The threat of analytic flexibility in using large language models to simulate human data
Pith reviewed 2026-05-21 22:51 UTC · model grok-4.3
The pith
Different defensible choices when configuring large language models to generate synthetic human data can produce conflicting conclusions about how closely those data match real responses.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
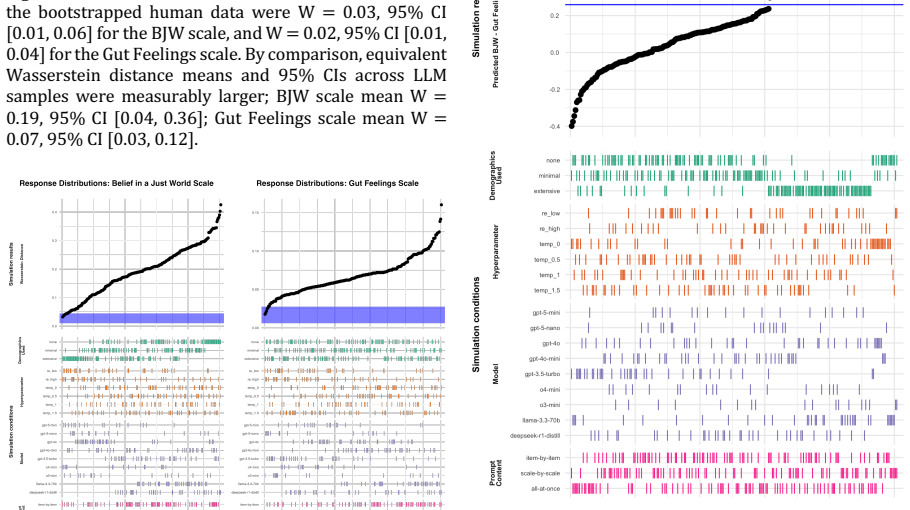
The central claim is that different defensible configuration choices can materially alter conclusions about the fidelity of silicon samples. Across 252 configurations for two social-psychological scales, performance varied substantially on recovering participant rankings, response distributions, and between-scale correlations, with strong performance on one criterion often coinciding with weak performance on another. Re-examining a prior published use case with 66 alternative configurations produced correlations between human and silicon association structures that ranged from r = .23 to r = .84.
What carries the argument
Analytic flexibility across LLM configuration choices for silicon samples; it carries the argument by demonstrating that these choices directly control the measured correspondence between synthetic and human data on multiple criteria.
If this is right
- Conclusions drawn from any single silicon-sample configuration are sensitive to the particular choices made.
- Researchers using silicon samples should examine multiple configurations rather than relying on one set of decisions.
- Attention to analytic flexibility is needed to avoid over- or under-estimating the usefulness of LLM-generated data in social science.
Where Pith is reading between the lines
- The same flexibility issue could affect other LLM applications in research that involve generating synthetic responses or judgments.
- One practical extension would be to develop shared checklists or default configuration sets that researchers can adopt to reduce unintended variation.
- Future work could test whether certain configuration dimensions, such as prompt format, exert more influence than others on fidelity metrics.
Load-bearing premise
The tested sets of 252 and 66 configurations are representative of the choices researchers would actually make when using silicon samples.
What would settle it
A new study that applies the same silicon-sample task to many additional defensible configurations and finds that all of them produce essentially the same conclusions about fidelity.
Figures


read the original abstract
Social scientists are now using large language models to create "silicon samples": synthetic datasets intended to stand in for human respondents. However, producing these samples requires many analytic choices, including model selection, sampling parameters, prompt format, and the amount of demographic or contextual information provided. Across two studies, I examine whether these choices materially affect correspondence between silicon samples and human data. In Study 1, I generated 252 silicon-sample configurations for a controlled case study using two social-psychological scales, evaluating whether configurations recovered participant rankings, response distributions, and between-scale correlations. Configurations varied substantially across all three criteria, and configurations that performed well on one dimension often performed poorly on another. In Study 2, I extended this analysis to a published silicon-sample use case by re-examining Argyle et al.'s (2023) Study 3 using 66 alternative configurations. Correlations between human and silicon association structures differed substantially across configurations, from r = .23 to r = .84. Taken together, the results from these studies demonstrate that different defensible configuration choices can materially alter conclusions about the fidelity of silicon samples. I call for greater attention to the threat of analytic flexibility in using silicon samples and outline strategies that researchers may adopt to reduce this threat.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript examines the threat of analytic flexibility when using large language models to generate 'silicon samples' as proxies for human respondents. Across two studies, it tests many configurations varying model choice, sampling parameters, prompt format, and demographic context. Study 1 uses 252 configurations on two social-psychological scales to evaluate recovery of participant rankings, response distributions, and between-scale correlations. Study 2 re-examines Argyle et al. (2023) Study 3 with 66 configurations and reports human-silicon association correlations ranging from r = .23 to r = .84. The central claim is that different defensible configuration choices can materially alter conclusions about the fidelity of silicon samples, warranting greater attention to this issue and strategies to mitigate it.
Significance. If the tested configurations represent plausible researcher choices, the results would highlight a serious methodological risk in the growing use of LLMs for simulating human data in social science, as wide variability in recovery metrics and correlations could lead to inconsistent or non-replicable findings. The paper's strength lies in its concrete empirical approach with large numbers of configurations and clear numerical ranges demonstrating outcome spread, which provides falsifiable evidence rather than abstract warnings. This could encourage adoption of sensitivity analyses or pre-specification of configurations if the representativeness concern is addressed.
major comments (1)
- [Study 1 and Study 2] Study 1 (252 configurations) and Study 2 (66 configurations): the manuscript varies model, sampling parameters, prompt format, and demographic context but supplies no explicit mapping to published silicon-sample studies or expert elicitation showing these choices reflect common or reasonable practice. This is load-bearing for the central claim that different defensible choices materially alter conclusions about fidelity, because the observed spreads (e.g., r = .23–.84) demonstrate variability under the selected conditions rather than under the actual distribution of analytic flexibility that threatens the method in practice.
minor comments (1)
- [Abstract] The abstract refers to 'two social-psychological scales' without naming them; specifying the scales (e.g., in the opening sentence of the abstract or §3) would improve immediate clarity.
Simulated Author's Rebuttal
We thank the referee for their constructive review and for recognizing the empirical approach and falsifiable evidence in our manuscript. We address the major comment below and have revised the manuscript to strengthen the link between tested configurations and published practices.
read point-by-point responses
-
Referee: [Study 1 and Study 2] Study 1 (252 configurations) and Study 2 (66 configurations): the manuscript varies model, sampling parameters, prompt format, and demographic context but supplies no explicit mapping to published silicon-sample studies or expert elicitation showing these choices reflect common or reasonable practice. This is load-bearing for the central claim that different defensible choices materially alter conclusions about fidelity, because the observed spreads (e.g., r = .23–.84) demonstrate variability under the selected conditions rather than under the actual distribution of analytic flexibility that threatens the method in practice.
Authors: We agree that an explicit mapping to published studies would make the relevance of the tested configurations clearer. In the revised manuscript we have added a dedicated subsection to the Methods section that systematically maps each varied dimension (model family and size, sampling temperature and top-p, prompt format variants, and demographic context levels) to specific choices reported in published silicon-sample studies, including Argyle et al. (2023), Park et al. (2023), and several other recent applications. A supplementary table now lists representative citations for each parameter setting. While we do not claim these 252 and 66 configurations exhaust the full distribution of researcher practice, the added documentation shows that the observed spreads arise from choices that have already appeared in the literature or are direct extensions of them. This supports the central claim that defensible analytic flexibility can materially change conclusions about fidelity without requiring a full expert elicitation survey, which lies outside the scope of the present work. revision: yes
Circularity Check
No circularity: empirical variability demonstrated directly from tested configurations
full rationale
The paper reports direct empirical comparisons of correlations and recovery metrics across 252 and 66 explicitly enumerated configurations of LLM silicon samples. No mathematical derivation, equation, or first-principles result is present that reduces to its inputs by construction, nor does any central claim rely on a self-citation chain, fitted parameter renamed as prediction, or ansatz smuggled via prior work. The observed spread in outcomes (e.g., r = .23–.84) follows immediately from the generation and evaluation steps described, rendering the demonstration self-contained against external benchmarks without circular reduction.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Standard assumptions of Pearson correlation, rank-order statistics, and distribution comparison hold for the evaluated metrics.
Forward citations
Cited by 2 Pith papers
-
LLM-Based Educational Simulation: Evaluating Temporal Student Persona Stability Across ADHD Profiles
LLM-simulated ADHD student personas show stable self-reported traits but behavioral drift in unscripted interactions that explicit task prompts fully eliminate.
-
LLM-Based Educational Simulation: Evaluating Temporal Student Persona Stability Across ADHD Profiles
LLM student personas with ADHD show stable self-reported traits at high intensity but behavioral drift in unscripted interactions that scripted prompts eliminate.
Reference graph
Works this paper leans on
-
[1]
Data Feature 1: Gut Feelings .40** [.29, .50]
-
[2]
Data Feature 2: BJW -.38** [-.49, -.27] -.24** [-.35, -.11]
-
[3]
Data Feature 2: Gut Feelings .12 [-.01, .24] .00 [-.13, .13] .12 [-.01, .24]
-
[4]
analog to humanlike cognitive selfhood
Data Feature 3 .27** [.14, .38] .14* [.02, .27] -.13* [-.25, -.00] .07 [-.06, .19] Note. M and SD are used to represent mean and standard deviation, respectively. Values in square brackets indicate the 95% confidence interval for each correlation. The confidence interval is a plausible range of population correlations that could have caused the sample cor...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.