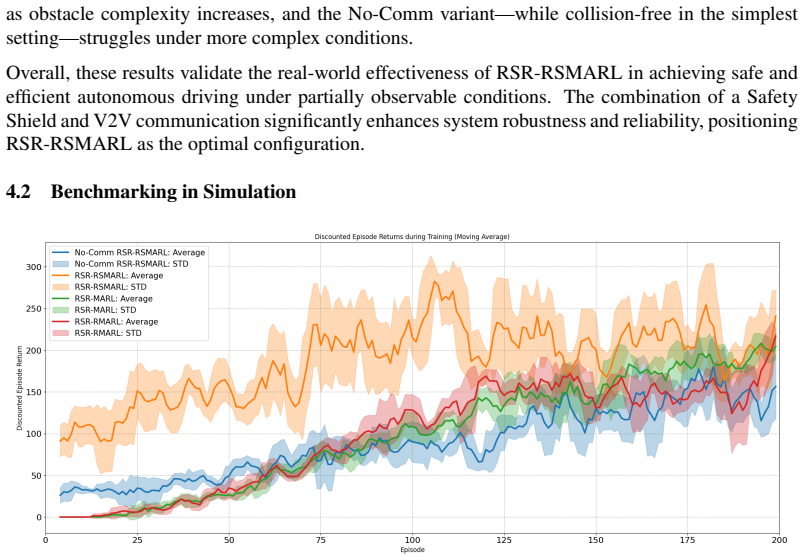
Robust and Safe Multi-Agent Reinforcement Learning with Communication for Autonomous Vehicles: From Simulation to Hardware
Pith reviewed 2026-05-19 11:15 UTC · model grok-4.3
The pith
A MARL framework trains driving policies in simulation and transfers them directly to physical vehicles while adding safety shields.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
RSR-RSMARL is a Robust and Safe MARL framework that supports Real-Sim-Real policy adaptation for multi-agent systems with communication among agents. It leverages state representations that include shared information among agents and action representations that consider real system complexities. The policy is trained with a robust MARL algorithm to enable zero-shot transfer to hardware despite the sim-to-real gap. A safety shield module using Control Barrier Functions provides safety guarantees for each individual agent. Experiments on 1/10th-scale autonomous vehicles with V2V communication show that the framework enhances driving safety and coordination across multiple configurations.
What carries the argument
The RSR-RSMARL framework, which combines robust MARL training, state and action representations that include shared V2V information and real-system details, Real-Sim-Real adaptation, and modular Control Barrier Function safety shields to support zero-shot hardware transfer.
If this is right
- Multi-agent vehicle teams can maintain individual safety guarantees while using shared communication to improve overall coordination.
- Zero-shot transfer from simulation becomes feasible for MARL policies when representations are designed around physical complexities rather than idealized models.
- Safety shields based on Control Barrier Functions can be added modularly without retraining the core policy for hardware use.
- The same framework supports testing across varied team sizes and scenarios once the representations and training are fixed.
Where Pith is reading between the lines
- The approach might scale to full-size vehicles if the state representations are adjusted for higher speeds and longer communication ranges.
- Similar combinations of robust training and barrier-function shields could apply to other multi-agent domains such as drone coordination or warehouse robots.
- If communication is intermittent, the framework's reliance on shared states would need explicit robustness extensions that the current experiments do not test.
- The method could be combined with online adaptation modules to handle larger distribution shifts not seen in the 1/10-scale tests.
Load-bearing premise
State and action representations that capture real system complexities, together with robust training, are enough to overcome sim-to-real discrepancies and model uncertainties so that the policies work directly on physical hardware.
What would settle it
Deploy the simulator-trained policies on the 1/10th-scale vehicles without any fine-tuning and observe whether safety or coordination breaks down in the presence of communication delays, model uncertainties, or dynamic obstacles.
Figures








read the original abstract
Deep multi-agent reinforcement learning (MARL) has been demonstrated effectively in simulations for multi-robot problems. For autonomous vehicles, the development of vehicle-to-vehicle (V2V) communication technologies provide opportunities to further enhance system safety. However, zero-shot transfer of simulator-trained MARL policies to dynamic hardware systems remains challenging, and how to leverage communication and shared information for MARL has limited demonstrations on hardware. This problem is challenged by discrepancies between simulated and physical states, system state and model uncertainties, practical shared information design, and the need for safety guarantees in both simulation and hardware. This paper designs RSR-RSMARL, a novel Robust and Safe MARL framework that supports Real-Sim-Real (RSR) policy adaptation for multi-agent systems with communication among agents, with both simulation and hardware demonstrations. RSR-RSMARL leverages state (includes shared state information among agents) and action representations considering real system complexities for MARL formulation. The MARL policy is trained with robust MARL algorithm to enable zero-shot transfer to hardware considering the sim-to-real gap. A safety shield module using Control Barrier Functions (CBFs) provides safety guarantee for each individual agent. Experimental results on 1/10th-scale autonomous vehicles with V2V communication demonstrate the ability of RSR-RSMARL framework to enhance driving safety and coordination across multiple configurations. These findings emphasize the importance of jointly designing robust policy representations and modular safety architectures to enable scalable, generalizable RSR transfer in multi-agent autonomy.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes RSR-RSMARL, a novel Robust and Safe Multi-Agent Reinforcement Learning framework with V2V communication for autonomous vehicles. It enables Real-Sim-Real (RSR) policy adaptation by designing state (including shared information) and action representations that account for real-system complexities, training via a robust MARL algorithm for zero-shot hardware transfer, and adding a Control Barrier Function (CBF) safety shield per agent. The central claim is that this yields enhanced driving safety and coordination, supported by both simulation results and hardware experiments on 1/10th-scale vehicles across multiple configurations.
Significance. If the hardware results hold with quantitative support, the work would be significant for multi-agent autonomy: it directly tackles sim-to-real transfer, communication design, and safety in a single modular architecture. The combination of representation choices, robust training, and CBF shielding offers a concrete path toward deployable MARL policies on physical vehicles, which remains rare in the literature.
major comments (2)
- [Abstract and Section 4] Abstract and Section 4: The manuscript asserts that 'Experimental results on 1/10th-scale autonomous vehicles with V2V communication demonstrate the ability of RSR-RSMARL framework to enhance driving safety and coordination,' yet supplies no quantitative metrics (success rates, collision counts, trajectory error, or statistical significance), no baselines, and no error analysis or training hyperparameters. This absence directly undermines the central empirical claim of effective zero-shot transfer.
- [Section 4 and RSR adaptation description] Section 4 and RSR adaptation description: No explicit quantification of the sim-to-real gap is provided (e.g., Wasserstein distance between state distributions, actuator latency mismatch, or sensor noise statistics). Without these measurements it is impossible to determine whether any observed hardware performance arises from the chosen state/action representations or from unstated environment simplifications or CBF intervention. This is load-bearing for the zero-shot guarantee.
minor comments (1)
- [Abstract] The expansion of the acronym RSR-RSMARL is not stated on first use; adding '(Robust and Safe Real-Sim-Real Multi-Agent Reinforcement Learning)' would improve readability.
Simulated Author's Rebuttal
Thank you for the opportunity to respond to the referee's report. We value the constructive criticism regarding the presentation of our hardware experiments and the quantification of the sim-to-real gap. We believe these points can be addressed through targeted revisions and additional analysis, which we outline below.
read point-by-point responses
-
Referee: [Abstract and Section 4] Abstract and Section 4: The manuscript asserts that 'Experimental results on 1/10th-scale autonomous vehicles with V2V communication demonstrate the ability of RSR-RSMARL framework to enhance driving safety and coordination,' yet supplies no quantitative metrics (success rates, collision counts, trajectory error, or statistical significance), no baselines, and no error analysis or training hyperparameters. This absence directly undermines the central empirical claim of effective zero-shot transfer.
Authors: We acknowledge the validity of this observation. The current manuscript emphasizes qualitative demonstrations and figures in Section 4 to illustrate the hardware performance. In the revision, we will incorporate quantitative metrics such as success rates, number of collisions, trajectory errors with standard deviations, and p-values for statistical significance. Baselines including non-communicative MARL and MARL without CBF will be added, along with a table summarizing hyperparameters and error analysis. This will provide the necessary quantitative support for the zero-shot transfer claims. revision: yes
-
Referee: [Section 4 and RSR adaptation description] Section 4 and RSR adaptation description: No explicit quantification of the sim-to-real gap is provided (e.g., Wasserstein distance between state distributions, actuator latency mismatch, or sensor noise statistics). Without these measurements it is impossible to determine whether any observed hardware performance arises from the chosen state/action representations or from unstated environment simplifications or CBF intervention. This is load-bearing for the zero-shot guarantee.
Authors: We agree that providing explicit measures of the sim-to-real gap would enhance the rigor of our claims. We will revise Section 4 to include an analysis of the sim-to-real discrepancies, such as statistical comparisons of state distributions (including Wasserstein distance where applicable), measured actuator latencies, and sensor noise levels from the hardware setup. We will also clarify how the designed state and action representations mitigate these gaps and evaluate the contribution of the CBF safety shield through ablation studies. These additions will better justify the zero-shot transfer performance. revision: yes
Circularity Check
No significant circularity; framework and transfer claims rest on external hardware validation
full rationale
The paper introduces RSR-RSMARL as a design combining state/action representations that incorporate real-system complexities, robust MARL training, and a modular CBF safety shield. Central claims are validated by direct hardware experiments on 1/10-scale vehicles with V2V communication across multiple configurations. No equations, fitted parameters, or results are shown to reduce by construction to quantities defined within the same experiment. No load-bearing self-citation chains or uniqueness theorems imported from prior author work appear in the derivation. The sim-to-real transfer is presented as an empirical outcome of the chosen representations and robust training rather than a tautological re-statement of inputs. This qualifies as self-contained against external benchmarks (hardware runs), warranting score 0.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Control barrier functions provide per-agent safety guarantees in both simulation and hardware
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
RSR-RSMARL leverages state (includes shared state information among agents) and action representations considering real system complexities for MARL formulation. The MARL policy is trained with robust MARL algorithm to enable zero-shot transfer to hardware considering the sim-to-real gap. A safety shield module using Control Barrier Functions (CBFs) provides safety guarantee for each individual agent.
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We adopt the kinematic bicycle model ... The CBF is the additional safety constraint ... min u ½∥u−uref∥² s.t. ∂h/∂t + Lf h + Lg h u ≥ −γh
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
U. I. J. P. Office. Saving lives with connectivity: A plan to accelerate v2x deployment non- binding contents, 2024
work page 2024
- [2]
-
[3]
N. Hyldmar, Y . He, and A. Prorok. A fleet of miniature cars for experiments in cooperative driving. Proceedings - IEEE International Conference on Robotics and Automation , 2019- May:3238–3244, 5 2019. ISSN 10504729. doi:10.1109/ICRA.2019.8794445
-
[4]
Active deformation through visual servoing of soft objects
A. Miller, K. Rim, P. Chopra, P. Kelkar, and M. Likhachev. Cooperative perception and lo- calization for cooperative driving. Proceedings - IEEE International Conference on Robotics and Automation, pages 1256–1262, 5 2020. ISSN 10504729. doi:10.1109/ICRA40945.2020. 9197463
- [5]
-
[6]
S. Han, H. Wang, S. Su, Y . Shi, and F. Miao. Stable and efficient shapley value-based reward reallocation for multi-agent reinforcement learning of autonomous vehicles. Proceedings - IEEE International Conference on Robotics and Automation, pages 8765–8771, 3 2022. ISSN 10504729. doi:10.1109/ICRA46639.2022.9811626. URL https://arxiv.org/abs/ 2203.06333v2
-
[7]
J. Rios-Torres and A. A. Malikopoulos. A survey on the coordination of connected and automated vehicles at intersections and merging at highway on-ramps. IEEE Transac- tions on Intelligent Transportation Systems , 18:1066–1077, 5 2017. ISSN 15249050. doi: 10.1109/TITS.2016.2600504
-
[8]
S. Han, S. Zhou, J. Wang, L. Pepin, C. Ding, J. Fu, and F. Miao. A multi-agent reinforcement learning approach for safe and efficient behavior planning of connected autonomous vehicles. IEEE Transactions on Intelligent Transportation Systems , 25(5):3654–3670, 2024. doi:10. 1109/TITS.2023.3336670
-
[9]
A. Mokhtarian, P. Scheffe, M. Kloock, S. Sch ¨afer, Heeseung Bang, Viet-Anh Le, Sangeet Ulhas, J. Betz, S. Wilson, S. Berman, A. Prorok, and B. Alrifaee. A survey on small-scale testbeds for connected and automated vehicles and robot swarms. 2024. doi:10.13140/RG.2. 2.16176.74248/1. URL https://arxiv.org/abs/2408.03539
-
[10]
Y . Shao, M. A. M. Zulkefli, Z. Sun, and P. Huang. Evaluating connected and autonomous vehicles using a hardware-in-the-loop testbed and a living lab. Transportation Research Part C: Emerging Technologies, 102:121–135, 5 2019. ISSN 0968-090X. doi:10.1016/J.TRC.2019. 03.010
-
[11]
C. Tang, B. Abbatematteo, J. Hu, R. Chandra, R. Mart´ın-Mart´ın, and P. Stone. Deep reinforce- ment learning for robotics: A survey of real-world successes. 8 2024. doi:10.1146/((please). URL https://arxiv.org/abs/2408.03539v2
- [12]
-
[13]
P. Werner, T. Seyde, P. Drews, T. M. Balch, I. Gilitschenski, W. Schwarting, G. Rosman, S. Karaman, and D. Rus. Dynamic multi-team racing: Competitive driving on 1/10-th scale vehicles via learning in simulation. In 7th Annual Conference on Robot Learning, 2023. URL https://openreview.net/forum?id=fvXFBCHVGn. 10
work page 2023
- [14]
- [15]
- [16]
-
[17]
M. T. Villasevil, A. Jain, V . Macha, J. Yuan, L. L. Ankile, A. Simeonov, P. Agrawal, and A. Gupta. Scaling robot-learning by crowdsourcing simulation environments
-
[18]
W. Zhao, J. P. Queralta, and T. Westerlund. Sim-to-real transfer in deep reinforcement learning for robotics: A survey. 2020 IEEE Symposium Series on Computational Intelligence, SSCI 2020, pages 737–744, 12 2020. doi:10.1109/SSCI47803.2020.9308468
- [19]
-
[20]
S. S. Sandha, L. Garcia, B. Balaji, F. Anwar, and M. Srivastava. Sim2real transfer for deep reinforcement learning with stochastic state transition delays. In J. Kober, F. Ramos, and C. Tomlin, editors, Proceedings of the 2020 Conference on Robot Learning , volume 155 of Proceedings of Machine Learning Research, pages 1066–1083. PMLR, 16–18 Nov 2021. URL ...
work page 2020
- [21]
-
[22]
I. ElSayed-Aly, S. Bharadwaj, C. Amato, R. Ehlers, U. Topcu, and L. Feng. Safe multi- agent reinforcement learning via shielding. In Proceedings of the 20th International Confer- ence on Autonomous Agents and MultiAgent Systems, AAMAS ’21, page 483–491, Richland, SC, 2021. International Foundation for Autonomous Agents and Multiagent Systems. ISBN 9781450383073
work page 2021
-
[23]
Z. Cai, H. Cao, W. Lu, L. Zhang, and H. Xiong. Safe multi-agent reinforcement learning through decentralized multiple control barrier functions, 2021
work page 2021
- [24]
-
[25]
S. He, S. Han, S. Su, S. Han, S. Zou, and F. Miao. Robust multi-agent reinforcement learning with state uncertainty. Transactions on Machine Learning Research, 2023
work page 2023
-
[26]
A. Mokhtarian, P. Scheffe, M. Kloock, S. Sch ¨afer, Heeseung Bang, Viet-Anh Le, Sangeet Ulhas, J. Betz, S. Wilson, S. Berman, A. Prorok, and B. Alrifaee. A survey on small-scale testbeds for connected and automated vehicles and robot swarms. 2024. doi:10.13140/RG.2.2. 16176.74248/1. URL https://rgdoi.net/10.13140/RG.2.2.16176.74248/1
-
[27]
Z. Qin, H. Wang, and X. Li. Ultra fast structure-aware deep lane detection. In Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceed- ings, Part XXIV 16, pages 276–291. Springer, 2020
work page 2020
-
[28]
Y . Li, D. Ma, Z. An, Z. Wang, Y . Zhong, S. Chen, and C. Feng. V2x-sim: Multi-agent col- laborative perception dataset and benchmark for autonomous driving. IEEE Robotics and Au- tomation Letters, 7:10914–10921, 2 2022. ISSN 23773766. doi:10.1109/LRA.2022.3192802. URL https://arxiv.org/abs/2202.08449v2. 11
- [29]
-
[30]
J. Kong, M. Pfeiffer, G. Schildbach, and F. Borrelli. Autonomous driving using model predic- tive control and a kinematic bicycle vehicle model. In Intelligent Vehicles Symposium, Seoul, Korea, 2015
work page 2015
-
[31]
Proximal Policy Optimization Algorithms
J. Schulman, F. Wolski, P. Dhariwal, A. Radford, and O. Klimov. Proximal policy optimization algorithms. arXiv preprint arXiv:1707.06347, 2017. 12 A Appendix A.1 Modeling and Algorithmic Details A.1.1 Vehicle Dynamic Model We adopt a kinematic bicycle model to describe the motion of each F1/10th vehicle. The state of each vehicle is represented asx = [X, ...
work page internal anchor Pith review Pith/arXiv arXiv 2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.