Decentralized Nonconvex Optimization under Heavy-Tailed Noise: Normalization and Optimal Convergence
Pith reviewed 2026-05-22 15:44 UTC · model grok-4.3
The pith
GT-NSGDm achieves the optimal non-asymptotic convergence rate O(1/T^{(p-1)/(3p-2)}) for decentralized nonconvex stochastic optimization under heavy-tailed noise.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The authors prove that GT-NSGDm guarantees, for the first time, that the expected gradient norm converges at the optimal non-asymptotic rate O(1/T^{(p-1)/(3p-2)}), matching the centralized lower bound, for zero-mean heavy-tailed noise with p-th moment where p is in (1,2].
What carries the argument
GT-NSGDm or Gradient Tracking based Normalized Stochastic Gradient Descent with momentum, which normalizes updates to mitigate heavy tails while using tracking and momentum in a decentralized graph.
Load-bearing premise
The communication graph admits primitive and doubly stochastic weights.
What would settle it
An experiment on a small decentralized network with simulated heavy-tailed gradients where the observed convergence of the gradient norm is slower than the claimed rate.
Figures

read the original abstract
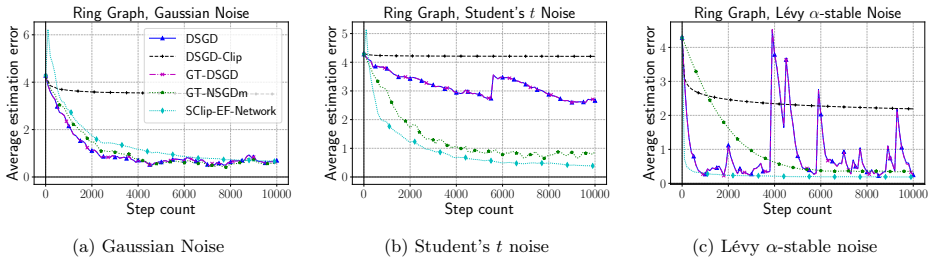
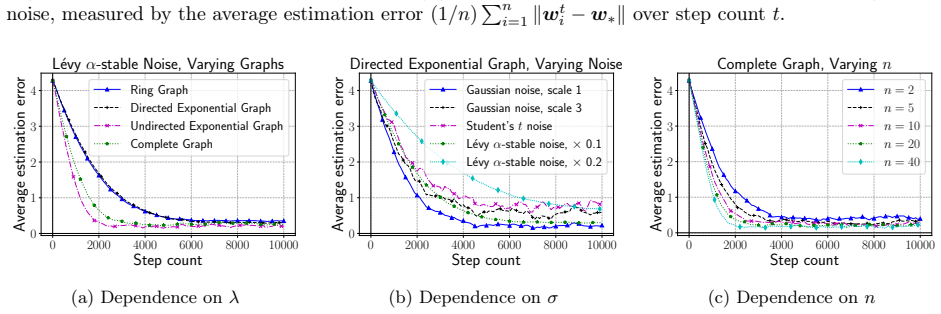
Heavy-tailed noise in nonconvex stochastic optimization has garnered increasing research interest, as empirical studies, including those on training attention models, suggest it is a more realistic gradient noise condition. This paper studies first-order nonconvex stochastic optimization under heavy-tailed gradient noise in a decentralized setup, where each node can only communicate with its direct neighbors in a predefined graph. Specifically, we consider a class of heavy-tailed gradient noise that is zero-mean and has only $p$-th moment for $p \in (1, 2]$. We propose GT-NSGDm, Gradient Tracking based Normalized Stochastic Gradient Descent with momentum, that utilizes normalization, in conjunction with gradient tracking and momentum, to cope with heavy-tailed noise on distributed nodes. We show that, when the communication graph admits primitive and doubly stochastic weights, GT-NSGDm guarantees, for the \textit{first} time in the literature, that the expected gradient norm converges at an optimal non-asymptotic rate $O\big(1/T^{(p-1)/(3p-2)}\big)$, which matches the lower bound in the centralized setup. When tail index $p$ is unknown, GT-NSGDm attains a non-asymptotic rate $O\big( 1/T^{(p-1)/(2p)} \big)$ that is, for $p < 2$, topology independent and has a speedup factor $n^{1-1/p}$ in terms of the number of nodes $n$. Finally, experiments on nonconvex linear regression with tokenized synthetic data and decentralized training of language models on a real-world corpus demonstrate that GT-NSGDm is more robust and efficient than baselines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes GT-NSGDm, a gradient-tracking normalized stochastic gradient descent algorithm with momentum, for decentralized nonconvex optimization where each node observes stochastic gradients with only p-th moment (1 < p ≤ 2) under heavy-tailed noise. Under the assumption that the communication graph admits primitive and doubly stochastic weights, the authors prove that the expected gradient norm converges at the non-asymptotic rate O(1/T^{(p-1)/(3p-2)}), claimed to be optimal and matching the centralized lower bound for the first time. When p is unknown the method attains O(1/T^{(p-1)/(2p)}), which is topology-independent for p < 2 and enjoys an n^{1-1/p} speedup. The claims rest on a convergence analysis in Section 4 together with experiments on nonconvex linear regression and decentralized language-model training.
Significance. If the stated rate holds, the result is significant: it supplies the first optimal non-asymptotic guarantee for decentralized heavy-tailed nonconvex optimization and shows that the centralized exponent (p-1)/(3p-2) can be recovered without degradation from the mixing term. The analysis credits gradient tracking (Lemma 3.3) for geometrically contracting the consensus error so that it is absorbed into lower-order contributions, preserving the leading T-exponent. This is a concrete advance over prior decentralized heavy-tailed work that typically incurred worse exponents or topology dependence.
major comments (1)
- [Section 4] §4, the main recursion after Lemma 3.3: the proof sketch states that the mixing term is absorbed into lower-order contributions without altering the leading exponent, yet the explicit dependence of the O(·) constants on the graph’s second-largest eigenvalue (or mixing time) is not displayed; this dependence must be verified to ensure the claimed exponent remains independent of the fixed graph for any n.
minor comments (3)
- [Abstract and Section 5] Abstract and §5: the experimental section reports robustness on tokenized synthetic data and real-world corpora but does not specify how error bars are computed or which data points are excluded; adding these details would strengthen reproducibility.
- [Algorithm 1] Algorithm 1 and surrounding text: the precise normalization step (division by the estimated p-norm or a surrogate) is described verbally; an explicit equation would remove ambiguity in implementation.
- [Introduction] Introduction: a short table comparing the new rate to the best prior decentralized heavy-tailed rates (with and without momentum) would help readers immediately see the improvement in the exponent.
Simulated Author's Rebuttal
We thank the referee for the positive assessment and for highlighting the potential significance of recovering the centralized optimal rate in the decentralized setting. We address the major comment below.
read point-by-point responses
-
Referee: [Section 4] §4, the main recursion after Lemma 3.3: the proof sketch states that the mixing term is absorbed into lower-order contributions without altering the leading exponent, yet the explicit dependence of the O(·) constants on the graph’s second-largest eigenvalue (or mixing time) is not displayed; this dependence must be verified to ensure the claimed exponent remains independent of the fixed graph for any n.
Authors: We agree that explicitly displaying the dependence on the graph mixing properties would improve clarity. In the detailed proof (Appendix), Lemma 3.3 shows that gradient tracking yields a geometric contraction of the consensus error with rate ρ < 1, where ρ is determined by the second-largest eigenvalue of the doubly stochastic weight matrix. This factor enters the constants in the O(·) bound (specifically through terms of the form 1/(1-ρ) multiplying lower-order contributions), but because the contraction is geometric it is absorbed into the o(1/T^α) remainder and does not change the leading exponent α = (p-1)/(3p-2). For any fixed primitive doubly stochastic graph the value of ρ is a constant independent of T, so the T-exponent remains unchanged. When the number of nodes n varies, ρ may depend on n through the graph topology, but the exponent itself stays the same under the stated assumptions; only the hidden constants are affected. We will revise the manuscript to state this dependence explicitly in the main theorem and in the proof sketch of Section 4. revision: yes
Circularity Check
No significant circularity; derivation is self-contained
full rationale
The central convergence rate O(1/T^{(p-1)/(3p-2)}) is obtained in Section 4 by combining a gradient-tracking consensus lemma with a normalized momentum recursion that absorbs the mixing term into lower-order contributions. The exponent arises from standard heavy-tail moment bounds and step-size tuning under the stated p-moment assumption; it is not obtained by fitting to data, self-definition, or reduction to a prior self-citation. The primitive doubly-stochastic graph condition supplies only a uniform contraction factor <1 and does not appear in the leading T-exponent. The analysis is therefore independent of the target result and receives the default non-circularity finding.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Communication graph admits primitive and doubly stochastic weights.
- domain assumption Gradient noise is zero-mean with finite p-th moment for p in (1,2].
Forward citations
Cited by 2 Pith papers
-
High-Probability Convergence Guarantees of Decentralized SGD
Decentralized SGD achieves high-probability convergence with order-optimal rates and linear speedup under standard cost assumptions matching those for MSE convergence.
-
High-Probability Convergence Guarantees of Decentralized SGD
Decentralized SGD achieves high-probability convergence with order-optimal rates and linear speedup in the number of users under standard smoothness and convexity conditions on the cost function.
Reference graph
Works this paper leans on
-
[1]
Distributed asynchronous deterministic and stochastic gradient optimization algorithms,
J. Tsitsiklis, D. Bertsekas, and M. Athans, “Distributed asynchronous deterministic and stochastic gradient optimization algorithms,”IEEE transactions on automatic control, vol. 31, no. 9, pp. 803–812, 1986
work page 1986
-
[2]
Network topology and communication-computation tradeoffs in decentralized optimization,
A. Nedić, A. Olshevsky, and M. G. Rabbat, “Network topology and communication-computation tradeoffs in decentralized optimization,”Proceedings of the IEEE, vol. 106, no. 5, pp. 953–976, 2018
work page 2018
-
[3]
Federated learning: Challenges, methods, and future directions,
T. Li, A. K. Sahu, A. Talwalkar, and V. Smith, “Federated learning: Challenges, methods, and future directions,”IEEE signal processing magazine, vol. 37, no. 3, pp. 50–60, 2020
work page 2020
-
[4]
Advances and open problems in federated learning,
P. Kairouz, H. B. McMahan, B. Avent, A. Bellet, M. Bennis, A. N. Bhagoji, K. Bonawitz, Z. Charles, G. Cormode, R. Cummings,et al., “Advances and open problems in federated learning,”Foundations and Trends® in Machine Learning, vol. 14, no. 1–2, pp. 1–210, 2021. 11
work page 2021
-
[5]
Federated learning of predictive models from federated electronic health records,
T. S. Brisimi, R. Chen, T. Mela, A. Olshevsky, I. C. Paschalidis, and W. Shi, “Federated learning of predictive models from federated electronic health records,”International journal of medical informatics, vol. 112, pp. 59–67, 2018
work page 2018
-
[6]
X. Lian, C. Zhang, H. Zhang, C.-J. Hsieh, W. Zhang, and J. Liu, “Can decentralized algorithms outperform centralized algorithms? a case study for decentralized parallel stochastic gradient descent,” Advances in neural information processing systems, vol. 30, 2017
work page 2017
-
[7]
A general framework for decentralized optimization with first-order methods,
R. Xin, S. Pu, A. Nedić, and U. A. Khan, “A general framework for decentralized optimization with first-order methods,”Proceedings of the IEEE, vol. 108, no. 11, pp. 1869–1889, 2020
work page 2020
-
[8]
Distributed stochastic subgradient projection algorithms for convex optimization,
S. Sundhar Ram, A. Nedić, and V. V. Veeravalli, “Distributed stochastic subgradient projection algorithms for convex optimization,”Journal of optimization theory and applications, vol. 147, pp. 516–545, 2010
work page 2010
-
[9]
A unified theory of decentralized sgd with changing topology and local updates,
A. Koloskova, N. Loizou, S. Boreiri, M. Jaggi, and S. Stich, “A unified theory of decentralized sgd with changing topology and local updates,” inInternational Conference on Machine Learning, pp. 5381–5393, PMLR, 2020
work page 2020
-
[10]
Cooperative sgd: A unified framework for the design and analysis of local-update sgd algorithms,
J. Wang and G. Joshi, “Cooperative sgd: A unified framework for the design and analysis of local-update sgd algorithms,”Journal of Machine Learning Research, vol. 22, no. 213, pp. 1–50, 2021
work page 2021
-
[11]
Variance-reduced stochastic learning by networked agents under random reshuffling,
K. Yuan, B. Ying, J. Liu, and A. H. Sayed, “Variance-reduced stochastic learning by networked agents under random reshuffling,”IEEE Transactions on Signal Processing, vol. 67, no. 2, pp. 351–366, 2018
work page 2018
-
[12]
Next: In-network nonconvex optimization,
P. Di Lorenzo and G. Scutari, “Next: In-network nonconvex optimization,”IEEE Transactions on Signal and Information Processing over Networks, vol. 2, no. 2, pp. 120–136, 2016
work page 2016
-
[13]
Distributed stochastic gradient tracking methods,
S. Pu and A. Nedić, “Distributed stochastic gradient tracking methods,”Mathematical Programming, vol. 187, no. 1, pp. 409–457, 2021
work page 2021
-
[14]
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin, “Attention is all you need,”Advances in neural information processing systems, vol. 30, 2017
work page 2017
-
[15]
J. Nair, A. Wierman, and B. Zwart,The fundamentals of heavy tails: Properties, emergence, and estimation, vol. 53. Cambridge University Press, 2022
work page 2022
-
[16]
A tail-index analysis of stochastic gradient noise in deep neural networks,
U. Simsekli, L. Sagun, and M. Gurbuzbalaban, “A tail-index analysis of stochastic gradient noise in deep neural networks,” inInternational Conference on Machine Learning, pp. 5827–5837, PMLR, 2019
work page 2019
-
[17]
Why are adaptive methods good for attention models?,
J. Zhang, S. P. Karimireddy, A. Veit, S. Kim, S. Reddi, S. Kumar, and S. Sra, “Why are adaptive methods good for attention models?,”Advances in Neural Information Processing Systems, vol. 33, pp. 15383–15393, 2020
work page 2020
-
[18]
Stochastic optimization with heavy-tailed noise via accelerated gradient clipping,
E. Gorbunov, M. Danilova, and A. Gasnikov, “Stochastic optimization with heavy-tailed noise via accelerated gradient clipping,”Advances in Neural Information Processing Systems, vol. 33, pp. 15042– 15053, 2020
work page 2020
-
[19]
The heavy-tail phenomenon in sgd,
M. Gurbuzbalaban, U. Simsekli, and L. Zhu, “The heavy-tail phenomenon in sgd,” inInternational Conference on Machine Learning, pp. 3964–3975, PMLR, 2021
work page 2021
-
[20]
Linear attention is (maybe) all you need (to understand transformer optimization),
K. Ahn, X. Cheng, M. Song, C. Yun, A. Jadbabaie, and S. Sra, “Linear attention is (maybe) all you need (to understand transformer optimization),” inThe Twelfth International Conference on Learning Representations, 2024. 12
work page 2024
-
[21]
Heavy-tailed class imbalance and why adam outperforms gradient descent on language models,
F. Kunstner, A. Milligan, R. Yadav, M. Schmidt, and A. Bietti, “Heavy-tailed class imbalance and why adam outperforms gradient descent on language models,”Advances in Neural Information Processing Systems, vol. 37, pp. 30106–30148, 2024
work page 2024
-
[22]
On large-cohort training for federated learning,
Z. Charles, Z. Garrett, Z. Huo, S. Shmulyian, and V. Smith, “On large-cohort training for federated learning,”Advances in neural information processing systems, vol. 34, pp. 20461–20475, 2021
work page 2021
-
[23]
Taming fat-tailed (“heavier-tailed
H. Yang, P. Qiu, and J. Liu, “Taming fat-tailed (“heavier-tailed” with potentially infinite variance) noise in federated learning,”Advances in Neural Information Processing Systems, vol. 35, pp. 17017–17029, 2022
work page 2022
-
[24]
A. Sadiev, M. Danilova, E. Gorbunov, S. Horváth, G. Gidel, P. Dvurechensky, A. Gasnikov, and P. Richtárik, “High-probability bounds for stochastic optimization and variational inequalities: the case of unbounded variance,” inInternational Conference on Machine Learning, pp. 29563–29648, PMLR, 2023
work page 2023
-
[25]
Adaptive methods through the lens of SDEs: Theoretical insights on the role of noise,
E. M. Compagnoni, T. Liu, R. Islamov, F. N. Proske, A. Orvieto, and A. Lucchi, “Adaptive methods through the lens of SDEs: Theoretical insights on the role of noise,” inThe Thirteenth International Conference on Learning Representations, 2025
work page 2025
-
[26]
From gradient clipping to normalization for heavy tailed sgd,
F. Hübler, I. Fatkhullin, and N. He, “From gradient clipping to normalization for heavy tailed sgd,”arXiv preprint arXiv:2410.13849, 2024
-
[27]
Z. Liu and Z. Zhou, “Nonconvex stochastic optimization under heavy-tailed noises: Optimal convergence without gradient clipping,” inThe Thirteenth International Conference on Learning Representations, 2025
work page 2025
-
[28]
A. Armacki, S. Yu, P. Sharma, G. Joshi, D. Bajovic, D. Jakovetic, and S. Kar, “High-probability convergence bounds for online nonlinear stochastic gradient descent under heavy-tailed noise,” inThe 28th International Conference on Artificial Intelligence and Statistics, 2025
work page 2025
-
[29]
Distributed stochastic strongly convex optimization under heavy-tailed noises,
C. Sun and B. Chen, “Distributed stochastic strongly convex optimization under heavy-tailed noises,” in 2024 IEEE International Conference on Cybernetics and Intelligent Systems (CIS) and IEEE Interna- tional Conference on Robotics, Automation and Mechatronics (RAM), pp. 150–155, IEEE, 2024
work page 2024
-
[30]
S. Yu, D. Jakovetic, and S. Kar, “Smoothed gradient clipping and error feedback for decentralized optimization under symmetric heavy-tailed noise,”arXiv preprint arXiv:2310.16920, 2023
-
[31]
Multi30K: Multilingual English-German Image Descriptions
D. Elliott, S. Frank, K. Sima’an, and L. Specia, “Multi30k: Multilingual english-german image descrip- tions,”arXiv preprint arXiv:1605.00459, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[32]
Heavy tails in sgd and compressibility of overparametrized neural networks,
M. Barsbey, M. Sefidgaran, M. A. Erdogdu, G. Richard, and U. Simsekli, “Heavy tails in sgd and compressibility of overparametrized neural networks,”Advances in neural information processing systems, vol. 34, pp. 29364–29378, 2021
work page 2021
-
[33]
Revisiting the noise model of stochastic gradient descent,
B. Battash, L. Wolf, and O. Lindenbaum, “Revisiting the noise model of stochastic gradient descent,” in International Conference on Artificial Intelligence and Statistics, pp. 4780–4788, PMLR, 2024
work page 2024
-
[34]
Stable behaviour of infinitely wide deep neural networks,
S. Peluchetti, S. Favaro, and S. Fortini, “Stable behaviour of infinitely wide deep neural networks,” in International Conference on Artificial Intelligence and Statistics, pp. 1137–1146, PMLR, 2020
work page 2020
-
[35]
Efficient distributed optimization under heavy-tailed noise,
S. H. Lee, M. Zaheer, and T. Li, “Efficient distributed optimization under heavy-tailed noise,”arXiv preprint arXiv:2502.04164, 2025. 13
-
[36]
Z. Liu, J. Zhang, and Z. Zhou, “Breaking the lower bound with (little) structure: Acceleration in non-convex stochastic optimization with heavy-tailed noise,” inThe Thirty Sixth Annual Conference on Learning Theory, pp. 2266–2290, PMLR, 2023
work page 2023
-
[37]
Improved convergence in high probability of clipped gradient methods with heavy tailed noise,
T. D. Nguyen, T. H. Nguyen, A. Ene, and H. Nguyen, “Improved convergence in high probability of clipped gradient methods with heavy tailed noise,”Advances in Neural Information Processing Systems, vol. 36, pp. 24191–24222, 2023
work page 2023
-
[38]
Gradient clipping improves adagrad when the noise is heavy-tailed,
S. Chezhegov, Y. Klyukin, A. Semenov, A. Beznosikov, A. Gasnikov, S. Horváth, M. Takáč, and E. Gorbunov, “Gradient clipping improves adagrad when the noise is heavy-tailed,”arXiv preprint arXiv:2406.04443, 2024
-
[39]
Adaptive subgradient methods for online learning and stochastic optimization.,
J. Duchi, E. Hazan, and Y. Singer, “Adaptive subgradient methods for online learning and stochastic optimization.,”Journal of machine learning research, vol. 12, no. 7, 2011
work page 2011
-
[40]
Adam: A Method for Stochastic Optimization
D. P. Kingma and J. Ba, “Adam: A method for stochastic optimization,”arXiv preprint arXiv:1412.6980, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[41]
Gradient normalization provably benefits nonconvex sgd under heavy-tailed noise,
T. Sun, X. Liu, and K. Yuan, “Gradient normalization provably benefits nonconvex sgd under heavy-tailed noise,”arXiv preprint arXiv:2410.16561, 2024
-
[42]
D. Jakovetić, D. Bajović, A. K. Sahu, S. Kar, N. Milosević, and D. Stamenković, “Nonlinear gradient mappings and stochastic optimization: A general framework with applications to heavy-tail noise,”SIAM Journal on Optimization, vol. 33, no. 2, pp. 394–423, 2023
work page 2023
-
[43]
A. Armacki, S. Yu, D. Bajovic, D. Jakovetic, and S. Kar, “Large deviations and improved mean-squared error rates of nonlinear sgd: Heavy-tailed noise and power of symmetry,”arXiv preprint arXiv:2410.15637, 2024
-
[44]
E. Gorbunov, A. Sadiev, M. Danilova, S. Horváth, G. Gidel, P. Dvurechensky, A. Gasnikov, and P. Richtárik, “High-probability convergence for composite and distributed stochastic minimization and variational inequalities with heavy-tailed noise,” 2024
work page 2024
-
[45]
Unbiased and sign compression in distributed learning: Comparing noise resilience via SDEs,
E. M. Compagnoni, R. Islamov, F. N. Proske, and A. Lucchi, “Unbiased and sign compression in distributed learning: Comparing noise resilience via SDEs,” inThe 28th International Conference on Artificial Intelligence and Statistics, 2025
work page 2025
-
[46]
Efficient adaptive federated optimization,
S. H. Lee, S. Sharma, M. Zaheer, and T. Li, “Efficient adaptive federated optimization,”arXiv preprint arXiv:2410.18117, 2024
-
[47]
Secure distributed optimization under gradient attacks,
S. Yu and S. Kar, “Secure distributed optimization under gradient attacks,”IEEE Transactions on Signal Processing, 2023
work page 2023
-
[48]
B. Li and Y. Chi, “Convergence and privacy of decentralized nonconvex optimization with gradient clipping and communication compression,”IEEE Journal of Selected Topics in Signal Processing, 2025
work page 2025
-
[49]
On generalization of decentralized learning with separable data,
H. Taheri and C. Thrampoulidis, “On generalization of decentralized learning with separable data,” in International Conference on Artificial Intelligence and Statistics, pp. 4917–4945, PMLR, 2023
work page 2023
-
[50]
Improving language understanding by generative pre-training,
A. Radford, K. Narasimhan, T. Salimans, I. Sutskever,et al., “Improving language understanding by generative pre-training,” 2018
work page 2018
-
[51]
Variance-reduced decentralized stochastic optimization with accelerated convergence,
R. Xin, U. A. Khan, and S. Kar, “Variance-reduced decentralized stochastic optimization with accelerated convergence,”IEEE Transactions on Signal Processing, vol. 68, pp. 6255–6271, 2020. 14
work page 2020
-
[52]
A. Olshevsky, “Linear time average consensus on fixed graphs and implications for decentralized opti- mization and multi-agent control,”arXiv preprint arXiv:1411.4186, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[53]
Distributed strategies for generating weight-balanced and doubly stochastic digraphs,
B. Gharesifard and J. Cortés, “Distributed strategies for generating weight-balanced and doubly stochastic digraphs,”European Journal of Control, vol. 18, no. 6, pp. 539–557, 2012
work page 2012
-
[54]
Stochastic gradient push for distributed deep learning,
M. Assran, N. Loizou, N. Ballas, and M. Rabbat, “Stochastic gradient push for distributed deep learning,” in International Conference on Machine Learning, pp. 344–353, PMLR, 2019
work page 2019
-
[55]
The laplacian spectrum of graphs,
B. Mohar, Y. Alavi, G. Chartrand, and O. Oellermann, “The laplacian spectrum of graphs,”Graph theory, combinatorics, and applications, vol. 2, no. 871-898, p. 12, 1991
work page 1991
-
[56]
An improved convergence analysis for decentralized online stochastic non-convex optimization,
R. Xin, U. A. Khan, and S. Kar, “An improved convergence analysis for decentralized online stochastic non-convex optimization,”IEEE Transactions on Signal Processing, vol. 69, pp. 1842–1858, 2021
work page 2021
-
[57]
Distributed subgradient methods for multi-agent optimization,
A. Nedic and A. Ozdaglar, “Distributed subgradient methods for multi-agent optimization,”IEEE Transactions on Automatic Control, vol. 54, no. 1, pp. 48–61, 2009
work page 2009
-
[58]
A scheme for robust distributed sensor fusion based on average consensus,
L. Xiao, S. Boyd, and S. Lall, “A scheme for robust distributed sensor fusion based on average consensus,” in IPSN 2005. Fourth International Symposium on Information Processing in Sensor Networks, 2005., pp. 63–70, IEEE, 2005
work page 2005
-
[59]
The fitting of power series, meaning polynomials, illustrated on band-spectroscopic data,
A. E. Beaton and J. W. Tukey, “The fitting of power series, meaning polynomials, illustrated on band-spectroscopic data,”Technometrics, vol. 16, no. 2, pp. 147–185, 1974
work page 1974
-
[60]
Quasi-global momentum: Accelerating decentralized deep learning on heterogeneous data,
T. Lin, S. P. Karimireddy, S. Stich, and M. Jaggi, “Quasi-global momentum: Accelerating decentralized deep learning on heterogeneous data,” inInternational Conference on Machine Learning, pp. 6654–6665, PMLR, 2021
work page 2021
-
[61]
Gtadam: Gradient tracking with adaptive momentum for distributed online optimization,
G. Carnevale, F. Farina, I. Notarnicola, and G. Notarstefano, “Gtadam: Gradient tracking with adaptive momentum for distributed online optimization,”IEEE Transactions on Control of Network Systems, vol. 10, no. 3, pp. 1436–1448, 2022
work page 2022
-
[62]
Smoothed normalization for efficient distributed private optimization,
E. Shulgin, S. Khirirat, and P. Richtárik, “Smoothed normalization for efficient distributed private optimization,”arXiv preprint arXiv:2502.13482, 2025. Appendix A Proof of Claim 1 Proof. Consider n scalar functions that for eachi ∈ V, fi(x) = (1 /2)(x − ai)2 for some ai, and complete graph with W = (1/n)1n1⊤ n. Let ai = a, ∀i = 1, . . . , n/2, and ai = ...
-
[63]
W − 1n1⊤ n /n = (W − 1n1⊤ n /n)(In − 1n1⊤ n /n) = (In − 1n1⊤ n /n)(W − 1n1⊤ n /n)
-
[64]
W k − 1n1⊤ n /n = (W − 1n1⊤ n /n)k, ∀k ∈ N+
- [65]
-
[66]
We then present a standard decent lemma forL-smooth functions
Pm i=1 ap i ≤ Pm i=1 ai p ≤ mp−1Pm i=1 ap i , ∀m ∈ N+, ∀ai ∈ R+. We then present a standard decent lemma forL-smooth functions . Lemma 2 (Decent lemma forL-smooth functions). Let Assumption 2 hold. For anyx, y ∈ Rd, there holds f(y) ≤ f(x) + ∇f(x)⊤(y − x) + L 2 ∥x − y∥2. We next present the main descent lemma on the network average. Lemma 3 (Decent lemma ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.