The Receptive Field as a Regularizer in Deep Convolutional Neural Networks for Acoustic Scene Classification
Pith reviewed 2026-05-25 10:03 UTC · model grok-4.3
The pith
Receptive field size acts as a regularizer that lets adapted ResNet and DenseNet outperform VGG models on acoustic scene classification.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
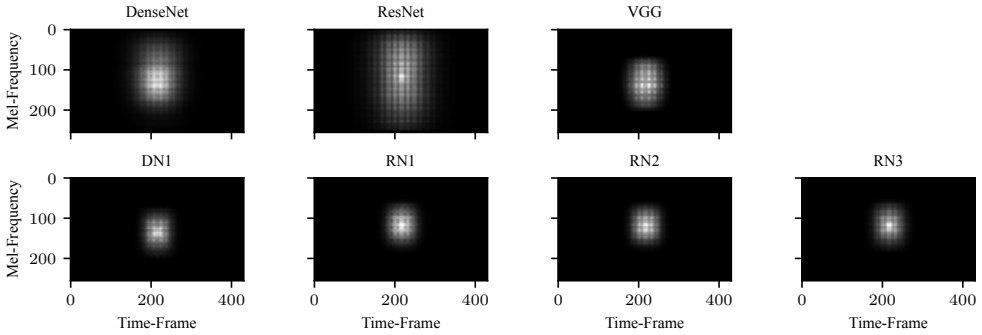
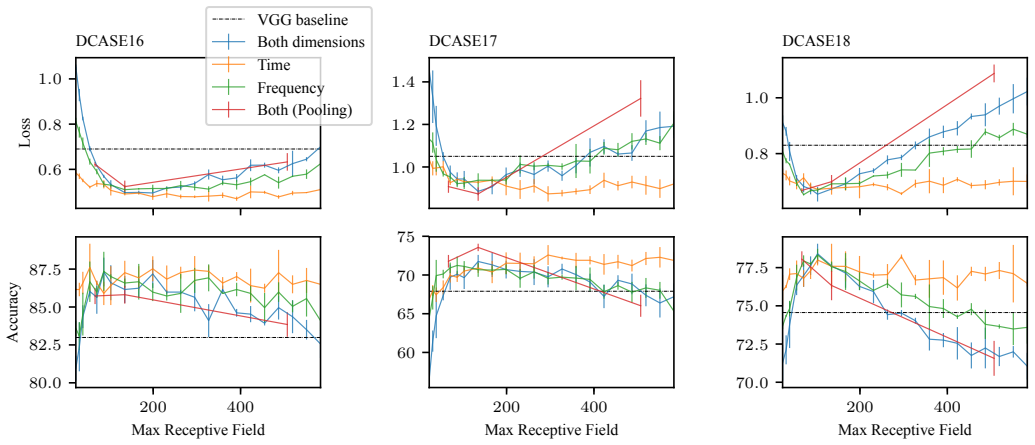
The receptive field size in CNNs serves as a regularizer for acoustic scene classification. Very small or very large receptive fields cause performance degradation, yet deep models generalize well once an appropriate receptive field size is chosen within a suitable range. Systematic adaptation of receptive fields in ResNet and DenseNet produces models that achieve state-of-the-art results and outperform VGG-based approaches on multiple audio datasets.
What carries the argument
Receptive field (RF) size of CNN units, the effective input region influencing each activation, adjusted separately over time and frequency axes to control regularization strength.
If this is right
- Adapted deep CNNs reach state-of-the-art acoustic scene classification by matching receptive field to audio spectrogram structure.
- Model performance degrades outside an intermediate receptive field range on three evaluated datasets.
- Systematic receptive field adaptation methods transfer to other deep architectures for audio tasks.
- Receptive field size functions as an independent regularizer alongside standard techniques.
Where Pith is reading between the lines
- Receptive field tuning may benefit CNN design for other anisotropic signals such as video or sensor time series.
- Architecture search procedures could incorporate receptive field size as an explicit hyperparameter rather than an afterthought.
- The same receptive field analysis might clarify performance gaps between architectures in additional non-image domains.
Load-bearing premise
Differences in receptive field size are the main reason deep architectures lag behind VGG on acoustic scene classification rather than training dynamics or other optimization factors.
What would settle it
A controlled experiment in which unmodified ResNet or DenseNet matches or exceeds VGG performance on the same ASC datasets after identical training procedures would falsify the necessity of receptive field adaptation.
Figures
read the original abstract
Convolutional Neural Networks (CNNs) have had great success in many machine vision as well as machine audition tasks. Many image recognition network architectures have consequently been adapted for audio processing tasks. However, despite some successes, the performance of many of these did not translate from the image to the audio domain. For example, very deep architectures such as ResNet and DenseNet, which significantly outperform VGG in image recognition, do not perform better in audio processing tasks such as Acoustic Scene Classification (ASC). In this paper, we investigate the reasons why such powerful architectures perform worse in ASC compared to simpler models (e.g., VGG). To this end, we analyse the receptive field (RF) of these CNNs and demonstrate the importance of the RF to the generalization capability of the models. Using our receptive field analysis, we adapt both ResNet and DenseNet, achieving state-of-the-art performance and eventually outperforming the VGG-based models. We introduce systematic ways of adapting the RF in CNNs, and present results on three data sets that show how changing the RF over the time and frequency dimensions affects a model's performance. Our experimental results show that very small or very large RFs can cause performance degradation, but deep models can be made to generalize well by carefully choosing an appropriate RF size within a certain range.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript analyzes why deep CNNs such as ResNet and DenseNet underperform simpler VGG-based models on acoustic scene classification (ASC). It attributes the gap to receptive-field (RF) size, introduces systematic adaptations (kernel sizes, dilations, pooling strides) to control RF over time and frequency axes, and reports that the adapted ResNet and DenseNet reach state-of-the-art results on three datasets while outperforming the VGG baselines. The authors conclude that very small or very large RFs degrade generalization while an appropriate intermediate range enables deep models to perform well.
Significance. If the performance gains can be shown to stem specifically from RF size rather than correlated changes in capacity or optimization, the work would supply a practical design rule for transferring vision architectures to audio and would position RF size as an explicit regularizer in ASC models.
major comments (2)
- [Results / experimental evaluation] The central empirical claim (abstract and results sections) requires that RF size is the primary causal factor behind the performance gap versus VGG. The reported adaptations alter kernel sizes, dilations or pooling strides; these changes simultaneously modify parameter count, effective depth, gradient flow and the optimization landscape. No ablation is described that holds all other hyperparameters, initialization, data augmentation and training schedule fixed while varying only the RF-controlling elements. Without such a control, the observed gains cannot be unambiguously attributed to RF size.
- [Results] Table or figure reporting the final accuracies on the three datasets: the manuscript states that the adapted models outperform VGG, yet the text does not quantify how much of the improvement is retained when the same RF size is imposed on the original VGG architecture or when RF is varied while freezing all other architectural choices. This comparison is load-bearing for the claim that RF adaptation explains the superiority of the modified ResNet/DenseNet.
minor comments (2)
- [Receptive-field analysis] Notation for receptive-field calculation (likely §3) should be made fully explicit, including the precise formula used for cumulative RF over time versus frequency dimensions.
- [Abstract / Experiments] The abstract lists three datasets but does not name them; the experimental section should state the dataset names, official splits, and any preprocessing steps in the first paragraph of the results.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. The concerns about isolating receptive-field size as the causal factor are well-taken, and we will strengthen the manuscript with additional controlled experiments.
read point-by-point responses
-
Referee: [Results / experimental evaluation] The central empirical claim (abstract and results sections) requires that RF size is the primary causal factor behind the performance gap versus VGG. The reported adaptations alter kernel sizes, dilations or pooling strides; these changes simultaneously modify parameter count, effective depth, gradient flow and the optimization landscape. No ablation is described that holds all other hyperparameters, initialization, data augmentation and training schedule fixed while varying only the RF-controlling elements. Without such a control, the observed gains cannot be unambiguously attributed to RF size.
Authors: We agree that a stricter isolation of RF size is needed. Our systematic adaptations were designed to target RF over time and frequency while preserving the core architecture, and we already show performance sensitivity to RF size on three datasets. However, we did not include an ablation that holds parameter count, depth, initialization, augmentation and schedule exactly fixed. We will add such an ablation (e.g., varying only dilation rates) in the revised manuscript. revision: yes
-
Referee: [Results] Table or figure reporting the final accuracies on the three datasets: the manuscript states that the adapted models outperform VGG, yet the text does not quantify how much of the improvement is retained when the same RF size is imposed on the original VGG architecture or when RF is varied while freezing all other architectural choices. This comparison is load-bearing for the claim that RF adaptation explains the superiority of the modified ResNet/DenseNet.
Authors: We agree that direct RF-controlled comparisons with VGG would strengthen the argument. The current results compare adapted ResNet/DenseNet against standard VGG baselines. In revision we will add a table/figure that imposes comparable RF sizes on VGG (via the same kernel/dilation/pooling adjustments) and reports the resulting accuracies to quantify how much of the gain is retained. revision: yes
Circularity Check
No circularity; empirical RF adaptation validated on held-out data
full rationale
The paper performs an empirical investigation: it measures receptive-field sizes across architectures, modifies kernel/dilation/pooling parameters to control RF on time and frequency axes, trains the resulting models on three ASC datasets, and reports accuracy. No derivation, equation, or uniqueness theorem is invoked that reduces the final performance claim to a fitted parameter or self-citation by construction. All reported gains are obtained by retraining and evaluating on standard splits; the central result is therefore falsifiable against external benchmarks and does not collapse to its own inputs.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We introduce systematic ways of adapting the RF in CNNs... very small or very large RFs can cause performance degradation
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Equation (1) shows that there are various ways to modify the RF of a CNN
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Deep residual learning for image recognition,
K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 770–778
-
[2]
Densely connected convolutional networks,
G. Huang, Z. Liu, L. Van Der Maaten, and K. Q. Weinberger, “Densely connected convolutional networks,” in Proceedings of the IEEE Confer- ence on Computer Vision and Pattern Recognition , pp. 4700–4708
-
[3]
Very Deep Convolutional Networks for Large-Scale Image Recognition
K. Simonyan and A. Zisserman, “Very Deep Convolutional Networks for Large-Scale Image Recognition.” [Online]. Available: http: //arxiv.org/abs/1409.1556
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
H. Eghbal-Zadeh, B. Lehner, M. Dorfer, and G. Widmer, “CP-JKU sub- missions for DCASE-2016: A hybrid approach using binaural i-vectors and deep convolutional neural networks.” DCASE2016 Challenge
work page 2016
-
[5]
B. Lehner, H. Eghbal-Zadeh, M. Dorfer, F. Korzeniowski, K. Koutini, and G. Widmer, “Classifying short acoustic scenes with I-vectors and CNNs: Challenges and optimisations for the 2017 DCASE ASC task.” DCASE2017 Challenge
work page 2017
-
[6]
Acoustic Scene Classification with Fully Convolutional Neural Networks and I-Vectors
M. Dorfer, B. Lehner, H. Eghbal-zadeh, C. Heindl, F. Paischer, and G. Widmer, “Acoustic Scene Classification with Fully Convolutional Neural Networks and I-Vectors.” DCASE2018 Challenge
-
[7]
Acoustic Scene Classification by Ensemble of Spectrograms Based on Adaptive Temporal Divisions
Y . Sakashita and M. Aono, “Acoustic Scene Classification by Ensemble of Spectrograms Based on Adaptive Temporal Divisions.” DCASE2018 Challenge
-
[8]
CNN architectures for large-scale audio classification,
S. Hershey, S. Chaudhuri, D. P. W. Ellis, J. F. Gemmeke, A. Jansen, R. C. Moore, M. Plakal, D. Platt, R. A. Saurous, B. Seybold, M. Slaney, R. J. Weiss, and K. Wilson, “CNN architectures for large-scale audio classification,” in 2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , pp. 131–135
work page 2017
-
[9]
Training general-purpose audio tagging networks with noisy labels and iterative self-verification,
M. Dorfer and G. Widmer, “Training general-purpose audio tagging networks with noisy labels and iterative self-verification,” inProceedings of the Detection and Classification of Acoustic Scenes and Events 2018 Workshop (DCASE2018), pp. 178–182
work page 2018
-
[10]
Stacked Convolutional Neural Networks for General-purpose Audio Tagging
T. Iqbal, Q. Kong, M. Plumbley, and W. Wang, “Stacked Convolutional Neural Networks for General-purpose Audio Tagging.” DCASE2018 Challenge
-
[11]
D. Lee, S. Lee, Y . Han, and K. Lee, “Ensemble of Convolutional Neural Networks for Weakly-Supervised Sound Event Detection Using Multiple Scale Input.” DCASE2017 Challenge
-
[12]
Iterative knowledge distillation in R-CNNs for weakly-labeled semi-supervised sound event detection,
K. Koutini, H. Eghbal-zadeh, and G. Widmer, “Iterative knowledge distillation in R-CNNs for weakly-labeled semi-supervised sound event detection,” in Proceedings of the Detection and Classification of Acoustic Scenes and Events 2018 Workshop (DCASE2018) , pp. 173–177
work page 2018
-
[13]
Experimenting with musically motivated convolutional neural networks,
J. Pons, T. Lidy, and X. Serra, “Experimenting with musically motivated convolutional neural networks,” in 2016 14th International Workshop on Content-Based Multimedia Indexing (CBMI) , pp. 1–6
work page 2016
-
[14]
Understanding the Effective Receptive Field in Deep Convolutional Neural Networks,
W. Luo, Y . Li, R. Urtasun, and R. Zemel, “Understanding the Effective Receptive Field in Deep Convolutional Neural Networks,” in Advances in Neural Information Processing Systems 29 , pp. 4898–4906
-
[15]
TUT database for acoustic scene classification and sound event detection,
A. Mesaros, T. Heittola, and T. Virtanen, “TUT database for acoustic scene classification and sound event detection,” in Signal Processing Conference (EUSIPCO), 2016 24th European . IEEE, pp. 1128–1132
work page 2016
-
[16]
DCASE 2017 challenge setup: Tasks, datasets and baseline system,
A. Mesaros, T. Heittola, A. Diment, B. Elizalde, A. Shah, E. Vincent, B. Raj, and T. Virtanen, “DCASE 2017 challenge setup: Tasks, datasets and baseline system,” in DCASE 2017-Workshop on Detection and Classification of Acoustic Scenes and Events
work page 2017
-
[17]
A multi-device dataset for urban acoustic scene classification,
A. Mesaros, T. Heittola, and T. Virtanen, “A multi-device dataset for urban acoustic scene classification,” in Proceedings of the Detection and Classification of Acoustic Scenes and Events 2018 Workshop (DCASE2018), pp. 9–13
work page 2018
-
[18]
Adam: A Method for Stochastic Optimization
D. P. Kingma and J. Ba, “Adam: A Method for Stochastic Optimization.” [Online]. Available: http://arxiv.org/abs/1412.6980
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
mixup: Beyond Empirical Risk Minimization
H. Zhang, M. Cisse, Y . N. Dauphin, and D. Lopez-Paz, “Mixup: Beyond Empirical Risk Minimization.” [Online]. Available: http: //arxiv.org/abs/1710.09412
work page internal anchor Pith review Pith/arXiv arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.