Active Statistical Inference
Pith reviewed 2026-05-24 03:18 UTC · model grok-4.3
The pith
Active inference uses a machine learning model to select which points to label, producing valid confidence intervals and tests with substantially fewer samples than non-adaptive collection.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Active inference constructs provably valid confidence intervals and hypothesis tests while leveraging any black-box machine learning model and handling any data distribution. The key point is that it achieves the same level of accuracy with far fewer samples than existing baselines relying on non-adaptively-collected data.
What carries the argument
The adaptive labeling rule that prioritizes data points where the machine-learning model exhibits high uncertainty, while the resulting estimator remains unbiased and the coverage guarantees hold exactly.
If this is right
- Valid confidence intervals and p-values are obtained under adaptive data collection.
- Equivalent accuracy is reached with substantially fewer labeled samples than non-adaptive baselines.
- The same number of collected samples yields smaller intervals and more powerful tests.
- The procedure applies to any black-box machine-learning model and any data distribution.
Where Pith is reading between the lines
- The method could be combined with sequential stopping rules to further reduce average sample size.
- In settings where labeling cost varies, the uncertainty score could be weighted by cost to optimize total expenditure.
- The same adaptive principle may extend to other inference targets such as quantile estimation or causal effect estimation.
Load-bearing premise
An adaptive labeling rule based on the machine learning model's uncertainty estimates can be constructed so that the resulting estimator remains unbiased and the coverage guarantees hold exactly even though the selection depends on the same data being inferred upon.
What would settle it
A simulation in which active inference is applied to a known data-generating process and the empirical coverage of its nominal 95 percent intervals falls below 95 percent.
Figures




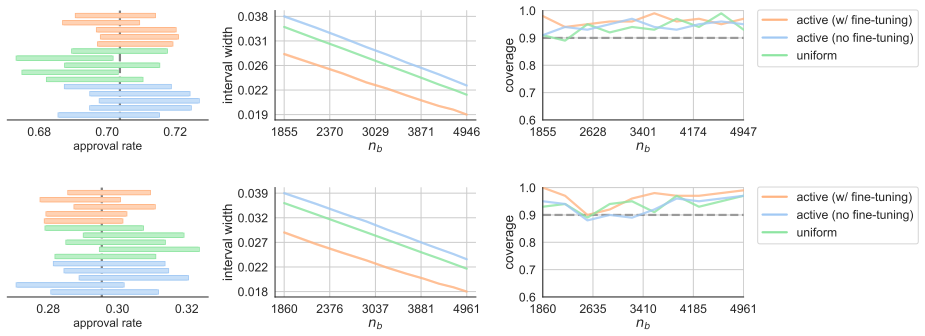

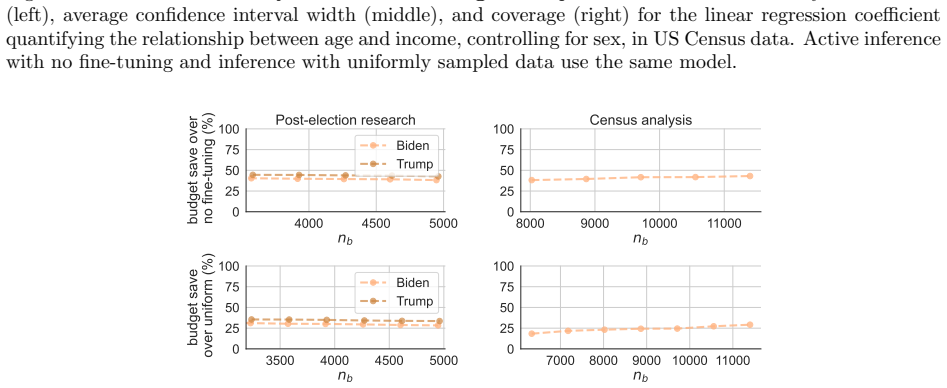

read the original abstract
Inspired by the concept of active learning, we propose active inference$\unicode{x2013}$a methodology for statistical inference with machine-learning-assisted data collection. Assuming a budget on the number of labels that can be collected, the methodology uses a machine learning model to identify which data points would be most beneficial to label, thus effectively utilizing the budget. It operates on a simple yet powerful intuition: prioritize the collection of labels for data points where the model exhibits uncertainty, and rely on the model's predictions where it is confident. Active inference constructs provably valid confidence intervals and hypothesis tests while leveraging any black-box machine learning model and handling any data distribution. The key point is that it achieves the same level of accuracy with far fewer samples than existing baselines relying on non-adaptively-collected data. This means that for the same number of collected samples, active inference enables smaller confidence intervals and more powerful p-values. We evaluate active inference on datasets from public opinion research, census analysis, and proteomics.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes active inference, a framework that uses any black-box ML model to adaptively select a budgeted number of data points for labeling by prioritizing those where the model is uncertain, then constructs confidence intervals and hypothesis tests from the resulting data. It claims these procedures are provably valid (exact coverage and type-I error control) for arbitrary models and distributions, achieve the accuracy of non-adaptive methods with substantially fewer labels, and demonstrates the approach on public-opinion, census, and proteomics datasets.
Significance. If the validity guarantees survive the adaptivity, the result would be a notable contribution to efficient statistical inference: it would allow rigorous uncertainty quantification while exploiting modern ML for data collection, potentially reducing labeling costs in applied domains without sacrificing exact finite-sample guarantees. The model-agnostic and distribution-free framing, together with real-data experiments, would make the method broadly usable if the technical construction is sound.
major comments (2)
- [Theoretical Results] Theoretical Results section: the claim that adaptive labeling (based on the black-box model's uncertainty) yields an estimator with exact 1-α coverage for arbitrary models requires an explicit argument restoring validity (e.g., via martingales, conditional coverage, or importance weighting). Standard Hoeffding or CLT bounds assume fixed samples; without a concrete correction for the dependence between the selection rule and the observed labels, the “any black-box model, any distribution” guarantee does not follow from existing concentration results.
- [§3 / Algorithm 1] Algorithm 1 / §3: the precise selection rule, the form of the final estimator, and any debiasing step must be stated so that unbiasedness and coverage can be verified. The abstract describes only the high-level intuition (“prioritize uncertain points”); without the explicit mapping from model outputs to labeling decisions and the resulting estimator, the central validity claim cannot be checked.
minor comments (2)
- [Evaluation] Evaluation section: reported efficiency gains on the three datasets should include variability measures (standard errors or bootstrap intervals) across random seeds or data splits so that the claimed sample-size reductions can be assessed for statistical reliability.
- [Notation] Notation: the distinction between the ML model used for selection and any model used inside the final estimator should be made explicit throughout; current wording occasionally blurs whether the same black-box is reused for inference.
Simulated Author's Rebuttal
We thank the referee for the careful and constructive review. The comments correctly identify that the current manuscript does not supply a self-contained argument for validity under adaptivity nor a fully explicit algorithmic description. We address both points below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Theoretical Results] Theoretical Results section: the claim that adaptive labeling (based on the black-box model's uncertainty) yields an estimator with exact 1-α coverage for arbitrary models requires an explicit argument restoring validity (e.g., via martingales, conditional coverage, or importance weighting). Standard Hoeffding or CLT bounds assume fixed samples; without a concrete correction for the dependence between the selection rule and the observed labels, the “any black-box model, any distribution” guarantee does not follow from existing concentration results.
Authors: We agree that the theoretical results section does not contain an explicit argument that restores exact coverage once the labeling rule depends on the black-box model. Standard concentration inequalities cannot be invoked directly. In the revision we will insert a self-contained proof that accounts for the dependence, for example by exhibiting the procedure as an importance-weighted estimator whose weights are known functions of the model outputs, or by applying a suitable martingale concentration inequality to the adaptively collected labels. This will make the model-agnostic, distribution-free coverage claim rigorous. revision: yes
-
Referee: [§3 / Algorithm 1] Algorithm 1 / §3: the precise selection rule, the form of the final estimator, and any debiasing step must be stated so that unbiasedness and coverage can be verified. The abstract describes only the high-level intuition (“prioritize uncertain points”); without the explicit mapping from model outputs to labeling decisions and the resulting estimator, the central validity claim cannot be checked.
Authors: We acknowledge that Section 3 and Algorithm 1 currently give only a high-level description. The precise mapping from model uncertainty scores to labeling decisions (deterministic threshold, probabilistic selection, etc.), the explicit form of the estimator used for inference, and any weighting or debiasing step are not stated at a level that permits direct verification of unbiasedness or coverage. We will revise §3 and Algorithm 1 to supply these missing specifications so that the validity argument can be checked line by line. revision: yes
Circularity Check
No significant circularity detected; derivation remains self-contained.
full rationale
The provided abstract and context describe a general methodology for active inference that claims provably valid confidence intervals and tests for arbitrary black-box models and distributions via adaptive labeling. No equations, self-citations, or fitted parameters are quoted that reduce a claimed prediction or validity result to an input by construction. The framework is presented as model-agnostic without evidence of self-definitional steps, fitted inputs renamed as predictions, or load-bearing self-citations. This is the normal case of a self-contained statistical construction whose validity arguments (if present in the full text) stand independently of the target claims.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Machine learning models can supply uncertainty estimates that are useful for deciding which points to label.
Forward citations
Cited by 3 Pith papers
-
Multi-Armed Bandits With Machine Learning-Generated Surrogate Rewards
The MLA-UCB algorithm uses ML-generated surrogate rewards from auxiliary data to provably lower cumulative regret in multi-armed bandits, achieving asymptotic optimality under joint Gaussian assumptions without requir...
-
Batch-Adaptive Causal Annotations
Derives closed-form optimal batch sampling probabilities to minimize asymptotic variance of doubly robust ATE estimator with missing outcomes, achieving lower MSE and matching full-sample precision with 75% fewer labe...
-
High-Dimensional Statistics: Reflections on Progress and Open Problems
A survey synthesizing representative advances, common themes, and open problems in high-dimensional statistics while pointing to key entry-point works.
Reference graph
Works this paper leans on
-
[1]
Anastasios N Angelopoulos, Stephen Bates, Clara Fannjiang, Michael I Jordan, and Tijana Zrnic. Prediction-powered inference. Science, 382(6671):669–674, 2023
work page 2023
-
[2]
Prediction-powered inference: Data sets, 2023
Anastasios N Angelopoulos, Stephen Bates, Clara Fannjiang, Michael I Jordan, and Tijana Zrnic. Prediction-powered inference: Data sets, 2023. URL https://doi.org/10.5281/zenodo.8397451
-
[3]
PPI++: Efficient Prediction-Powered Inference
Anastasios N Angelopoulos, John C Duchi, and Tijana Zrnic. PPI++: Efficient prediction-powered inference. arXiv preprint arXiv:2311.01453 , 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[4]
Deep batch active learning by diverse, uncertain gradient lower bounds
Jordan T Ash, Chicheng Zhang, Akshay Krishnamurthy, John Langford, and Alekh Agarwal. Deep batch active learning by diverse, uncertain gradient lower bounds. arXiv preprint arXiv:1906.03671 , 2019
-
[5]
Semi- supervised linear regression
David Azriel, Lawrence D Brown, Michael Sklar, Richard Berk, Andreas Buja, and Linda Zhao. Semi- supervised linear regression. Journal of the American Statistical Association, 117(540):2238–2251, 2022
work page 2022
-
[6]
Maria-Florina Balcan, Alina Beygelzimer, and John Langford. Agnostic active learning. In Proceedings of the 23rd international conference on Machine learning , pages 65–72, 2006
work page 2006
-
[7]
Learning economic parameters from revealed preferences
Maria-Florina Balcan, Amit Daniely, Ruta Mehta, Ruth Urner, and Vijay V Vazirani. Learning economic parameters from revealed preferences. In Web and Internet Economics: 10th International Conference, WINE 2014, Beijing, China, December 14-17, 2014. Proceedings 10 , pages 338–353. Springer, 2014
work page 2014
-
[8]
Inferring welfare maximizing treatment assignment under budget constraints
Debopam Bhattacharya and Pascaline Dupas. Inferring welfare maximizing treatment assignment under budget constraints. Journal of Econometrics , 167(1):168–196, 2012
work page 2012
-
[9]
The structural context of posttrans- lational modifications at a proteome-wide scale
Isabell Bludau, Sander Willems, Wen-Feng Zeng, Maximilian T Strauss, Fynn M Hansen, Maria C Tanzer, Ozge Karayel, Brenda A Schulman, and Matthias Mann. The structural context of posttrans- lational modifications at a proteome-wide scale. PLoS biology, 20(5):e3001636, 2022
work page 2022
-
[10]
Adaptive instrument design for indirect experiments
Yash Chandak, Shiv Shankar, Vasilis Syrgkanis, and Emma Brunskill. Adaptive instrument design for indirect experiments. arXiv preprint arXiv:2312.02438 , 2023
-
[11]
Xgboost: A scalable tree boosting system
Tianqi Chen and Carlos Guestrin. Xgboost: A scalable tree boosting system. In Proceedings of the 22nd acm sigkdd international conference on knowledge discovery and data mining , pages 785–794, 2016
work page 2016
-
[12]
How many labelers do you have? a closer look at gold-standard labels
Chen Cheng, Hilal Asi, and John Duchi. How many labelers do you have? a closer look at gold-standard labels. arXiv preprint arXiv:2206.12041 , 2022
-
[13]
Double/debiased machine learning for treatment and structural parameters, 2018
Victor Chernozhukov, Denis Chetverikov, Mert Demirer, Esther Duflo, Christian Hansen, Whitney Newey, and James Robins. Double/debiased machine learning for treatment and structural parameters, 2018
work page 2018
-
[14]
Semiparametric efficient inference in adaptive experiments
Thomas Cook, Alan Mishler, and Aaditya Ramdas. Semiparametric efficient inference in adaptive experiments. arXiv preprint arXiv:2311.18274 , 2023
-
[15]
Retiring adult: New datasets for fair machine learning
Frances Ding, Moritz Hardt, John Miller, and Ludwig Schmidt. Retiring adult: New datasets for fair machine learning. Advances in neural information processing systems , 34:6478–6490, 2021
work page 2021
-
[16]
Probability: theory and examples , volume 49
Rick Durrett. Probability: theory and examples , volume 49. Cambridge university press, 2019
work page 2019
-
[17]
Asymptotic normality for sums of dependent random variables
Aryeh Dvoretzky. Asymptotic normality for sums of dependent random variables. In Proceedings of the Sixth Berkeley Symposium on Mathematical Statistics and Probability, Volume 2: Probability Theory , volume 6, pages 513–536. University of California Press, 1972
work page 1972
-
[18]
Deep Bayesian active learning with image data
Yarin Gal, Riashat Islam, and Zoubin Ghahramani. Deep Bayesian active learning with image data. In International conference on machine learning , pages 1183–1192. PMLR, 2017. 17
work page 2017
-
[19]
Prediction de-correlated inference
Feng Gan and Wanfeng Liang. Prediction de-correlated inference. arXiv preprint arXiv:2312.06478 , 2023
-
[20]
Confidence intervals for policy evaluation in adaptive experiments
Vitor Hadad, David A Hirshberg, Ruohan Zhan, Stefan Wager, and Susan Athey. Confidence intervals for policy evaluation in adaptive experiments. Proceedings of the national academy of sciences, 118(15): e2014602118, 2021
work page 2021
-
[21]
Adaptive experimental design using the propensity score
Jinyong Hahn, Keisuke Hirano, and Dean Karlan. Adaptive experimental design using the propensity score. Journal of Business & Economic Statistics , 29(1):96–108, 2011
work page 2011
-
[22]
Theory of disagreement-based active learning
Steve Hanneke et al. Theory of disagreement-based active learning. Foundations and Trends ® in Machine Learning, 7(2-3):131–309, 2014
work page 2014
-
[23]
The theory of response-adaptive randomization in clinical trials
Feifang Hu and William F Rosenberger. The theory of response-adaptive randomization in clinical trials. John Wiley & Sons, 2006
work page 2006
-
[24]
Combining satellite imagery and machine learning to predict poverty
Neal Jean, Marshall Burke, Michael Xie, W Matthew Davis, David B Lobell, and Stefano Ermon. Combining satellite imagery and machine learning to predict poverty. Science, 353(6301):790–794, 2016
work page 2016
-
[25]
Multi-class active learning for image clas- sification
Ajay J Joshi, Fatih Porikli, and Nikolaos Papanikolopoulos. Multi-class active learning for image clas- sification. In 2009 ieee conference on computer vision and pattern recognition , pages 2372–2379. IEEE, 2009
work page 2009
-
[26]
Highly accurate protein structure prediction with alphafold
John Jumper, Richard Evans, Alexander Pritzel, Tim Green, Michael Figurnov, Olaf Ronneberger, Kathryn Tunyasuvunakool, Russ Bates, AugustinˇZ´ ıdek, Anna Potapenko, et al. Highly accurate protein structure prediction with alphafold. Nature, 596(7873):583–589, 2021
work page 2021
-
[27]
Introduction to survey sampling
Graham Kalton. Introduction to survey sampling . Number 35. Sage Publications, 2020
work page 2020
-
[28]
Adaptive treatment assignment in experiments for policy choice
Maximilian Kasy and Anja Sautmann. Adaptive treatment assignment in experiments for policy choice. Econometrica, 89(1):113–132, 2021
work page 2021
-
[29]
Efficient adaptive experimental design for average treatment effect estimation
Masahiro Kato, Takuya Ishihara, Junya Honda, and Yusuke Narita. Efficient adaptive experimental design for average treatment effect estimation. arXiv preprint arXiv:2002.05308 , 2020
-
[30]
Designing stratified sampling in economic and business surveys
Mohammad GM Khan, Karuna G Reddy, and Dinesh K Rao. Designing stratified sampling in economic and business surveys. Journal of applied statistics , 42(10):2080–2099, 2015
work page 2080
-
[31]
Asymptotically efficient adaptive allocation rules
Tze Leung Lai and Herbert Robbins. Asymptotically efficient adaptive allocation rules. Advances in applied mathematics, 6(1):4–22, 1985
work page 1985
-
[32]
John A List, Sally Sadoff, and Mathis Wagner. So you want to run an experiment, now what? some simple rules of thumb for optimal experimental design. Experimental Economics, 14:439–457, 2011
work page 2011
-
[33]
Assumption-lean and data- adaptive post-prediction inference
Jiacheng Miao, Xinran Miao, Yixuan Wu, Jiwei Zhao, and Qiongshi Lu. Assumption-lean and data- adaptive post-prediction inference. arXiv preprint arXiv:2311.14220 , 2023
-
[34]
Valid inference after prediction
Keshav Motwani and Daniela Witten. Valid inference after prediction. arXiv preprint arXiv:2306.13746, 2023
-
[35]
Survey sampling: Theory and methods, 2001
Dankit K Nassiuma. Survey sampling: Theory and methods, 2001
work page 2001
-
[36]
Tight concentrations and confidence sequences from the regret of universal portfolio
Francesco Orabona and Kwang-Sung Jun. Tight concentrations and confidence sequences from the regret of universal portfolio. IEEE Transactions on Information Theory , 2023
work page 2023
-
[37]
Art B. Owen. Monte Carlo theory, methods and examples . https://artowen.su.domains/mc/, 2013
work page 2013
-
[38]
American trends panel (ATP) wave 79, 2020
Pew. American trends panel (ATP) wave 79, 2020. URL https://www.pewresearch.org/science/ dataset/american-trends-panel-wave-79/ . 18
work page 2020
-
[39]
A survey of deep active learning
Pengzhen Ren, Yun Xiao, Xiaojun Chang, Po-Yao Huang, Zhihui Li, Brij B Gupta, Xiaojiang Chen, and Xin Wang. A survey of deep active learning. ACM computing surveys (CSUR) , 54(9):1–40, 2021
work page 2021
-
[40]
Some aspects of the sequential design of experiments
Herbert Robbins. Some aspects of the sequential design of experiments. 1952
work page 1952
-
[41]
Semiparametric efficiency in multivariate regression models with missing data
James M Robins and Andrea Rotnitzky. Semiparametric efficiency in multivariate regression models with missing data. Journal of the American Statistical Association , 90(429):122–129, 1995
work page 1995
-
[42]
Estimation of regression coefficients when some regressors are not always observed
James M Robins, Andrea Rotnitzky, and Lue Ping Zhao. Estimation of regression coefficients when some regressors are not always observed. Journal of the American statistical Association , 89(427):846–866, 1994
work page 1994
-
[43]
A generalizable and accessible approach to machine learning with global satellite imagery
Esther Rolf, Jonathan Proctor, Tamma Carleton, Ian Bolliger, Vaishaal Shankar, Miyabi Ishihara, Benjamin Recht, and Solomon Hsiang. A generalizable and accessible approach to machine learning with global satellite imagery. Nature communications, 12(1):4392, 2021
work page 2021
-
[44]
Multiple imputation for nonresponse in surveys
D Rubin. Multiple imputation for nonresponse in surveys. Wiley Series in Probability and Statistics , page 1, 1987
work page 1987
-
[45]
Donald B Rubin. Inference and missing data. Biometrika, 63(3):581–592, 1976
work page 1976
-
[46]
Multiple imputation after 18+ years
Donald B Rubin. Multiple imputation after 18+ years. Journal of the American statistical Association , 91(434):473–489, 1996
work page 1996
-
[47]
Onπ-inverse weighting versus best linear unbiased weighting in probability sampling
Carl Erik S¨ arndal. Onπ-inverse weighting versus best linear unbiased weighting in probability sampling. Biometrika, 67(3):639–650, 1980
work page 1980
-
[48]
Springer Science & Business Media, 2003
Carl-Erik S¨ arndal, Bengt Swensson, and Jan Wretman.Model assisted survey sampling. Springer Science & Business Media, 2003
work page 2003
-
[49]
Less is more: Active learning with support vector machines
Greg Schohn and David Cohn. Less is more: Active learning with support vector machines. In ICML, volume 2, page 6, 2000
work page 2000
-
[50]
Active learning literature survey
Burr Settles. Active learning literature survey. Department of Computer Sciences, University of Wisconsin-Madison, 2009
work page 2009
-
[51]
Support vector machine active learning with applications to text classification
Simon Tong and Daphne Koller. Support vector machine active learning with applications to text classification. Journal of machine learning research , 2(Nov):45–66, 2001
work page 2001
-
[52]
Asymptotic statistics, volume 3
Aad W Van der Vaart. Asymptotic statistics, volume 3. Cambridge university press, 2000
work page 2000
-
[53]
Promises and pitfalls of threshold-based auto-labeling
Harit Vishwakarma, Heguang Lin, Frederic Sala, and Ramya Korlakai Vinayak. Promises and pitfalls of threshold-based auto-labeling. Advances in Neural Information Processing Systems , 36, 2023
work page 2023
-
[54]
Estimating means of bounded random variables by betting
Ian Waudby-Smith and Aaditya Ramdas. Estimating means of bounded random variables by betting. Journal of the Royal Statistical Society Series B: Statistical Methodology , 86(1):1–27, 2024
work page 2024
-
[55]
Transfer learning from deep features for remote sensing and poverty mapping
Michael Xie, Neal Jean, Marshall Burke, David Lobell, and Stefano Ermon. Transfer learning from deep features for remote sensing and poverty mapping. In Proceedings of the AAAI conference on artificial intelligence, volume 30, 2016
work page 2016
-
[56]
Machine politics: How America casts and counts its votes
Matt Zdun. Machine politics: How America casts and counts its votes. Reuters, 2022
work page 2022
-
[57]
Semi-supervised inference: General theory and estimation of means
Anru Zhang, Lawrence D Brown, and T Tony Cai. Semi-supervised inference: General theory and estimation of means. Annals of Statistics , 47(5):2538–2566, 2019
work page 2019
-
[58]
Active learning for optimal intervention design in causal models
Jiaqi Zhang, Louis Cammarata, Chandler Squires, Themistoklis P Sapsis, and Caroline Uhler. Active learning for optimal intervention design in causal models. Nature Machine Intelligence , pages 1–10, 2023
work page 2023
-
[59]
Statistical inference with M-estimators on adaptively collected data
Kelly Zhang, Lucas Janson, and Susan Murphy. Statistical inference with M-estimators on adaptively collected data. Advances in neural information processing systems , 34:7460–7471, 2021. 19
work page 2021
-
[60]
High-dimensional semi-supervised learning: in search of optimal inference of the mean
Yuqian Zhang and Jelena Bradic. High-dimensional semi-supervised learning: in search of optimal inference of the mean. Biometrika, 109(2):387–403, 2022
work page 2022
-
[61]
Tijana Zrnic and Emmanuel J Cand` es. Cross-prediction-powered inference.Proceedings of the National Academy of Sciences, 121(15):e2322083121, 2024. 20 A Proofs A.1 Proof of Proposition 1 Recall that ξi ∼ Bern(πˆη(Xi)). For any η ∈ H, we define ξη i = 1{πη(Xi) ≤ πˆη(Xi)}ξi(1 − ξ≤ i ) + 1{πη(Xi) > π ˆη(Xi)}(ξi + (1 − ξi)ξ> i ), (13) where ξ≤ i ∼ Bern( π ˆη...
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.