MathFlow: Enhancing the Perceptual Flow of MLLMs for Visual Mathematical Problems
Pith reviewed 2026-05-22 22:49 UTC · model grok-4.3
The pith
Decoupling perception into a separate trained stage improves MLLM accuracy on diagram-based math problems.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
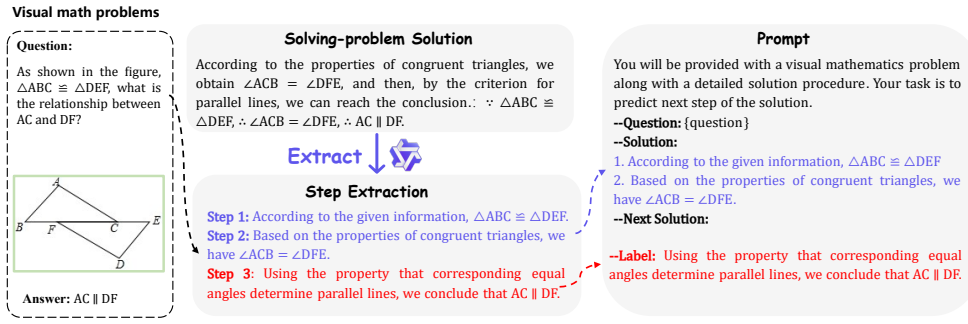
MathFlow is a modular pipeline that decouples perception of diagrams from subsequent inference. Training a dedicated perception model, MathFlow-P-7B, and feeding its output to various inference models produces substantial performance gains on visual mathematical tasks.
What carries the argument
The MathFlow pipeline that isolates diagram perception as an independent, trainable stage before handing structured information to an inference model.
If this is right
- Perception can be optimized independently of the reasoning component.
- The same perception model works with multiple closed-source and open-source inference systems.
- FlowVerse supplies separate scores for perception accuracy and reasoning accuracy.
Where Pith is reading between the lines
- The same separation might help other visual domains where diagrams or charts are central.
- Specialized perception models could be developed for different diagram styles or subjects.
- The benchmark could be used to diagnose exactly which visual features current models miss.
Load-bearing premise
That training perception separately will reliably improve end-to-end results without introducing new interface errors between the two stages.
What would settle it
An experiment in which MathFlow-P-7B is paired with the same inference models on FlowVerse and yields no accuracy increase over the baseline MLLM.
Figures













read the original abstract
Despite strong results on many tasks, multimodal large language models (MLLMs) still underperform on visual mathematical problem solving, especially in reliably perceiving and interpreting diagrams. Inspired by human problem-solving, we hypothesize that the ability to extract meaningful information from diagrams is pivotal, as it directly conditions subsequent inference. Hence, we introduce FlowVerse, a comprehensive benchmark that provides a fine-grained evaluation of MLLMs' perception and reasoning capabilities. Our preliminary results on FlowVerse reveal that existing MLLMs exhibit substantial limitations when extracting essential information and reasoned properties from diagrams and performing complex reasoning based on these visual inputs. In response, we introduce MathFlow, a modular problem-solving pipeline that decouples perception and inference into distinct stages, thereby optimizing each independently. Given the perceptual limitations observed in current MLLMs, we trained MathFlow-P-7B as a dedicated perception model. Experimental results indicate that MathFlow-P-7B yields substantial performance gains when integrated with various closed-source and open-source inference models. This demonstrates the effectiveness of the MathFlow pipeline and its compatibility with diverse inference frameworks. Project page: https://github.com/MathFlow-zju/MathFlow.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces FlowVerse, a benchmark providing fine-grained evaluation of MLLMs' perception and reasoning on visual mathematical problems, and MathFlow, a modular pipeline decoupling perception from inference. It trains MathFlow-P-7B as a dedicated perception model and reports that this yields substantial performance gains when paired with various closed- and open-source inference models.
Significance. If the claimed gains hold under scrutiny, the work would provide evidence that separating and specializing the perception stage can address a key bottleneck in MLLM visual math solving, while also supplying a new benchmark for the community.
major comments (2)
- [Abstract] Abstract: the central claim of 'substantial performance gains' from MathFlow-P-7B is stated without any quantitative metrics, dataset sizes, error bars, or ablation results, preventing verification of the effect size or statistical reliability.
- [Abstract] The hypothesis that decoupling perception into a separate trained stage will reliably improve end-to-end performance is presented as pivotal, yet the abstract supplies no evidence on whether the perception model was trained on data disjoint from the inference models or benchmarks.
minor comments (1)
- [Abstract] The project page link is provided, which supports potential reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the two major comments point-by-point below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim of 'substantial performance gains' from MathFlow-P-7B is stated without any quantitative metrics, dataset sizes, error bars, or ablation results, preventing verification of the effect size or statistical reliability.
Authors: We agree that the abstract would be strengthened by including quantitative support for the central claim. In the revision we will add specific performance deltas on FlowVerse (with dataset sizes), while retaining the note that full ablations, error bars, and statistical details appear in the experimental sections. revision: yes
-
Referee: [Abstract] The hypothesis that decoupling perception into a separate trained stage will reliably improve end-to-end performance is presented as pivotal, yet the abstract supplies no evidence on whether the perception model was trained on data disjoint from the inference models or benchmarks.
Authors: We acknowledge the abstract does not explicitly state data disjointness. We will insert a concise clause confirming that MathFlow-P-7B was trained on data disjoint from both the FlowVerse benchmark and the inference models used in the paired experiments. The full training-data description and separation protocol are already detailed in Sections 3 and 4. revision: yes
Circularity Check
No significant circularity
full rationale
The paper describes an empirical pipeline: creation of FlowVerse benchmark, observation of MLLM perception limits, introduction of modular MathFlow decoupling perception/inference, training of MathFlow-P-7B, and reporting of integration gains. No equations, fitted parameters, derivations, or uniqueness theorems appear. No self-citation chains or ansatzes are invoked as load-bearing. The performance claims rest on external experimental results rather than any quantity that reduces to its own inputs by construction. This is a standard empirical contribution with self-contained evaluation.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 1 Pith paper
-
Large Language Models for Operations Research: A Comprehensive Survey
A survey compiling roles, applications, benchmarks, challenges, and future directions for large language models in operations research.
Reference graph
Works this paper leans on
-
[1]
Large language models for mathematical reasoning: Progresses and challenges
Janice Ahn, Rishu Verma, Renze Lou, Di Liu, Rui Zhang, and Wenpeng Yin. Large language models for mathemat- ical reasoning: Progresses and challenges. arXiv preprint arXiv:2402.00157, 2024. 2
-
[2]
Flamingo: a visual language model for few-shot learning
Jean-Baptiste Alayrac, Jeff Donahue, Pauline Luc, Antoine Miech, Iain Barr, Yana Hasson, Karel Lenc, Arthur Men- sch, Katherine Millican, Malcolm Reynolds, et al. Flamingo: a visual language model for few-shot learning. Advances in neural information processing systems, 35:23716–23736,
-
[3]
MathQA: Towards Interpretable Math Word Problem Solving with Operation-Based Formalisms
Aida Amini, Saadia Gabriel, Peter Lin, Rik Koncel- Kedziorski, Yejin Choi, and Hannaneh Hajishirzi. Mathqa: Towards interpretable math word problem solving with operation-based formalisms. arXiv preprint arXiv:1905.13319, 2019. 3
work page internal anchor Pith review Pith/arXiv arXiv 1905
-
[4]
claude-3-5-sonnet system card, 2024
Anthropic. claude-3-5-sonnet system card, 2024. 4, 6, 9
work page 2024
-
[5]
OpenFlamingo: An Open-Source Framework for Training Large Autoregressive Vision-Language Models
Anas Awadalla, Irena Gao, Josh Gardner, Jack Hessel, Yusuf Hanafy, Wanrong Zhu, Kalyani Marathe, Yonatan Bitton, Samir Gadre, Shiori Sagawa, et al. Openflamingo: An open- source framework for training large autoregressive vision- language models. arXiv preprint arXiv:2308.01390 , 2023. 3
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[6]
Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond
Jinze Bai, Shuai Bai, Shusheng Yang, Shijie Wang, Sinan Tan, Peng Wang, Junyang Lin, Chang Zhou, and Jingren Zhou. Qwen-vl: A frontier large vision-language model with versatile abilities. arXiv preprint arXiv:2308.12966, 2023. 1, 4, 5, 6, 9
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[7]
Geogpt4v: Towards geometric multi-modal large language models with geometric image generation
Shihao Cai, Keqin Bao, Hangyu Guo, Jizhi Zhang, Jun Song, and Bo Zheng. Geogpt4v: Towards geometric multi-modal large language models with geometric image generation. arXiv preprint arXiv:2406.11503, 2024. 6
-
[8]
Geoqa: A geometric question answering benchmark towards multimodal numeri- cal reasoning
Jiaqi Chen, Jianheng Tang, Jinghui Qin, Xiaodan Liang, Lingbo Liu, Eric P Xing, and Liang Lin. Geoqa: A geometric question answering benchmark towards multimodal numeri- cal reasoning. arXiv preprint arXiv:2105.14517, 2021. 1
-
[9]
Unigeo: Unifying ge- ometry logical reasoning via reformulating mathematical ex- pression
Jiaqi Chen, Tong Li, Jinghui Qin, Pan Lu, Liang Lin, Chongyu Chen, and Xiaodan Liang. Unigeo: Unifying ge- ometry logical reasoning via reformulating mathematical ex- pression. arXiv preprint arXiv:2212.02746, 2022. 1
-
[10]
MiniGPT-v2: large language model as a unified interface for vision-language multi-task learning
Jun Chen, Deyao Zhu, Xiaoqian Shen, Xiang Li, Zechun Liu, Pengchuan Zhang, Raghuraman Krishnamoorthi, Vikas Chandra, Yunyang Xiong, and Mohamed Elhoseiny. Minigpt-v2: large language model as a unified interface for vision-language multi-task learning. arXiv preprint arXiv:2310.09478, 2023. 1
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[11]
Chatcot: Tool- augmented chain-of-thought reasoning on chat-based large language models
Zhipeng Chen, Kun Zhou, Beichen Zhang, Zheng Gong, Wayne Xin Zhao, and Ji-Rong Wen. Chatcot: Tool- augmented chain-of-thought reasoning on chat-based large language models. arXiv preprint arXiv:2305.14323, 2023. 3
-
[12]
Zhe Chen, Weiyun Wang, Yue Cao, Yangzhou Liu, Zhang- wei Gao, Erfei Cui, Jinguo Zhu, Shenglong Ye, Hao Tian, Zhaoyang Liu, et al. Expanding performance boundaries of open-source multimodal models with model, data, and test- time scaling. arXiv preprint arXiv:2412.05271, 2024. 4, 6
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[13]
How to learn and teach economics with large language models, including gpt
Tyler Cowen and Alexander T Tabarrok. How to learn and teach economics with large language models, including gpt
-
[14]
Xiaoyi Dong, Pan Zhang, Yuhang Zang, Yuhang Cao, Bin Wang, Linke Ouyang, Xilin Wei, Songyang Zhang, Haodong Duan, Maosong Cao, et al. Internlm-xcomposer2: Mastering free-form text-image composition and compre- hension in vision-language large model. arXiv preprint arXiv:2401.16420, 2024. 5, 6, 9
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[15]
Mohammed Elhenawy, Ahmad Abutahoun, Taqwa I Alha- didi, Ahmed Jaber, Huthaifa I Ashqar, Shadi Jaradat, Ahmed Abdelhay, Sebastien Glaser, and Andry Rakotonirainy. Vi- sual reasoning and multi-agent approach in multimodal large language models (mllms): Solving tsp and mtsp combinato- rial challenges. arXiv preprint arXiv:2407.00092, 2024. 3
-
[16]
Tony Haoran Feng, Paul Denny, Burkhard Wuensche, An- drew Luxton-Reilly, and Steffan Hooper. More than meets the ai: Evaluating the performance of gpt-4 on computer graphics assessment questions. In Proceedings of the 26th Australasian Computing Education Conference, pages 182– 191, 2024. 2
work page 2024
-
[17]
Gpt-3: Its nature, scope, limits, and consequences
Luciano Floridi and Massimo Chiriatti. Gpt-3: Its nature, scope, limits, and consequences. Minds and Machines, 30: 681–694, 2020. 3
work page 2020
-
[18]
Mathematical capabilities of chatgpt
Simon Frieder, Luca Pinchetti, Ryan-Rhys Griffiths, Tom- maso Salvatori, Thomas Lukasiewicz, Philipp Petersen, and Julius Berner. Mathematical capabilities of chatgpt. Ad- vances in neural information processing systems , 36, 2024. 3
work page 2024
-
[19]
Omni-MATH: A Universal Olympiad Level Mathematic Benchmark For Large Language Models
Bofei Gao, Feifan Song, Zhe Yang, Zefan Cai, Yibo Miao, Qingxiu Dong, Lei Li, Chenghao Ma, Liang Chen, Runxin Xu, et al. Omni-math: A universal olympiad level mathe- matic benchmark for large language models. arXiv preprint arXiv:2410.07985, 2024. 3
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[21]
G-LLaVA: Solving Geometric Problem with Multi- Modal Large Language Model.arXiv:2312.11370, 2023
Jiahui Gao, Renjie Pi, Jipeng Zhang, Jiacheng Ye, Wan- jun Zhong, Yufei Wang, Lanqing Hong, Jianhua Han, Hang Xu, Zhenguo Li, et al. G-llava: Solving geometric prob- lem with multi-modal large language model. arXiv preprint arXiv:2312.11370, 2023. 6
-
[22]
LLaMA-Adapter V2: Parameter-Efficient Visual Instruction Model
Peng Gao, Jiaming Han, Renrui Zhang, Ziyi Lin, Shijie Geng, Aojun Zhou, Wei Zhang, Pan Lu, Conghui He, Xi- angyu Yue, et al. Llama-adapter v2: Parameter-efficient vi- sual instruction model. arXiv preprint arXiv:2304.15010 ,
work page internal anchor Pith review Pith/arXiv arXiv
-
[23]
Peng Gao, Renrui Zhang, Chris Liu, Longtian Qiu, Siyuan Huang, Weifeng Lin, Shitian Zhao, Shijie Geng, Ziyi Lin, Peng Jin, et al. Sphinx-x: Scaling data and parameters for a family of multi-modal large language models.arXiv preprint arXiv:2402.05935, 2024. 5, 6, 9
-
[24]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning. arXiv preprint arXiv:2501.12948, 2025. 7
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[25]
Infimm-webmath-40b: Advancing mul- timodal pre-training for enhanced mathematical reasoning
Xiaotian Han, Yiren Jian, Xuefeng Hu, Haogeng Liu, Yiqi Wang, Qihang Fan, Yuang Ai, Huaibo Huang, Ran He, Zhen- heng Yang, et al. Infimm-webmath-40b: Advancing mul- timodal pre-training for enhanced mathematical reasoning. arXiv preprint arXiv:2409.12568, 2024. 3, 4, 5, 9
-
[26]
Measuring Mathematical Problem Solving With the MATH Dataset
Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874, 2021. 3, 12
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[27]
Albert Q Jiang, Alexandre Sablayrolles, Antoine Roux, Arthur Mensch, Blanche Savary, Chris Bamford, Deven- dra Singh Chaplot, Diego de las Casas, Emma Bou Hanna, Florian Bressand, et al. Mixtral of experts. arXiv preprint arXiv:2401.04088, 2024. 3
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[28]
Jennifer L Krawec. Problem representation and mathemati- cal problem solving of students of varying math ability.Jour- nal of Learning Disabilities, 47(2):103–115, 2014. 1
work page 2014
-
[29]
Solving quantitative reasoning problems with language mod- els
Aitor Lewkowycz, Anders Andreassen, David Dohan, Ethan Dyer, Henryk Michalewski, Vinay Ramasesh, Ambrose Slone, Cem Anil, Imanol Schlag, Theo Gutman-Solo, et al. Solving quantitative reasoning problems with language mod- els. Advances in Neural Information Processing Systems, 35: 3843–3857, 2022. 3
work page 2022
-
[30]
LLaVA-OneVision: Easy Visual Task Transfer
Bo Li, Yuanhan Zhang, Dong Guo, Renrui Zhang, Feng Li, Hao Zhang, Kaichen Zhang, Yanwei Li, Ziwei Liu, and Chunyuan Li. Llava-onevision: Easy visual task transfer. arXiv preprint arXiv:2408.03326, 2024. 1, 3
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[31]
LLaVA-NeXT-Interleave: Tackling Multi-image, Video, and 3D in Large Multimodal Models
Feng Li, Renrui Zhang, Hao Zhang, Yuanhan Zhang, Bo Li, Wei Li, Zejun Ma, and Chunyuan Li. Llava-next-interleave: Tackling multi-image, video, and 3d in large multimodal models. arXiv preprint arXiv:2407.07895, 2024. 3
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[32]
Eagle: Elevating geo- metric reasoning through llm-empowered visual instruction tuning
Zhihao Li, Yao Du, Yang Liu, Yan Zhang, Yufang Liu, Mengdi Zhang, and Xunliang Cai. Eagle: Elevating geo- metric reasoning through llm-empowered visual instruction tuning. arXiv preprint arXiv:2408.11397, 2024. 3
-
[33]
Hunter Lightman, Vineet Kosaraju, Yura Burda, Harri Ed- wards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, and Karl Cobbe. Let’s verify step by step. arXiv preprint arXiv:2305.20050, 2023. 3
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[34]
Ziyi Lin, Chris Liu, Renrui Zhang, Peng Gao, Longtian Qiu, Han Xiao, Han Qiu, Chen Lin, Wenqi Shao, Keqin Chen, et al. Sphinx: The joint mixing of weights, tasks, and visual embeddings for multi-modal large language models. arXiv preprint arXiv:2311.07575, 2023. 1
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[35]
Aixin Liu, Bei Feng, Bing Xue, Bingxuan Wang, Bochao Wu, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chenyu Zhang, Chong Ruan, et al. Deepseek-v3 technical report. arXiv preprint arXiv:2412.19437, 2024. 7
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[36]
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning. Advances in neural information processing systems, 36, 2024. 1, 3
work page 2024
-
[37]
Hongwei Liu, Zilong Zheng, Yuxuan Qiao, Haodong Duan, Zhiwei Fei, Fengzhe Zhou, Wenwei Zhang, Songyang Zhang, Dahua Lin, and Kai Chen. Mathbench: Evalu- ating the theory and application proficiency of llms with a hierarchical mathematics benchmark. arXiv preprint arXiv:2405.12209, 2024. 3
-
[38]
Wentao Liu, Qianjun Pan, Yi Zhang, Zhuo Liu, Ji Wu, Jie Zhou, Aimin Zhou, Qin Chen, Bo Jiang, and Liang He. Cmm-math: A chinese multimodal math dataset to evaluate and enhance the mathematics reasoning of large multimodal models. arXiv preprint arXiv:2409.02834, 2024. 3
-
[39]
Finemath: A fine-grained mathematical evaluation bench- mark for chinese large language models
Yan Liu, Renren Jin, Ling Shi, Zheng Yao, and Deyi Xiong. Finemath: A fine-grained mathematical evaluation bench- mark for chinese large language models. arXiv preprint arXiv:2403.07747, 2024. 3
-
[40]
MathVista: Evaluating Mathematical Reasoning of Foundation Models in Visual Contexts
Pan Lu, Hritik Bansal, Tony Xia, Jiacheng Liu, Chunyuan Li, Hannaneh Hajishirzi, Hao Cheng, Kai-Wei Chang, Michel Galley, and Jianfeng Gao. Mathvista: Evaluating mathemat- ical reasoning of foundation models in visual contexts.arXiv preprint arXiv:2310.02255, 2023. 1, 3
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[41]
Visaidmath: Benchmark- ing visual-aided mathematical reasoning
Jingkun Ma, Runzhe Zhan, Derek F Wong, Yang Li, Di Sun, Hou Pong Chan, and Lidia S Chao. Visaidmath: Benchmark- ing visual-aided mathematical reasoning. arXiv preprint arXiv:2410.22995, 2024. 3
-
[42]
Language Models are Few-Shot Learners
Ben Mann, N Ryder, M Subbiah, J Kaplan, P Dhariwal, A Neelakantan, P Shyam, G Sastry, A Askell, S Agarwal, et al. Language models are few-shot learners. arXiv preprint arXiv:2005.14165, 1, 2020. 3
work page internal anchor Pith review Pith/arXiv arXiv 2005
-
[43]
A Comprehensive Overview of Large Language Models
Humza Naveed, Asad Ullah Khan, Shi Qiu, Muhammad Saqib, Saeed Anwar, Muhammad Usman, Naveed Akhtar, Nick Barnes, and Ajmal Mian. A comprehensive overview of large language models. arXiv preprint arXiv:2307.06435,
work page internal anchor Pith review Pith/arXiv arXiv
-
[44]
OpenAI. Chatgpt. https://chat.openai.com, 2023. 3
work page 2023
- [45]
-
[46]
GPT-4V(ision) system card, 2023
OpenAI. GPT-4V(ision) system card, 2023. 3, 4, 5, 6, 9
work page 2023
- [47]
-
[48]
Multimath: Bridging visual and mathematical reasoning for large language models
Shuai Peng, Di Fu, Liangcai Gao, Xiuqin Zhong, Hongguang Fu, and Zhi Tang. Multimath: Bridging visual and mathe- matical reasoning for large language models. arXiv preprint arXiv:2409.00147, 2024. 3
-
[49]
How to solve it: A new aspect of mathematical method
George Polya and George P ´olya. How to solve it: A new aspect of mathematical method . Princeton university press,
-
[50]
We-Math: Does Your Large Multimodal Model Achieve Human-like Mathematical Reasoning?
Runqi Qiao, Qiuna Tan, Guanting Dong, Minhui Wu, Chong Sun, Xiaoshuai Song, Zhuoma GongQue, Shanglin Lei, Zhe Wei, Miaoxuan Zhang, et al. We-math: Does your large mul- timodal model achieve human-like mathematical reasoning? arXiv preprint arXiv:2407.01284, 2024. 2, 3, 12
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[51]
Learning transferable visual models from natural language supervi- sion
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervi- sion. In International conference on machine learning, pages 8748–8763. PMLR, 2021. 1
work page 2021
-
[52]
Vision language models are blind
Pooyan Rahmanzadehgervi, Logan Bolton, Moham- mad Reza Taesiri, and Anh Totti Nguyen. Vision language models are blind. arXiv preprint arXiv:2407.06581 , 2024. 1, 2
-
[53]
Towards robust automated math problem solving: a survey of statistical and deep learning approaches
Amrutesh Saraf, Pooja Kamat, Shilpa Gite, Satish Kumar, and Ketan Kotecha. Towards robust automated math problem solving: a survey of statistical and deep learning approaches. Evolutionary Intelligence, pages 1–38, 2024. 3
work page 2024
-
[54]
Can llms master math? investigating large language models on math stack exchange
Ankit Satpute, Noah Gießing, Andr ´e Greiner-Petter, Moritz Schubotz, Olaf Teschke, Akiko Aizawa, and Bela Gipp. Can llms master math? investigating large language models on math stack exchange. In Proceedings of the 47th Interna- tional ACM SIGIR Conference on Research and Develop- ment in Information Retrieval, pages 2316–2320, 2024. 3
work page 2024
-
[55]
P ´olya, problem solving, and education
Alan H Schoenfeld. P ´olya, problem solving, and education. Mathematics magazine, 60(5):283–291, 1987. 1, 2
work page 1987
-
[56]
Survey of different large language model archi- tectures: Trends, benchmarks, and challenges
Minghao Shao, Abdul Basit, Ramesh Karri, and Muhammad Shafique. Survey of different large language model archi- tectures: Trends, benchmarks, and challenges. IEEE Access,
-
[57]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Y Wu, et al. Deepseekmath: Pushing the limits of mathe- matical reasoning in open language models. arXiv preprint arXiv:2402.03300, 2024. 3
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[58]
Math-llava: Bootstrapping mathematical reasoning for multimodal large language models
Wenhao Shi, Zhiqiang Hu, Yi Bin, Junhua Liu, Yang Yang, See-Kiong Ng, Lidong Bing, and Roy Ka-Wei Lee. Math- llava: Bootstrapping mathematical reasoning for multimodal large language models. arXiv preprint arXiv:2406.17294 ,
-
[59]
Automatic prompt augmentation and selection with chain-of-thought from labeled data,
KaShun Shum, Shizhe Diao, and Tong Zhang. Automatic prompt augmentation and selection with chain-of-thought from labeled data. arXiv preprint arXiv:2302.12822, 2023. 3
-
[60]
Gemini: A Family of Highly Capable Multimodal Models
Gemini Team, Rohan Anil, Sebastian Borgeaud, Jean- Baptiste Alayrac, Jiahui Yu, Radu Soricut, Johan Schalkwyk, Andrew M Dai, Anja Hauth, Katie Millican, et al. Gemini: a family of highly capable multimodal models. arXiv preprint arXiv:2312.11805, 2023. 4, 5, 6, 9
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[61]
Qwen2.5-llm: Extending the boundary of llms,
Qwen Team. Qwen2.5-llm: Extending the boundary of llms,
-
[62]
LLaMA: Open and Efficient Foundation Language Models
Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timoth´ee Lacroix, Baptiste Rozi`ere, Naman Goyal, Eric Hambro, Faisal Azhar, et al. Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971, 2023. 3
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[63]
Examining the potential and pitfalls of chatgpt in science and engineering problem-solving
Karen D Wang, Eric Burkholder, Carl Wieman, Shima Salehi, and Nick Haber. Examining the potential and pitfalls of chatgpt in science and engineering problem-solving. In Frontiers in Education, page 1330486. Frontiers Media SA,
-
[64]
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution
Peng Wang, Shuai Bai, Sinan Tan, Shijie Wang, Zhihao Fan, Jinze Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, et al. Qwen2-vl: Enhancing vision-language model’s perception of the world at any resolution. arXiv preprint arXiv:2409.12191, 2024. 4, 5, 6, 9
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[65]
Yiqi Wang, Wentao Chen, Xiaotian Han, Xudong Lin, Hait- eng Zhao, Yongfei Liu, Bohan Zhai, Jianbo Yuan, Quanzeng You, and Hongxia Yang. Exploring the reasoning abilities of multimodal large language models (mllms): A compre- hensive survey on emerging trends in multimodal reasoning. arXiv preprint arXiv:2401.06805, 2024. 3
-
[66]
Generative ai for math: Part i–mathpile: A billion-token-scale pretraining cor- pus for math
Zengzhi Wang, Rui Xia, and Pengfei Liu. Generative ai for math: Part i–mathpile: A billion-token-scale pretraining cor- pus for math. arXiv preprint arXiv:2312.17120, 2023. 4
-
[67]
Chain-of-thought prompting elicits reasoning in large lan- guage models
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al. Chain-of-thought prompting elicits reasoning in large lan- guage models. Advances in neural information processing systems, 35:24824–24837, 2022. 3, 5, 7
work page 2022
-
[68]
Chain-of- though (cot) prompting strategies for medical error detection and correction
Zhaolong Wu, Abul Hasan, Jinge Wu, Yunsoo Kim, Ja- son PY Cheung, Teng Zhang, and Honghan Wu. Chain-of- though (cot) prompting strategies for medical error detection and correction. arXiv preprint arXiv:2406.09103, 2024. 3
-
[69]
LLaVA-CoT: Let Vision Language Models Reason Step-by-Step
Guowei Xu, Peng Jin, Li Hao, Yibing Song, Lichao Sun, and Li Yuan. Llava-o1: Let vision language models reason step- by-step. arXiv preprint arXiv:2411.10440, 2024. 12
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[70]
Model Merging in LLMs, MLLMs, and Beyond: Methods, Theories, Applications and Opportunities
Enneng Yang, Li Shen, Guibing Guo, Xingwei Wang, Xi- aochun Cao, Jie Zhang, and Dacheng Tao. Model merging in llms, mllms, and beyond: Methods, theories, applications and opportunities. arXiv preprint arXiv:2408.07666, 2024. 3
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[71]
Mathglm-vision: Solving mathematical problems with multi-modal large language model
Zhen Yang, Jinhao Chen, Zhengxiao Du, Wenmeng Yu, Wei- han Wang, Wenyi Hong, Zhihuan Jiang, Bin Xu, Yuxiao Dong, and Jie Tang. Mathglm-vision: Solving mathemati- cal problems with multi-modal large language model. arXiv preprint arXiv:2409.13729, 2024. 3
-
[72]
Gokul Yenduri, M Ramalingam, G Chemmalar Selvi, Y Supriya, Gautam Srivastava, Praveen Kumar Reddy Mad- dikunta, G Deepti Raj, Rutvij H Jhaveri, B Prabadevi, Weizheng Wang, et al. Gpt (generative pre-trained transformer)–a comprehensive review on enabling technolo- gies, potential applications, emerging challenges, and future directions. IEEE Access, 2024. 3
work page 2024
-
[73]
Lamm: Language-assisted multi-modal instruction-tuning dataset, framework, and benchmark
Zhenfei Yin, Jiong Wang, Jianjian Cao, Zhelun Shi, Dingn- ing Liu, Mukai Li, Xiaoshui Huang, Zhiyong Wang, Lu Sheng, Lei Bai, et al. Lamm: Language-assisted multi-modal instruction-tuning dataset, framework, and benchmark. Ad- vances in Neural Information Processing Systems, 36, 2024. 3
work page 2024
-
[74]
MAmmoTH: Building Math Generalist Models through Hybrid Instruction Tuning
Xiang Yue, Xingwei Qu, Ge Zhang, Yao Fu, Wenhao Huang, Huan Sun, Yu Su, and Wenhu Chen. Mammoth: Building math generalist models through hybrid instruction tuning. arXiv preprint arXiv:2309.05653, 2023. 4
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[75]
Mario eval: Evalu- ate your math llm with your math llm–a mathematical dataset evaluation toolkit
Boning Zhang, Chengxi Li, and Kai Fan. Mario eval: Evalu- ate your math llm with your math llm–a mathematical dataset evaluation toolkit. arXiv preprint arXiv:2404.13925, 2024. 3
-
[76]
Llama-berry: Pairwise optimization for o1-like olympiad-level mathematical reasoning
Di Zhang, Jianbo Wu, Jingdi Lei, Tong Che, Jiatong Li, Tong Xie, Xiaoshui Huang, Shufei Zhang, Marco Pavone, Yuqiang Li, et al. Llama-berry: Pairwise optimization for o1- like olympiad-level mathematical reasoning. arXiv preprint arXiv:2410.02884, 2024. 12
-
[77]
Mm-llms: Recent ad- vances in multimodal large language models
Duzhen Zhang, Yahan Yu, Jiahua Dong, Chenxing Li, Dan Su, Chenhui Chu, and Dong Yu. Mm-llms: Recent ad- vances in multimodal large language models. arXiv preprint arXiv:2401.13601, 2024. 3
-
[78]
LLaMA-Adapter: Efficient Fine-tuning of Language Models with Zero-init Attention
Renrui Zhang, Jiaming Han, Chris Liu, Peng Gao, Ao- jun Zhou, Xiangfei Hu, Shilin Yan, Pan Lu, Hongsheng Li, and Yu Qiao. Llama-adapter: Efficient fine-tuning of language models with zero-init attention. arXiv preprint arXiv:2303.16199, 2023. 3
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[79]
MathVerse: Does Your Multi-modal LLM Truly See the Diagrams in Visual Math Problems?
Renrui Zhang, Dongzhi Jiang, Yichi Zhang, Haokun Lin, Ziyu Guo, Pengshuo Qiu, Aojun Zhou, Pan Lu, Kai-Wei Chang, Peng Gao, et al. Mathverse: Does your multi-modal llm truly see the diagrams in visual math problems? arXiv preprint arXiv:2403.14624, 2024. 1, 2, 3, 7, 4
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[80]
Mavis: Mathematical visual in- struction tuning
Renrui Zhang, Xinyu Wei, Dongzhi Jiang, Yichi Zhang, Ziyu Guo, Chengzhuo Tong, Jiaming Liu, Aojun Zhou, Bin Wei, Shanghang Zhang, et al. Mavis: Mathematical visual in- struction tuning. arXiv preprint arXiv:2407.08739, 2024. 3, 5, 6
-
[81]
Is your model really a good math rea- soner? evaluating mathematical reasoning with checklist
Zihao Zhou, Shudong Liu, Maizhen Ning, Wei Liu, Jin- dong Wang, Derek F Wong, Xiaowei Huang, Qiufeng Wang, and Kaizhu Huang. Is your model really a good math rea- soner? evaluating mathematical reasoning with checklist. arXiv preprint arXiv:2407.08733, 2024. 2
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.