High-Probability Convergence Guarantees of Decentralized SGD
Pith reviewed 2026-05-22 13:10 UTC · model grok-4.3
The pith
Decentralized SGD converges in high probability under the same conditions on the cost function as required for mean-squared error convergence.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Decentralized SGD converges in high probability under the same conditions on the cost as in the MSE sense, removing the restrictive assumptions used in prior works. The sharp analysis yields order-optimal rates for both non-convex and strongly convex costs. It also establishes a linear speed-up in the number of users, leading to matching or strictly better transient times than those obtained from MSE results. These outcomes rest on technical results including a variance-reduction effect of decentralized methods in the high-probability sense and a novel bound on the moment-generating function of strongly convex costs.
What carries the argument
The variance-reduction effect of decentralized methods in the high-probability sense together with a novel bound on the moment-generating function of strongly convex costs.
If this is right
- DSGD achieves order-optimal convergence rates in high probability for both non-convex and strongly convex costs.
- Linear speed-up with the number of users holds in the high-probability setting.
- Transient times match or improve upon those derived from mean-squared error analyses.
- The same light-tailed noise and standard smoothness assumptions suffice for both high-probability and mean-squared error convergence.
Where Pith is reading between the lines
- The moment-generating function bound may also tighten high-probability analyses for centralized SGD.
- The variance-reduction observation could apply to other distributed first-order methods that average information across nodes.
- These guarantees suggest decentralized training could be used in settings where single-run reliability matters as much as average performance.
- Extensions to time-varying communication graphs or asynchronous updates would test how robust the linear speed-up remains.
Load-bearing premise
The stochastic noise must be light-tailed so that moment-generating functions exist and yield exponential tail bounds.
What would settle it
An experiment or calculation showing that the claimed high-probability bounds fail when the noise has heavier tails for which the moment-generating function does not exist.
Figures
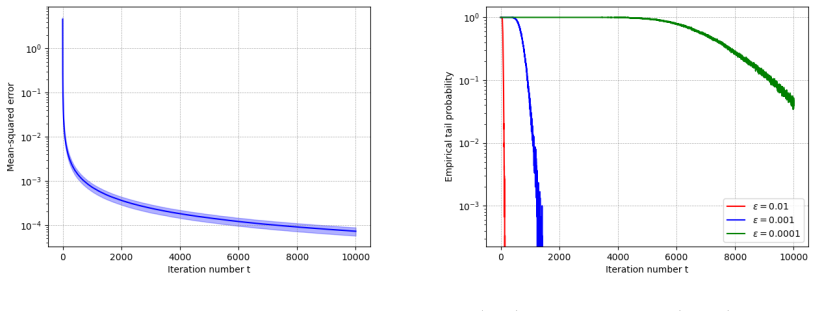
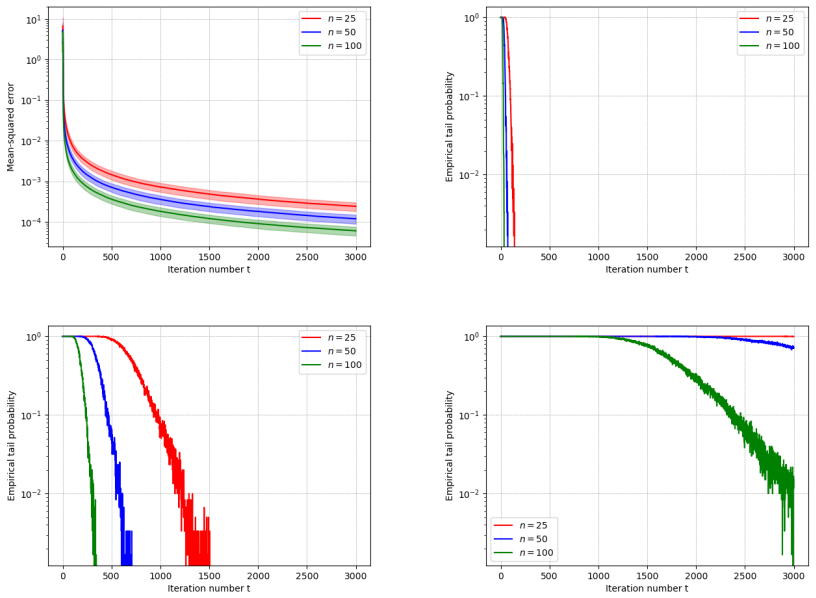
read the original abstract
Convergence in high-probability (HP) has attracted increasing interest, due to implying exponentially decaying tail bounds and strong guarantees for individual runs of an algorithm. While many works study HP guarantees in centralized settings, much less is understood in the decentralized setup, where existing works require strong assumptions, like uniformly bounded gradients, or asymptotically vanishing noise. This results in a significant gap between the assumptions used to establish convergence in the HP and the mean-squared error (MSE) sense, and is also contrary to centralized settings, where it is known that $\mathtt{SGD}$ converges in HP under the same conditions on the cost function as needed for MSE convergence. Motivated by these observations, we study the HP convergence of Decentralized $\mathtt{SGD}$ ($\mathtt{DSGD}$) in the presence of light-tailed noise, providing several strong results. First, we show that $\mathtt{DSGD}$ converges in HP under the same conditions on the cost as in the MSE sense, removing the restrictive assumptions used in prior works. Second, our sharp analysis yields order-optimal rates for both non-convex and strongly convex costs. Third, we establish a linear speed-up in the number of users, leading to matching or strictly better transient times than those obtained from MSE results, further underlining the tightness of our analysis. To the best of our knowledge, this is the first work that shows $\mathtt{DSGD}$ achieves a linear speed-up in the HP sense. Our relaxed assumptions and sharp rates stem from several technical results of independent interest, including a result on the variance-reduction effect of decentralized methods in the HP sense, as well as a novel bound on the moment-generating function of strongly convex costs, of interest even in centralized settings. Numerical experiments validate our theory.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript analyzes high-probability convergence of Decentralized SGD (DSGD) under light-tailed noise. It claims that DSGD converges in high probability under the same smoothness/strong-convexity and light-tailed noise conditions required for mean-squared error convergence, without needing uniformly bounded gradients or asymptotically vanishing noise. The sharp analysis yields order-optimal rates for both non-convex and strongly convex objectives, establishes linear speedup in the number of users, and shows matching or strictly better transient times than MSE-based results. The results rely on new technical tools including a variance-reduction effect of decentralized averaging in the high-probability sense and a novel moment-generating function bound for strongly convex costs.
Significance. If the central claims hold, the work closes a notable gap between high-probability and MSE analyses in the decentralized setting, aligning it with known centralized SGD results. The order-optimal rates, linear speedup, and improved transient times would represent a tight analysis. The novel MGF bound and variance-reduction result are of independent interest and could apply even in centralized settings. Numerical experiments are cited as validation.
major comments (2)
- [MGF bound and Theorem on linear speedup (around the variance-reduction lemma)] The linear speedup and order-optimality claims hinge on the high-probability bounds not introducing network-dependent multiplicative factors from the consensus step. The analysis must explicitly show that the MGF bound and variance-reduction effect remain free of terms scaling with the mixing time or 1/(1-λ₂) of the gossip matrix; otherwise the rates would carry graph-dependent constants absent from the corresponding MSE analyses and could fail to deliver linear speedup on poorly connected graphs.
- [Main convergence theorems for strongly convex and non-convex cases] The central claim that DSGD converges in HP under exactly the same conditions as MSE requires that the light-tailed noise assumption suffices without additional restrictions on the network topology. If the consensus averaging inflates the effective sub-Gaussian parameter or MGF constant by a factor depending on the spectral gap, the high-probability deviation bounds would not match the MSE rates uniformly.
minor comments (2)
- [Abstract] Clarify in the abstract and introduction the precise regimes in which the transient time is strictly better than the MSE counterpart.
- [Preliminaries] Ensure all notation for the mixing matrix, its eigenvalues, and the consensus error is introduced consistently before the first technical lemma.
Simulated Author's Rebuttal
We thank the referee for the careful reading and constructive comments. We address each major comment below, providing clarifications on how our analysis ensures the high-probability bounds remain free of network-dependent factors in the leading terms.
read point-by-point responses
-
Referee: [MGF bound and Theorem on linear speedup (around the variance-reduction lemma)] The linear speedup and order-optimality claims hinge on the high-probability bounds not introducing network-dependent multiplicative factors from the consensus step. The analysis must explicitly show that the MGF bound and variance-reduction effect remain free of terms scaling with the mixing time or 1/(1-λ₂) of the gossip matrix; otherwise the rates would carry graph-dependent constants absent from the corresponding MSE analyses and could fail to deliver linear speedup on poorly connected graphs.
Authors: We thank the referee for this important observation. Our variance-reduction result (Lemma 3.3) shows that decentralized averaging produces a high-probability contraction on the consensus error whose leading term is independent of the spectral gap; the mixing time appears only in a lower-order transient that is absorbed into the overall iteration complexity. The novel MGF bound (Lemma 4.2) for strongly convex objectives is obtained by exploiting strong convexity to dominate the deviation after averaging, again without a multiplicative 1/(1-λ₂) factor in the exponent. Consequently, the high-probability rates in Theorems 4.1 and 5.1 match the centralized rates up to constants independent of the graph, delivering linear speedup in the number of nodes for any fixed connected graph. We will add a short remark immediately after Lemma 3.3 to make this independence explicit. revision: partial
-
Referee: [Main convergence theorems for strongly convex and non-convex cases] The central claim that DSGD converges in HP under exactly the same conditions as MSE requires that the light-tailed noise assumption suffices without additional restrictions on the network topology. If the consensus averaging inflates the effective sub-Gaussian parameter or MGF constant by a factor depending on the spectral gap, the high-probability deviation bounds would not match the MSE rates uniformly.
Authors: We appreciate the referee raising this point. The proofs of the main theorems (Theorems 4.1 and 5.1) explicitly track the moment-generating function through the consensus step. Because the variance-reduction effect bounds the deviation of the averaged gradient noise by a quantity whose sub-Gaussian parameter is the same as the local noise (up to a universal constant independent of λ₂), the light-tailed assumption is preserved without inflation by the spectral gap. The network topology affects only the number of steps needed to reach consensus, which is already accounted for in the transient-time comparison with MSE results. Thus the high-probability convergence holds under precisely the same smoothness/strong-convexity and light-tailed noise conditions used for MSE convergence, for any connected gossip matrix satisfying the standard assumptions. revision: no
Circularity Check
Derivation chain self-contained; novel HP variance-reduction and MGF bounds are independent contributions
full rationale
The paper derives high-probability convergence for DSGD under the same smoothness/strong-convexity and light-tailed noise assumptions used for MSE analyses. It explicitly introduces two technical results of independent interest—a variance-reduction effect of decentralized methods in the HP sense and a novel MGF bound for strongly convex costs—that do not reduce to fitted parameters, self-definitions, or prior self-citations by construction. No equations or steps are shown to rename known results or import uniqueness via overlapping-author citations in a load-bearing manner. The linear speedup and order-optimal rates follow from these new bounds rather than from any circular reduction to inputs. This is the expected honest non-finding for a proof paper whose central claims rest on fresh analysis rather than reparameterization.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The cost function satisfies standard smoothness and (strong) convexity assumptions identical to those sufficient for MSE convergence of DSGD.
- domain assumption The stochastic noise is light-tailed, allowing moment-generating function bounds.
Reference graph
Works this paper leans on
-
[1]
A. H. Sayed, “Adaptive Networks,”Proceedings of the IEEE, vol. 102, no. 4, pp. 460–497, 2014
work page 2014
-
[2]
Communication- Efficient Learning of Deep Networks from Decentralized Data,
B. McMahan, E. Moore, D. Ramage, S. Hampson, and B. A. y. Arcas, “Communication- Efficient Learning of Deep Networks from Decentralized Data,” inProceedings of the 20th International Conference on Artificial Intelligence and Statistics(A. Singh and J. Zhu, eds.), vol. 54 ofProceedings of Machine Learning Research, pp. 1273–1282, PMLR, 20–22 Apr 2017
work page 2017
-
[3]
Networked Signal and Information Processing: Learning by multiagent systems,
S. Vlaski, S. Kar, A. H. Sayed, and J. M. Moura, “Networked Signal and Information Processing: Learning by multiagent systems,”IEEE Signal Processing Magazine, vol. 40, no. 5, pp. 92–105, 2023
work page 2023
-
[4]
Practical secure aggregation for privacy-preserving machine learning,
K. Bonawitz, V. Ivanov, B. Kreuter, A. Marcedone, H. B. McMahan, S. Patel, D. Ram- age, A. Segal, and K. Seth, “Practical secure aggregation for privacy-preserving machine learning,” inproceedings of the 2017 ACM SIGSAC Conference on Computer and Com- munications Security, pp. 1175–1191, 2017
work page 2017
-
[5]
Secure Distributed Optimization Under Gradient Attacks,
S. Yu and S. Kar, “Secure Distributed Optimization Under Gradient Attacks,”IEEE Transactions on Signal Processing, vol. 71, pp. 1802–1816, 2023
work page 2023
-
[6]
Federated Learning: Strategies for Improving Communication Efficiency
J. Koneˇ cn` y, H. B. McMahan, F. X. Yu, P. Richt´ arik, A. T. Suresh, and D. Bacon, “Fed- erated learning: Strategies for improving communication efficiency,”arXiv:1610.05492, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
- [7]
-
[8]
Distributed Learning in the Nonconvex World: From batch data to streaming and beyond,
T.-H. Chang, M. Hong, H.-T. Wai, X. Zhang, and S. Lu, “Distributed Learning in the Nonconvex World: From batch data to streaming and beyond,”IEEE Signal Processing Magazine, vol. 37, no. 3, pp. 26–38, 2020
work page 2020
-
[9]
Local SGD Converges Fast and Communicates Little,
S. U. Stich, “Local SGD Converges Fast and Communicates Little,” inInternational Conference on Learning Representations, 2019
work page 2019
-
[10]
Towards Understanding Biased Client Selection in Federated Learning ,
Y. J. Cho, J. Wang, and G. Joshi, “ Towards Understanding Biased Client Selection in Federated Learning ,” inProceedings of The 25th International Conference on Artificial Intelligence and Statistics(G. Camps-Valls, F. J. R. Ruiz, and I. Valera, eds.), vol. 151 ofProceedings of Machine Learning Research, pp. 10351–10375, PMLR, 28–30 Mar 2022. 14
work page 2022
-
[11]
A Unified Theory of Decen- tralized SGD with Changing Topology and Local Updates,
A. Koloskova, N. Loizou, S. Boreiri, M. Jaggi, and S. Stich, “A Unified Theory of Decen- tralized SGD with Changing Topology and Local Updates,” inProceedings of the 37th International Conference on Machine Learning(H. D. III and A. Singh, eds.), vol. 119 ofProceedings of Machine Learning Research, pp. 5381–5393, PMLR, 13–18 Jul 2020
work page 2020
-
[12]
Asynchronous parallel algo- rithms for nonconvex optimization,
L. Cannelli, F. Facchinei, V. Kungurtsev, and G. Scutari, “Asynchronous parallel algo- rithms for nonconvex optimization,”Mathematical Programming, vol. 184, pp. 121–154, Nov 2020
work page 2020
-
[13]
Distributed Subgradient Methods for Multi-Agent Opti- mization,
A. Nedi´ c and A. Ozdaglar, “Distributed Subgradient Methods for Multi-Agent Opti- mization,”IEEE Transactions on Automatic Control, vol. 54, no. 1, pp. 48–61, 2009
work page 2009
-
[14]
Fast Distributed Gradient Methods,
D. Jakoveti´ c, J. Xavier, and J. M. F. Moura, “Fast Distributed Gradient Methods,” IEEE Transactions on Automatic Control, vol. 59, no. 5, pp. 1131–1146, 2014
work page 2014
-
[15]
EXTRA: An Exact First-Order Algorithm for Decentralized Consensus Optimization,
W. Shi, Q. Ling, G. Wu, and W. Yin, “EXTRA: An Exact First-Order Algorithm for Decentralized Consensus Optimization,”SIAM Journal on Optimization, vol. 25, no. 2, pp. 944–966, 2015
work page 2015
-
[16]
NEXT: In-Network Nonconvex Optimization,
P. D. Lorenzo and G. Scutari, “NEXT: In-Network Nonconvex Optimization,”IEEE Transactions on Signal and Information Processing over Networks, vol. 2, no. 2, pp. 120– 136, 2016
work page 2016
-
[17]
On the Convergence of Decentralized Gradient Descent,
K. Yuan, Q. Ling, and W. Yin, “On the Convergence of Decentralized Gradient Descent,” SIAM Journal on Optimization, vol. 26, no. 3, pp. 1835–1854, 2016
work page 2016
-
[18]
A Unification and Generalization of Exact Distributed First-Order Meth- ods,
D. Jakoveti´ c, “A Unification and Generalization of Exact Distributed First-Order Meth- ods,”IEEE Transactions on Signal and Information Processing over Networks, vol. 5, no. 1, pp. 31–46, 2019
work page 2019
-
[19]
B. Swenson, R. Murray, H. V. Poor, and S. Kar, “Distributed Stochastic Gradient Descent: Nonconvexity, Nonsmoothness, and Convergence to Local Minima,”JMLR, vol. 23, jan 2022
work page 2022
-
[20]
Convergence Rates for Distributed Stochastic Optimization Over Random Networks,
D. Jakoveti´ c, D. Bajovic, A. K. Sahu, and S. Kar, “Convergence Rates for Distributed Stochastic Optimization Over Random Networks,” in2018 IEEE Conference on Decision and Control (CDC), pp. 4238–4245, 2018
work page 2018
-
[21]
Distributed stochastic gradient tracking methods,
S. Pu and A. Nedi´ c, “Distributed stochastic gradient tracking methods,”Mathematical Programming, vol. 187, pp. 409–457, May 2021
work page 2021
-
[22]
Distributed Learning in Non-Convex Environments—Part I: Agreement at a Linear Rate,
S. Vlaski and A. H. Sayed, “Distributed Learning in Non-Convex Environments—Part I: Agreement at a Linear Rate,”IEEE Transactions on Signal Processing, vol. 69, pp. 1242– 1256, 2021
work page 2021
-
[23]
Distributed Learning in Non-Convex Environments— Part II: Polynomial Escape From Saddle-Points,
S. Vlaski and A. H. Sayed, “Distributed Learning in Non-Convex Environments— Part II: Polynomial Escape From Saddle-Points,”IEEE Transactions on Signal Processing, vol. 69, pp. 1257–1270, 2021
work page 2021
-
[24]
Variance-Reduced Decentralized Stochastic Optimiza- tion With Accelerated Convergence,
R. Xin, U. A. Khan, and S. Kar, “Variance-Reduced Decentralized Stochastic Optimiza- tion With Accelerated Convergence,”IEEE Transactions on Signal Processing, vol. 68, pp. 6255–6271, 2020. 15
work page 2020
-
[25]
An Improved Convergence Analysis for Decentralized Online Stochastic Non-Convex Optimization,
R. Xin, U. A. Khan, and S. Kar, “An Improved Convergence Analysis for Decentralized Online Stochastic Non-Convex Optimization,”IEEE Transactions on Signal Processing, vol. 69, pp. 1842–1858, 2021
work page 2021
-
[26]
Cooperative SGD: A Unified Framework for the Design and Analysis of Local-Update SGD Algorithms,
J. Wang and G. Joshi, “Cooperative SGD: A Unified Framework for the Design and Analysis of Local-Update SGD Algorithms,”Journal of Machine Learning Research, vol. 22, no. 213, pp. 1–50, 2021
work page 2021
-
[27]
Adaptation, Learning, and Optimization over Networks,
A. H. Sayed, “Adaptation, Learning, and Optimization over Networks,”Foundations and Trends®in Machine Learning, vol. 7, no. 4-5, pp. 311–801, 2014
work page 2014
-
[28]
Robust stochastic approximation approach to stochastic programming,
A. Nemirovski˘ ı, A. Juditsky, G. Lan, and A. Shapiro, “Robust stochastic approximation approach to stochastic programming,”SIAM Journal on optimization, vol. 19, no. 4, pp. 1574–1609, 2009
work page 2009
-
[29]
Stochastic first-and zeroth-order methods for nonconvex stochastic programming,
S. Ghadimi and G. Lan, “Stochastic first-and zeroth-order methods for nonconvex stochastic programming,”SIAM Journal on Optimization, vol. 23, no. 4, pp. 2341–2368, 2013
work page 2013
-
[30]
On the Convergence of Stochastic Gradient Descent with Adap- tive Stepsizes,
X. Li and F. Orabona, “On the Convergence of Stochastic Gradient Descent with Adap- tive Stepsizes,” inProceedings of the Twenty-Second International Conference on Ar- tificial Intelligence and Statistics(K. Chaudhuri and M. Sugiyama, eds.), vol. 89 of Proceedings of Machine Learning Research, pp. 983–992, PMLR, 16–18 Apr 2019
work page 2019
-
[31]
Tight analyses for non-smooth stochastic gradient descent,
N. J. A. Harvey, C. Liaw, Y. Plan, and S. Randhawa, “Tight analyses for non-smooth stochastic gradient descent,” inProceedings of the Thirty-Second Conference on Learning Theory(A. Beygelzimer and D. Hsu, eds.), vol. 99 ofProceedings of Machine Learning Research, pp. 1579–1613, PMLR, 25–28 Jun 2019
work page 2019
-
[32]
Large deviations rates for stochastic gradient descent with strongly convex functions,
D. Bajovi´ c, D. Jakoveti´ c, and S. Kar, “Large deviations rates for stochastic gradient descent with strongly convex functions,” inProceedings of The 26th International Con- ference on Artificial Intelligence and Statistics(F. Ruiz, J. Dy, and J.-W. van de Meent, eds.), vol. 206 ofProceedings of Machine Learning Research, pp. 10095–10111, PMLR, 25–27 Apr 2023
work page 2023
-
[33]
High Probability Conver- gence of Stochastic Gradient Methods,
Z. Liu, T. D. Nguyen, T. H. Nguyen, A. Ene, and H. Nguyen, “High Probability Conver- gence of Stochastic Gradient Methods,” inProceedings of the 40th International Confer- ence on Machine Learning(A. Krause, E. Brunskill, K. Cho, B. Engelhardt, S. Sabato, and J. Scarlett, eds.), vol. 202 ofProceedings of Machine Learning Research, pp. 21884– 21914, PMLR, ...
work page 2023
-
[34]
Improved Convergence in High Probability of Clipped Gradient Methods with Heavy Tailed Noise,
T. D. Nguyen, T. H. Nguyen, A. Ene, and H. Nguyen, “Improved Convergence in High Probability of Clipped Gradient Methods with Heavy Tailed Noise,” inAdvances in Neural Information Processing Systems(A. Oh, T. Neumann, A. Globerson, K. Saenko, M. Hardt, and S. Levine, eds.), vol. 36, pp. 24191–24222, Curran Associates, Inc., 2023
work page 2023
-
[35]
Z. Liu, J. Zhang, and Z. Zhou, “Breaking the Lower Bound with (Little) Structure: Acceleration in Non-Convex Stochastic Optimization with Heavy-Tailed Noise,” inPro- ceedings of Thirty Sixth Conference on Learning Theory(G. Neu and L. Rosasco, eds.), vol. 195 ofProceedings of Machine Learning Research, pp. 2266–2290, PMLR, 12–15 Jul 2023. 16
work page 2023
-
[36]
From Gradient Clipping to Normalization for Heavy Tailed SGD,
F. H¨ ubler, I. Fatkhullin, and N. He, “From Gradient Clipping to Normalization for Heavy Tailed SGD,” inThe 28th International Conference on Artificial Intelligence and Statistics, vol. 258, 2025
work page 2025
-
[37]
N. Kornilov, P. Zmushko, A. Semenov, A. Gasnikov, and A. Beznosikov, “Sign Operator for Coping with Heavy-Tailed Noise: High Probability Convergence Bounds with Exten- sions to Distributed Optimization and Comparison Oracle,”arXiv:2502.07923, 2025
-
[38]
A. Armacki, S. Yu, P. Sharma, G. Joshi, D. Bajovi´ c, D. Jakoveti´ c, and S. Kar, “High- probability Convergence Bounds for Online Nonlinear Stochastic Gradient Descent under Heavy-tailed Noise,” inThe 28th International Conference on Artificial Intelligence and Statistics(Y. Li, S. Mandt, S. Agrawal, and E. Khan, eds.), vol. 258 ofProceedings of Machine ...
work page 2025
-
[39]
A high probability analysis of adaptive sgd with momentum,
X. Li and F. Orabona, “A high probability analysis of adaptive sgd with momentum,” Workshop on “Beyond first-order methods in ML systems”, 37th International Confer- ence on Machine Learning, 2020
work page 2020
-
[40]
Revisiting the Last-Iterate Convergence of Stochastic Gradient Methods,
Z. Liu and Z. Zhou, “Revisiting the Last-Iterate Convergence of Stochastic Gradient Methods,” inThe Twelfth International Conference on Learning Representations, 2024
work page 2024
-
[41]
L. Madden, E. Dall’Anese, and S. Becker, “High Probability Convergence Bounds for Non-convex Stochastic Gradient Descent with Sub-Weibull Noise,”Journal of Machine Learning Research, vol. 25, no. 241, pp. 1–36, 2024
work page 2024
-
[42]
J. Nair, A. Wierman, and B. Zwart,The Fundamentals of Heavy Tails: Properties, Emer- gence, and Estimation. Cambridge Series in Statistical and Probabilistic Mathematics, Cambridge University Press, 2022
work page 2022
-
[43]
A. Sadiev, M. Danilova, E. Gorbunov, S. Horv´ ath, G. Gidel, P. Dvurechensky, A. Gas- nikov, and P. Richt´ arik, “High-Probability Bounds for Stochastic Optimization and Vari- ational Inequalities: the Case of Unbounded Variance,” inInternational Conference on Machine Learning, pp. 29563–29648, PMLR, 2023
work page 2023
-
[44]
Breaking the Heavy-Tailed Noise Barrier in Stochastic Optimization Problems,
N. Puchkin, E. Gorbunov, N. Kutuzov, and A. Gasnikov, “Breaking the Heavy-Tailed Noise Barrier in Stochastic Optimization Problems,”arXiv:2311.04161, 2023
-
[45]
A. Armacki, S. Yu, D. Bajovi´ c, D. Jakoveti´ c, and S. Kar, “Large Deviations and Im- proved Mean-squared Error Rates of Nonlinear SGD: Heavy-tailed Noise and Power of Symmetry,”arXiv:2410.15637, 2024
-
[46]
Optimal High-probability Convergence of Nonlinear SGD under Heavy-tailed Noise via Symmetrization,
A. Armacki, D. Bajovi´ c, D. Jakoveti´ c, and S. Kar, “Optimal High-probability Convergence of Nonlinear SGD under Heavy-tailed Noise via Symmetrization,” arXiv:2507.09093, 2025
-
[47]
Better Theory for SGD in the Nonconvex World,
A. Khaled and P. Richt´ arik, “Better Theory for SGD in the Nonconvex World,”Trans- actions on Machine Learning Research, 2023
work page 2023
-
[48]
Achieving Geometric Convergence for Distributed Optimization Over Time-Varying Graphs,
A. Nedi´ c, A. Olshevsky, and W. Shi, “Achieving Geometric Convergence for Distributed Optimization Over Time-Varying Graphs,”SIAM Journal on Optimization, vol. 27, no. 4, pp. 2597–2633, 2017. 17
work page 2017
-
[49]
Harnessing Smoothness to Accelerate Distributed Optimization,
G. Qu and N. Li, “Harnessing Smoothness to Accelerate Distributed Optimization,” IEEE Transactions on Control of Network Systems, vol. 5, no. 3, pp. 1245–1260, 2018
work page 2018
-
[50]
Second-Order Guarantees of Stochastic Gradient Descent in Nonconvex Optimization,
S. Vlaski and A. H. Sayed, “Second-Order Guarantees of Stochastic Gradient Descent in Nonconvex Optimization,”IEEE Transactions on Automatic Control, vol. 67, no. 12, pp. 6489–6504, 2022
work page 2022
-
[51]
Revisiting Gradient Clipping: Stochastic bias and tight convergence guarantees,
A. Koloskova, H. Hendrikx, and S. U. Stich, “Revisiting Gradient Clipping: Stochastic bias and tight convergence guarantees,”arXiv:2305.01588, 2023
-
[52]
H. Karimi, J. Nutini, and M. Schmidt, “Linear convergence of gradient and proximal- gradient methods under the Polyak- Lojasiewicz condition,” inMachine Learning and Knowledge Discovery in Databases: European Conference, ECML PKDD 2016, Riva del Garda, Italy, September 19-23, 2016, Proceedings, Part I 16, pp. 795–811, Springer, 2016
work page 2016
-
[53]
Decentralized Nonconvex Optimization under Heavy-Tailed Noise: Normalization and Optimal Convergence
S. Yu, D. Jakoveti´ c, and S. Kar, “Decentralized Nonconvex Optimization under Heavy- Tailed Noise: Normalization and Optimal Convergence,”arXiv:2505.03736, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[54]
S. Kar, J. M. F. Moura, and K. Ramanan, “Distributed Parameter Estimation in Sensor Networks: Nonlinear Observation Models and Imperfect Communication,”IEEE Trans- actions on Information Theory, vol. 58, no. 6, pp. 3575–3605, 2012
work page 2012
-
[55]
Distributed Pareto Optimization via Diffusion Strategies,
J. Chen and A. H. Sayed, “Distributed Pareto Optimization via Diffusion Strategies,” IEEE Journal of Selected Topics in Signal Processing, vol. 7, no. 2, pp. 205–220, 2013
work page 2013
-
[56]
Multitask learning over graphs: An approach for distributed, streaming machine learning,
R. Nassif, S. Vlaski, C. Richard, J. Chen, and A. H. Sayed, “Multitask learning over graphs: An approach for distributed, streaming machine learning,”IEEE Signal Pro- cessing Magazine, vol. 37, no. 3, pp. 14–25, 2020
work page 2020
-
[57]
Convergence in High Probability of Dis- tributed Stochastic Gradient Descent Algorithms,
K. Lu, H. Wang, H. Zhang, and L. Wang, “Convergence in High Probability of Dis- tributed Stochastic Gradient Descent Algorithms,”IEEE Transactions on Automatic Control, vol. 69, no. 4, pp. 2189–2204, 2024
work page 2024
-
[58]
K. Lu, “Online Distributed Algorithms for Online Noncooperative Games With Stochas- tic Cost Functions: High Probability Bound of Regrets,”IEEE Transactions on Auto- matic Control, vol. 69, no. 12, pp. 8860–8867, 2024
work page 2024
-
[59]
H. Xu, K. Lu, and Y.-L. Wang, “Online distributed nonconvex optimization with stochas- tic objective functions: High probability bound analysis of dynamic regrets,”Automatica, vol. 170, p. 111863, 2024
work page 2024
-
[60]
High Probability Convergence of Clipped Dis- tributed Dual Averaging With Heavy-Tailed Noises,
Y. Qin, K. Lu, H. Xu, and X. Chen, “High Probability Convergence of Clipped Dis- tributed Dual Averaging With Heavy-Tailed Noises,”IEEE Transactions on Systems, Man, and Cybernetics: Systems, vol. 55, no. 4, pp. 2624–2632, 2025
work page 2025
-
[61]
Y. Yang, K. Lu, and L. Wang, “Online distributed optimization with clipped stochastic gradients: High probability bound of regrets,”Automatica, vol. 182, p. 112525, 2025
work page 2025
-
[62]
Y. Yang, K. Lu, and L. Wang, “High Probability Convergence of Distributed Clipped Stochastic Gradient Descent with Heavy-tailed Noise,”arXiv:2506.11647, 2025. 18
-
[63]
Distributed Detection via Gaussian Running Consensus: Large Deviations Asymptotic Analysis,
D. Bajovi´ c, D. Jakoveti´ c, J. Xavier, B. Sinopoli, and J. M. F. Moura, “Distributed Detection via Gaussian Running Consensus: Large Deviations Asymptotic Analysis,” IEEE Transactions on Signal Processing, vol. 59, no. 9, pp. 4381–4396, 2011
work page 2011
-
[64]
D. Bajovi´ c, D. Jakoveti´ c, J. M. F. Moura, J. Xavier, and B. Sinopoli, “Large Devia- tions Performance of Consensus+Innovations Distributed Detection With Non-Gaussian Observations,”IEEE Transactions on Signal Processing, vol. 60, no. 11, pp. 5987–6002, 2012
work page 2012
-
[65]
V. Matta, P. Braca, S. Marano, and A. H. Sayed, “Diffusion-Based Adaptive Distributed Detection: Steady-State Performance in the Slow Adaptation Regime,”IEEE Transac- tions on Information Theory, vol. 62, no. 8, pp. 4710–4732, 2016
work page 2016
-
[66]
Distributed Detection Over Adaptive Networks: Refined Asymptotics and the Role of Connectivity,
V. Matta, P. Braca, S. Marano, and A. H. Sayed, “Distributed Detection Over Adaptive Networks: Refined Asymptotics and the Role of Connectivity,”IEEE Transactions on Signal and Information Processing over Networks, vol. 2, no. 4, pp. 442–460, 2016
work page 2016
-
[67]
D. Bajovi´ c, “Inaccuracy Rates for Distributed Inference Over Random Networks With Applications to Social Learning,”IEEE Transactions on Information Theory, vol. 70, no. 1, pp. 415–435, 2024
work page 2024
-
[68]
A unified and refined convergence analysis for non-convex decentralized learning,
S. A. Alghunaim and K. Yuan, “A unified and refined convergence analysis for non-convex decentralized learning,”IEEE Transactions on Signal Processing, vol. 70, pp. 3264–3279, 2022
work page 2022
-
[69]
Diffusion Least-Mean Squares Over Adaptive Net- works: Formulation and Performance Analysis,
C. G. Lopes and A. H. Sayed, “Diffusion Least-Mean Squares Over Adaptive Net- works: Formulation and Performance Analysis,”IEEE Transactions on Signal Process- ing, vol. 56, no. 7, pp. 3122–3136, 2008
work page 2008
-
[70]
Diffusion LMS Strategies for Distributed Estimation,
F. S. Cattivelli and A. H. Sayed, “Diffusion LMS Strategies for Distributed Estimation,” IEEE Transactions on Signal Processing, vol. 58, no. 3, pp. 1035–1048, 2010
work page 2010
-
[71]
Diffusion Adaptation Strategies for Distributed Optimization and Learning Over Networks,
J. Chen and A. H. Sayed, “Diffusion Adaptation Strategies for Distributed Optimization and Learning Over Networks,”IEEE Transactions on Signal Processing, vol. 60, no. 8, pp. 4289–4305, 2012
work page 2012
-
[72]
S. Kar and J. M. Moura, “Consensus + innovations distributed inference over net- works: cooperation and sensing in networked systems,”IEEE Signal Processing Mag- azine, vol. 30, no. 3, pp. 99–109, 2013
work page 2013
-
[73]
R. A. Horn and C. R. Johnson,Matrix Analysis. Cambridge University Press, 2 ed., 2012
work page 2012
-
[74]
X. Lian, C. Zhang, H. Zhang, C.-J. Hsieh, W. Zhang, and J. Liu, “Can Decentralized Algorithms Outperform Centralized Algorithms? A Case Study for Decentralized Parallel Stochastic Gradient Descent,” inAdvances in Neural Information Processing Systems (I. Guyon, U. V. Luxburg, S. Bengio, H. Wallach, R. Fergus, S. Vishwanathan, and R. Garnett, eds.), vol. 3...
work page 2017
-
[75]
Nesterov,Lectures on Convex Optimization
Y. Nesterov,Lectures on Convex Optimization. Springer Publishing Company, Incorpo- rated, 2nd ed., 2018. 19
work page 2018
-
[76]
A Short Note on Concentration Inequalities for Random Vectors with SubGaussian Norm
C. Jin, P. Netrapalli, R. Ge, S. M. Kakade, and M. I. Jordan, “A Short Note on Concen- tration Inequalities for Random Vectors with SubGaussian Norm,”arXiv:1902.03736, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1902
-
[77]
Gradient Convergence in Gradient methods with Errors,
D. P. Bertsekas and J. N. Tsitsiklis, “Gradient Convergence in Gradient methods with Errors,”SIAM Journal on Optimization, vol. 10, no. 3, pp. 627–642, 2000
work page 2000
-
[78]
Vershynin,High-Dimensional Probability: An Introduction with Applications in Data Science
R. Vershynin,High-Dimensional Probability: An Introduction with Applications in Data Science. Cambridge Series in Statistical and Probabilistic Mathematics, Cambridge Uni- versity Press, 2018
work page 2018
-
[79]
Fast linear iterations for distributed averaging,
L. Xiao and S. Boyd, “Fast linear iterations for distributed averaging,”Systems & Control Letters, vol. 53, no. 1, pp. 65–78, 2004
work page 2004
-
[80]
D. Cvetkovic, P. Rowlinson, and S. Simic,Eigenspaces of Graphs. Encyclopedia of Math- ematics and its Applications, Cambridge University Press, 1997
work page 1997
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.