REI-Bench: Can Embodied Agents Understand Vague Human Instructions in Task Planning?
Pith reviewed 2026-05-22 15:19 UTC · model grok-4.3
The pith
Vagueness in referring expressions causes up to 36.9 percent drops in success rates for LLM-based robot task planners.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
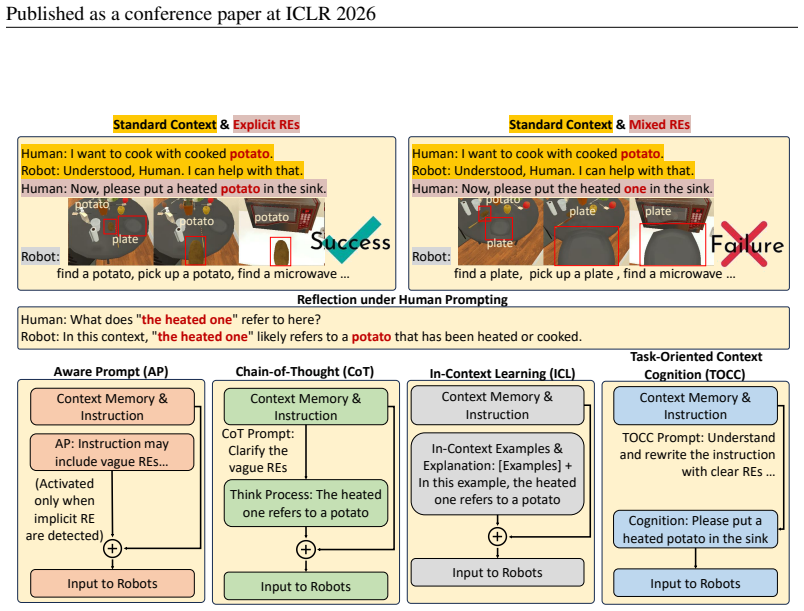
The central claim is that vagueness arising from referring expressions in human instructions severely impairs robot task planning by large language models, with performance drops reaching 36.9 percent, mainly from failures to locate the referenced objects. REI-Bench systematically incorporates such vagueness based on pragmatic principles, and task-oriented context cognition resolves it by producing explicit instructions that achieve the best results among tested methods.
What carries the argument
task-oriented context cognition, which generates clear instructions for robots by incorporating task-oriented and environmental context to resolve vagueness in referring expressions
If this is right
- Robot task planners must incorporate mechanisms to handle vague referring expressions to reach reliable real-world performance.
- Task-oriented context cognition provides a simple mitigation that surpasses aware prompts, chains of thought, and in-context learning.
- Most planning failures trace to missing objects, so future systems should prioritize explicit object identification when context is ambiguous.
- Benchmarks for embodied agents should include modeled vagueness to reflect the instructions actually produced by elderly and child users.
Where Pith is reading between the lines
- Planners could integrate real-time scene perception to resolve referring expressions without separate clarification steps.
- The benchmark could be extended to multi-turn conversations where vagueness builds across exchanges.
- Similar vagueness problems likely affect other instruction-following domains such as robot navigation or manipulation commands.
Load-bearing premise
The benchmark's modeling of vague referring expressions, grounded in pragmatic theory, accurately captures the distribution and impact of real-world vagueness that non-expert users produce when giving instructions to robots.
What would settle it
Running task-oriented context cognition on REI-Bench and checking whether the observed success-rate drop of up to 36.9 percent is eliminated or greatly reduced compared with baseline planners that receive the original vague instructions.
Figures











read the original abstract
Robot task planning decomposes human instructions into executable action sequences that enable robots to complete a series of complex tasks. Although recent large language model (LLM)-based task planners achieve amazing performance, they assume that human instructions are clear and straightforward. However, real-world users are not experts, and their instructions to robots often contain significant vagueness. Linguists suggest that such vagueness frequently arises from referring expressions (REs), whose meanings depend heavily on dialogue context and environment. This vagueness is even more prevalent among the elderly and children, who are the groups that robots should serve more. This paper studies how such vagueness in REs within human instructions affects LLM-based robot task planning and how to overcome this issue. To this end, we propose the first robot task planning benchmark that systematically models vague REs grounded in pragmatic theory (REI-Bench), where we discover that the vagueness of REs can severely degrade robot planning performance, leading to success rate drops of up to 36.9%. We also observe that most failure cases stem from missing objects in planners. To mitigate the REs issue, we propose a simple yet effective approach: task-oriented context cognition, which generates clear instructions for robots, achieving state-of-the-art performance compared to aware prompts, chains of thought, and in-context learning. By tackling the overlooked issue of vagueness, this work contributes to the research community by advancing real-world task planning and making robots more accessible to non-expert users, e.g., the elderly and children.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces REI-Bench, the first benchmark for LLM-based robot task planning that systematically incorporates vague referring expressions (REs) modeled from pragmatic theory. It reports that such vagueness causes success-rate drops of up to 36.9%, with most failures arising from missing objects, and proposes a task-oriented context cognition method that generates clarified instructions and outperforms aware prompts, chain-of-thought, and in-context learning baselines.
Significance. If the benchmark's synthetic vagueness faithfully reproduces the distribution of REs produced by non-expert users, the work identifies a practically important failure mode for current planners and supplies a lightweight mitigation that could improve accessibility for elderly and child users. The benchmark itself may become a useful testbed for future embodied agents.
major comments (1)
- [§3] §3 (REI-Bench construction): The modeling of vague REs is stated to be grounded in pragmatic theory, yet the manuscript supplies neither a user-study corpus of instructions from elderly or children nor any quantitative comparison of ambiguity metrics (candidate referents, context-dependence scores) between the generated set and real data. This assumption is load-bearing for both the reported 36.9% degradation magnitude and the claim that task-oriented context cognition achieves reliable SOTA mitigation in the target deployment scenario.
minor comments (2)
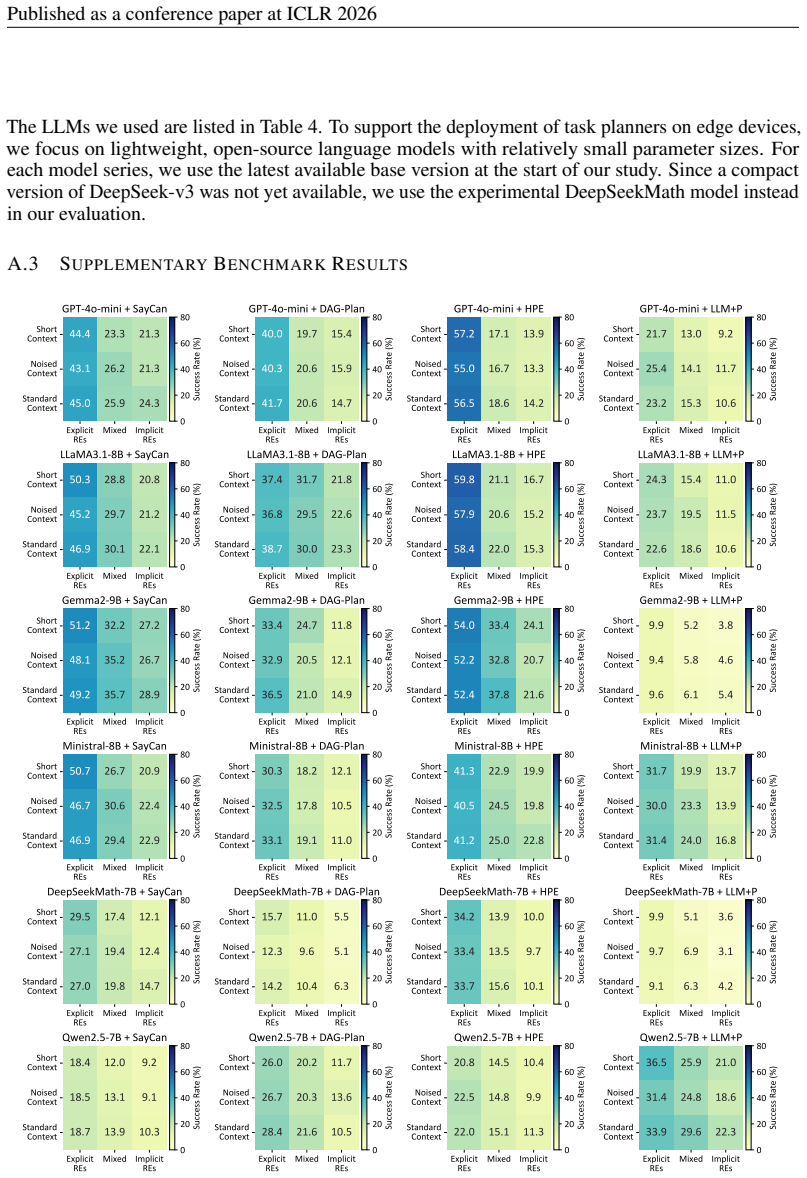
- [Table 2] Table 2 and §4.2: the success-rate tables would benefit from explicit reporting of the number of trials per condition and any statistical significance tests on the observed differences.
- [§5] §5 (Discussion): the claim that 'most failure cases stem from missing objects' would be strengthened by a breakdown of failure modes with counts rather than a qualitative statement.
Simulated Author's Rebuttal
We thank the referee for their detailed review and constructive comments on our manuscript. We address the major concern regarding the construction of REI-Bench below.
read point-by-point responses
-
Referee: §3 (REI-Bench construction): The modeling of vague REs is stated to be grounded in pragmatic theory, yet the manuscript supplies neither a user-study corpus of instructions from elderly or children nor any quantitative comparison of ambiguity metrics (candidate referents, context-dependence scores) between the generated set and real data. This assumption is load-bearing for both the reported 36.9% degradation magnitude and the claim that task-oriented context cognition achieves reliable SOTA mitigation in the target deployment scenario.
Authors: We agree that empirical validation with real user data would strengthen the benchmark. Our approach in §3 models vague REs by applying principles from pragmatic theory, such as the use of underspecified referring expressions that depend on shared context and the number of potential referents. This allows for systematic variation in ambiguity levels. However, we did not perform a dedicated user study with elderly or children participants in this work, relying instead on theoretical grounding to generate the test cases. The 36.9% degradation is measured within this controlled synthetic setting, which we believe captures key aspects of real-world vagueness as described in the linguistics literature. Similarly, the task-oriented context cognition method is evaluated on the benchmark and shows improvements over baselines. We will revise the manuscript to include a more explicit discussion of the modeling assumptions and a limitations section addressing the lack of direct real-data validation. revision: partial
- The lack of a user-study corpus from elderly or children and quantitative comparison of ambiguity metrics to real data.
Circularity Check
No significant circularity; empirical benchmark with independent evaluations
full rationale
The paper introduces REI-Bench by modeling vague referring expressions according to pragmatic theory, then runs direct experiments on LLM-based planners to measure success-rate degradation and compares a proposed task-oriented context cognition method against prompting baselines. All reported outcomes (36.9% drop, failure-mode observations, SOTA mitigation) are obtained from these external comparisons and observations rather than any self-defined quantities, fitted parameters renamed as predictions, or load-bearing self-citations. The derivation chain remains self-contained against the benchmark data and standard baselines.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Human instructions to robots frequently contain vagueness arising from referring expressions whose meanings depend on dialogue context and environment.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
we propose the first robot task planning benchmark that systematically models vague REs grounded in pragmatic theory (REI-Bench)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 1 Pith paper
-
TaskGround: Structured Executable Task Inference for Full-Scene Household Reasoning
TaskGround introduces a Ground-Infer-Execute framework for full-scene household reasoning that improves success rates on the FullHome benchmark and enables compact models to match larger ones at up to 18x lower token cost.
Reference graph
Works this paper leans on
-
[1]
Jae-Woo Choi, Youngwoo Yoon, Hyobin Ong, Jaehong Kim, and Minsu Jang
arXiv preprint arXiv:2311.15649. Jae-Woo Choi, Youngwoo Yoon, Hyobin Ong, Jaehong Kim, and Minsu Jang. Lota-bench: Benchmarking language-oriented task planners for embodied agents, 2024. arXiv preprint arXiv:2402.08178. Herbert H Clark. Bridging.Theoretical issues in natural language processing/Association for Computing Machinery, 1975. Fethiye Irmak Do ˘...
-
[2]
An Embodied Generalist Agent in 3D World
arXiv preprint arXiv:2311.12871. Wenlong Huang, Pieter Abbeel, Deepak Pathak, and Igor Mordatch. Language models as zero-shot planners: Extracting actionable knowledge for embodied agents. InICML, pp. 9118–9147, 2022a. Wenlong Huang, Fei Xia, Ted Xiao, Harris Chan, Jacky Liang, Pete Florence, Andy Zeng, Jonathan Tompson, Igor Mordatch, Yevgen Chebotar, Pi...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
The dialogue content of {Seed Instruction} should be included in Alice’s final instruction. Please have Alice state the request mentioned above only in the last sentence and refrain from making any other requests
-
[4]
Before making this request, Alice should mention some other requirements related to the {REs}
-
[5]
There should be six rounds of dialogue before this request. Each character’s lines should contain no fewer than 20 words, and no actions should be included for any character
-
[6]
Please do not output anything other than the dialogue
-
[7]
Please try to retain the words of{REs} themselves in the conversation, rather than replacing them with pronouns like ”it.” Below, I will give you an example:{Example} We used this prompt to expand a seed instruction into a full dialogue, which is shown below. 28 Published as a conference paper at ICLR 2026 Context Memory Generation Example Seed Instructio...
work page 2026
-
[8]
Please add content only within the dialogue without deleting any existing content or changing the order of the dialogue
-
[9]
Please do not change the number of turns in the dialogue.Please do not change the structure of the dialogue
-
[10]
{REs}” in the sentence “{Seed Instruction}
Please ensure the fluency of the dialogue. Please follow the requirements below for the adaptation. Associated Name Background:There is another member (a human) of the family named {Ambiguous Name}. Please have Alice mention him 3 times when discussing anything related to THE REFERENCE, but without changing the existing meaning of the conversation. Some d...
work page 2026
-
[11]
Please output the whole new dialogue
-
[12]
You must output the whole new dialogue, including all the sentences from Alice and Robot
-
[13]
{REs}” in the previous text, except for replacing “{REs}
Please retain every instance of “{REs}” in the previous text, except for replacing “{REs}” in the last sentence spoken by Alice
-
[14]
explicit REs & standard context,
You need to output the complete multi-turn dialogue, including the multiple turns of language from both Alice and the robot. Here is an example:{Example} Here is the dialogue:{Dialogue} Output: 30 Published as a conference paper at ICLR 2026 Context Memory Processing Human: Hey there, I’ve been thinking about what to do with the tomatoes we have. I really...
work page 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.