derived topics and their correspondence to known shifts in reading/writing behavior. We will revise the abstract to reference the multi-scale design and the specific qualitative patterns (e.g., topic transitions in Darwin's drafts) that support the claimed interplay. revision: partial
-
Referee: [Case Studies] Darwin case study (and extension to Jefferson/neuroscience): domain-specific issues such as 19th-century language shift, non-book formats, and citation-text peculiarities are not addressed, yet these directly affect whether the topic clusters can be interpreted as faithful representations of the information environment.
Authors: These domain factors can influence topic coherence and are not explicitly discussed in the current text. Standard LDA preprocessing was applied across datasets. We will add targeted discussion in the methods and each case-study section addressing language evolution, non-book formats, and citation characteristics, along with any mitigation steps used. revision: yes
Circularity Check
No circularity: descriptive LDA case studies with external citation
full rationale
The paper applies standard LDA topic modeling to historical reading/writing records (Darwin's books and drafts, Jefferson correspondence, neuroscience citations) to produce descriptive characterizations of information environments. No equations, fitted parameters, or predictions are defined in terms of the outputs themselves. The central claim quotes an external 2014 paper (Tria et al.) rather than relying on self-citation chains or uniqueness theorems. All steps remain interpretive applications of an off-the-shelf unsupervised method to external data sources; nothing reduces by construction to the paper's own inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LDA topic modeling can represent the information environment of the texts each author read and wrote
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
These studies use LDA topic modeling to represent the information environment of the texts each author read and wrote... quantify the relative surprise of these decisions... using information theoretic measures
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Formation of Scientific Fields as a Universal Topological Transition
DOI: 10.1002/hbm.24038. Allen, Colin, Hongliang Luo, Jaimie Murdock, Jianghuai Pu, Xiaohong Wang, Yanjie Zhai, and Kun Zhao (2017). “Topic Modeling the H `an di ˘an Ancient Classics”. Journal of Cultural Analytics . DOI: 10 . 22148/16.016. Andrieu, Christophe, Nando de Freitas, Arnaud Doucet, and Michael I. Jordan (2003). “An Introduction to Markov chain ...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1002/hbm.24038 2017
-
[2]
BTM: Topic Modeling over Short Texts
DOI: 10.1016/0010-0285(73)90004-2. Cheng, Xueqi, Xiaohui Yan, Yanyan Lan, and Jiafeng Guo (2014). “BTM: Topic Modeling over Short Texts”. IEEE Transactions on Knowledge and Data Engineering 26.12, pp. 2928–2941. DOI: 10 . 1109/TKDE.2014.2313872. Chi, Ed H., Peter Pirolli, and James Pitkow (2001). “Using Information Scent to Model User Information Needs an...
-
[3]
The Darwin Reading Notebooks (1838–1860)
DOI: 10.1002/smj.738. van Hulle, Dirk (2014). Modern Manuscripts: The Extended Mind and Creative Undoing from Darwin to Beckett and Beyond. Historicizing Modernism. Bloomsbury Academic. Van Wyhe, John (2013). Dispelling the Darkness: Voyage in the Malay Archipelago and the Discovery of Evolution by Wallace and Darwin. World Scientific Publishing Company In...
-
[4]
The Wisdom of the Crowd in Combinatorial Problems
DOI: 10.1038/nmeth.1635. Yi, Sheng Kung Michael, Mark Steyvers, Michael D. Lee, and Matthew J. Dry (2012). “The Wisdom of the Crowd in Combinatorial Problems”. Cognitive Science 36.3, pp. 452–470. DOI: 10.1111/j.1551- 6709.2011.01223.x. Youn, Hyejin, Deborah Strumsky, Luis M.A. A Bettencourt, and Jos´e Lobo (2015). “Invention as a combi- natorial process:...
-
[5]
Topic Modeling the H\`an di\u{a}n Ancient Classics
Colin Allen, Hongliang Luo, Jaimie Murdock, Jianghuai Pu, Xiaohong Wang, Yanjie Zhai, and Zhao Kun. “Topic Modeling the Hàn diăn Ancient Classics (ࠡܞׅݱ.”) Journal of Cultural Analytics (2017). doi: 10.22148/16.016. arXiv: 1702.00860
work page internal anchor Pith review Pith/arXiv arXiv doi:10.22148/16.016 2017
-
[6]
Multi-level computational methods for interdisciplinary research in the HathiTrust Digital Library
Jaimie Murdock, Colin Allen, Katy Börner, Robert Light, Simon McAlister, Robert Rose, Doori Rose, Jun Otsuka, David Bourget, John Lawrence, Andrew Ravenscroft, and Chris Reed. “Multi-level Computational Methods for Interdisciplinary Research in the HathiTrust Digital Library”. PLOS ONE 12.9 (2017), e0184188. doi: 10.1371/journal.pone.0184188. arXiv: 1702.01090
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1371/journal.pone.0184188 2017
-
[7]
Exploration and Exploitation of Victorian Science in Darwin's Reading Notebooks
Jaimie Murdock, Colin Allen, and Simon DeDeo. “Exploration and Exploitation of Victorian Science in Darwin’s Reading Notebooks”. Cognition 159 (2017), pp. 117–126. doi: 10.1016/ j.cognition.2016.11.012. arXiv: 1509.07175
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[8]
The Wisdom of the Few? "Supertaggers" in Collaborative Tagging Systems
Jared Lorince, Sam Zorowitz, Jaimie Murdock, and Peter Todd. “Wisdom of the Few? “Su- pertaggers” in Collaborative Tagging Systems”. Journal of Web Science 1.1 (2015). doi: 10.1561/106.00000002. arXiv: 1502.02777. Book Chapters
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1561/106.00000002 2015
-
[9]
Jaimie Murdock, Cameron Buckner, and Colin Allen. “Evaluating Dynamic Ontologies”. In: Knowledge Discovery, Knowledge Engineering, and Knowledge Management: Second Interna- tional Joint Conference, IC3K 2010, Valencia, Spain, October 25-28, 2010, Revised Selected Papers. Ed. by Ana Fred, Jan L. G. Dietz, Kecheng Liu, and Joaquim Filipe. Vol. 272. Com- mun...
-
[10]
Jaimie Murdock. “Computational Discovery”. In: The Dynamics of Science: Computational Frontiers in History and Philosophy of Science . Ed. by Grant Ramsay and Andreas De Block. University of Pittsburgh Press, accepted
-
[11]
Jaimie Murdock, Colin Allen, and Simon DeDeo. “Darwin’s Semantic Voyage”. In: The Dy- namics of Science: Computational Frontiers in History and Philosophy of Science . Ed. by Grant Ramsay and Andreas De Block. University of Pittsburgh Press, accepted. Conference Papers
-
[12]
The Development of Darwin's Origin of Species
Jaimie Murdock, Colin Allen, and Simon DeDeo. “Quantitative and Qualitative Approaches to the Development of Darwin’s Origin of Species”. Current Research in Digital History 1 (2018). doi: 10.31835/crdh.2018.14. arXiv: 1802.09944
work page internal anchor Pith review Pith/arXiv arXiv doi:10.31835/crdh.2018.14 2018
-
[13]
Towards Publishing Secure Capsule-Based Analysis
Jaimie Murdock, Jacob Jett, Tim Cole, Yu Ma, J. Stephen Downie, and Beth Plale. “Towards Publishing Secure Capsule-Based Analysis”. 2017 ACM/IEEE Joint Conference on Digital Libraries (JCDL). Toronto, Ontario, Canada, June 2017. doi: 10.1109/JCDL.2017.7991585
-
[14]
Jared Lorince, Sam Zorowitz, Jaimie Murdock, and Peter Todd. ““Supertagger” behavior in building folksonomies”. WebSci ’14: Proceedings of the 2014 ACM Conference on Web Science. Bloomington, Indiana, USA, June 2014, pp. 129–138. doi: 10.1145/2615569.2615686
-
[15]
Containing the Semantic Explosion
Jaimie Murdock, Cameron Buckner, and Colin Allen. “Containing the Semantic Explosion”. Proceedings of the WWW2012 conference workshop PhiloWeb 2012: “Web and Philosophy, Why and What For?” Ed. by Alexandre Monnin, Harry Halpin, and Leslie Carr. Vol. 859. CEUR Workshop Proceedings. Apr. 2012
work page 2012
-
[16]
InPhO for All: Why APIs Matter
Jaimie Murdock and Colin Allen. “InPhO for All: Why APIs Matter”. Journal of the Chicago Colloquium on Digital Humanities and Computer Science 1.3 (Nov. 2011)
work page 2011
-
[17]
Identifying Species by Genetic Clustering
Jaimie Murdock and Larry S. Yaeger. “Identifying Species by Genetic Clustering”. Advances in Artificial Life: 20th Anniversary Edition - Back to the Origins of Alife, ECAL 2011 . Paris, France: MIT Press, Aug. 2011, pp. 564–572
work page 2011
-
[18]
Two Methods for Evaluating Dynamic Ontologies
Jaimie Murdock, Cameron Buckner, and Colin Allen. “Two Methods for Evaluating Dynamic Ontologies”. Proceedings of the 2nd International Conference on Knowledge Engineering and Ontology Development (KEOD) . Ed. by Ana Fred and Joaquim Filipe. Vol. 272. Revised and expanded in [ 5]. Valencia, Spain: Springer-Verlag, Oct. 2010, pp. 110–122. doi: 10.5220/ 000...
work page 2010
-
[19]
Enhancing Access to Digital Media: The Language Application Grid in the HTRC Data Capsule
James Pustejovsky, Marc Verhagen, Keongmin Rim, Yu Ma, Liang Ran, Samitha Liyanage, Jaimie Murdock, Robert H. McDonald, and Beth Plale. “Enhancing Access to Digital Media: The Language Application Grid in the HTRC Data Capsule”. PEARC ’17: Proceedings of the Practice and Experience in Advanced Research Computing 2017 on Sustainability, Success and Impact....
-
[20]
Visualization Techniques for Topic Model Checking
Jaimie Murdock and Colin Allen. “Visualization Techniques for Topic Model Checking”. AAAI-15: Proceedings of the Twenty-Ninth AAAI Conference on Artificial Intelligence . Demo of https://hypershelf.org. Jan. 2015, pp. 4284–4285
work page 2015
-
[21]
Topic Exploration with the HTRC Data Capsule for Non-Consumptive Research
Jaimie Murdock, Jiaan Zeng, and Robert H. McDonald. “Topic Exploration with the HTRC Data Capsule for Non-Consumptive Research”. JCDL ’15: Proceedings of the 15th ACM/IEEE- CS Joint Conference on Digital Libraries . Tutorial. Knoxville, Tennessee, USA, June 2015, p. 295. doi: 10.1145/2756406.2756929
-
[22]
LODE: Linking Digital Humanities Content to the Web of Data
Timo Sztyler, Jakob Huber, Jan Noessner, Jaimie Murdock, Colin Allen, and Mathias Niepert. “LODE: Linking Digital Humanities Content to the Web of Data”. JCDL ’14: Proceedings of the 14th ACM/IEEE-CS Joint Conference on Digital Libraries . Demo. London, United Kingdom, Sept. 2014, pp. 423–424
work page 2014
-
[23]
Mapping the Intersection of Science and Philosophy
Jaimie Murdock, Robert Light, Colin Allen, and Katy Börner. “Mapping the Intersection of Science and Philosophy”. JCDL ’13, Proceedings of the 13th ACM/IEEE-CS Joint Conference on Digital Libraries . Poster. Indianapolis, Indiana, USA, July 2013, pp. 405–406. doi: 10. 1145/2467696.2467777
-
[24]
Genetic Clustering for the Identification of Species
Jaimie Murdock and Larry S. Yaeger. “Genetic Clustering for the Identification of Species”. GECCO ’11. Proceedings of the 13th Annual Conference Companion on Genetic and Evolu- tionary Computation . Poster. Expanded in [ 13]. Dublin, Ireland, July 2011, pp. 29–30. doi: 10.1145/2001858.2001875
-
[25]
InPhO: A System for Collaboratively Populating and Extending a Dynamic Ontology
Mathias Niepert, Cameron Buckner, Jaimie Murdock, and Colin Allen. “InPhO: A System for Collaboratively Populating and Extending a Dynamic Ontology”. JCDL ’08: Proceedings of the 8th ACM/IEEE-CS Joint Conference on Digital Libraries . Pittsburgh, Pennsylvania, USA, June 2008, p. 429. doi: 10.1145/1378889.1378976. Miscellaneous
-
[26]
Towards Evaluation of Cultural-scale Claims in Light of Topic Model Sampling Effects
Jaimie Murdock, Jiaan Zeng, and Colin Allen. Towards Evaluation of Cultural-scale Claims in Light of Topic Model Sampling Effects . Advanced Collaborative Support Technical Report. HathiTrust Research Center, June 2016. arXiv: 1512.05004
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[27]
LODE: Linking Digital Humanities Content to the Web of Data
Jakob Huber, Timo Sztyler, Jan Noessner, Jaimie Murdock, Colin Allen, and Mathias Niepert. LODE: Linking Digital Humanities Conetnt to the Web of Data . Expanded pre-print of abstract published in [ 18]. 2014. arXiv: 1406.0216
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[28]
Computational Phi- losophy and the Examined Text: A Tale of Two Encyclopedias
Colin Allen, Jaimie Murdock, Cameron Buckner, and Robert Rose. “Computational Phi- losophy and the Examined Text: A Tale of Two Encyclopedias”. American Philosophical Association Newsletter on Philosophy and Computers 12.2 (2013), pp. 28–30
work page 2013
-
[29]
Cross-Cutting Categorization Schemes in the Digital Humanities
Colin Allen and the InPhO Group. “Cross-Cutting Categorization Schemes in the Digital Humanities”. Isis 104.3 (2013), pp. 573–583. doi: 10.1086/673276. TEACHING Indiana University , Bloomington, IN Foundations in Science and Mathematics Introduction to Computer Science June 2016 Introduction to Computer Science June 2015 Department of History and Philosop...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.