SLAM&Render: A Benchmark for the Intersection Between Neural Rendering, Gaussian Splatting and SLAM
Pith reviewed 2026-05-22 18:55 UTC · model grok-4.3
The pith
SLAM&Render supplies robot-recorded multi-modal sequences to test combined SLAM and neural rendering methods under controlled variations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
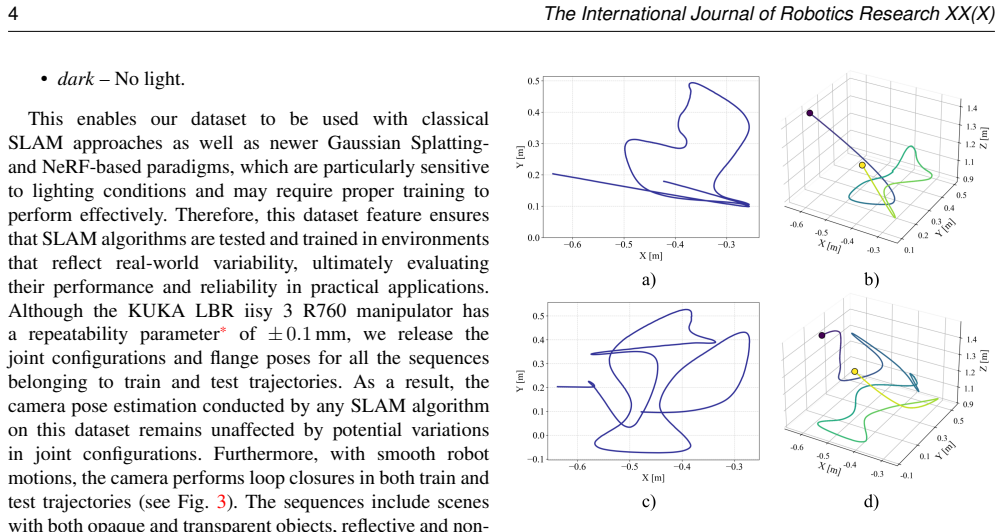
Existing datasets for SLAM and novel view synthesis lack sequential processing, multi-modality, controlled generalization tests across viewpoints and lighting, and exact sensor motion reproduction, so SLAM&Render records 40 sequences with a robot manipulator across five setups of consumer and industrial objects under four lighting conditions, each with separate training and test trajectories in static scenes that include different levels of rearrangements and occlusions, plus time-synchronized RGB-D, IMU, kinematic, and ground-truth pose data.
What carries the argument
Robot kinematic data streams that enable exact reproduction of sensor trajectories and direct assessment of SLAM methods inside robotic control loops.
If this is right
- SLAM methods can be evaluated for sequential mapping performance using the time-synchronized streams.
- Neural rendering and Gaussian Splatting techniques can be measured for robustness to lighting and viewpoint changes with separate test trajectories.
- Integrations of SLAM into robotic systems become testable through the released kinematic data.
- Occlusion and rearrangement effects on reconstruction quality can be isolated across the four lighting conditions.
Where Pith is reading between the lines
- The kinematic data could support closed-loop simulation of robot paths to test how well rendering affects localization feedback.
- Industrial objects in the setups open direct comparisons between consumer-grade and factory-grade scene reconstruction under the same motion paths.
- Future work could add slight scene motion to the static sequences to check whether the benchmark still ranks methods consistently.
Load-bearing premise
Laboratory setups with controlled lighting, static scenes, consumer and industrial objects, and robot-recorded trajectories capture the main real-world difficulties that SLAM and neural rendering methods must overcome.
What would settle it
If standard SLAM and Gaussian Splatting baselines achieve similar generalization and accuracy scores on SLAM&Render as on existing handheld datasets, the new benchmark would not have introduced meaningfully harder or more representative conditions.
Figures





read the original abstract
Models and methods originally developed for Novel View Synthesis and Scene Rendering, such as Neural Radiance Fields (NeRF) and Gaussian Splatting, are increasingly being adopted as representations in Simultaneous Localization and Mapping (SLAM). However, existing datasets fail to include the specific challenges of both fields, such as sequential operations and, in many settings, multi-modality in SLAM or generalization across viewpoints and illumination conditions in neural rendering. Additionally, the data are often collected using sensors which are handheld or mounted on drones or mobile robots, which complicates the accurate reproduction of sensor motions. To bridge these gaps, we introduce SLAM&Render, a novel dataset designed to benchmark methods in the intersection between SLAM, Novel View Rendering and Gaussian Splatting. Recorded with a robot manipulator, it uniquely includes 40 sequences with time-synchronized RGB-D images, IMU readings, robot kinematic data, and ground-truth pose streams. By releasing robot kinematic data, the dataset also enables the assessment of recent integrations of SLAM paradigms within robotic applications. The dataset features five setups with consumer and industrial objects under four controlled lighting conditions, each with separate training and test trajectories. All sequences are static with different levels of object rearrangements and occlusions. Our experimental results, obtained with several baselines from the literature, validate SLAM&Render as a relevant benchmark for this emerging research area.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces SLAM&Render, a benchmark dataset for methods at the intersection of SLAM, novel view synthesis, and Gaussian Splatting. It comprises 40 sequences recorded with a robot manipulator, providing time-synchronized RGB-D images, IMU readings, robot kinematic data, and ground-truth poses. The data cover five setups with consumer and industrial objects under four controlled lighting conditions, static scenes with object rearrangements and occlusions, and separate training/test trajectories to evaluate sequential/multi-modal SLAM and viewpoint/illumination generalization.
Significance. If the dataset design and baseline results hold, this work would provide a useful controlled benchmark for integrated SLAM and neural rendering pipelines, with particular value in the release of robot kinematic data for accurate motion reproduction and assessment in robotic contexts. The multi-modal synchronization and structured variations in lighting and scene configuration are explicit strengths that could support systematic evaluation where prior datasets fall short.
major comments (2)
- [Dataset] Dataset section: the central claim that the dataset bridges gaps by enabling assessment of generalization across viewpoints and illumination conditions rests on five setups and four discrete lighting conditions with static scenes; however, the absence of continuous illumination variation, dynamic elements, or unstructured environments means the chosen conditions may not expose the failure modes that dominate practical SLAM and rendering deployments, weakening the generalization argument.
- [Experiments] Experiments section: while the abstract states that baselines validate the benchmark's relevance, the manuscript provides insufficient detail on quantitative metrics, error analysis, or how baselines were adapted to incorporate the robot kinematic data and multi-modal inputs; this leaves the utility claim only partially supported and requires explicit results to be load-bearing.
minor comments (2)
- [Abstract] Abstract: the validation statement would be strengthened by briefly noting one or two key quantitative outcomes from the baselines rather than a general reference.
- [Related Work] Related work: add a table comparing SLAM&Render to prior datasets on dimensions such as kinematic data availability, lighting variation, and multi-modality to clarify the claimed gaps.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback on our manuscript. We address each major comment below and indicate the revisions we will incorporate to strengthen the presentation of the benchmark and its evaluation.
read point-by-point responses
-
Referee: [Dataset] Dataset section: the central claim that the dataset bridges gaps by enabling assessment of generalization across viewpoints and illumination conditions rests on five setups and four discrete lighting conditions with static scenes; however, the absence of continuous illumination variation, dynamic elements, or unstructured environments means the chosen conditions may not expose the failure modes that dominate practical SLAM and rendering deployments, weakening the generalization argument.
Authors: We appreciate this observation on the scope of our controlled variations. SLAM&Render is intentionally designed around static scenes with discrete lighting conditions, object rearrangements, and occlusions to enable systematic, reproducible testing of viewpoint and illumination generalization using precise robot kinematic ground truth. This structured approach fills a specific gap left by prior datasets that lack synchronized multi-modal data and controlled factors. We agree that the manuscript should more explicitly delineate the intended scope of these generalization tests. In the revision we will update the Dataset and Introduction sections to clarify the design rationale and add a limitations paragraph discussing the absence of continuous illumination changes, dynamic elements, and fully unstructured environments. revision: yes
-
Referee: [Experiments] Experiments section: while the abstract states that baselines validate the benchmark's relevance, the manuscript provides insufficient detail on quantitative metrics, error analysis, or how baselines were adapted to incorporate the robot kinematic data and multi-modal inputs; this leaves the utility claim only partially supported and requires explicit results to be load-bearing.
Authors: We agree that additional detail is required to make the experimental validation fully load-bearing. The manuscript reports results from several literature baselines, yet we acknowledge the need for greater transparency. In the revised version we will expand the Experiments section with explicit quantitative metrics (including ATE/RPE for SLAM trajectories and PSNR/SSIM/LPIPS for rendering), a breakdown of error sources, and step-by-step descriptions of how the robot kinematic data was used for motion reproduction and how multi-modal (RGB-D + IMU) inputs were integrated into each baseline. These additions will directly support the utility claim. revision: yes
Circularity Check
No circularity: dataset paper relies on physical collection and external baselines
full rationale
The paper introduces SLAM&Render as a benchmark dataset collected with a robot manipulator, featuring 40 sequences of time-synchronized RGB-D, IMU, kinematic, and ground-truth pose data across five setups, four lighting conditions, and varying object rearrangements/occlusions. Its central claims concern the dataset's coverage of sequential/multi-modal SLAM challenges and viewpoint/illumination generalization for neural rendering, achieved directly via hardware recording and release of robot kinematics rather than any derivation, prediction, or first-principles result. No equations, fitted parameters, or self-referential definitions appear in the provided text. Validation consists of running literature baselines on the new data, which constitutes external testing rather than circular reduction. The contribution is therefore self-contained against external benchmarks with no load-bearing steps that collapse to inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Static scenes with controlled rearrangements and occlusions adequately test generalization for SLAM and rendering methods
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
we introduce SLAM&Render, a novel dataset designed to benchmark methods in the intersection between SLAM, Novel View Rendering and Gaussian Splatting
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Bonarini A, Burgard W, Fontana G, Matteucci M, Sorrenti DG, Tardos JD et al
Barron JT, Mildenhall B, Verbin D, Srinivasan PP and Hedman P (2022) Mip-nerf 360: Unbounded anti-aliased neural radiance fields.CVPR. Bonarini A, Burgard W, Fontana G, Matteucci M, Sorrenti DG, Tardos JD et al. (2006) Rawseeds: Robotics advancement through web-publishing of sensorial and elaborated extensive data sets. In:In proceedings of IROS, volume
work page 2022
-
[2]
Burri M, Nikolic J, Gohl P, Schneider T, Rehder J, Omari S, Achtelik MW and Siegwart R (2016) The euroc micro aerial vehicle datasets.The International Journal of Robotics Research35(10): 1157–1163. Cadena C, Carlone L, Carrillo H, Latif Y , Scaramuzza D, Neira J, Reid I and Leonard JJ (2016) Past, present, and future of simultaneous localization and mapp...
work page 2016
-
[3]
In:2015 international conference on advanced robotics (ICAR)
Calli B, Singh A, Walsman A, Srinivasa S, Abbeel P and Dollar AM (2015) The ycb object and model set: Towards common benchmarks for manipulation research. In:2015 international conference on advanced robotics (ICAR). IEEE, pp. 510–517. Campos C, Elvira R, Rodr ´ıguez JJG, Montiel JM and Tard ´os JD (2021) Orb-slam3: An accurate open-source library for vis...
work page 2015
-
[4]
In:Proceedings of the IEEE conference on computer vision and pattern recognition
Jensen R, Dahl A, V ogiatzis G, Tola E and Aanæs H (2014) Large scale multi-view stereopsis evaluation. In:Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 406–413. Keetha N, Karhade J, Jatavallabhula KM, Yang G, Scherer S, Ramanan D and Luiten J (2024) Splatam: Splat track & map 3d gaussians for dense rgb-d slam. In:Proc...
work page 2014
-
[5]
Macario Barros A, Michel M, Moline Y , Corre G and Carrel F (2022) A comprehensive survey of visual slam algorithms. Robotics11(1):
work page 2022
-
[6]
In:Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Martin-Brualla R, Radwan N, Sajjadi MS, Barron JT, Dosovitskiy A and Duckworth D (2021) Nerf in the wild: Neural radiance fields for unconstrained photo collections. In:Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 7210–7219. Martins TB and Civera J (2024) Feature splatting for better novel view synthesis with low ...
work page 2021
-
[7]
The Replica Dataset: A Digital Replica of Indoor Spaces
Matsuki H, Murai R, Kelly PH and Davison AJ (2024) Gaussian splatting slam. In:Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 18039– 18048. Mildenhall B, Srinivasan PP, Tancik M, Barron JT, Ramamoorthi R and Ng R (2021) Nerf: Representing scenes as neural radiance fields for view synthesis.Communications of the ACM6...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[8]
pp. 16558–16569. Tosi F, Zhang Y , Gong Z, Sandstr¨om E, Mattoccia S, Oswald MR and Poggi M (2024) How nerfs and 3d gaussian splatting are reshaping slam: a survey.arXiv preprint arXiv:2402.132554:
-
[9]
Wang Z, Bovik A, Sheikh H and Simoncelli E (2004) Image quality assessment: from error visibility to structural similarity.IEEE Transactions on Image Processing13(4): 600–612. DOI: 10.1109/TIP.2003.819861. Ye S, Dong ZH, Hu Y , Wen YH and Liu YJ (2024) Gaussian in the dark: Real-time view synthesis from inconsistent dark images using gaussian splatting. I...
-
[10]
Wiley Online Library, p. e15213. Yeshwanth C, Liu YC, Nießner M and Dai A (2023) Scannet++: A high-fidelity dataset of 3d indoor scenes. In:Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 12–22. Zhang J and Singh S (2014) Loam: Lidar odometry and mapping in real-time. In:Robotics: Science and Systems (RSS). p
work page 2023
-
[11]
In:Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR)
Zhang R, Isola P, Efros AA, Shechtman E and Wang O (2018) The unreasonable effectiveness of deep features as a perceptual metric. In:Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR). p
work page 2018
-
[12]
In:Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Zhu Z, Peng S, Larsson V , Xu W, Bao H, Cui Z, Oswald MR and Pollefeys M (2022) Nice-slam: Neural implicit scalable encoding for slam. In:Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 12786–12796. Prepared usingsagej.cls
work page 2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.