ReGA: Model-Based Safeguard for LLMs via Representation-Guided Abstraction
Pith reviewed 2026-05-19 11:29 UTC · model grok-4.3
The pith
LLMs contain low-dimensional safety-critical representations that allow construction of scalable abstract models for harm detection and jailbreak resistance.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
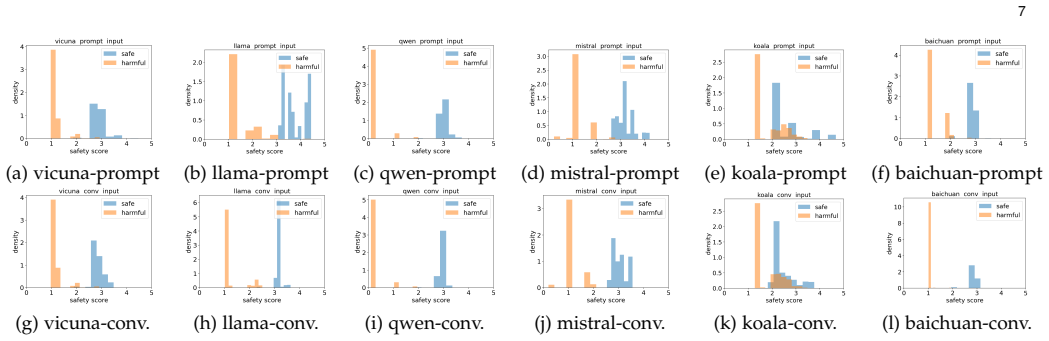
ReGA is a model-based analysis framework with Representation-Guided Abstraction to safeguard LLMs against harmful prompts and generations. By leveraging safety-critical representations, which are key directions in hidden states that indicate safety-related concepts, ReGA effectively narrows the scalability gap when developing the abstract model for safety modeling. Comprehensive evaluation shows that ReGA performs sufficiently well in distinguishing between safe and harmful inputs, achieving an AUROC of 0.975 at the prompt level and 0.985 at the conversation level. Additionally, ReGA exhibits robustness to real-world attacks and generalization across different safety perspectives, outperfor
What carries the argument
Representation-Guided Abstraction, which extracts key safety directions from LLM hidden states to reduce the full feature space into a smaller abstract model that still carries safety information for detection.
Load-bearing premise
Low-dimensional safety-critical representations exist inside LLMs and can be extracted and used to build an abstract model that keeps the safety information needed while avoiding too many missed threats or scaling problems.
What would settle it
Running ReGA on a fresh collection of jailbreaking prompts and finding its prompt-level AUROC drops below 0.9 or that it misses many harmful cases on a different LLM family would show the abstraction lost critical safety details.
Figures

read the original abstract
Large Language Models (LLMs) have achieved tremendous success in various tasks, yet concerns about their safety and security have emerged. In particular, they pose risks of generating harmful content and are vulnerable to jailbreaking attacks, creating unaddressed security issues regarding their deployments. In the context of software engineering for artificial intelligence (SE4AI) techniques, model-based analysis has demonstrated notable potential for analyzing and monitoring machine learning models, particularly in stateful deep neural networks. However, it suffers from scalability issues when extended to LLMs due to their vast feature spaces. In this paper, we aim to address the scalability issue of model-based analysis techniques for safeguarding LLM-scale models. Motivated by the recent discovery of low-dimensional safety-critical representations that emerged in LLMs, we propose ReGA, a model-based analysis framework with Representation-Guided Abstraction, to safeguard LLMs against harmful prompts and generations. By leveraging safety-critical representations, which are key directions in hidden states that indicate safety-related concepts, ReGA effectively narrows the scalability gap when developing the abstract model for safety modeling. Our comprehensive evaluation shows that ReGA performs sufficiently well in distinguishing between safe and harmful inputs, achieving an AUROC of 0.975 at the prompt level and 0.985 at the conversation level. Additionally, ReGA exhibits robustness to real-world attacks and generalization across different safety perspectives, outperforming existing safeguard paradigms in terms of interpretability and scalability. Overall, ReGA serves as an efficient and scalable solution to enhance LLM safety by integrating representation engineering with model-based abstraction, paving the way for new paradigms to utilize software insights for AI safety.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes ReGA, a model-based safeguard for LLMs that uses representation-guided abstraction. It identifies low-dimensional safety-critical directions in hidden states via linear probes, constructs a reduced state-space abstract model from those directions, and evaluates the resulting monitor for distinguishing safe versus harmful prompts and conversations. The central empirical claims are AUROC 0.975 (prompt level) and 0.985 (conversation level), plus robustness to real-world attacks and generalization across safety perspectives, while addressing the scalability limitations of prior model-based analysis techniques for LLMs.
Significance. If the reported performance and robustness hold under the held-out evaluations described, the work would demonstrate a practical integration of representation engineering with model-based abstraction that narrows the scalability gap for LLM safety monitoring. The approach offers improved interpretability over black-box safeguards and supplies concrete extraction and abstraction procedures, which are strengths for reproducibility in the SE4AI and AI safety literature.
major comments (2)
- [§4.1] §4.1 (Representation Extraction): The linear-probe procedure for identifying safety-critical directions is presented with a concrete layer-selection heuristic and held-out validation, but the manuscript does not report the number of positive/negative examples used to train the probes or any ablation on probe regularization; without these, it is difficult to rule out that the high AUROC partly reflects overfitting to the probe training distribution rather than robust safety concepts.
- [Table 3] Table 3 (Conversation-level results): The reported AUROC of 0.985 is given without confidence intervals or a statistical comparison to the strongest baseline; this weakens the claim that ReGA generalizes across safety perspectives and outperforms existing paradigms, especially since the central scalability argument rests on these performance numbers remaining high after abstraction.
minor comments (2)
- [§2] The abstract and §2 could more explicitly cite the specific prior works on low-dimensional safety representations that motivate the approach, rather than referring only to 'recent discovery'.
- [Figure 2] Figure 2 (abstraction diagram) would benefit from an explicit legend indicating which dimensions are retained versus discarded after the representation-guided reduction.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which helps strengthen the empirical rigor of the manuscript. We address each major comment below and will revise the paper accordingly.
read point-by-point responses
-
Referee: [§4.1] §4.1 (Representation Extraction): The linear-probe procedure for identifying safety-critical directions is presented with a concrete layer-selection heuristic and held-out validation, but the manuscript does not report the number of positive/negative examples used to train the probes or any ablation on probe regularization; without these, it is difficult to rule out that the high AUROC partly reflects overfitting to the probe training distribution rather than robust safety concepts.
Authors: We agree that reporting the training set sizes and regularization ablations would improve transparency and help rule out overfitting concerns. In the revised manuscript we will explicitly state the number of positive and negative examples used to train the probes (drawn from the safety datasets described in §4.1) and add a regularization ablation study showing that the extracted directions remain stable across reasonable hyper-parameter choices. revision: yes
-
Referee: [Table 3] Table 3 (Conversation-level results): The reported AUROC of 0.985 is given without confidence intervals or a statistical comparison to the strongest baseline; this weakens the claim that ReGA generalizes across safety perspectives and outperforms existing paradigms, especially since the central scalability argument rests on these performance numbers remaining high after abstraction.
Authors: We acknowledge that confidence intervals and statistical comparisons would make the performance claims more robust. We will add 95% bootstrap confidence intervals to all AUROC entries in Table 3 and include a statistical comparison (DeLong test) against the strongest baseline to support the generalization and outperformance statements. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper frames ReGA as an empirical method that extracts safety-critical directions via linear probes on hidden states and constructs an abstract state-space model from them, then reports AUROC metrics (0.975 prompt-level, 0.985 conversation-level) on held-out evaluations. These metrics are presented as measured outcomes rather than quantities forced by the extraction procedure itself. No equations or steps reduce by construction to fitted inputs, self-definitions, or load-bearing self-citations; the central claim remains independent of the reported numbers and is consistent with external benchmarks for representation engineering and model abstraction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Low-dimensional safety-critical representations exist in LLMs and indicate safety-related concepts
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
By leveraging safety-critical representations, which are low-dimensional directions emerging in hidden states that indicate safety-related concepts, ReGA effectively addresses the scalability issue when constructing the abstract model for safety modeling.
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanembed_strictMono_of_one_lt unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
we apply principal component analysis (PCA) reduction to construct the safety representations... K-Means to fit the concrete states
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 2 Pith papers
-
RACC: Representation-Aware Coverage Criteria for LLM Safety Testing
RACC defines six representation-aware coverage criteria that score jailbreak test suites by measuring activation of safety concepts extracted from LLM hidden states on a calibration set.
-
Secure LLM Fine-Tuning via Safety-Aware Probing
SAP locates safety-correlated directions via contrastive signals and perturbs hidden-state propagation with a lightweight probe to preserve safety while fine-tuning LLMs for task performance.
Reference graph
Works this paper leans on
-
[1]
OpenAI, “Gpt-4 technical report,” arXiv preprint arXiv:2303.08774, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[2]
Pretraining language models with human preferences,
T. Korbak et al. , “Pretraining language models with human preferences,” in ICML, 2023
work page 2023
- [3]
-
[4]
Large language models for mathematical reasoning: Progresses and challenges
J. Ahn et al., “Large language models for mathematical reasoning: Progresses and challenges,” arXiv preprint arXiv:2402.00157, 2024
-
[5]
DeepSeek-Coder: When the Large Language Model Meets Programming -- The Rise of Code Intelligence
D. Guo et al., “Deepseek-coder: When the large language model meets programming–the rise of code intelligence,” arXiv preprint arXiv:2401.14196, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[6]
A performance study of llm- generated code on leetcode,
T. Coignion et al. , “A performance study of llm- generated code on leetcode,” in EASE, 2024
work page 2024
-
[7]
RepairAgent: An Autonomous, LLM-Based Agent for Program Repair
I. Bouzenia et al. , “Repairagent: An autonomous, llm-based agent for program repair,” arXiv preprint arXiv:2403.17134, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[8]
Inferfix: End-to-end program repair with llms,
M. Jin et al., “Inferfix: End-to-end program repair with llms,” in FSE, 2023, pp. 1646–1656
work page 2023
-
[9]
Foundational challenges in assuring alignment and safety of large language models,
U. Anwar et al., “Foundational challenges in assuring alignment and safety of large language models,” Trans- actions on Machine Learning Research, 2024
work page 2024
-
[10]
The fusion of large language models and formal methods for trustworthy ai agents: A roadmap,
Y. Zhanget al., “The fusion of large language models and formal methods for trustworthy ai agents: A roadmap,” arXiv preprint arXiv:2412.06512, 2024
-
[11]
A survey on large language model (llm) security and privacy: The good, the bad, and the ugly,
Y. Yao et al., “A survey on large language model (llm) security and privacy: The good, the bad, and the ugly,” High-Confidence Computing, 2024
work page 2024
-
[12]
Combating misinformation in the age of llms: Opportunities and challenges,
C. Chen et al., “Combating misinformation in the age of llms: Opportunities and challenges,” AI Magazine, pp. 354–368, 2024
work page 2024
-
[13]
Harmbench: A standardized evalua- tion framework for automated red teaming and robust refusal,
M. Mazeika et al., “Harmbench: A standardized evalua- tion framework for automated red teaming and robust refusal,” in ICML, 2024
work page 2024
-
[14]
Decodingtrust: A comprehensive as- sessment of trustworthiness in gpt models
B. Wang et al. , “Decodingtrust: A comprehensive as- sessment of trustworthiness in gpt models.” in NeurIPS, 2023
work page 2023
-
[15]
TrustLLM: Trustworthiness in Large Language Models
L. Sun et al. , “Trustllm: Trustworthiness in large lan- guage models,” arXiv preprint arXiv:2401.05561, vol. 3, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[16]
Multitrust: A comprehensive benchmark towards trustworthy multimodal large language mod- els,
Y. o. Zhang, “Multitrust: A comprehensive benchmark towards trustworthy multimodal large language mod- els,” NeurIPS, 2024
work page 2024
-
[17]
X. Shen et al. , “”do anything now”: Characterizing and evaluating in-the-wild jailbreak prompts on large language models,” in CCS, 2023
work page 2023
-
[18]
Universal and Transferable Adversarial Attacks on Aligned Language Models
A. Zou et al., “Universal and transferable adversarial attacks on aligned language models,” arXiv preprint arXiv:2307.15043, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[19]
Jailbroken: How does llm safety training fail?
A. Wei et al., “Jailbroken: How does llm safety training fail?” in NeurIPS, 2023
work page 2023
-
[20]
Jailbreaking ChatGPT via Prompt Engineering: An Empirical Study
Y. Liu et al., “Jailbreaking chatgpt via prompt engineer- ing: An empirical study,”arXiv preprint arXiv:2305.13860, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[21]
Constitutional AI: Harmlessness from AI Feedback
Y. Bai et al., “Constitutional ai: Harmlessness from ai feedback,” arXiv preprint arXiv:2212.08073, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[22]
Safe rlhf: Safe reinforcement learning from human feedback,
J. Dai et al., “Safe rlhf: Safe reinforcement learning from human feedback,” in ICLR, 2024
work page 2024
-
[23]
Deepstellar: Model-based quantitative analysis of stateful deep learning systems,
X. Du et al. , “Deepstellar: Model-based quantitative analysis of stateful deep learning systems,” in FSE, 2019
work page 2019
-
[24]
Rnnrepair: Automatic rnn repair via model- based analysis,
X. Xie et al., “Rnnrepair: Automatic rnn repair via model- based analysis,” in ICML, 2021
work page 2021
-
[25]
Marble: Model-based robustness analysis of stateful deep learning systems,
X. Du et al., “Marble: Model-based robustness analysis of stateful deep learning systems,” in ASE, 2020
work page 2020
-
[26]
Deeparc: Modularizing neural networks for the model maintenance,
X. Ren et al., “Deeparc: Modularizing neural networks for the model maintenance,” in ICSE, 2023
work page 2023
-
[27]
Mosaic: Model-based safety analysis frame- work for ai-enabled cyber-physical systems,
X. Xie et al., “Mosaic: Model-based safety analysis frame- work for ai-enabled cyber-physical systems,” arXiv preprint arXiv:2305.03882, 2023
-
[28]
Archrepair: Block-level architecture- oriented repairing for deep neural networks,
H. Qi et al. , “Archrepair: Block-level architecture- oriented repairing for deep neural networks,” ACM Transactions on Software Engineering and Methodology , vol. 32, no. 5, pp. 1–31, 2023
work page 2023
-
[29]
Z. Wei et al. , “Weighted automata extraction and ex- planation of recurrent neural networks for natural language tasks,” Journal of Logical and Algebraic Methods in Programming, 2024
work page 2024
-
[30]
X. Huang et al., “A survey of safety and trustworthiness of deep neural networks: Verification, testing, adversar- ial attack and defence, and interpretability,” Computer Science Review, vol. 37, p. 100270, 2020
work page 2020
-
[31]
Software engineering for ai-based systems: a survey,
S. Mart ´ınez-Fern´andez et al. , “Software engineering for ai-based systems: a survey,” ACM Transactions on Software Engineering and Methodology (TOSEM), vol. 31, no. 2, pp. 1–59, 2022
work page 2022
-
[32]
Luna: A model-based universal analysis framework for large language models,
D. Song et al., “Luna: A model-based universal analysis framework for large language models,” IEEE Transac- tions on Software Engineering, 2024
work page 2024
-
[33]
Representation Engineering: A Top-Down Approach to AI Transparency
A. Zou et al. , “Representation engineering: A top- down approach to ai transparency,” arXiv preprint arXiv:2310.01405, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[34]
arXiv preprint arXiv:2402.05162 , year=
B. Wei et al., “Assessing the brittleness of safety align- ment via pruning and low-rank modifications,” arXiv preprint arXiv:2402.05162, 2024
- [35]
-
[36]
Adversarial representation engineering: A general model editing framework for large language models,
Y. Zhang et al., “Adversarial representation engineering: A general model editing framework for large language models,” arXiv preprint arXiv:2404.13752, 2024
-
[37]
A. Vaswani et al., “Attention is all you need,” in NeurIPS, 2017
work page 2017
-
[38]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
D. Guo et al. , “Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning,” arXiv preprint arXiv:2501.12948, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[39]
Evaluation of openai o1: Opportunities and challenges of agi,
T. Zhong et al., “Evaluation of openai o1: Opportunities and challenges of agi,” arXiv preprint arXiv:2409.18486, 2024
-
[40]
Improving language understanding by generative pre-training,
A. Radford et al., “Improving language understanding by generative pre-training,” 2018
work page 2018
-
[41]
Reinforcement Learning for LLM Post-Training: A Survey
Z. Wang et al., “A comprehensive survey of llm align- ment techniques: Rlhf, rlaif, ppo, dpo and more,” arXiv preprint arXiv:2407.16216, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[42]
Towards the worst-case robustness of large language models,
H. Chen et al., “Towards the worst-case robustness of large language models,” arXiv preprint arXiv:2501.19040, 2025
-
[43]
Position: Agent-specific trustworthiness risk as a research priority,
Z. Wei et al., “Position: Agent-specific trustworthiness risk as a research priority,” OpenReview preprint, 2025
work page 2025
-
[44]
Training a Helpful and Harmless Assistant with Reinforcement Learning from Human Feedback
Y. Bai et al., “Training a helpful and harmless assistant 12 with reinforcement learning from human feedback,” arXiv preprint arXiv:2204.05862, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[45]
Secure LLM Fine-Tuning via Safety-Aware Probing
C. Wu et al. , “Mitigating fine-tuning risks in llms via safety-aware probing optimization,” arXiv preprint arXiv:2505.16737, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[46]
Safety alignment should be made more than just a few tokens deep,
X. Qi et al. , “Safety alignment should be made more than just a few tokens deep,” in ICLR, 2024
work page 2024
-
[47]
Understanding pre-training and fine-tuning from loss landscape perspectives,
H. Chen et al., “Understanding pre-training and fine- tuning from loss landscape perspectives,” arXiv preprint arXiv:2505.17646, 2025
- [48]
-
[49]
Y. Zeng et al. , “How johnny can persuade llms to jailbreak them: Rethinking persuasion to challenge ai safety by humanizing llms,” in ACL, 2024
work page 2024
-
[50]
H. Jin et al., “Guard: Role-playing to generate natural- language jailbreakings to test guideline adherence of large language models,” arXiv preprint arXiv:2402.03299, 2024
-
[51]
Detecting Language Model Attacks with Perplexity
G. Alon et al., “Detecting language model attacks with perplexity,” arXiv preprint arXiv:2308.14132, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[52]
Baseline Defenses for Adversarial Attacks Against Aligned Language Models
N. Jain et al. , “Baseline defenses for adversarial at- tacks against aligned language models,” arXiv preprint arXiv:2309.00614, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[53]
A theoretical understanding of self- correction through in-context alignment,
Y. Wang et al. , “A theoretical understanding of self- correction through in-context alignment,” in NeurIPS, 2024
work page 2024
-
[54]
Defending chatgpt against jailbreak attack via self-reminders,
Y. Xie et al., “Defending chatgpt against jailbreak attack via self-reminders,” Nature Machine Intelligence, 2023
work page 2023
-
[55]
Jailbreak and guard aligned language mod- els with only few in-context demonstrations,
Z. Wei et al. , “Jailbreak and guard aligned language models with only few in-context demonstrations,” arXiv preprint arXiv:2310.06387, 2023
-
[56]
OR- Bench: An over-refusal benchmark for large language models
J. Cui et al., “Or-bench: An over-refusal benchmark for large language models,” arXiv preprint arXiv:2405.20947, 2024
-
[57]
Scalable defense against in-the-wild jailbreaking attacks with safety context retrieval,
T. Chen et al. , “Scalable defense against in-the-wild jailbreaking attacks with safety context retrieval,” arXiv preprint arXiv:2505.15753, 2025
-
[58]
Deep Inside Convolutional Networks: Visualising Image Classification Models and Saliency Maps
K. Simonyan et al., “Deep inside convolutional networks: Visualising image classification models and saliency maps,” arXiv preprint arXiv:1312.6034, 2013
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[59]
Grad-cam: Visual explanations from deep networks via gradient-based localization,
R. R. Selvaraju et al., “Grad-cam: Visual explanations from deep networks via gradient-based localization,” in ICCV, 2017
work page 2017
-
[60]
Linguistic regularities in continuous space word representations,
T. Mikolov et al., “Linguistic regularities in continuous space word representations,” in NAACL, 2013
work page 2013
-
[61]
Interpretable convolutional neural networks,
Q. Zhang et al. , “Interpretable convolutional neural networks,” in CVPR, 2018, pp. 8827–8836
work page 2018
-
[62]
Does representation matter? exploring intermediate layers in large language models,
O. Skean et al., “Does representation matter? exploring intermediate layers in large language models,” arXiv preprint arXiv:2412.09563, 2024
-
[63]
Improving steering vectors by tar- geting sparse autoencoder features,
S. Chalnev et al. , “Improving steering vectors by tar- geting sparse autoencoder features,” arXiv preprint arXiv:2411.02193, 2024
-
[64]
A. Stolfo et al. , “Improving instruction-following in language models through activation steering,” arXiv preprint arXiv:2410.12877, 2024
-
[65]
Advanc- ing llm safe alignment with safety representation ranking
T. Du et al., “Advancing llm safe alignment with safety representation ranking,” arXiv preprint arXiv:2505.15710, 2025
-
[66]
The hidden dimensions of llm alignment: A multi-dimensional safety analysis,
W. Pan et al., “The hidden dimensions of llm alignment: A multi-dimensional safety analysis,” arXiv preprint arXiv:2502.09674, 2025
-
[67]
Stanford alpaca: An instruction-following llama model,
R. Taoriet al., “Stanford alpaca: An instruction-following llama model,” https://github.com/tatsu-lab/stanford alpaca, 2023
work page 2023
-
[68]
Decision-guided weighted automata extraction from recurrent neural networks,
X. Zhang et al., “Decision-guided weighted automata extraction from recurrent neural networks,” in AAAI, 2021
work page 2021
-
[69]
Class-based n-gram models of natural language,
P . F. Brownet al., “Class-based n-gram models of natural language,” Computational linguistics, vol. 18, no. 4, pp. 467–480, 1992
work page 1992
- [70]
-
[71]
Judging llm-as-a-judge with mt-bench and chatbot arena,
L. Zheng et al., “Judging llm-as-a-judge with mt-bench and chatbot arena,” in NeurIPS, 2023
work page 2023
-
[72]
Llama 2: Open Foundation and Fine-Tuned Chat Models
H. Touvron et al., “Llama 2: Open foundation and fine- tuned chat models,” arXiv preprint arXiv:2307.09288 , 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[73]
J. Bai et al. , “Qwen technical report,” https://qwenlm.github.io/blog/qwen3/, 2023
work page 2023
-
[74]
Koala: A dialogue model for academic research,
X. Geng et al., “Koala: A dialogue model for academic research,” 2023
work page 2023
-
[75]
Baichuan 2: Open Large-scale Language Models
A. Yang et al., “Baichuan 2: Open large-scale language models,” arXiv preprint arXiv:2309.10305, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[76]
JailbreakBench: An Open Robustness Benchmark for Jailbreaking Large Language Models
P . Chao et al. , “Jailbreakbench: An open robustness benchmark for jailbreaking large language models,” arXiv preprint arXiv:2404.01318, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[77]
Lmsys-chat-1m: A large-scale real-world llm conversation dataset,
L. Zheng et al., “Lmsys-chat-1m: A large-scale real-world llm conversation dataset,” 2023
work page 2023
-
[78]
Rainbow teaming: Open-ended generation of diverse adversarial prompts,
M. Samvelyan et al., “Rainbow teaming: Open-ended generation of diverse adversarial prompts,” NeurIPS, 2024
work page 2024
-
[79]
Sorry-bench: Systematically evaluating large language model safety refusal,
T. Xie et al. , “Sorry-bench: Systematically evaluating large language model safety refusal,” in ICLR, 2025
work page 2025
-
[80]
Wildteaming at scale: From in-the-wild jailbreaks to (adversarially) safer language models,
L. Jiang et al., “Wildteaming at scale: From in-the-wild jailbreaks to (adversarially) safer language models,” 2024
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.