When a Robot is More Capable than a Human: Learning from Constrained Demonstrators
Pith reviewed 2026-05-18 08:29 UTC · model grok-4.3
The pith
Robots can learn better policies than their constrained human demonstrators by inferring state-only rewards and exploring efficient trajectories.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By extracting a state-only reward signal from constrained demonstrations and using temporal interpolation to self-label rewards for unseen states, an agent can move beyond imitating expert actions and discover superior trajectories that complete the task more efficiently.
What carries the argument
State-only reward inferred from demonstrations, with temporal interpolation to label unknown states and enable exploration of better trajectories.
If this is right
- The robot finishes the task in substantially less time than behavioral cloning.
- Fewer training samples are needed to reach a working policy.
- The method works on physical hardware with real constrained inputs such as 2D joystick control.
- Policies can exceed the expert's demonstrated actions instead of being bounded by them.
Where Pith is reading between the lines
- The same reward-inference step could be applied to other interfaces that force experts into lower-dimensional control spaces.
- It raises the possibility that reward shaping from imperfect human input becomes a general way to let robots exceed human physical limits in teleoperation settings.
- Testing whether the interpolated rewards remain accurate when the task has more complex dynamics would clarify how far the self-labeling step generalizes.
Load-bearing premise
The demonstrations contain enough information for a state-only reward to accurately reflect task progress, and temporal interpolation reliably assigns correct rewards to states the expert never reached.
What would settle it
Running the method on the WidowX arm and finding that the learned trajectories take as long or longer than the original constrained demonstrations, or that the interpolated rewards lead the robot into dead ends, would show the approach does not produce better policies.
Figures







read the original abstract
Learning from demonstrations enables experts to teach robots complex tasks using interfaces such as kinesthetic teaching, joystick control, and sim-to-real transfer. However, these interfaces often constrain the expert's ability to demonstrate optimal behavior due to indirect control, setup restrictions, and hardware safety. For example, a joystick can move a robotic arm only in a 2D plane, even though the robot operates in a higher-dimensional space. As a result, the demonstrations collected by constrained experts lead to suboptimal performance of the learned policies. This raises a key question: Can a robot learn a better policy than the one demonstrated by a constrained expert? We address this by allowing the agent to go beyond direct imitation of expert actions and explore shorter and more efficient trajectories. We use the demonstrations to infer a state-only reward signal that measures task progress, and self-label reward for unknown states using temporal interpolation. Our approach outperforms common imitation learning in both sample efficiency and task completion time. On a real WidowX robotic arm, it completes the task in 12 seconds, 10x faster than behavioral cloning, as shown in real-robot videos on https://sites.google.com/view/constrainedexpert .
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a method for learning robot policies from constrained expert demonstrations (e.g., via joystick or kinesthetic teaching) by first inferring a state-only reward function that measures task progress directly from the demonstrations, then using temporal interpolation to self-label rewards for states not visited in the demonstrations. This enables the agent to explore shorter and more efficient trajectories than those shown by the constrained expert. The approach is evaluated against common imitation learning baselines, with a claimed real-robot result on a WidowX arm completing the task in 12 seconds (10x faster than behavioral cloning).
Significance. If the central construction holds, the work addresses a practically important gap in imitation learning: how to extract better-than-demonstrated behavior when experts are limited by hardware or interface constraints. The real-robot timing result, if reproducible with proper controls, would be a concrete strength. The paper also ships a public video link, which aids verification.
major comments (2)
- [§3.2] §3.2 (Reward Inference and Temporal Interpolation): The method assigns rewards to unseen states via linear interpolation along the time axis of the constrained demonstration trajectories. This implicitly assumes that time-to-goal along the expert path is a monotonic proxy for task progress. For constrained experts whose paths are indirect or non-uniform, states visited by shorter optimal trajectories can receive erroneously low interpolated rewards, undermining the exploration advantage claimed in the abstract. This assumption is load-bearing for the central claim that the robot can outperform the demonstrator.
- [§4] §4 (Experiments): The abstract states a specific 12-second real-robot timing result and 10x improvement over behavioral cloning, yet the manuscript provides insufficient detail on trial count, variance, statistical tests, exact baseline implementations (including whether any IRL methods beyond BC were tested), and the precise form of the inferred reward function used at deployment. Without these, it is difficult to determine whether the reported outperformance is robust or an artifact of the particular task and setup.
minor comments (2)
- [Abstract] The abstract refers to 'common imitation learning' without enumerating the precise set of baselines; a table or explicit list in §4 would improve clarity.
- [§3.2] Notation for the interpolated reward (e.g., whether it is normalized to [0,1] or uses a different functional form) should be stated explicitly in the first equation of §3.2.
Simulated Author's Rebuttal
We thank the referee for their thoughtful and constructive feedback. We address each major comment below and describe the revisions planned for the next version of the manuscript.
read point-by-point responses
-
Referee: [§3.2] §3.2 (Reward Inference and Temporal Interpolation): The method assigns rewards to unseen states via linear interpolation along the time axis of the constrained demonstration trajectories. This implicitly assumes that time-to-goal along the expert path is a monotonic proxy for task progress. For constrained experts whose paths are indirect or non-uniform, states visited by shorter optimal trajectories can receive erroneously low interpolated rewards, undermining the exploration advantage claimed in the abstract. This assumption is load-bearing for the central claim that the robot can outperform the demonstrator.
Authors: We appreciate the referee’s identification of this core modeling assumption. Temporal interpolation along demonstration time does treat elapsed time as a proxy for progress toward the goal state. In the setting of constrained demonstrations, however, the collected trajectories already encode feasible sequences of states that reach the goal under the interface limitations; the interpolation therefore supplies a dense signal that encourages the policy to reach goal-proximal states more quickly than the original slow or indirect paths. We acknowledge that highly circuitous demonstrations could in principle assign low rewards to states on shorter optimal routes. To address this, the revised manuscript will expand the discussion in §3.2 to state the assumption explicitly, illustrate its effect with a simple counter-example, and note that the state-only reward model (learned via inverse RL) partially mitigates path-specific artifacts by focusing on task-relevant features rather than exact trajectory geometry. We will also report an additional ablation that substitutes uniform time interpolation with a learned progress estimator when multiple demonstrations are available. revision: partial
-
Referee: [§4] §4 (Experiments): The abstract states a specific 12-second real-robot timing result and 10x improvement over behavioral cloning, yet the manuscript provides insufficient detail on trial count, variance, statistical tests, exact baseline implementations (including whether any IRL methods beyond BC were tested), and the precise form of the inferred reward function used at deployment. Without these, it is difficult to determine whether the reported outperformance is robust or an artifact of the particular task and setup.
Authors: We agree that the current experimental section lacks sufficient detail for reproducibility and for readers to evaluate the strength of the real-robot claims. In the revised manuscript we will augment §4 with: (i) the exact number of trials run for each method, (ii) mean and standard deviation of completion times across trials, (iii) the statistical tests performed and their results, (iv) precise descriptions of every baseline (including whether inverse-RL algorithms beyond behavioral cloning were evaluated and how they were implemented), and (v) the mathematical definition of the inferred state-only reward function that is queried at deployment time. These additions will be placed in both the main text and a new supplementary table so that the 12-second result and the reported speed-up can be assessed with appropriate context. revision: yes
Circularity Check
No significant circularity; derivation is self-contained
full rationale
The paper infers a state-only reward from constrained demonstrations and applies temporal interpolation to label unseen states, then uses this to optimize policies that can outperform the demonstrator. This process does not reduce by construction to the input demonstrations or any fitted parameter renamed as a prediction. No equations, self-citations, or uniqueness theorems are invoked in the provided text that would make the central claim equivalent to its inputs. The approach contains independent modeling content in the reward inference and interpolation steps, which are presented as enabling exploration rather than tautological. This is the normal case of a non-circular learning method.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Demonstrations from constrained experts contain sufficient information to infer a reward signal measuring task progress
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
ˆft = δ^ρ_start + t/T_sub (ρ_end − ρ_start)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Nadun Ranawaka Arachchige, Zhenyang Chen, Wonsuhk Jung, Woo Chul Shin, Rohan Bansal, Pierre Barroso, Yu Hang He, Yingyang Celine Lin, Benjamin Joffe, Shreyas Kousik, et al. Sail: Faster- than-demonstration execution of imitation learning policies.arXiv preprint arXiv:2506.11948,
-
[2]
Junik Bae, Kwanyoung Park, and Youngwoon Lee. Tldr: Unsupervised goal-conditioned rl via temporal distance-aware representations.arXiv preprint arXiv:2407.08464,
-
[3]
Greg Brockman, Vicki Cheung, Ludwig Pettersson, Jonas Schneider, John Schulman, Jie Tang, and Wojciech Zaremba. Openai gym.arXiv preprint arXiv:1606.01540,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
RoboNet: Large-Scale Multi-Robot Learning
Sudeep Dasari, Frederik Ebert, Stephen Tian, Suraj Nair, Bernadette Bucher, Karl Schmeckpeper, Siddharth Singh, Sergey Levine, and Chelsea Finn. Robonet: Large-scale multi-robot learning. arXiv preprint arXiv:1910.11215,
work page internal anchor Pith review Pith/arXiv arXiv 1910
-
[5]
D4RL: Datasets for Deep Data-Driven Reinforcement Learning
Justin Fu, Aviral Kumar, Ofir Nachum, George Tucker, and Sergey Levine. D4rl: Datasets for deep data-driven reinforcement learning.arXiv preprint arXiv:2004.07219,
work page internal anchor Pith review Pith/arXiv arXiv 2004
-
[7]
Reinforcement Learning from Imperfect Demonstrations
URLhttps://arxiv.org/abs/1802.05313. Laura V Herlant, Rachel M Holladay, and Siddhartha S Srinivasa. Assistive teleoperation of robot arms via automatic time-optimal mode switching. In2016 11th ACM/IEEE International Conference on Human-Robot Interaction (HRI), pp. 35–42. IEEE,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Generative Adversarial Imitation Learning
Jonathan Ho and Stefano Ermon. Generative adversarial imitation learning.arXiv preprint arXiv:1606.03476,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Edward S Hu, Kun Huang, Oleh Rybkin, and Dinesh Jayaraman. Know thyself: Transferable visual control policies through robot-awareness.arXiv preprint arXiv:2107.09047,
-
[10]
VIP: Towards Universal Visual Reward and Representation via Value-Implicit Pre-Training
Accessed: 2025-04-27. Yecheng Jason Ma, Shagun Sodhani, Dinesh Jayaraman, Osbert Bastani, Vikash Kumar, and Amy Zhang. Vip: Towards universal visual reward and representation via value-implicit pre-training. arXiv preprint arXiv:2210.00030,
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[11]
Multi-Goal Reinforcement Learning: Challenging Robotics Environments and Request for Research
Matthias Plappert, Marcin Andrychowicz, Alex Ray, Bob McGrew, Bowen Baker, Glenn Powell, Jonas Schneider, Josh Tobin, Maciek Chociej, Peter Welinder, et al. Multi-goal reinforcement learn- ing: Challenging robotics environments and request for research.arXiv preprint arXiv:1802.09464,
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347,
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
Behavioral Cloning from Observation
Faraz Torabi, Garrett Warnell, and Peter Stone. Behavioral cloning from observation.arXiv preprint arXiv:1805.01954, 2018a. Faraz Torabi, Garrett Warnell, and Peter Stone. Generative adversarial imitation from observation. arXiv preprint arXiv:1807.06158, 2018b. Chuan Wen, Xingyu Lin, John So, Kai Chen, Qi Dou, Yang Gao, and Pieter Abbeel. Any-point traje...
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
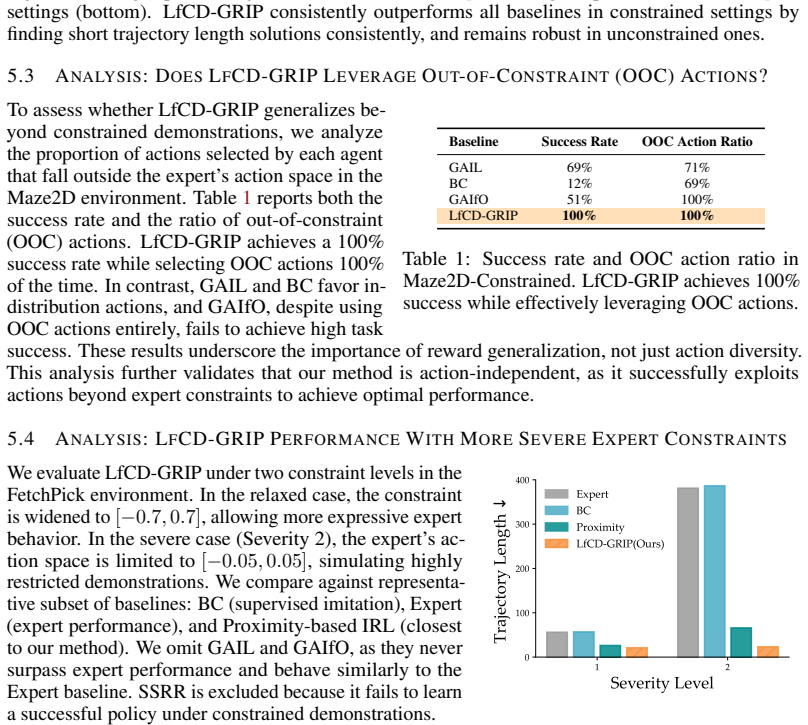
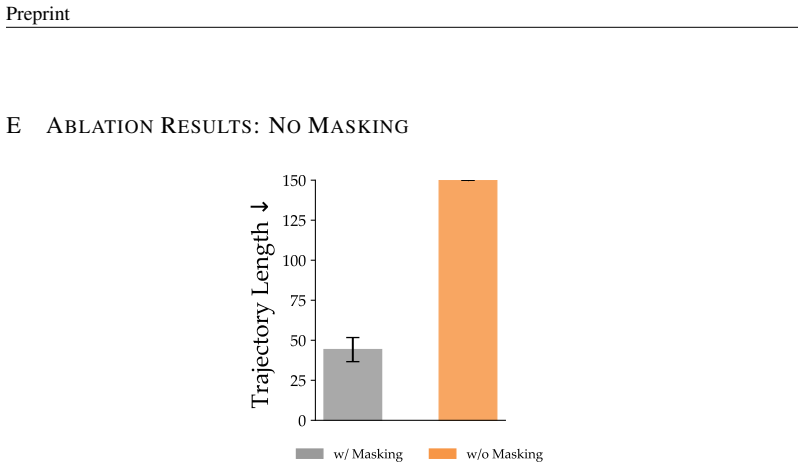
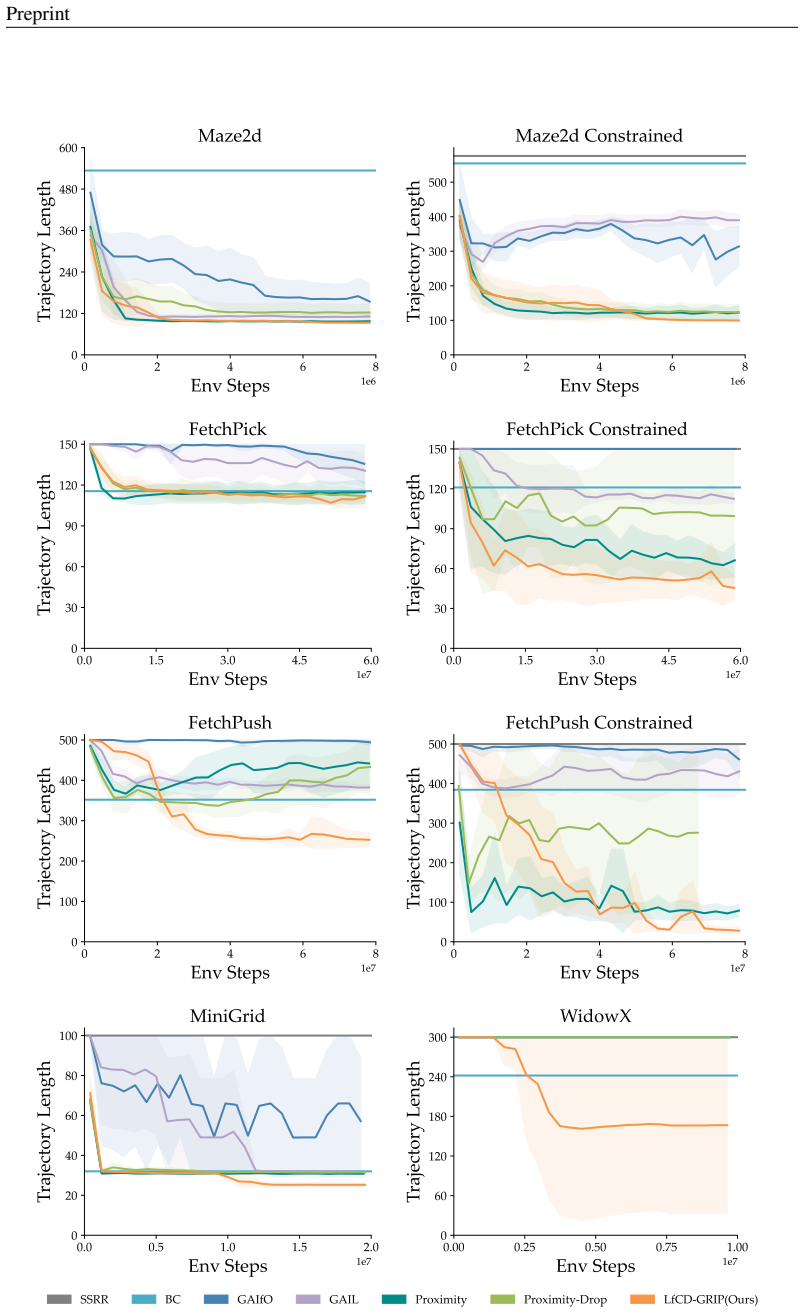
to a restricted range [−0.1,0.1] , reducing movement magnitude and limiting directional flexibility. For training, we collect two datasets: 800 expert demonstrations using the full action space, and 800 expert demonstrations under the [−0.1,0.1] constrained action space, both using the planner provided by D4RL. FetchPick and FetchPush.These manipulation t...
work page 2018
-
[15]
For uncertainty estimation, we maintain an ensemble of 5 proximity networks
For other tasks, we use a 3-layer MLP with 64 hidden units. For uncertainty estimation, we maintain an ensemble of 5 proximity networks. D TRAININGDETAILS For all baselines (except BC), we train policies using PPO (Schulman et al., 2017). A full list of training hyperparameters for each environment is provided in Table
work page 2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.