Ensemble RL through Classifier Models: Enhancing Risk-Return Trade-offs in Trading Strategies
Pith reviewed 2026-05-23 02:36 UTC · model grok-4.3
The pith
Ensemble RL models paired with classifiers deliver better risk-adjusted trading performance than individual RL agents.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
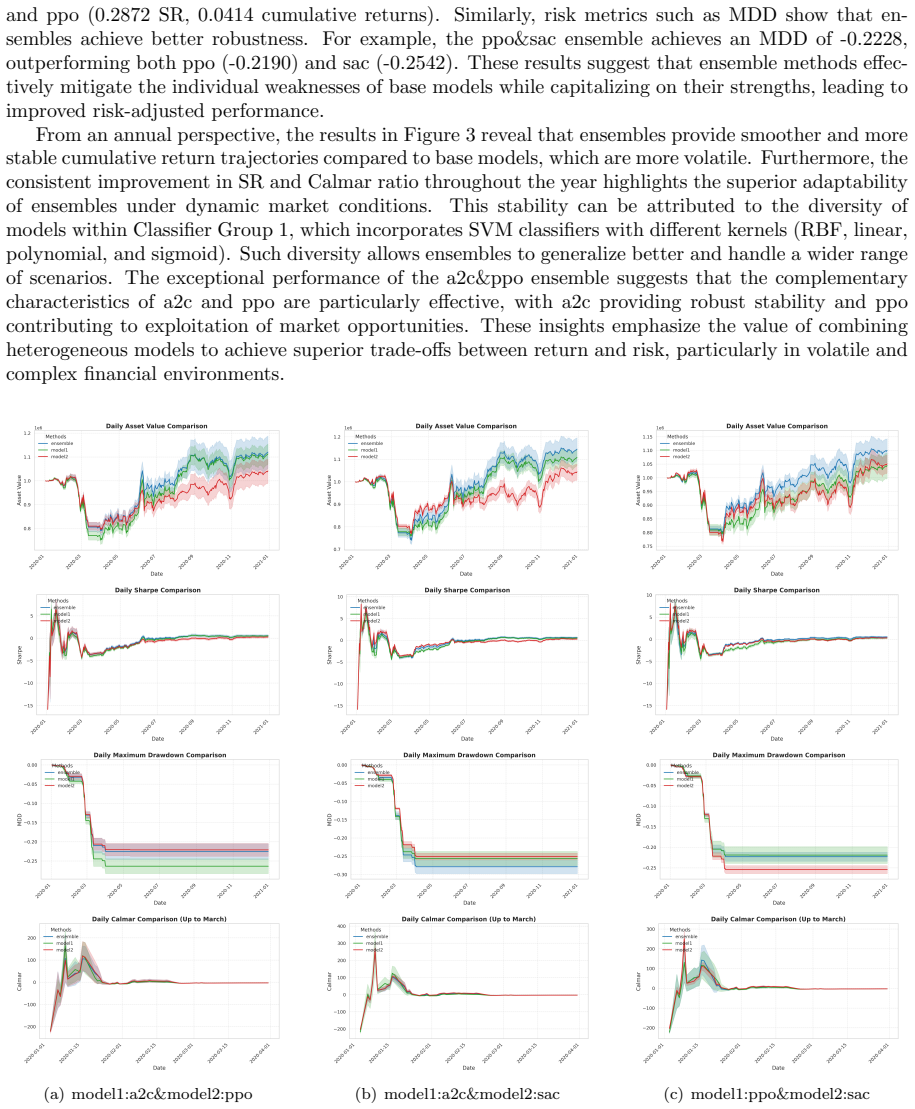
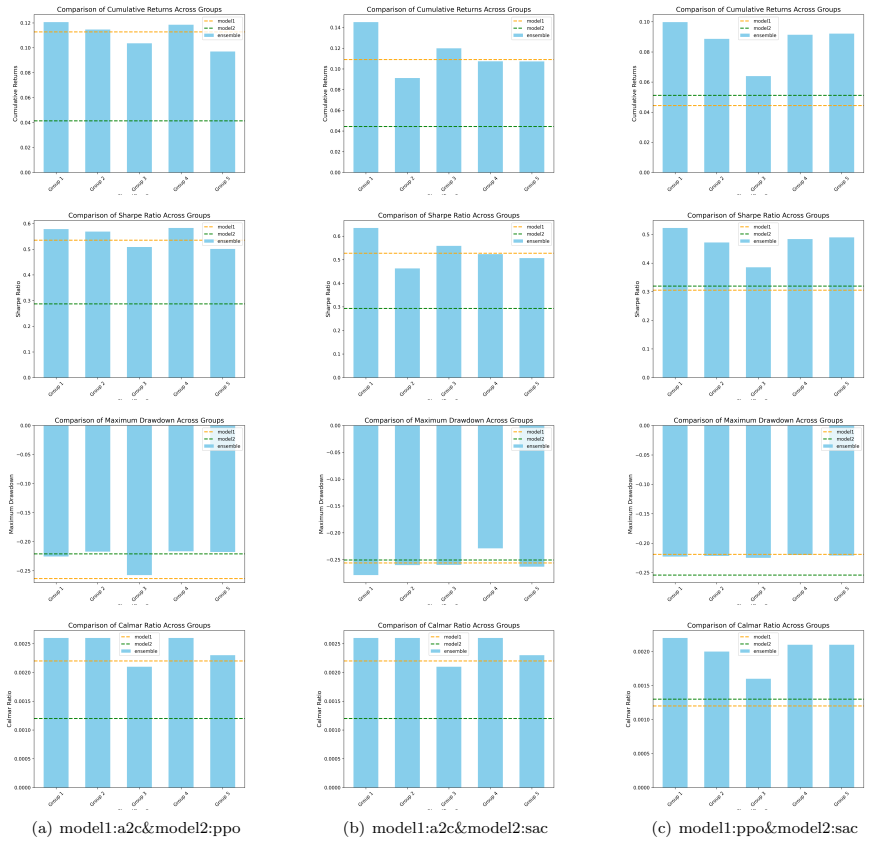
Integrating classifier predictions with RL policies through ensemble rules based on a variance threshold tau produces trading agents that outperform their base RL components on risk-return metrics, including higher Sharpe and Calmar ratios alongside reduced maximum drawdowns.
What carries the argument
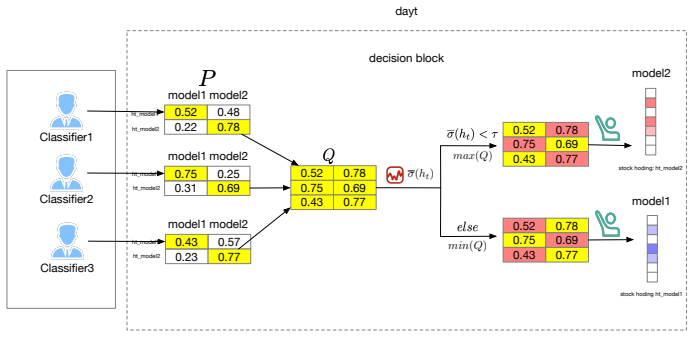
The variance-thresholded ensemble rule that merges action distributions from multiple RL agents with classifier outputs to select or weight decisions.
Load-bearing premise
The chosen classifiers contribute information not already encoded in the RL policies' learned behaviors.
What would settle it
Running the same trading environments and finding that no ensemble variant exceeds the best base RL model on Sharpe ratio or drawdown metrics would contradict the reported outperformance.
Figures

read the original abstract
This paper presents a comprehensive study on the use of ensemble Reinforcement Learning (RL) models in financial trading strategies, leveraging classifier models to enhance performance. By combining RL algorithms such as A2C, PPO, and SAC with traditional classifiers like Support Vector Machines (SVM), Decision Trees, and Logistic Regression, we investigate how different classifier groups can be integrated to improve risk-return trade-offs. The study evaluates the effectiveness of various ensemble methods, comparing them with individual RL models across key financial metrics, including Cumulative Returns, Sharpe Ratios (SR), Calmar Ratios, and Maximum Drawdown (MDD). Our original experimental results demonstrate that ensemble methods often outperform base models in terms of risk-adjusted returns, providing better management of drawdowns and overall stability. However, both the original analysis and the additional reproduction reported in this version show that ensemble performance is sensitive to the choice of variance threshold \(\tau\), classifier group, RL-agent pair, and market universe. The reproduction evidence strengthens the conclusion that classifier-assisted ensemble selection can improve robustness, while also clarifying that the advantage is conditional rather than automatic across all datasets. This study emphasizes the value of combining RL with classifiers for adaptive decision-making, with implications for financial trading, robotics, and other dynamic environments.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that ensembles combining RL algorithms (A2C, PPO, SAC) with classifiers (SVM, Decision Trees, Logistic Regression) outperform individual RL models on financial trading metrics including cumulative returns, Sharpe ratio, Calmar ratio, and maximum drawdown, while noting sensitivity of results to the variance threshold τ.
Significance. If validated with proper controls, the work could provide a practical template for hybrid RL-classical ML ensembles in sequential decision tasks with risk constraints. The explicit acknowledgment of τ sensitivity is a strength, but the absence of reproducibility details and independence checks limits the current impact.
major comments (3)
- [Abstract] Abstract and experimental section: no description of train/test splits, walk-forward validation, or statistical significance testing (e.g., Diebold-Mariano or bootstrap) is provided for the reported SR/Calmar/MDD improvements, making it impossible to assess whether gains exceed sampling variability.
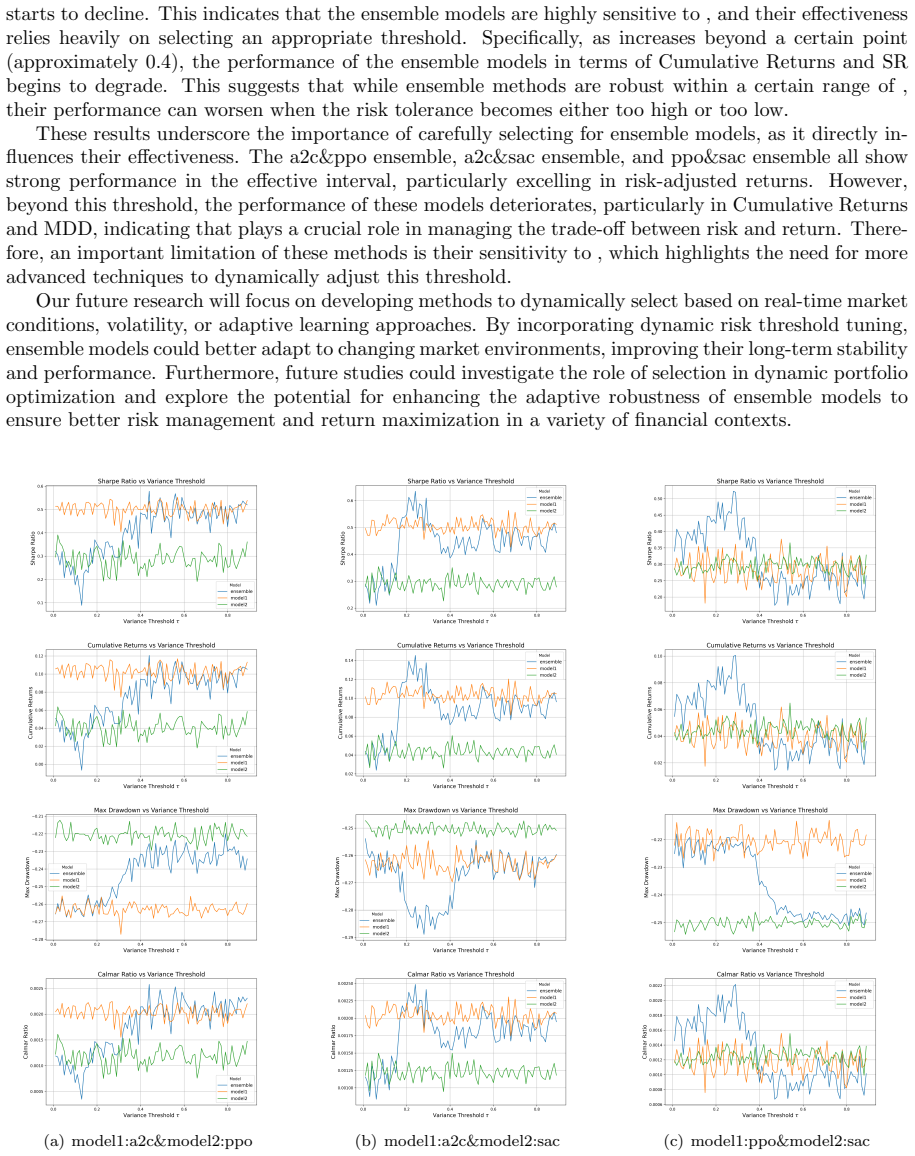
- [Methods / Ensemble Construction] Ensemble integration (variance-threshold gating): τ is treated as a tunable hyperparameter whose optimal value must be selected per experiment; the paper itself flags performance sensitivity to τ, which directly undermines the claim that ensembles are inherently superior rather than the result of post-hoc fitting.
- [Results / Classifier Integration] Classifier-RL complementarity: no ablation, pairwise action-agreement rate, or mutual-information analysis is reported to test whether SVM/DT/LR outputs supply signal orthogonal to the A2C/PPO/SAC policies. Without this, the observed variance reduction is consistent with averaging correlated predictors rather than true ensemble benefit.
minor comments (1)
- [Methods] Notation: the symbol τ is introduced without an explicit equation defining how the variance threshold is computed from the classifier outputs.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which identify key areas for improving the manuscript's clarity, reproducibility, and analytical depth. We respond to each major comment below and indicate the revisions we will make.
read point-by-point responses
-
Referee: [Abstract] Abstract and experimental section: no description of train/test splits, walk-forward validation, or statistical significance testing (e.g., Diebold-Mariano or bootstrap) is provided for the reported SR/Calmar/MDD improvements, making it impossible to assess whether gains exceed sampling variability.
Authors: We agree that these details are necessary for proper evaluation. The revised manuscript will include an expanded Experimental Setup section describing the chronological train/test splits, walk-forward validation procedure to prevent data leakage, and statistical significance testing via bootstrap confidence intervals on the reported metrics. revision: yes
-
Referee: [Methods / Ensemble Construction] Ensemble integration (variance-threshold gating): τ is treated as a tunable hyperparameter whose optimal value must be selected per experiment; the paper itself flags performance sensitivity to τ, which directly undermines the claim that ensembles are inherently superior rather than the result of post-hoc fitting.
Authors: We present the sensitivity to τ as an explicit finding rather than a hidden caveat. Our central claim is that ensembles with suitable τ selection deliver improved risk-return profiles relative to base RL models; this is not claimed to be tuning-free. We will add further discussion and sensitivity plots across τ values to clarify the method's practical use. revision: partial
-
Referee: [Results / Classifier Integration] Classifier-RL complementarity: no ablation, pairwise action-agreement rate, or mutual-information analysis is reported to test whether SVM/DT/LR outputs supply signal orthogonal to the A2C/PPO/SAC policies. Without this, the observed variance reduction is consistent with averaging correlated predictors rather than true ensemble benefit.
Authors: This is a fair critique on the need for explicit complementarity analysis. We will add an ablation study together with pairwise action-agreement rates between the classifier outputs and RL policies in the revised Results section to better demonstrate the source of the observed gains. revision: yes
Circularity Check
Empirical comparison with acknowledged parameter sensitivity; no load-bearing derivation reduces to inputs
full rationale
The paper reports experimental results on ensembles of RL policies (A2C/PPO/SAC) with classifiers (SVM/DT/LR), evaluating financial metrics. The abstract explicitly flags sensitivity of results to the variance threshold τ and calls for dynamic adjustment, indicating performance is not presented as first-principles or independent of this choice. No equations, uniqueness theorems, or self-citations are shown that would make the outperformance claim reduce by construction to fitted inputs or prior author work. The central claim remains an empirical observation rather than a self-referential prediction.
Axiom & Free-Parameter Ledger
free parameters (1)
- variance threshold tau
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.