Seeing Before Agreeing: Aligning Multi-Agent Consensus with Visual Evidence
Pith reviewed 2026-06-28 23:23 UTC · model grok-4.3
The pith
Answer-level agreement alone is insufficient for reliable multi-agent VQA; aligned visual evidence from shared image regions is required for trustworthy consensus.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
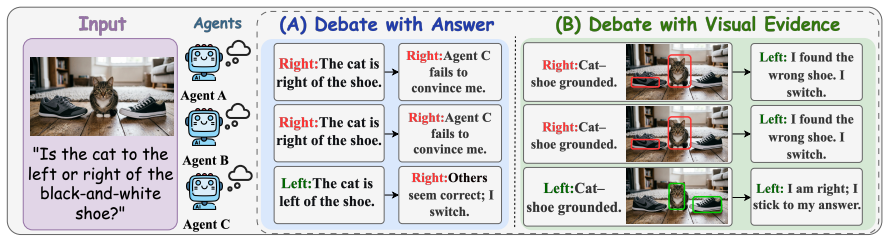
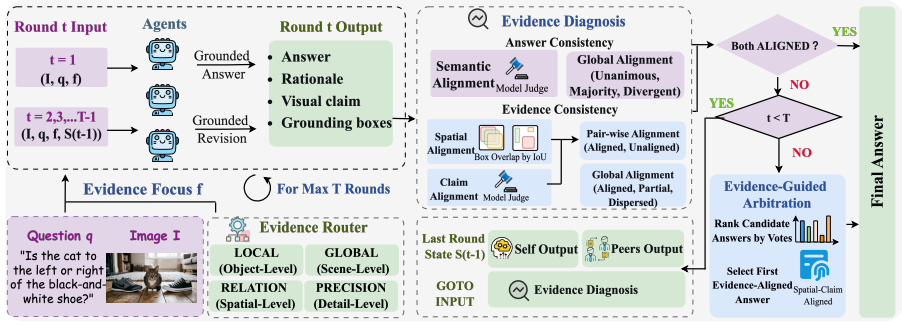
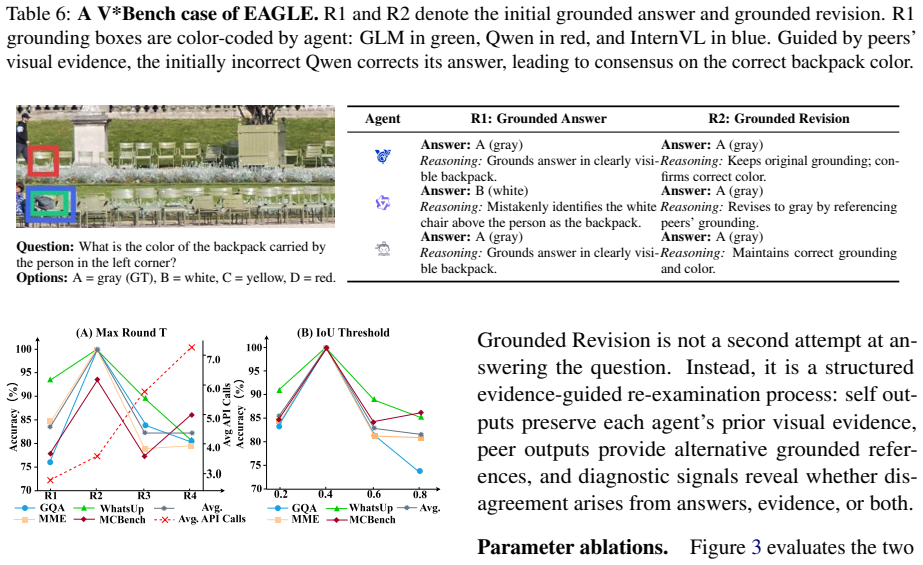
The central claim is that answer-level agreement is insufficient for reliable multi-agent VQA and that aligned visual evidence—shared support from the image regions agents rely on—is essential for trustworthy consensus. EAGLE implements this by explicitly exposing each agent's grounding regions as visual evidence, enabling mutual verification over the evidence, and using evidence consistency to guide final decision-making, achieving best average performance across domains on six VQA benchmarks while remaining training-free.
What carries the argument
EAGLE (Evidence-Aligned Grounded multi-agent Reasoning), the training-free framework that exposes grounding regions for mutual verification and consistency-guided decision-making.
If this is right
- EAGLE achieves the best average performance across domains on six VQA benchmarks.
- The method remains training-free, lightweight, interpretable, and practical for deployment.
- Focusing on visual evidence alignment rather than textual discussion alone mitigates individual hallucinations and blind spots more effectively than text-centric protocols.
- Existing multi-agent VQA approaches that adapt text-only protocols are insufficient for the multimodal setting.
Where Pith is reading between the lines
- If evidence alignment is the key mechanism, similar verification of grounding regions could be added to single-agent VLM pipelines to reduce hallucinations without multi-agent overhead.
- Gains may vary with the accuracy of region extraction, suggesting direct tests that swap different grounding modules while holding other components fixed.
- The same evidence-consistency step could be applied to other multi-model multimodal tasks such as visual chain-of-thought or joint image-captioning systems.
Load-bearing premise
That mutual verification over exposed grounding regions can be effectively implemented in VLMs and that evidence consistency reliably guides better decision-making.
What would settle it
A controlled comparison in which multi-agent systems reach high answer agreement but show no accuracy gain when required to align on visual evidence regions would falsify the claim that aligned visual evidence is essential.
Figures
read the original abstract
Vision-language models (VLMs) have achieved strong performance on visual question answering (VQA). To mitigate individual hallucinations and blind spots, aggregating diverse perspectives via multi-agent collaboration has emerged as a promising paradigm. While this approach has shown great success in textual QA, its potential in the multimodal domain remains under-explored. Existing multi-agent VQA methods predominantly adapt text-centric protocols, focusing on textual discussions while ignoring the alignment of visual information. In this work, we reveal a key insight: answer-level agreement is insufficient for reliable multi-agent VQA; \textit{aligned visual evidence} -- shared support from the image regions agents rely on -- is essential for trustworthy consensus. To leverage this insight, we propose EAGLE (\textbf{E}vidence-\textbf{A}ligned \textbf{G}rounded mu\textbf{L}ti-agent r\textbf{E}asoning), a training-free evidence-centered framework for coordinating multiple VLM agents. EAGLE explicitly exposes each agent's grounding regions as visual evidence, enables mutual verification over the evidence, and uses evidence consistency to guide final decision-making. Experiments on six VQA benchmarks show that EAGLE achieves best average performance across domains while remaining lightweight, interpretable, and practical for deployment.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that answer-level agreement is insufficient for reliable multi-agent VQA and that aligned visual evidence—shared support from the image regions agents rely on—is essential for trustworthy consensus. It proposes EAGLE, a training-free evidence-centered framework that exposes each agent's grounding regions, enables mutual verification over the evidence, and uses evidence consistency to guide final decision-making, reporting best average performance across domains on six VQA benchmarks.
Significance. If the results hold, the work would advance multi-agent VLM collaboration by shifting focus from textual agreement to visual evidence alignment. The training-free design is a clear strength, supporting lightweight and practical deployment without additional fine-tuning costs.
major comments (2)
- [Abstract] Abstract: The assertion that EAGLE 'achieves best average performance across domains' on six VQA benchmarks provides no information on baselines, statistical tests, error bars, dataset specifics, or controls for confounds, leaving the central empirical claim without verifiable support.
- [EAGLE framework description] EAGLE framework description: The core mechanisms for exposing grounding regions, performing mutual verification, and applying evidence consistency lack concrete details on extraction, comparison, and differentiation from prior grounding techniques, which is load-bearing for evaluating whether the approach reliably improves decision-making.
minor comments (1)
- [Abstract] The acronym expansion for EAGLE could be formatted more explicitly for immediate readability.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment point-by-point below, providing clarifications from the manuscript and indicating where revisions have been made to improve clarity and support for the claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: The assertion that EAGLE 'achieves best average performance across domains' on six VQA benchmarks provides no information on baselines, statistical tests, error bars, dataset specifics, or controls for confounds, leaving the central empirical claim without verifiable support.
Authors: We agree the abstract is concise by design and omits granular experimental details. The full manuscript (Section 4) specifies the six benchmarks (VQA v2, GQA, OK-VQA, A-OKVQA, TextVQA, VizWiz), lists all baselines (single-agent VLMs and prior multi-agent methods), reports per-dataset and average results with error bars, and includes controls for confounds such as agent count and prompting variations. Statistical comparisons are provided via paired t-tests in the supplementary material. To better support the claim in the abstract, we have revised it to name the benchmark domains and note the consistent outperformance, while directing readers to the experiments for full details. revision: yes
-
Referee: [EAGLE framework description] EAGLE framework description: The core mechanisms for exposing grounding regions, performing mutual verification, and applying evidence consistency lack concrete details on extraction, comparison, and differentiation from prior grounding techniques, which is load-bearing for evaluating whether the approach reliably improves decision-making.
Authors: Section 3 of the manuscript details these components: grounding regions are extracted via each agent's output of bounding boxes aligned to reasoning tokens (using the VLM's native localization capability); mutual verification computes region overlap via IoU thresholds and semantic consistency via CLIP embeddings; evidence consistency then weights the final answer by the fraction of agents sharing supporting regions above a threshold. Differentiation from prior single-agent grounding work (e.g., attention visualization or box prediction methods) is that EAGLE uses the shared evidence for cross-agent consensus rather than individual accuracy. We have expanded this section in revision with pseudocode, explicit extraction steps, and a new comparison table against prior techniques to make the mechanisms fully reproducible. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper presents a conceptual insight (answer-level agreement insufficient; aligned visual evidence essential) and proposes the training-free EAGLE framework that exposes grounding regions for mutual verification. No equations, parameter fittings, self-definitional reductions, or load-bearing self-citations appear in the abstract or described method. The central claim is an observation used to motivate the framework rather than a derived result that collapses to its own inputs by construction. Experiments on external VQA benchmarks provide independent evaluation, rendering the approach self-contained.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Vision-language models can expose grounding regions as visual evidence that can be compared across agents
Reference graph
Works this paper leans on
-
[1]
LLaVA-OneVision-1.5: Fully Open Framework for Democratized Multimodal Training
Llava-onevision-1.5: Fully open framework for democratized multimodal training.arXiv preprint arXiv:2509.23661. Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, and 1 others
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Qwen3-vl technical report.arXiv preprint arXiv:2511.21631. Maciej Besta, Nils Blach, Ales Kubicek, Robert Gersten- berger, Michal Podstawski, Lukas Gianinazzi, Joanna Gajda, Tomasz Lehmann, Hubert Niewiadomski, Pi- otr Nyczyk, and 1 others. 2024. Graph of thoughts: Solving elaborate problems with large language mod- els. InProceedings of the AAAI conferen...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[3]
Grounding answers for visual questions asked by visually impaired people. InProceedings of the IEEE/CVF Conference on Computer Vision and Pat- tern Recognition, pages 19098–19107. Justin Chen, Swarnadeep Saha, and Mohit Bansal. 2024b. Reconcile: Round-table conference improves reasoning via consensus among diverse llms. InPro- ceedings of the 62nd Annual ...
-
[4]
Global Context or Local Detail? Adaptive Visual Grounding for Hallucination Mitigation
Global context or local detail? adaptive vi- sual grounding for hallucination mitigation.arXiv preprint arXiv:2604.24396. Lars Benedikt Kaesberg, Jonas Becker, Jan Philip Wahle, Terry Ruas, and Bela Gipp. 2025. V oting or consensus? decision-making in multi-agent debate. InFindings of the Association for Computational Linguistics: ACL 2025, pages 11640–11...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
InProceedings of the Computer Vision and Pattern Recognition Conference, pages 191–201
Multimodal rationales for explainable visual question answering. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 191–201. Qing Li, Qingyi Tao, Shafiq Joty, Jianfei Cai, and Jiebo Luo. 2018. Vqa-e: Explaining, elaborating, and en- hancing your answers for visual questions. InPro- ceedings of the European Conference on Compute...
-
[6]
Rethinking Information Synthesis in Multimodal Question Answering A Multi-Agent Perspective
Improving automatic vqa evaluation using large language models. InProceedings of the AAAI Conference on Artificial Intelligence, volume 38, pages 4171–4179. Dung Nguyen, Minh Khoi Ho, Huy Ta, Thanh Tam Nguyen, Qi Chen, Kumar Rav, Quy Duong Dang, Satwik Ramchandre, Son Lam Phung, Zhibin Liao, and 1 others. 2025. Localizing before answering: A benchmark for...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[7]
Kimi-vl technical report.arXiv preprint arXiv:2504.07491. Shengbang Tong, Zhuang Liu, Yuexiang Zhai, Yi Ma, Yann LeCun, and Saining Xie. 2024. Eyes wide shut? exploring the visual shortcomings of multi- modal llms. InProceedings of the IEEE/CVF con- ference on computer vision and pattern recognition, pages 9568–9578. Khanh-Tung Tran, Dung Dao, Minh-Duong ...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[8]
What color is the car?
Tree of thoughts: Deliberate problem solving with large language models.Advances in neural information processing systems, 36:11809–11822. Shixin Yi and Lin Shang. 2025. Corgi: Verified chain- of-thought reasoning with visual grounding.arXiv e-prints, pages arXiv–2508. Kepu Zhang, Weijie Yu, Sunhao Dai, and Jun Xu. 2025. Citalaw: Enhancing llm with citati...
2025
-
[9]
Inspect the image independently
-
[10]
Follow the evidence-grounding instruction
-
[11]
Answer the question with concise evidence-grounded reasoning
-
[12]
Provide one atomic visual claim that directly supports your answer
-
[13]
reasoning
Provide the grounding boxes for the image region(s) that support this visual claim. Output JSON schema: { "reasoning": "brief evidence-grounded reasoning", "visual_claim": "one atomic visual finding explaining how the grounded regions support the answer", "grounding_boxes": [ {"label": "object or region name", "box": [x1, y1, x2, y2]} ], "answer": "short ...
-
[14]
Keep the reasoning concise and tied to visible evidence in the image
-
[15]
The visual_claim must be a single atomic visual finding that directly supports the answer
-
[16]
The grounding_boxes must localize the region(s) that support the visual_claim
-
[17]
Use tight boxes around the relevant visual evidence whenever possible
-
[18]
Do not ground irrelevant objects, background regions, or the whole image unless the evidence focus requires global scene evidence
-
[19]
If no specific local region is decisive, return grounding_boxes: []
-
[20]
claim_aligned
Return raw JSON only. Grounding boxes and coordinate normalization. The grounding_boxes field localizes the image region(s) that support the visual claim. Since dif- ferent VLMs may emit boxes under different co- ordinate conventions, we normalize all predicted boxes into the original image pixel coordinate sys- tem before evidence diagnosis. This shared ...
-
[21]
Re-read the original image independently
-
[22]
Use self and peer hypotheses as visual references, not as authority
-
[23]
Keep your previous answer if the image still supports it
-
[24]
Revise only if a newly verified visual observation better supports another answer
-
[25]
answer":
Keep the reasoning concise and grounded in visible evidence. Output JSON: { "answer": "short final answer", "reasoning": "brief image-grounded reasoning", "grounding_boxes": [ {"label": "object name", "box": [x1, y1, x2, y2]} ], "visual_claim": "one atomic visual finding that directly supports the answer" } B.6 Evidence-Guided Arbitration When no evidence...
2024
-
[26]
Use explicit multi-step reasoning grounded in the image and question
-
[27]
Keep the reasoning focused and concrete rather than verbose
-
[28]
Self-Consistency(Wang et al., 2022)
Return raw JSON only. Self-Consistency(Wang et al., 2022). Self- Consistency samples multiple reasoning paths from a single model and aggregates their final answers by voting. For each question, we query the same backbone multiple times with the Zero-shot CoT prompt above. Each response contains its own rea- soning path and final answer. We then discard t...
2022
-
[29]
Extract the final answer from each sampled response
-
[30]
critique
Select the final answer by majority voting. Self-Refine(Madaan et al., 2023). Self-Refine iteratively improves a model’s own answer using self-generated feedback. For each sample, the model first generates an initial answer with the Zero-shot CoT prompt. It then critiques its own reasoning and answer, and finally produces a re- fined response conditioned ...
2023
-
[31]
Focus the critique on the most important possible error in the reasoning or answer
-
[32]
If the current answer is still supported by the image, keep it unchanged
-
[33]
Revise the answer only when the image provides evidence for the change
-
[34]
Do not introduce information that is not visible in the image
-
[35]
reasoning
Return raw JSON only. Multi-Agent Debate(Du et al., 2024; Liang et al., 2024). Multi-Agent Debate lets multiple agents exchange their answers and textual ratio- nales over multiple rounds. In the first round, each agent independently answers the question using the Zero-shot CoT prompt. In later rounds, each agent observes the other agents’ previous answer...
2024
-
[36]
Consider peers, but do not follow them blindly
-
[37]
Explain step by step how the peer evidence changes or confirms your view
-
[38]
Keep the reasoning concrete and tied to the image question
-
[39]
Debate Judge Prompt You are given an image question and the full state of a multi-round debate among several vision-language agents
Return raw JSON only. Debate Judge Prompt You are given an image question and the full state of a multi-round debate among several vision-language agents. Question: {question} Debate states: {debate_text} Task:
-
[40]
Read the image yourself
-
[41]
Use the debate states only as auxiliary evidence
-
[42]
Identify all candidate answers that appeared in the debate states
-
[43]
reasoning
Select the single best final answer from these candidate answers only. Output schema: { "reasoning": "brief image-grounded adjudication that explains why the selected candidate is best", "answer": "one candidate answer copied from the debate states" } Rules:
-
[44]
The image is the source of truth; do not blindly follow the debaters
-
[45]
You must choose one answer that already appears in the debate states
-
[46]
If multiple candidates are plausible, choose the one best supported by the image
-
[47]
reasoning
Return raw JSON only. ReConcile(Chen et al., 2024b). ReConcile is a confidence-driven multi-agent discussion frame- work. Each agent first provides an answer with a confidence score. Then, agents review grouped peer answers, justifications, and confidences before updating their predictions. After the final discus- sion round, we group semantically equival...
-
[48]
Base your answer on the image and question
-
[50]
Keep the reasoning focused and concrete
-
[51]
reasoning
Return raw JSON only. [Reconcile] 21 You are in a round-table conference with other agents. Review grouped peer answers, justifications, and confidences, then update your answer and confidence. Question: {question} Previous response: {previous_text} Grouped peer views: {peer_json} Output JSON: { "reasoning": "brief evidence-grounded reasoning after review...
-
[52]
Review each answer group and compare the supporting justifications
-
[53]
Keep your answer if it remains best supported by the image
-
[54]
Change your answer only if another group provides more convincing visual evidence
-
[55]
Confidence must reflect your final belief after reviewing all groups
-
[56]
selected_tools
Return raw JSON only. [Final confidence-aware aggregation] After the last discussion round, group semantically equivalent final answers. For each answer group y, compute its aggregation score as the sum of confidences from agents supporting y: score(y) = sum(confidence_i for agents whose final answer is y) Select the answer group with the highest score as...
2026
-
[57]
Select only tools that are useful for resolving the disagreement
-
[58]
grounding
Select "grounding" when agents disagree about where the relevant evidence is located
-
[59]
object_detection
Select "object_detection" when agents disagree about the presence or identity of objects
-
[60]
Select "ocr" when the question depends on visible text, letters, numbers, labels, or symbols
-
[61]
spatial_reasoning
Select "spatial_reasoning" when agents disagree about relative positions, directions, distances, or spatial configurations
-
[62]
captioning
Select "captioning" when global scene context may resolve the disagreement
-
[63]
attribute_detection
Select "attribute_detection" when agents disagree about visual attributes such as color, shape, material, state, or markings
-
[64]
reasoning
Select "reasoning" when the disagreement requires additional visual reasoning beyond direct perception
-
[65]
tool_name
Return raw JSON only. [Expert tool execution] Each selected tool is executed with its corresponding query. Tool implementations: - grounding: GroundingDINO. - object_detection: YOLOv11. - spatial_reasoning: SpaceLLaVA. - ocr: OCR-Qwen. - captioning / attribute_detection / reasoning: InternVL-2.5 MPO. Tool output format: { "tool_name": "tool_name", "query"...
-
[66]
Score each agent between 0 and 1
-
[67]
A high score means the agent's answer and reasoning are supported by the tool outputs
-
[68]
A low score means the agent's answer conflicts with or is unsupported by the tool outputs
-
[69]
Use the tool outputs as auxiliary evidence, not as the only criterion
-
[70]
reasoning
Return raw JSON only. [Tool-assisted discussion] You are in a tool-assisted multi-agent discussion. Review the grouped agent solutions, tool outputs, and tool-agreement scores, then update your answer. Question: {question} Previous response: {previous_text} Grouped agent solutions: {grouped_json} Tool outputs: {tool_json} Agreement scores: {score_json} Ou...
-
[71]
Prefer answers supported by reliable tool outputs, while keeping the original image question central
-
[72]
Use agreement scores as auxiliary evidence, not as the only criterion
-
[73]
Keep your answer if it remains best supported by the image and tool evidence
-
[74]
Change your answer only when another candidate is better supported by visual evidence
-
[75]
Confidence must be a number between 0 and 1
-
[76]
reasoning
Return raw JSON only. [Final aggregator] Choose the best final answer after reviewing post-discussion agent solutions, tool outputs, and tool-agreement scores. Question: {question} Post-discussion solutions: {discussion_json} Tool outputs: {tools_json} Agreement scores: {scores_json} Candidate answers: {candidate_answers} Output JSON: { "reasoning": "brie...
-
[77]
Select exactly one answer from Candidate answers
-
[78]
Do not invent a new answer or output an answer not proposed by any agent
-
[79]
Prefer answers supported by reliable tool outputs
-
[80]
Use vote counts, confidence scores, and tool-agreement scores together
-
[81]
Do not rely on tool scores alone if image-grounded reasoning contradicts them
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.