Automatic Radiology Report Generation based on Multi-view Image Fusion and Medical Concept Enrichment
Pith reviewed 2026-05-24 18:17 UTC · model grok-4.3
The pith
A generative encoder-decoder model fuses multi-view chest X-ray images and enriches them with medical concepts to generate radiology reports.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
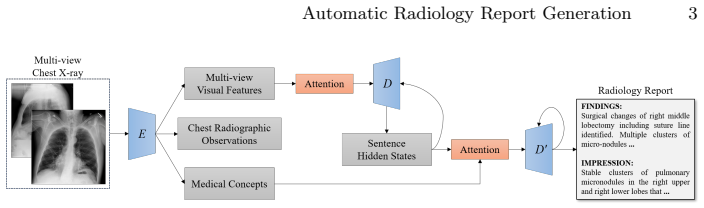
The authors introduce a generative encoder-decoder architecture that pretrains the encoder to recognize 14 radiographic observations with cross-view consistency, synthesizes multi-view features via sentence-level attention in late fusion, and fine-tunes the encoder to extract frequent medical concepts from images so these can be injected at each decoding step through word-level attention, thereby enforcing correctness on organ and diagnosis mentions.
What carries the argument
Generative encoder-decoder model that performs multi-view visual feature synthesis with sentence-level attention and injects medical concepts with word-level attention during decoding.
If this is right
- Multi-view fusion produces richer visual representations than single-view processing for chest X-ray interpretation.
- Medical concept enrichment reduces mismatches between generated text and deterministic clinical facts such as organ names or diagnoses.
- Pretraining on a large unlabeled image set followed by concept fine-tuning compensates for the small size of paired image-report datasets.
- The resulting reports contain more accurate mentions of observations while maintaining natural language flow.
Where Pith is reading between the lines
- The same fusion and enrichment steps could be tested on other paired image-report tasks such as pathology slide captioning.
- If concept extraction misses rare findings, the model may still generate incomplete reports on unusual cases.
- The cross-view consistency loss during pretraining might generalize to other multi-image modalities like CT slices.
Load-bearing premise
That pretraining an encoder on 14 observations and fine-tuning it to pull medical concepts from images will improve semantic correctness and clinical accuracy of the generated reports without adding new errors.
What would settle it
Running the model on a held-out test set of chest X-rays where radiologist ratings of clinical accuracy show no gain over a standard image-captioning baseline.
Figures


read the original abstract
Generating radiology reports is time-consuming and requires extensive expertise in practice. Therefore, reliable automatic radiology report generation is highly desired to alleviate the workload. Although deep learning techniques have been successfully applied to image classification and image captioning tasks, radiology report generation remains challenging in regards to understanding and linking complicated medical visual contents with accurate natural language descriptions. In addition, the data scales of open-access datasets that contain paired medical images and reports remain very limited. To cope with these practical challenges, we propose a generative encoder-decoder model and focus on chest x-ray images and reports with the following improvements. First, we pretrain the encoder with a large number of chest x-ray images to accurately recognize 14 common radiographic observations, while taking advantage of the multi-view images by enforcing the cross-view consistency. Second, we synthesize multi-view visual features based on a sentence-level attention mechanism in a late fusion fashion. In addition, in order to enrich the decoder with descriptive semantics and enforce the correctness of the deterministic medical-related contents such as mentions of organs or diagnoses, we extract medical concepts based on the radiology reports in the training data and fine-tune the encoder to extract the most frequent medical concepts from the x-ray images. Such concepts are fused with each decoding step by a word-level attention model. The experimental results conducted on the Indiana University Chest X-Ray dataset demonstrate that the proposed model achieves the state-of-the-art performance compared with other baseline approaches.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a generative encoder-decoder model for automatic radiology report generation from chest X-ray images. It pretrains the encoder on 14 radiographic observations while enforcing cross-view consistency, performs late multi-view feature fusion via sentence-level attention, and enriches the decoder by extracting and injecting frequent medical concepts from training reports using word-level attention. Experiments on the Indiana University Chest X-Ray dataset are claimed to achieve state-of-the-art performance over baselines.
Significance. If the empirical results and ablations hold, the work could be significant for medical image captioning by showing how pretraining on observations, multi-view fusion, and concept enrichment can address limited paired data and improve semantic accuracy in generated reports. The approach is consistent with contemporaneous encoder-decoder methods but adds targeted medical-domain adaptations.
major comments (2)
- [Abstract and §4] Abstract and §4 (Experimental Results): The central SOTA claim is asserted without any reported metrics (BLEU, METEOR, CIDEr, etc.), baseline details, statistical significance tests, or ablation results. This makes it impossible to determine whether gains arise from the proposed multi-view fusion and concept enrichment or from dataset artifacts or under-tuned baselines.
- [§3.3] §3.3 (Medical Concept Enrichment): The assumption that fine-tuning the encoder on report-derived concepts and injecting them via word-level attention will improve clinical accuracy without introducing new errors or biases is load-bearing for the correctness claim, yet no error analysis, ablation removing the concept module, or comparison of concept extraction precision is provided.
minor comments (2)
- [§3.2] The description of the sentence-level attention for multi-view fusion lacks an explicit equation or diagram, making the late-fusion mechanism harder to reproduce.
- [§2] Related work section should cite additional contemporaneous works on IU-CXR report generation for proper positioning.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and agree that revisions are needed to strengthen the empirical presentation.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and §4 (Experimental Results): The central SOTA claim is asserted without any reported metrics (BLEU, METEOR, CIDEr, etc.), baseline details, statistical significance tests, or ablation results. This makes it impossible to determine whether gains arise from the proposed multi-view fusion and concept enrichment or from dataset artifacts or under-tuned baselines.
Authors: We agree that the SOTA claim in the abstract and §4 lacks the necessary quantitative support. The submitted manuscript does not report specific metrics, baseline details, ablations, or significance tests. In the revised version we will add BLEU, METEOR, CIDEr (and other) scores, full baseline descriptions, ablation results isolating multi-view fusion and concept enrichment, and statistical significance tests. revision: yes
-
Referee: [§3.3] §3.3 (Medical Concept Enrichment): The assumption that fine-tuning the encoder on report-derived concepts and injecting them via word-level attention will improve clinical accuracy without introducing new errors or biases is load-bearing for the correctness claim, yet no error analysis, ablation removing the concept module, or comparison of concept extraction precision is provided.
Authors: We acknowledge that the manuscript provides no ablation, error analysis, or precision evaluation for the concept module. We will add an ablation that removes the concept enrichment component, include error analysis of generated reports with respect to clinical accuracy and potential biases, and report the precision of the concept extraction step. revision: yes
Circularity Check
No significant circularity
full rationale
The paper presents a standard encoder-decoder pipeline for report generation: pretraining an image encoder on 14 radiographic observations with cross-view consistency, late sentence-level attention for multi-view fusion, and word-level attention to inject report-derived medical concepts. No equations, derivations, or uniqueness theorems are described that reduce by construction to fitted inputs or self-citations. The SOTA claim rests on empirical metrics on the external IU-CXR dataset rather than any self-definitional loop or renamed known result. The approach is self-contained against external benchmarks with no load-bearing self-citation chains or ansatzes smuggled via prior work.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We propose a generative encoder-decoder model... pretrain the encoder with... 14 common radiographic observations... sentence-level attention mechanism in a late fusion fashion... medical concepts... word-level attention model.
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
The experimental results... achieve the state-of-the-art performance
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Demner-Fushman, D., Kohli, M.D., Rosenman, M.B., Shooshan, S.E., Rodriguez, L., Antani, S.K., Thoma, G.R., McDonald, C.J.: Preparing a collection of radiology examinations for distribution and retrieval. JAMIA 23(2), 304–310 (2016)
work page 2016
-
[2]
In: Proceedings of the ninth workshop on statistical machine translation
Denkowski, M., Lavie, A.: Meteor universal: Language specific translation evalua- tion for any target language. In: Proceedings of the ninth workshop on statistical machine translation. pp. 376–380 (2014)
work page 2014
-
[3]
In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition
Feng, Y., Ma, L., Liu, W., Luo, J.: Unsupervised image captioning. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. pp. 4125– 4134 (2019) Automatic Radiology Report Generation 9
work page 2019
-
[4]
In: Proceedings of the IEEE conference on Computer Vision and Pattern Recognition
He, K., Zhang, X., Ren, S., Sun, J.: Deep residual learning for image recognition. In: Proceedings of the IEEE conference on Computer Vision and Pattern Recognition. pp. 770–778 (2016)
work page 2016
-
[5]
CheXpert: A Large Chest Radiograph Dataset with Uncertainty Labels and Expert Comparison
Irvin, J., Rajpurkar, P., Ko, M., Yu, Y., Ciurea-Ilcus, S., Chute, C., Marklund, H., Haghgoo, B., Ball, R., Shpanskaya, K., et al.: Chexpert: A large chest radiograph dataset with uncertainty labels and expert comparison. arXiv:1901.07031 (2019)
work page internal anchor Pith review Pith/arXiv arXiv 1901
-
[6]
Jing, B., Xie, P., Xing, E.P.: On the automatic generation of medical imaging reports. In: Proceedings of the 56th Annual Meeting of the Association for Com- putational Linguistics, ACL 2018, Melbourne, Australia. pp. 2577–2586 (2018)
work page 2018
-
[7]
Knowledge-driven Encode, Retrieve, Paraphrase for Medical Image Report Generation
Li, C.Y., Liang, X., Hu, Z., Xing, E.P.: Knowledge-driven encode, retrieve, para- phrase for medical image report generation. arxiv:1903.10122 (2019)
work page internal anchor Pith review Pith/arXiv arXiv 1903
-
[8]
In: Proceed- ings of the ACL-04 Workshop
Lin, C.Y.: Rouge: A package for automatic evaluation of summaries. In: Proceed- ings of the ACL-04 Workshop. pp. 74–81. Association for Computational Linguis- tics, Barcelona, Spain (July 2004)
work page 2004
-
[9]
In: Proceedings of the 40th annual meeting on association for computational linguistics
Papineni, K., Roukos, S., Ward, T., Zhu, W.J.: Bleu: a method for automatic evaluation of machine translation. In: Proceedings of the 40th annual meeting on association for computational linguistics. pp. 311–318 (2002)
work page 2002
-
[10]
In: Proceedings of the IEEE International Conference on Computer Vision
Selvaraju, R.R., Cogswell, M., Das, A., Vedantam, R., Parikh, D., Batra, D.: Grad- cam: Visual explanations from deep networks via gradient-based localization. In: Proceedings of the IEEE International Conference on Computer Vision. pp. 618– 626 (2017)
work page 2017
-
[11]
Show and Tell: A Neural Image Caption Generator
Vinyals, O., Toshev, A., Bengio, S., Erhan, D.: Show and tell: A neural image caption generator. arxiv:1411.4555 (2015)
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[12]
In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition
Wang, X., Peng, Y., Lu, L., Lu, Z., Bagheri, M., Summers, R.M.: Chestx-ray8: Hospital-scale chest x-ray database and benchmarks on weakly-supervised classi- fication and localization of common thorax diseases. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. pp. 2097–2106 (2017)
work page 2097
-
[13]
Show, Attend and Tell: Neural Image Caption Generation with Visual Attention
Xu, K., Ba, J., Kiros, R., Cho, K., Courville, A., Salakhudinov, R., Zemel, R., Bengio, Y.: Show, attend and tell: Neural image caption generation with visual attention. In: arxiv:1502.03044 (2015)
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[14]
Xue, Y., Xu, T., Long, L.R., Xue, Z., Antani, S.K., Thoma, G.R., Huang, X.: Mul- timodal recurrent model with attention for automated radiology report generation. In: Medical Image Computing and Computer Assisted Intervention 2018, Granada, Spain, Proceedings, Part I. pp. 457–466 (2018)
work page 2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.