COMMA: Coordinate-aware Modulated Mamba Network for 3D Dispersed Vessel Segmentation
Pith reviewed 2026-05-23 01:42 UTC · model grok-4.3
The pith
COMMA combines full-image Mamba encoding with patch processing through coordinate modulation to retain spatial context for 3D vessel segmentation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
COMMA achieves superior 3D vessel segmentation by encoding entire images with a channel-compressed Mamba block to capture long-range dependencies efficiently, then routing coordinate information through a modulated block to let local patch branches perceive spatial context, yielding better results on small dispersed vessels than existing approaches.
What carries the argument
The coordinate-aware modulated (CaM) block, which enhances interactions between the global and local branches to allow the local branch to perceive spatial information.
Load-bearing premise
The coordinate-aware modulated block actually improves the local branch's perception of spatial information enough to boost segmentation accuracy.
What would settle it
An ablation experiment that removes the CaM block and measures whether accuracy on small vessels drops compared with the full model.
Figures



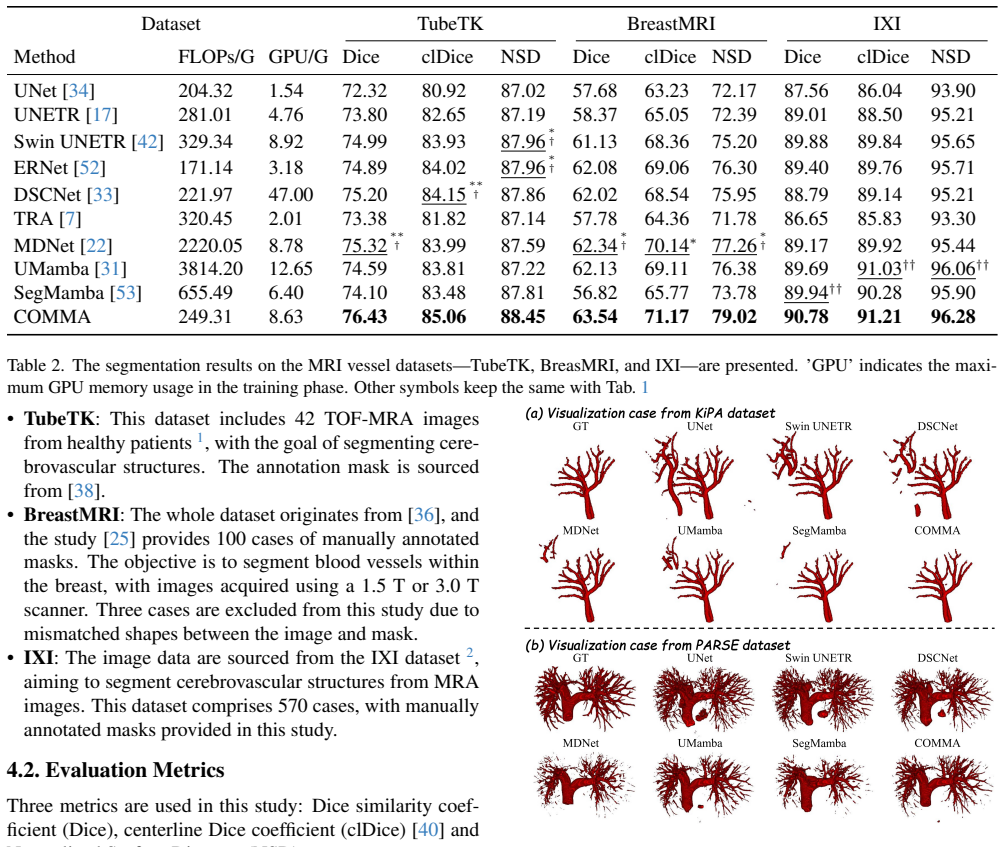
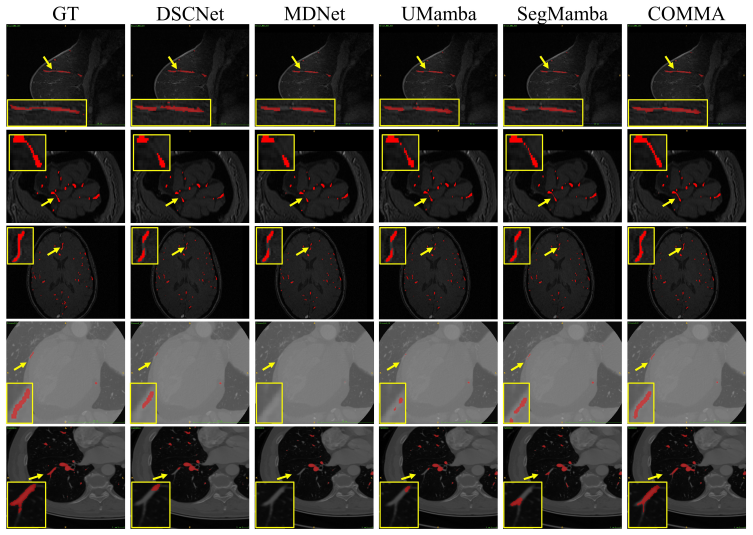


read the original abstract
Accurate segmentation of 3D vascular structures is essential for various medical imaging applications. The dispersed nature of vascular structures leads to inherent spatial uncertainty and necessitates location awareness, yet most current 3D medical segmentation models rely on the patch-wise training strategy that usually loses this spatial context. In this study, we introduce the Coordinate-aware Modulated Mamba Network (COMMA) and contribute a manually labeled dataset of 570 cases, the largest publicly available 3D vessel dataset to date. COMMA leverages both entire and cropped patch data through global and local branches, ensuring robust and efficient spatial location awareness. Specifically, COMMA employs a channel-compressed Mamba (ccMamba) block to encode entire image data, capturing long-range dependencies while optimizing computational costs. Additionally, we propose a coordinate-aware modulated (CaM) block to enhance interactions between the global and local branches, allowing the local branch to better perceive spatial information. We evaluate COMMA on six datasets, covering two imaging modalities and five types of vascular tissues. The results demonstrate COMMA's superior performance compared to state-of-the-art methods with computational efficiency, especially in segmenting small vessels. Ablation studies further highlight the importance of our proposed modules and spatial information. The code and data will be open source at https://github.com/shigen-StoneRoot/COMMA.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes the Coordinate-aware Modulated Mamba Network (COMMA) for segmenting dispersed 3D vascular structures. It combines global (entire-image) and local (patch) branches using a channel-compressed Mamba (ccMamba) block for long-range dependencies and a coordinate-aware modulated (CaM) block to improve spatial awareness in the local branch. The work contributes a new manually annotated dataset of 570 cases (largest public 3D vessel dataset) and evaluates on six datasets spanning two modalities and five vessel types, claiming superior accuracy and efficiency versus state-of-the-art methods, especially for small vessels, with ablations confirming the value of the proposed modules and spatial context.
Significance. If the reported gains hold under rigorous validation, the contribution of a large, publicly released 3D vessel dataset plus open-source code would be a clear asset to the medical-image-segmentation community. The global-local architecture with explicit coordinate modulation addresses a recognized limitation of patch-wise training for dispersed structures and could influence subsequent Mamba-based or hybrid segmentation models.
minor comments (2)
- Abstract: the performance claims are stated qualitatively ('superior performance... with computational efficiency') without any numerical values, dataset-specific scores, or baseline names; adding one or two key metrics (e.g., Dice on the largest test set) would strengthen the summary without lengthening the abstract.
- The manuscript states that code and data 'will be open source' at a GitHub URL; confirming the repository is live at submission time would increase reproducibility.
Simulated Author's Rebuttal
We thank the referee for the positive summary, recognition of the dataset contribution, and recommendation for minor revision. No major comments were provided in the report.
Circularity Check
No significant circularity
full rationale
The paper proposes an empirical architecture (COMMA with ccMamba and CaM blocks) for 3D vessel segmentation and validates it via performance comparisons on six external datasets plus ablations. No derivation chain, equations, or predictions are presented that reduce to self-definition, fitted inputs renamed as predictions, or load-bearing self-citations. The central claims rest on observable segmentation metrics against independent benchmarks, satisfying the self-contained criterion for a score of 0.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Patch-wise training loses spatial context for dispersed vascular structures
- domain assumption Long-range dependencies can be captured efficiently by channel-compressed Mamba blocks
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
COMMA employs a channel-compressed Mamba (ccMamba) block to encode entire image data... coordinate-aware modulated (CaM) block to enhance interactions between the global and local branches
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
unified positional encoding strategy... normalized center coordinates (-1,1) of the randomly cropped patch
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Multilayered thresholding-based blood vessel segmentation for screening of diabetic retinopathy
M Usman Akram and Shoab A Khan. Multilayered thresholding-based blood vessel segmentation for screening of diabetic retinopathy. Engineering with computers , 29: 165–173, 2013. 2
work page 2013
-
[2]
Medical image segmentation review: The suc- cess of u-net
Reza Azad, Ehsan Khodapanah Aghdam, Amelie Rauland, Yiwei Jia, Atlas Haddadi Avval, Afshin Bozorgpour, Sanaz Karimijafarbigloo, Joseph Paul Cohen, Ehsan Adeli, and Dorit Merhof. Medical image segmentation review: The suc- cess of u-net. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2024. 2, 3
work page 2024
-
[3]
Shubhi Bansal, Sreekanth Madisetty, Mohammad Zia Ur Rehman, Chandravardhan Singh Raghaw, Gaurav Dug- gal, Nagendra Kumar, et al. A comprehensive survey of mamba architectures for medical image analysis: Classifi- cation, segmentation, restoration and beyond. arXiv preprint arXiv:2410.02362, 2024. 3
-
[4]
Pseudo-label guided con- trastive learning for semi-supervised medical image segmen- tation
Hritam Basak and Zhaozheng Yin. Pseudo-label guided con- trastive learning for semi-supervised medical image segmen- tation. In CVPR, pages 19786–19797, 2023. 2
work page 2023
-
[5]
Pseudo-label guided con- trastive learning for semi-supervised medical image segmen- tation
Hritam Basak and Zhaozheng Yin. Pseudo-label guided con- trastive learning for semi-supervised medical image segmen- tation. In CVPR, pages 19786–19797, 2023. 9
work page 2023
-
[6]
Gianluca Brugnara, Michael Baumgartner, Edwin David Scholze, Katerina Deike-Hofmann, Klaus Kades, Jonas Scherer, Stefan Denner, Hagen Meredig, Aditya Rastogi, Mustafa Ahmed Mahmutoglu, et al. Deep-learning based detection of vessel occlusions on ct-angiography in patients with suspected acute ischemic stroke. Nature Communica- tions, 14(1):4938, 2023. 1
work page 2023
-
[7]
Cerebrovascular seg- mentation in tof-mra with topology regularization adversar- ial model
Cheng Chen, Yunqing Chen, Shuang Song, Jianan Wang, Huansheng Ning, and Ruoxiu Xiao. Cerebrovascular seg- mentation in tof-mra with topology regularization adversar- ial model. In ACM MM, pages 4250–4259, 2023. 5, 6
work page 2023
-
[8]
All answers are in the images: A review of deep learning for cerebrovascular segmentation
Cheng Chen, Kangneng Zhou, Zhiliang Wang, Qian Zhang, and Ruoxiu Xiao. All answers are in the images: A review of deep learning for cerebrovascular segmentation. Comput- erized Medical Imaging and Graphics , page 102229, 2023. 3
work page 2023
-
[9]
Visformer: The vision-friendly transformer
Zhengsu Chen, Lingxi Xie, Jianwei Niu, Xuefeng Liu, Longhui Wei, and Qi Tian. Visformer: The vision-friendly transformer. In ICCV, pages 589–598, 2021. 3
work page 2021
-
[10]
Tri Dao and Albert Gu. Transformers are SSMs: General- ized models and efficient algorithms through structured state space duality. In ICML, pages 10041–10071. PMLR, 2024. 2, 3
work page 2024
-
[11]
Multiscale vessel enhancement filtering
Alejandro F Frangi, Wiro J Niessen, Koen L Vincken, and Max A Viergever. Multiscale vessel enhancement filtering. In MICCAI, MA, USA, October 11–13, 1998 Proceedings 1, pages 130–137. Springer, 1998. 2
work page 1998
-
[12]
Ramtin Gharleghi, Dona Adikari, Katy Ellenberger, Mark Webster, Chris Ellis, Arcot Sowmya, Sze-Yuan Ooi, and Su- sann Beier. Computed tomography coronary angiogram im- ages, annotations and associated data of normal and diseased arteries. arXiv preprint arXiv:2211.01859, 2022. 5
-
[13]
Innervation of systemic blood vessels
Ian L Gibbins, Judith L Morris, John Furness, and Marcello Costa. Innervation of systemic blood vessels. In Nonadren- ergic innervation of blood vessels , pages 1–36. CRC press,
-
[14]
Mamba: Linear-Time Sequence Modeling with Selective State Spaces
Albert Gu and Tri Dao. Mamba: Linear-time sequence modeling with selective state spaces. arXiv preprint arXiv:2312.00752, 2023. 2, 3
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[15]
A survey on vision transformer
Kai Han, Yunhe Wang, Hanting Chen, Xinghao Chen, Jianyuan Guo, Zhenhua Liu, Yehui Tang, An Xiao, Chunjing Xu, Yixing Xu, et al. A survey on vision transformer. IEEE Transactions on Pattern Analysis and Machine Intelligence, 45(1):87–110, 2022. 3
work page 2022
-
[16]
Cerebrovascular segmentation from tof using stochastic models
M Sabry Hassouna, Aly A Farag, Stephen Hushek, and Thomas Moriarty. Cerebrovascular segmentation from tof using stochastic models. Medical Image Analysis, 10(1):2– 18, 2006. 2
work page 2006
-
[17]
Unetr: Transformers for 3d med- ical image segmentation
Ali Hatamizadeh, Yucheng Tang, Vishwesh Nath, Dong Yang, Andriy Myronenko, Bennett Landman, Holger R Roth, and Daguang Xu. Unetr: Transformers for 3d med- ical image segmentation. In WACV, pages 574–584, 2022. 5, 6
work page 2022
-
[18]
Transformers in medical image analysis
Kelei He, Chen Gan, Zhuoyuan Li, Islem Rekik, Zihao Yin, Wen Ji, Yang Gao, Qian Wang, Junfeng Zhang, and Ding- gang Shen. Transformers in medical image analysis. Intelli- gent Medicine, 3(1):59–78, 2023. 2
work page 2023
-
[19]
Yuting He, Guanyu Yang, Jian Yang, Yang Chen, Youyong Kong, Jiasong Wu, Lijun Tang, Xiaomei Zhu, Jean-Louis Dillenseger, Pengfei Shao, et al. Dense biased networks with deep priori anatomy and hard region adaptation: Semi- supervised learning for fine renal artery segmentation. Med- ical Image Analysis, 63:101722, 2020. 5
work page 2020
-
[20]
Meta grayscale adaptive network for 3d integrated renal structures segmentation
Yuting He, Guanyu Yang, Jian Yang, Rongjun Ge, Youy- ong Kong, Xiaomei Zhu, Shaobo Zhang, Pengfei Shao, Huazhong Shu, Jean-Louis Dillenseger, Jean-Louis Coa- trieux, and Shuo Li. Meta grayscale adaptive network for 3d integrated renal structures segmentation. Medical Image Analysis, 71:102055, 2021. 5
work page 2021
-
[21]
Squeeze-and-excitation net- works
Jie Hu, Li Shen, and Gang Sun. Squeeze-and-excitation net- works. In CVPR, pages 7132–7141, 2018. 5
work page 2018
-
[22]
Jiaxing Huang, Yanfeng Zhou, Yaoru Luo, Guole Liu, Heng Guo, and Ge Yang. Representing topological self-similarity using fractal feature maps for accurate segmentation of tubu- lar structures. In ECCV, pages 143–160. Springer, 2025. 5, 6
work page 2025
-
[23]
nnu-net: a self-configuring method for deep learning-based biomedical image segmen- tation
Fabian Isensee, Paul F Jaeger, Simon AA Kohl, Jens Pe- tersen, and Klaus H Maier-Hein. nnu-net: a self-configuring method for deep learning-based biomedical image segmen- tation. Nature Methods, 18(2):203–211, 2021. 2
work page 2021
-
[24]
Transformers in vision: A survey
Salman Khan, Muzammal Naseer, Munawar Hayat, Syed Waqas Zamir, Fahad Shahbaz Khan, and Mubarak 9 Shah. Transformers in vision: A survey. ACM computing surveys (CSUR), 54(10s):1–41, 2022. 3
work page 2022
-
[25]
Christopher O Lew, Majid Harouni, Ella R Kirksey, Elianne J Kang, Haoyu Dong, Hanxue Gu, Lars J Grimm, Ruth Walsh, Dorothy A Lowell, and Maciej A Mazurowski. A publicly available deep learning model and dataset for segmentation of breast, fibroglandular tissue, and vessels in breast mri.Sci- entific Reports, 14(1):5383, 2024. 6
work page 2024
-
[26]
Mingbao Lin, Mengzhao Chen, Yuxin Zhang, Chunhua Shen, Rongrong Ji, and Liujuan Cao. Super vision trans- former. International Journal of Computer Vision, 131(12): 3136–3151, 2023. 3
work page 2023
-
[27]
Has multimodal learning delivered universal intelligence in healthcare? a comprehensive survey
Qika Lin, Yifan Zhu, Xin Mei, Ling Huang, Jingying Ma, Kai He, Zhen Peng, Erik Cambria, and Mengling Feng. Has multimodal learning delivered universal intelligence in healthcare? a comprehensive survey. Information Fusion, page 102795, 2024. 2
work page 2024
-
[28]
Swin-umamba: Mamba-based unet with imagenet-based pretraining
Jiarun Liu, Hao Yang, Hong-Yu Zhou, Yan Xi, Lequan Yu, Cheng Li, Yong Liang, Guangming Shi, Yizhou Yu, Shaot- ing Zhang, et al. Swin-umamba: Mamba-based unet with imagenet-based pretraining. In MICCAI, pages 615–625. Springer, 2024. 2, 3
work page 2024
-
[29]
Efficient automatic segmentation for multi-level pulmonary arteries: The parse challenge
Gongning Luo, Kuanquan Wang, Jun Liu, Shuo Li, Xinjie Liang, Xiangyu Li, Shaowei Gan, Wei Wang, Suyu Dong, Wenyi Wang, et al. Efficient automatic segmentation for multi-level pulmonary arteries: The parse challenge. arXiv preprint arXiv:2304.03708, 2023. 5, 1, 2
-
[30]
Segment anything in medical images
Jun Ma, Yuting He, Feifei Li, Lin Han, Chenyu You, and Bo Wang. Segment anything in medical images. Nature Communications, 15(1):654, 2024. 2, 1
work page 2024
-
[31]
U-Mamba: Enhancing Long-range Dependency for Biomedical Image Segmentation
Jun Ma, Feifei Li, and Bo Wang. U-mamba: Enhancing long-range dependency for biomedical image segmentation. arXiv preprint arXiv:2401.04722, 2024. 3, 5, 6
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[32]
Self- supervised vessel segmentation via adversarial learning
Yuxin Ma, Yang Hua, Hanming Deng, Tao Song, Hao Wang, Zhengui Xue, Heng Cao, Ruhui Ma, and Haibing Guan. Self- supervised vessel segmentation via adversarial learning. In ICCV, pages 7536–7545, 2021. 9
work page 2021
-
[33]
Yaolei Qi, Yuting He, Xiaoming Qi, Yuan Zhang, and Guanyu Yang. Dynamic snake convolution based on topo- logical geometric constraints for tubular structure segmenta- tion. In ICCV, pages 6070–6079, 2023. 3, 5, 6
work page 2023
-
[34]
U-net: Convolutional networks for biomedical image segmentation
Olaf Ronneberger, Philipp Fischer, and Thomas Brox. U-net: Convolutional networks for biomedical image segmentation. In MICCAI, Munich, Germany, October 5-9, 2015, Proceed- ings, Part III 18, pages 234–241. Springer, 2015. 5, 6
work page 2015
-
[35]
arXiv preprint arXiv:2402.02491 (2024)
Jiacheng Ruan and Suncheng Xiang. Vm-unet: Vision mamba unet for medical image segmentation. arXiv preprint arXiv:2402.02491, 2024. 3
-
[36]
Ashirbani Saha, Michael R Harowicz, Lars J Grimm, Con- nie E Kim, Sujata V Ghate, Ruth Walsh, and Maciej A Mazurowski. A machine learning approach to radiogenomics of breast cancer: a study of 922 subjects and 529 dce-mri features. British Journal of Cancer, 119(4):508–516, 2018. 6
work page 2018
-
[37]
Progressive pretraining network for 3d system ma- trix calibration in magnetic particle imaging
Gen Shi, Lin Yin, Yu An, Guanghui Li, Liwen Zhang, Zhongwei Bian, Ziwei Chen, Haoran Zhang, Hui Hui, and Jie Tian. Progressive pretraining network for 3d system ma- trix calibration in magnetic particle imaging. IEEE Transac- tions on Medical Imaging, 42(12):3639–3650, 2023. 9
work page 2023
-
[38]
Gen Shi, Hao Lu, Hui Hui, and Jie Tian. Benefit from public unlabeled data: A frangi filter-based pretraining network for 3d cerebrovascular segmentation. Medical Image Analysis, 101:103442, 2025. 6
work page 2025
-
[39]
Centerline boundary dice loss for vascular segmentation
Pengcheng Shi, Jiesi Hu, Yanwu Yang, Zilve Gao, Wei Liu, and Ting Ma. Centerline boundary dice loss for vascular segmentation. In MICCAI, pages 46–56. Springer, 2024. 3
work page 2024
-
[40]
cldice-a novel topology-preserving loss function for tubular structure seg- mentation
Suprosanna Shit, Johannes C Paetzold, Anjany Sekuboyina, Ivan Ezhov, Alexander Unger, Andrey Zhylka, Josien PW Pluim, Ulrich Bauer, and Bjoern H Menze. cldice-a novel topology-preserving loss function for tubular structure seg- mentation. In CVPR, pages 16560–16569, 2021. 3, 6
work page 2021
-
[41]
3d attention u-net with pretrain- ing: A solution to cada-aneurysm segmentation challenge
Ziyu Su, Yizhuan Jia, Weibin Liao, Yi Lv, Jiaqi Dou, Zhong- wei Sun, and Xuesong Li. 3d attention u-net with pretrain- ing: A solution to cada-aneurysm segmentation challenge. In Cerebral Aneurysm Detection and Analysis: First Chal- lenge, CADA 2020, Held in Conjunction with MICCAI 2020, Lima, Peru, October 8, 2020, Proceedings 1 , pages 58–67. Springer, 2021. 2
work page 2020
-
[42]
Self-supervised pre-training of swin trans- formers for 3d medical image analysis
Yucheng Tang, Dong Yang, Wenqi Li, Holger R Roth, Bennett Landman, Daguang Xu, Vishwesh Nath, and Ali Hatamizadeh. Self-supervised pre-training of swin trans- formers for 3d medical image analysis. In CVPR, pages 20730–20740, 2022. 5, 6
work page 2022
-
[43]
Ilaria Tortorelli, Elena Bellan, Benedetta Chiusole, Fabio Murtas, Pietro Ruggieri, Elisa Pala, Mariachiara Cerchiaro, Maria Samaritana Buzzaccarini, Giovanni Scarzello, Marco Krengli, et al. Primary vascular tumors of bone: a com- prehensive literature review on classification, diagnosis and treatment. Critical Reviews in Oncology/Hematology, page 104268...
work page 2024
-
[44]
James J Tronolone, Tanmay Mathur, Christopher P Chaftari, and Abhishek Jain. Evaluation of the morphological and bio- logical functions of vascularized microphysiological systems with supervised machine learning. Annals of Biomedical En- gineering, 51(8):1723–1737, 2023
work page 2023
-
[45]
Deep learning for mr angiography: auto- mated detection of cerebral aneurysms
Daiju Ueda, Akira Yamamoto, Masataka Nishimori, Taro Shimono, Satoshi Doishita, Akitoshi Shimazaki, Yutaka Katayama, Shinya Fukumoto, Antoine Choppin, Yuki Shimahara, et al. Deep learning for mr angiography: auto- mated detection of cerebral aneurysms. Radiology, 290(1): 187–194, 2019. 2
work page 2019
-
[46]
Augmenting vascular disease di- agnosis by vasculature-aware unsupervised learning
Yong Wang, Mengqi Ji, Shengwei Jiang, Xukang Wang, Ji- amin Wu, Feng Duan, Jingtao Fan, Laiqiang Huang, Shao- hua Ma, Lu Fang, et al. Augmenting vascular disease di- agnosis by vasculature-aware unsupervised learning. Nature Machine Intelligence, 2(6):337–346, 2020. 1
work page 2020
-
[47]
vesselfm: A foundation model for universal 3d blood vessel segmenta- tion
Bastian Wittmann, Yannick Wattenberg, Tamaz Ami- ranashvili, Suprosanna Shit, and Bjoern Menze. vesselfm: A foundation model for universal 3d blood vessel segmenta- tion. arXiv preprint arXiv:2411.17386, 2024. 1
-
[48]
Cbam: Convolutional block attention module
Sanghyun Woo, Jongchan Park, Joon-Young Lee, and In So Kweon. Cbam: Convolutional block attention module. In ECCV, pages 3–19, 2018. 5
work page 2018
-
[49]
Junde Wu, Wei Ji, Yuanpei Liu, Huazhu Fu, Min Xu, Yanwu Xu, and Yueming Jin. Medical sam adapter: Adapting seg- 10 ment anything model for medical image segmentation.arXiv preprint arXiv:2304.12620, 2023. 2
-
[50]
Deep closing: Enhancing topological connectiv- ity in medical tubular segmentation
Qian Wu, Yufei Chen, Wei Liu, Xiaodong Yue, and Xiahai Zhuang. Deep closing: Enhancing topological connectiv- ity in medical tubular segmentation. IEEE Transactions on Medical Imaging, 43(11):3990–4003, 2024. 9
work page 2024
-
[51]
Yanan Wu, Shouliang Qi, Meihuan Wang, Shuiqing Zhao, Haowen Pang, Jiaxuan Xu, Long Bai, and Hongliang Ren. Transformer-based 3d u-net for pulmonary vessel segmen- tation and artery-vein separation from ct images. Medical & Biological Engineering & Computing, 61(10):2649–2663,
-
[52]
3d vessel-like structure segmentation in medical images by an edge-reinforced network
Likun Xia, Hao Zhang, Yufei Wu, Ran Song, Yuhui Ma, Lei Mou, Jiang Liu, Yixuan Xie, Ming Ma, and Yitian Zhao. 3d vessel-like structure segmentation in medical images by an edge-reinforced network. Medical Image Analysis , 82: 102581, 2022. 3, 5, 6
work page 2022
-
[53]
Segmamba: Long-range sequential modeling mamba for 3d medical image segmentation
Zhaohu Xing, Tian Ye, Yijun Yang, Guang Liu, and Lei Zhu. Segmamba: Long-range sequential modeling mamba for 3d medical image segmentation. In MICCAI, pages 578–588. Springer, 2024. 2, 3, 5, 6
work page 2024
-
[54]
A survey on vision mamba: Models, applications and chal- lenges
Rui Xu, Shu Yang, Yihui Wang, Bo Du, and Hao Chen. A survey on vision mamba: Models, applications and chal- lenges. arXiv preprint arXiv:2404.18861, 2024. 3
-
[55]
Chenyu You, Weicheng Dai, Yifei Min, Fenglin Liu, David A. Clifton, S. Kevin Zhou, Lawrence H. Staib, and James S. Duncan. Rethinking semi-supervised medical im- age segmentation: A variance-reduction perspective. In NeurIPS, New Orleans, LA, USA, December 10 - 16, 2023 ,
work page 2023
-
[56]
R Eugene Zierler, William D Jordan, Brajesh K Lal, Firas Mussa, Steven Leers, Joseph Fulton, William Pevec, Andrew Hill, and M Hassan Murad. The society for vascular surgery practice guidelines on follow-up after vascular surgery arte- rial procedures. Journal of vascular surgery, 68(1):256–284,
-
[57]
Performance of foundation model for 3D vessel segmen- tation
2 11 COMMA: Coordinate-aware Modulated Mamba Network for 3D Dispersed Vessel Segmentation Supplementary Material Figure 8. Performance of foundation model for 3D vessel segmen- tation
-
[58]
Appendix 7.1. Analysis of Fundation Model for 3D Vessel Seg- mantation The Medical-SAM was reported to perform poorly on vas- cular structures [30]. A 3D vessel FM study [47] (no pub- lic code) showed massive artifacts in vessel segmentation (Fig. 8a). The SAM-Med3D on a PARSE case also show low performance (Fig. 8b). We therefore believe that, at this st...
-
[59]
The λ is empirically set to 0.25
In the CaM block, the local feature patch sizes for each stage are [1, 2, 3, 6], while the global feature patch size remains consistently 8 at each stage. The λ is empirically set to 0.25. 7.4. Definition of Small Vessel Sructures The small vessels tend to have lower contrast, making seg- mentation more challenging. In this study, we define the 1 vessels ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.