Emergent Slow Thinking in LLMs as Inverse Tree Freezing
Pith reviewed 2026-05-18 12:39 UTC · model grok-4.3
The pith
RLVR causes LLMs to develop slow thinking by freezing concept networks into inverse trees.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central discovery is that slow thinking in LLMs emerges as the Concept Network freezes into multi-input, single-output directed inverse trees under RLVR dynamics. Path merging of compatible reasoning steps and frustrated competition among incompatible ones govern the evolution through nucleation, growth, and freezing stages. This structural picture reproduces the observed training dynamics of a 1.5B parameter LLM and generates specific predictions about lengthening reasoning chains, the timing dependence of supervised fine-tuning effects, and policy collapse under high frustration. The resulting Annealed-RLVR procedure, which applies brief SFT exactly at maximum frustration, delivers in-
What carries the argument
The Concept Network (CoNet), the Markov network of predictive states into which the autoregressive model compresses its prefix space, on which slow thinking acts as a random walk that RLVR then organizes into inverse trees via merging and competition.
If this is right
- Reasoning chains lengthen geometrically due to the sparse topology of the frozen inverse trees.
- Applying supervised fine-tuning after the trees have frozen causes catastrophic forgetting through rupture of bridge nodes.
- High frustration during training drives the policy to collapse.
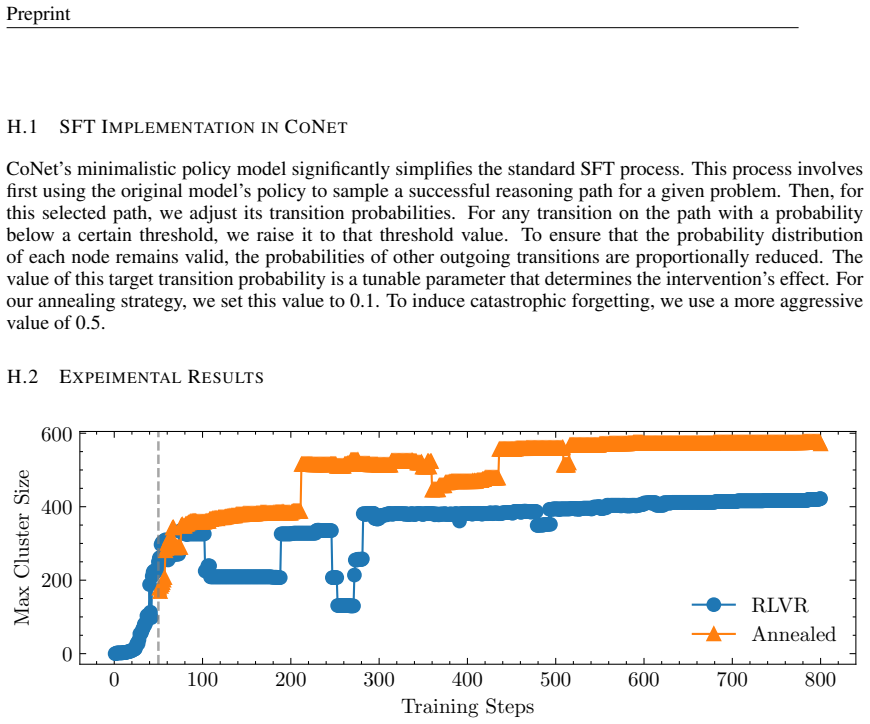
- Annealed-RLVR improves benchmark scores over standard RLVR on both in-distribution and out-of-distribution tasks, with gains largest at high sampling budgets where standard methods fail.
Where Pith is reading between the lines
- The timing of interventions relative to the freezing transition may generalize to other training regimes that aim to preserve or enhance reasoning structures.
- If the inverse-tree topology holds, then methods to directly encourage or measure such structures could accelerate the emergence of reliable multi-step reasoning.
- Connections to physical systems with similar nucleation and freezing dynamics might offer new ways to analyze or control LLM training trajectories.
Load-bearing premise
An autoregressive model's finite capacity must compress its exponentially large prefix space into a Markov network of predictive states on which reasoning unfolds as a random walk.
What would settle it
A direct test would be to check whether the internal concept activations or state transitions during RLVR training exhibit the predicted sequence of nucleation, growth, and freezing into inverse-tree structures; absence of such patterns or failure of Annealed-RLVR to outperform at high sampling budgets would challenge the account.
Figures












read the original abstract
Reinforcement learning with verifiable rewards (RLVR) enables large language models to acquire slow, multi-step reasoning from sparse final-answer signals. We provide a statistical-physics picture of this emergence. We show that an autoregressive model's finite capacity forces it to compress its exponentially large prefix space into a Markov network of predictive states, on which slow thinking unfolds as a random walk -- the Concept Network (CoNet) picture. Within CoNet, RLVR dynamics are governed by two mechanisms: merging of compatible paths and frustrated competition among incompatible ones. Together they drive the network through nucleation, growth, and freezing into multi-input, single-output directed inverse trees. The picture reproduces the training dynamics of a 1.5-billion-parameter LLM and yields three predictions: reasoning chains lengthen as a geometric necessity of sparse topology; SFT induces catastrophic forgetting through bridge-node rupture; and frustration drives policy collapse. Building on the structural timing inherent in inverse-tree freezing, we propose Annealed-RLVR -- a brief SFT intervention at the moment of maximum frustration. It outperforms standard RLVR on both in- and out-of-distribution benchmarks, with the largest gains at high sampling budgets where standard RLVR collapses. The same SFT applied after the trees freeze instead triggers catastrophic forgetting, isolating timing as the active ingredient.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that finite autoregressive capacity in LLMs compresses the prefix space into a Markovian Concept Network (CoNet) on which RLVR proceeds via path merging and frustrated competition, driving nucleation, growth, and freezing into multi-input single-output inverse trees. This framework is asserted to reproduce the training dynamics of a 1.5B-parameter LLM, explain phenomena such as lengthening reasoning chains and policy collapse, and motivate Annealed-RLVR (brief SFT at maximum frustration), which outperforms standard RLVR on in- and out-of-distribution benchmarks with largest gains at high sampling budgets.
Significance. If the central claims hold, the work supplies a statistical-physics account of slow-thinking emergence under RLVR, together with three falsifiable predictions and an empirically validated intervention (Annealed-RLVR) that improves performance where standard RLVR collapses. The combination of a structural explanation, reproduction of observed 1.5B-LLM curves, and a timing-specific SFT method would be a substantive contribution to the theory and practice of reasoning-oriented post-training.
major comments (4)
- [Abstract / CoNet introduction] Abstract and the section introducing the CoNet picture: the claim that finite autoregressive capacity 'necessarily' compresses the exponentially large prefix space into a Markov network of predictive states is asserted without derivation or explicit mapping from the autoregressive loss to the claimed network topology; it is therefore unclear whether this compression is required for the subsequent RLVR dynamics or inverse-tree freezing.
- [RLVR dynamics section] Abstract and the section on RLVR dynamics: no explicit mapping is supplied from the RLVR loss or policy gradient to the mechanisms of path merging and frustrated competition, nor is there a demonstration that observed length increases, forgetting, or collapse are geometric consequences of the inverse-tree topology rather than artifacts of the optimizer, reward sparsity, or sampling procedure.
- [Abstract] Abstract: the statement that the picture 'reproduces the training dynamics of a 1.5-billion-parameter LLM' is made without equations, error bars, exclusion criteria, or a description of how the free parameter (frustration timing threshold) was set, leaving open the possibility that the reproduction is post-hoc calibration rather than an independent test.
- [Annealed-RLVR section] The section describing Annealed-RLVR: the timing of the brief SFT intervention at 'maximum frustration' appears to be identified from the same training curves that the model is said to reproduce, creating a circularity concern for the claim that timing is the active ingredient.
minor comments (2)
- [Predictions section] Notation for 'inverse trees' and 'bridge-node rupture' should be defined more precisely with reference to the underlying graph structure before being used in the predictions.
- [Predictions] The manuscript would benefit from an explicit statement of the three predictions in a numbered list with corresponding experimental tests.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed report, which highlights both the potential significance of the work and areas where additional rigor would strengthen the presentation. We address each major comment below and outline the revisions we will make to the manuscript.
read point-by-point responses
-
Referee: [Abstract / CoNet introduction] Abstract and the section introducing the CoNet picture: the claim that finite autoregressive capacity 'necessarily' compresses the exponentially large prefix space into a Markov network of predictive states is asserted without derivation or explicit mapping from the autoregressive loss to the claimed network topology; it is therefore unclear whether this compression is required for the subsequent RLVR dynamics or inverse-tree freezing.
Authors: We agree that an explicit derivation would improve clarity. In the revised manuscript we will add a new subsection that starts from the autoregressive cross-entropy objective and shows how finite capacity induces equivalence classes of prefixes that share identical conditional distributions; these classes form the nodes of the Markovian Concept Network. We will also state explicitly that this compression is a prerequisite for RLVR to operate on a tractable state space rather than the full prefix tree. revision: yes
-
Referee: [RLVR dynamics section] Abstract and the section on RLVR dynamics: no explicit mapping is supplied from the RLVR loss or policy gradient to the mechanisms of path merging and frustrated competition, nor is there a demonstration that observed length increases, forgetting, or collapse are geometric consequences of the inverse-tree topology rather than artifacts of the optimizer, reward sparsity, or sampling procedure.
Authors: We will insert a new paragraph that maps the policy-gradient update directly to the two mechanisms: compatible trajectories that share reward signals reinforce the same nodes (path merging), while incompatible trajectories compete for limited node capacity (frustrated competition). We will further show, via a simple topological argument on the emerging inverse-tree structure, that chain lengthening and eventual collapse follow from the single-output constraint independently of the specific optimizer or reward sparsity, and we will contrast this with control experiments that vary sampling temperature. revision: yes
-
Referee: [Abstract] Abstract: the statement that the picture 'reproduces the training dynamics of a 1.5-billion-parameter LLM' is made without equations, error bars, exclusion criteria, or a description of how the free parameter (frustration timing threshold) was set, leaving open the possibility that the reproduction is post-hoc calibration rather than an independent test.
Authors: We will expand the experimental section with the precise functional form used to generate the model curves, report error bars across three independent runs, state the exclusion criteria for outlier seeds, and document that the frustration threshold was fixed by the theoretical prediction of the nucleation-to-freezing transition rather than by fitting to the observed curves. A sensitivity plot will be added to demonstrate robustness. revision: yes
-
Referee: [Annealed-RLVR section] The section describing Annealed-RLVR: the timing of the brief SFT intervention at 'maximum frustration' appears to be identified from the same training curves that the model is said to reproduce, creating a circularity concern for the claim that timing is the active ingredient.
Authors: We maintain that the timing is not circular: the theory predicts a distinct peak in frustration immediately prior to inverse-tree freezing, and the empirical curves are used only to locate this theoretically predicted moment for the intervention. The claim that timing is the active ingredient is supported by the post-freeze SFT control, which produces forgetting, and by the fact that the performance gains are measured on held-out in- and out-of-distribution benchmarks. We will add an explicit paragraph separating the theoretical timing prediction from its empirical application. revision: partial
Circularity Check
No significant circularity in CoNet derivation or inverse-tree predictions
full rationale
The paper derives the Concept Network (CoNet) as a direct consequence of finite autoregressive capacity compressing an exponentially large prefix space into a Markov network of predictive states, then analyzes RLVR dynamics via path merging and frustrated competition that nucleate, grow, and freeze into multi-input single-output inverse trees. This framework is used to interpret observed phenomena and to motivate the timing of the Annealed-RLVR SFT intervention at maximum frustration. The reproduction of 1.5B-LLM training dynamics serves as validation of the picture rather than a fitted input from which predictions are mechanically extracted; the three listed predictions (chain lengthening as geometric necessity, SFT-induced forgetting via bridge-node rupture, frustration-driven collapse) are presented as topological consequences independent of parameter tuning to the target curves. Benchmark outperformance at high sampling budgets supplies external falsifiability. No equation or step reduces by construction to its own inputs, and the central claim retains independent content beyond the data it reproduces.
Axiom & Free-Parameter Ledger
free parameters (1)
- frustration timing threshold
axioms (1)
- domain assumption Finite-capacity autoregressive models compress exponentially large prefix spaces into Markov networks of predictive states
invented entities (2)
-
Concept Network (CoNet)
no independent evidence
-
Inverse trees
no independent evidence
Reference graph
Works this paper leans on
-
[1]
P. W. Anderson. More Is Different . Science, 177 0 (4047): 0 393--396, August 1972. doi:10.1126/science.177.4047.393
-
[2]
Emergence of scaling in random networks
Albert-L \'a szl \'o Barab \'a si and R \'e ka Albert. Emergence of scaling in random networks. science, 286 0 (5439): 0 509--512, 1999
work page 1999
-
[3]
verl: Volcano engine reinforcement learning for llms
ByteDance Seed Team and verl community . verl: Volcano engine reinforcement learning for llms. https://github.com/volcengine/verl
-
[4]
Iteration head: A mechanistic study of chain-of-thought, 2024
Vivien Cabannes, Charles Arnal, Wassim Bouaziz, Alice Yang, Francois Charton, and Julia Kempe. Iteration head: A mechanistic study of chain-of-thought, 2024. URL https://arxiv.org/abs/2406.02128
-
[5]
Learning-at-criticality in large language models for quantum field theory and beyond, 2025
Xiansheng Cai, Sihan Hu, Tao Wang, Yuan Huang, Pan Zhang, Youjin Deng, and Kun Chen. Learning-at-criticality in large language models for quantum field theory and beyond, 2025. URL https://arxiv.org/abs/2506.03703
-
[6]
Zhipeng Chen, Xiaobo Qin, Youbin Wu, Yue Ling, Qinghao Ye, Wayne Xin Zhao, and Guang Shi. Pass@k training for adaptively balancing exploration and exploitation of large reasoning models, 2025. URL https://arxiv.org/abs/2508.10751
-
[7]
Reasoning with Exploration: An Entropy Perspective
Daixuan Cheng, Shaohan Huang, Xuekai Zhu, Bo Dai, Wayne Xin Zhao, Zhenliang Zhang, and Furu Wei. Reasoning with exploration: An entropy perspective on reinforcement learning for llms, 2025. URL https://arxiv.org/abs/2506.14758
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[8]
The Entropy Mechanism of Reinforcement Learning for Reasoning Language Models
Ganqu Cui, Yuchen Zhang, Jiacheng Chen, Lifan Yuan, Zhi Wang, Yuxin Zuo, Haozhan Li, Yuchen Fan, Huayu Chen, Weize Chen, Zhiyuan Liu, Hao Peng, Lei Bai, Wanli Ouyang, Yu Cheng, Bowen Zhou, and Ning Ding. The entropy mechanism of reinforcement learning for reasoning language models, 2025. URL https://arxiv.org/abs/2505.22617
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[9]
Improved supervised fine-tuning for large language models to mitigate catastrophic forgetting, 2025
Fei Ding and Baiqiao Wang. Improved supervised fine-tuning for large language models to mitigate catastrophic forgetting, 2025. URL https://arxiv.org/abs/2506.09428
-
[10]
How to think step-by-step: A mechanistic understanding of chain-of-thought reasoning, 2024
Subhabrata Dutta, Joykirat Singh, Soumen Chakrabarti, and Tanmoy Chakraborty. How to think step-by-step: A mechanistic understanding of chain-of-thought reasoning, 2024. URL https://arxiv.org/abs/2402.18312
-
[11]
Subgraph centrality in complex networks
Ernesto Estrada and Naomichi Hatano. Subgraph centrality in complex networks. Physical Review E, 77 0 (3): 0 036111, 2008
work page 2008
-
[12]
Concise reasoning via reinforcement learning, 2025
Mehdi Fatemi, Banafsheh Rafiee, Mingjie Tang, and Kartik Talamadupula. Concise reasoning via reinforcement learning, 2025. URL https://arxiv.org/abs/2504.05185
-
[13]
Mitigating forgetting in llm supervised fine-tuning and preference learning, 2025
Heshan Fernando, Han Shen, Parikshit Ram, Yi Zhou, Horst Samulowitz, Nathalie Baracaldo, and Tianyi Chen. Mitigating forgetting in llm supervised fine-tuning and preference learning, 2025. URL https://arxiv.org/abs/2410.15483
-
[14]
A complex network approach to topic models, 2023
Javier Ferrando, Mehran Rezagholizadeh, and VS Dinesh Chandra Prabhu. A complex network approach to topic models, 2023
work page 2023
-
[15]
Michael E. Fisher and Michael N. Barber. Scaling Theory for Finite-Size Effects in the Critical Region . Physical Review Letters, 28 0 (23): 0 1516--1519, June 1972. doi:10.1103/PhysRevLett.28.1516
-
[16]
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, Xiaokang Zhang, Xingkai Yu, Yu Wu, Z. F. Wu, Zhibin Gou, Zhihong Shao, Zhuoshu Li, Ziyi Gao, Aixin Liu, Bing Xue, Bingxuan Wang, Bochao Wu, Bei Feng, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chong Ruan, Damai Dai, Deli Chen, Dongjie Ji, ...
-
[17]
Jujie He, Jiacai Liu, Chris Yuhao Liu, Rui Yan, Chaojie Wang, Peng Cheng, Xiaoyu Zhang, Fuxiang Zhang, Jiacheng Xu, Wei Shen, Siyuan Li, Liang Zeng, Tianwen Wei, Cheng Cheng, Bo An, Yang Liu, and Yahui Zhou. Skywork open reasoner series. https://capricious-hydrogen-41c.notion.site/Skywork-Open-Reaonser-Series-1d0bc9ae823a80459b46c149e4f51680, 2025. Notion Blog
work page 2025
-
[18]
Measuring mathematical problem solving with the math dataset
Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. Measuring mathematical problem solving with the math dataset. NeurIPS, 2021
work page 2021
-
[19]
RL Fine-Tuning Heals OOD Forgetting in SFT
Hangzhan Jin, Sitao Luan, Sicheng Lyu, Guillaume Rabusseau, Reihaneh Rabbany, Doina Precup, and Mohammad Hamdaqa. Rl fine-tuning heals ood forgetting in sft, 2025. URL https://arxiv.org/abs/2509.12235
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[20]
Daniel Kahneman. Thinking, fast and slow. Farrar, Straus and Giroux, 2011
work page 2011
-
[21]
Optimization by simulated annealing
Scott Kirkpatrick, C Daniel Gelatt Jr, and Mario P Vecchi. Optimization by simulated annealing. science, 220 0 (4598): 0 671--680, 1983
work page 1983
-
[22]
Computerrl: Scaling end-to-end online reinforcement learning for computer use agents, 2025
Hanyu Lai, Xiao Liu, Yanxiao Zhao, Han Xu, Hanchen Zhang, Bohao Jing, Yanyu Ren, Shuntian Yao, Yuxiao Dong, and Jie Tang. Computerrl: Scaling end-to-end online reinforcement learning for computer use agents, 2025. URL https://arxiv.org/abs/2508.14040
-
[23]
Solving quantitative reasoning problems with language models, 2022
Aitor Lewkowycz, Anders Andreassen, David Dohan, Ethan Dyer, Henryk Michalewski, Vinay Ramasesh, Ambrose Slone, Cem Anil, Imanol Schlag, Theo Gutman-Solo, Yuhuai Wu, Behnam Neyshabur, Guy Gur-Ari, and Vedant Misra. Solving quantitative reasoning problems with language models, 2022
work page 2022
-
[24]
Revisiting catastrophic forgetting in large language model tuning
Hongyu Li, Liang Ding, Meng Fang, and Dacheng Tao. Revisiting catastrophic forgetting in large language model tuning. In Yaser Al-Onaizan, Mohit Bansal, and Yun-Nung Chen (eds.), Findings of the Association for Computational Linguistics: EMNLP 2024, pp.\ 4297--4308, Miami, Florida, USA, November 2024. Association for Computational Linguistics. doi:10.1865...
-
[25]
The emergence of essential structures in supervised learning
Huan Li, Ziqiao Liu, Yiding Li, and Qing-Fu Zhang. The emergence of essential structures in supervised learning. Nature Communications, 14 0 (1): 0 6483, 2023
work page 2023
-
[26]
Zhizhong Li and Derek Hoiem. Learning without forgetting, 2017. URL https://arxiv.org/abs/1606.09282
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[27]
Network dynamics-based framework for understanding deep neural networks, 2025
Yuchen Lin, Yong Zhang, Sihan Feng, and Hong Zhao. Network dynamics-based framework for understanding deep neural networks, 2025. URL https://arxiv.org/abs/2501.02436
-
[28]
Understanding R1-Zero-Like Training : A Critical Perspective , March 2025
Zichen Liu, Changyu Chen, Wenjun Li, Penghui Qi, Tianyu Pang, Chao Du, Wee Sun Lee, and Min Lin. Understanding R1-Zero-Like Training : A Critical Perspective , March 2025
work page 2025
-
[29]
Tang, Manan Roongta, Colin Cai, Jeffrey Luo, Li Erran Li, Raluca Ada Popa, and Ion Stoica
Michael Luo, Sijun Tan, Justin Wong, Xiaoxiang Shi, William Y. Tang, Manan Roongta, Colin Cai, Jeffrey Luo, Li Erran Li, Raluca Ada Popa, and Ion Stoica. Deepscaler: Surpassing o1-preview with a 1.5b model by scaling rl. https://pretty-radio-b75.notion.site/DeepScaleR-Surpassing-O1-Preview-with-a-1-5B-Model-by-Scaling-RL-19681902c1468005bed8ca303013a4e2, ...
work page 2025
-
[30]
Self-refine: Iterative refinement with self-feedback
Aman Madaan, Niket Tandon, Prakhar Gupta, Kevin Hallinan, Luyu Gao, Sarah Wiegreffe, Uri Alon, Peter Andersen, Ishan Misra, Shubham Singh, et al. Self-refine: Iterative refinement with self-feedback. In Advances in Neural Information Processing Systems, volume 36, 2023
work page 2023
-
[31]
Topology of reasoning: Understanding large reasoning models through reasoning graph properties, 2025
Gouki Minegishi, Hiroki Furuta, Takeshi Kojima, Yusuke Iwasawa, and Yutaka Matsuo. Topology of reasoning: Understanding large reasoning models through reasoning graph properties, 2025
work page 2025
-
[32]
Grokking: Generalization Beyond Overfitting on Small Algorithmic Datasets
Alethea Power, Yuri Burda, Harri Edwards, Igor Babuschkin, and Vedant Misra. Grokking: Generalization beyond overfitting on small algorithmic datasets, 2022. URL https://arxiv.org/abs/2201.02177
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[33]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, Y. K. Li, Y. Wu, and Daya Guo. DeepSeekMath : Pushing the Limits of Mathematical Reasoning in Open Language Models , April 2024. URL http://arxiv.org/abs/2402.03300. arXiv:2402.03300 [cs]
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[34]
RL's Razor: Why Online Reinforcement Learning Forgets Less
Idan Shenfeld, Jyothish Pari, and Pulkit Agrawal. Rl's razor: Why online reinforcement learning forgets less, 2025. URL https://arxiv.org/abs/2509.04259
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[35]
HybridFlow: A Flexible and Efficient RLHF Framework
Guangming Sheng, Chi Zhang, Zilingfeng Ye, Xibin Wu, Wang Zhang, Ru Zhang, Yanghua Peng, Haibin Lin, and Chuan Wu. Hybridflow: A flexible and efficient rlhf framework. arXiv preprint arXiv: 2409.19256, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[36]
Reflexion: An autonomous agent with dynamic memory and self-reflection, 2023
Noah Shinn, Beck Labash, and Roger Grosse. Reflexion: An autonomous agent with dynamic memory and self-reflection, 2023
work page 2023
-
[37]
Introduction to phase transitions and critical phenomena
Harry Eugene Stanley and Guenter Ahlers. Introduction to phase transitions and critical phenomena. American Journal of Physics, 40: 0 927--928, 1972. URL https://api.semanticscholar.org/CorpusID:10416417
work page 1972
-
[38]
Kimi k1.5: Scaling Reinforcement Learning with LLMs , March 2025
Kimi Team, Angang Du, Bofei Gao, Bowei Xing, Changjiu Jiang, et al. Kimi k1.5: Scaling Reinforcement Learning with LLMs , March 2025
work page 2025
-
[39]
A multiscale visualization of attention in the transformer model, 2019
Jesse Vig. A multiscale visualization of attention in the transformer model, 2019
work page 2019
-
[40]
Xinyi Wang, Alfonso Amayuelas, Kexun Zhang, Liangming Pan, Wenhu Chen, and William Yang Wang. Understanding reasoning ability of language models from the perspective of reasoning paths aggregation, 2024. URL https://arxiv.org/abs/2402.03268
-
[41]
Self-consistency improves chain of thought reasoning in language models, 2022
Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc Le, Ed Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou. Self-consistency improves chain of thought reasoning in language models, 2022
work page 2022
-
[42]
Collective dynamics of ‘small-world’networks
Duncan J Watts and Steven H Strogatz. Collective dynamics of ‘small-world’networks. nature, 393 0 (6684): 0 440--442, 1998
work page 1998
-
[43]
Chain-of-thought prompting elicits reasoning in large language models
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Ed Chi, Quoc Le, and Denny Zhou. Chain-of-thought prompting elicits reasoning in large language models. In Advances in Neural Information Processing Systems, volume 35, pp.\ 24824--24837, 2022
work page 2022
-
[44]
K. G. Wilson and John B. Kogut. The Renormalization group and the epsilon expansion . Phys. Rept., 12: 0 75--199, 1974. doi:10.1016/0370-1573(74)90023-4
-
[45]
Kenneth G. Wilson. The renormalization group and critical phenomena. Reviews of Modern Physics, 55 0 (3): 0 583--600, July 1983. doi:10.1103/RevModPhys.55.583
-
[46]
Towards system 2 reasoning in llms: Learning how to think with meta chain-of-thought, 2025
Violet Xiang, Charlie Snell, Kanishk Gandhi, Alon Albalak, Anikait Singh, Chase Blagden, Duy Phung, Rafael Rafailov, Nathan Lile, Dakota Mahan, Louis Castricato, Jan-Philipp Franken, Nick Haber, and Chelsea Finn. Towards system 2 reasoning in llms: Learning how to think with meta chain-of-thought, 2025. URL https://arxiv.org/abs/2501.04682
-
[47]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, et al. Qwen3 technical report. arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[48]
Tree of thoughts: Deliberate problem solving with large language models, 2023
Shunyu Yao, Dian Yu, Jeffrey Zhao, Izhak Sha, Silvio Savarese, and an an. Tree of thoughts: Deliberate problem solving with large language models, 2023
work page 2023
-
[49]
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xiaochen Zuo, et al. DAPO : An Open - Source LLM Reinforcement Learning System at Scale , March 2025. URL http://arxiv.org/abs/2503.14476. arXiv:2503.14476 [cs] version: 1
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[50]
Does Reinforcement Learning Really Incentivize Reasoning Capacity in LLMs Beyond the Base Model?
Yang Yue, Zhiqi Chen, Rui Lu, Andrew Zhao, Zhaokai Wang, Yang Yue, Shiji Song, and Gao Huang. Does reinforcement learning really incentivize reasoning capacity in llms beyond the base model?, 2025. URL https://arxiv.org/abs/2504.13837
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[51]
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION format.date year duplicate empty "emp...
-
[52]
\@ifxundefined[1] #1\@undefined \@firstoftwo \@secondoftwo \@ifnum[1] #1 \@firstoftwo \@secondoftwo \@ifx[1] #1 \@firstoftwo \@secondoftwo [2] @ #1 \@temptokena #2 #1 @ \@temptokena \@ifclassloaded agu2001 natbib The agu2001 class already includes natbib coding, so you should not add it explicitly Type <Return> for now, but then later remove the command n...
-
[53]
\@lbibitem[] @bibitem@first@sw\@secondoftwo \@lbibitem[#1]#2 \@extra@b@citeb \@ifundefined br@#2\@extra@b@citeb \@namedef br@#2 \@nameuse br@#2\@extra@b@citeb \@ifundefined b@#2\@extra@b@citeb @num @parse #2 @tmp #1 NAT@b@open@#2 NAT@b@shut@#2 \@ifnum @merge>\@ne @bibitem@first@sw \@firstoftwo \@ifundefined NAT@b*@#2 \@firstoftwo @num @NAT@ctr \@secondoft...
-
[54]
@open @close @open @close and [1] URL: #1 \@ifundefined chapter * \@mkboth \@ifxundefined @sectionbib * \@mkboth * \@mkboth\@gobbletwo \@ifclassloaded amsart * \@ifclassloaded amsbook * \@ifxundefined @heading @heading NAT@ctr thebibliography [1] @ \@biblabel @NAT@ctr \@bibsetup #1 @NAT@ctr @ @openbib .11em \@plus.33em \@minus.07em 4000 4000 `\.\@m @bibit...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.