Reflection-Based Task Adaptation for Self-Improving VLA
Pith reviewed 2026-05-18 07:25 UTC · model grok-4.3
The pith
A reflection loop lets pre-trained vision-language-action models adapt to new manipulation tasks by analyzing failures and imitating successes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that a dual-pathway architecture combining Failure-Driven Reflective RL, which automatically builds dense rewards from failure analysis, with Success-Driven Quality-Guided SFT, which imitates high-quality successful trajectories under a conditional curriculum, produces faster convergence and higher final success rates than representative baselines in challenging manipulation tasks.
What carries the argument
The dual-pathway architecture of Failure-Driven Reflective RL paired with Success-Driven Quality-Guided SFT that together close the adaptation loop.
If this is right
- The failure-analysis pathway supplies a focused learning signal that accelerates policy exploration in new tasks.
- The success-imitation pathway counters reward hacking by grounding the policy in complete task achievement.
- The conditional curriculum supports early exploration when the agent has little prior experience.
- Together the pathways enable fully autonomous adaptation without external reward engineering.
Where Pith is reading between the lines
- The same reflection mechanism could be tested on navigation or multi-step assembly tasks to see whether the speed gains transfer.
- If the model's reasoning remains stable across different robot platforms, the approach might lower the total demonstrations needed for fine-tuning.
- Extending the loop to include real-world sensor noise would reveal whether the synthesized rewards stay robust outside simulation.
Load-bearing premise
The vision-language model can reliably reason about the causes of its failures to create targeted reward functions.
What would settle it
Running the same manipulation tasks with the framework and finding no measurable improvement in convergence speed or final success rate compared to the baselines would disprove the central claim.
Figures


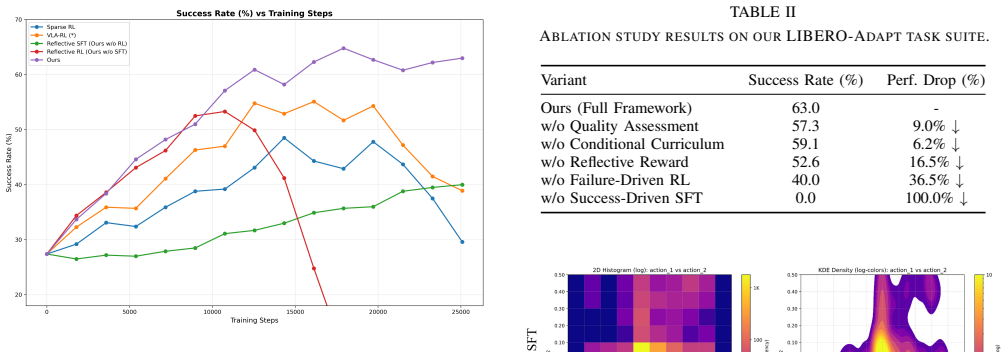

read the original abstract
Pre-trained Vision-Language-Action (VLA) models represent a major leap towards general-purpose robots, yet efficiently adapting them to novel, specific tasks in-situ remains a significant hurdle. While reinforcement learning (RL) is a promising avenue for such adaptation, the process often suffers from low efficiency, hindering rapid task mastery. We introduce Reflective Self-Adaptation, a framework for rapid, autonomous task adaptation without human intervention. Our framework establishes a self-improving loop where the agent learns from its own experience to enhance both strategy and execution. The core of our framework is a dual-pathway architecture that addresses the full adaptation lifecycle. First, a Failure-Driven Reflective RL pathway enables rapid learning by using the VLM's causal reasoning to automatically synthesize a targeted, dense reward function from failure analysis. This provides a focused learning signal that significantly accelerates policy exploration. However, optimizing such proxy rewards introduces a potential risk of "reward hacking," where the agent masters the reward function but fails the actual task. To counteract this, our second pathway, Success-Driven Quality-Guided SFT, grounds the policy in holistic success. It identifies and selectively imitates high-quality successful trajectories, ensuring the agent remains aligned with the ultimate task goal. This pathway is strengthened by a conditional curriculum mechanism to aid initial exploration. We conduct experiments in challenging manipulation tasks. The results demonstrate that our framework achieves faster convergence and higher final success rates compared to representative baselines. Our work presents a robust solution for creating self-improving agents that can efficiently and reliably adapt to new environments.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Reflective Self-Adaptation, a dual-pathway framework for in-situ adaptation of pre-trained Vision-Language-Action (VLA) models to novel tasks without human intervention. The Failure-Driven Reflective RL pathway uses VLM causal reasoning to synthesize dense proxy rewards from failure analysis for accelerated exploration, while the Success-Driven Quality-Guided SFT pathway imitates high-quality successful trajectories to mitigate reward hacking, augmented by a conditional curriculum. Experiments on manipulation tasks are reported to yield faster convergence and higher success rates relative to representative baselines.
Significance. If the empirical claims hold and the VLM-based mechanisms prove reliable, the work could meaningfully advance autonomous, self-improving robotic adaptation by reducing dependence on hand-crafted rewards and external supervision. The dual-pathway design directly targets the efficiency and alignment challenges in RL for high-dimensional VLA policies.
major comments (2)
- [Failure-Driven Reflective RL pathway] Failure-Driven Reflective RL pathway (core of §3): The claim that the VLM performs reliable causal reasoning to automatically synthesize a targeted, dense reward function from execution traces is load-bearing for the faster-convergence result, yet the manuscript supplies no validation of reasoning accuracy, no examples of generated rewards, and no ablation comparing against standard sparse-reward RL.
- [§4] §4, experimental results: The assertion of faster convergence and higher final success rates is presented without quantitative metrics, baseline implementations, trial counts, variance measures, or statistical tests, so the data-to-claim link cannot be evaluated.
minor comments (1)
- [Abstract] The abstract refers to 'representative baselines' without naming the specific methods or citing their original papers.
Simulated Author's Rebuttal
We thank the referee for their detailed and constructive review of our manuscript. We address each of the major comments below and outline the revisions we plan to make to strengthen the paper.
read point-by-point responses
-
Referee: Failure-Driven Reflective RL pathway (core of §3): The claim that the VLM performs reliable causal reasoning to automatically synthesize a targeted, dense reward function from execution traces is load-bearing for the faster-convergence result, yet the manuscript supplies no validation of reasoning accuracy, no examples of generated rewards, and no ablation comparing against standard sparse-reward RL.
Authors: We recognize the importance of validating the VLM's causal reasoning capabilities and providing concrete examples to support the claims regarding the Failure-Driven Reflective RL pathway. To address this, we will include in the revised manuscript: (1) examples of execution traces, the VLM's reasoning process, and the synthesized dense reward functions; (2) an ablation study that compares our reflective RL approach against a standard sparse-reward RL baseline to quantify the impact on convergence speed. This will strengthen the empirical support for the core mechanism. revision: yes
-
Referee: §4, experimental results: The assertion of faster convergence and higher final success rates is presented without quantitative metrics, baseline implementations, trial counts, variance measures, or statistical tests, so the data-to-claim link cannot be evaluated.
Authors: We agree that the experimental results section requires more rigorous quantitative details to allow proper evaluation of the claims. In the revised version, we will expand §4 to include specific quantitative metrics (e.g., success rates over training steps), details on baseline implementations, the number of trials conducted, variance measures such as standard deviations, and appropriate statistical tests to support the reported improvements in convergence and success rates. revision: yes
Circularity Check
No significant circularity; derivation relies on empirical validation rather than self-referential reduction
full rationale
The paper presents a dual-pathway framework (Failure-Driven Reflective RL for proxy reward synthesis via VLM causal analysis, followed by Success-Driven Quality-Guided SFT on high-quality trajectories) as a self-improving loop. No equations, fitted parameters renamed as predictions, or load-bearing self-citations appear in the provided text that would make any claimed result equivalent to its inputs by construction. The central claims of faster convergence and higher success rates are tied to experimental outcomes in manipulation tasks, with the VLM reasoning and success identification described as external mechanisms rather than internally defined in a circular manner. This is a standard empirical adaptation paper without the enumerated circular patterns.
Axiom & Free-Parameter Ledger
free parameters (1)
- curriculum parameters
axioms (1)
- domain assumption Vision-language models can perform reliable causal reasoning on task failures to synthesize dense rewards.
invented entities (2)
-
Failure-Driven Reflective RL pathway
no independent evidence
-
Success-Driven Quality-Guided SFT pathway
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Failure-Driven Reflective RL pathway enables rapid learning by using the VLM's causal reasoning to automatically synthesize a targeted, dense reward function from failure analysis... modular architecture... Reward Component Library... General Relationship Handlers (AND, IF, OR)
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Success-Driven Quality-Guided SFT... Q(τsucc) = w_reward * sum Rreflect(st) - w_steps * T
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 2 Pith papers
-
AsyncVLA: Asynchronous Flow Matching for Vision-Language-Action Models
AsyncVLA adds asynchronous flow matching and a confidence rater to VLA models so they can generate actions on flexible schedules and selectively refine low-confidence tokens before execution.
-
Evolvable Embodied Agent for Robotic Manipulation via Long Short-Term Reflection and Optimization
EEAgent with LSTRO sets new state-of-the-art results on six VIMA-Bench robotic manipulation tasks by dynamically refining prompts through reflection on successes and failures.
Reference graph
Works this paper leans on
-
[1]
RT-1: Robotics Transformer for Real-World Control at Scale
A. Brohan, N. Brown, J. Carbajal, Y . Chebotar, J. Dabis, C. Finn, K. Gopalakrishnan, K. Hausman, A. Herzog, J. Hsuet al., “Rt-1: Robotics transformer for real-world control at scale,”arXiv preprint arXiv:2212.06817, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[2]
Octo: An Open-Source Generalist Robot Policy
O. M. Team, D. Ghosh, H. Walke, K. Pertsch, K. Black, O. Mees, S. Dasari, J. Hejna, T. Kreiman, C. Xuet al., “Octo: An open-source generalist robot policy,”arXiv preprint arXiv:2405.12213, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[3]
Multimodal diffusion transformer: Learning versatile behavior from multimodal goals,
M. Reuss, ¨O. E. Ya ˘gmurlu, F. Wenzel, and R. Lioutikov, “Multimodal diffusion transformer: Learning versatile behavior from multimodal goals,”arXiv preprint arXiv:2407.05996, 2024
-
[4]
Vima: Robot manipulation with multimodal prompts,
Y . Jiang, A. Gupta, Z. Zhang, G. Wang, Y . Dou, Y . Chen, L. Fei-Fei, A. Anandkumar, Y . Zhu, and L. Fan, “Vima: Robot manipulation with multimodal prompts,” 2023
work page 2023
-
[5]
Rt-2: Vision-language-action models transfer web knowledge to robotic control,
B. Zitkovich, T. Yu, S. Xu, P. Xu, T. Xiao, F. Xia, J. Wu, P. Wohlhart, S. Welker, A. Wahidet al., “Rt-2: Vision-language-action models transfer web knowledge to robotic control,” inConference on Robot Learning. PMLR, 2023, pp. 2165–2183
work page 2023
-
[6]
OpenVLA: An Open-Source Vision-Language-Action Model
M. J. Kim, K. Pertsch, S. Karamcheti, T. Xiao, A. Balakrishna, S. Nair, R. Rafailov, E. Foster, G. Lam, P. Sanketiet al., “Openvla: An open- source vision-language-action model,”arXiv preprint arXiv:2406.09246, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[7]
Palm-e: An embodied multimodal language model,
D. Driess, F. Xia, M. S. Sajjadi, C. Lynch, A. Chowdhery, A. Wahid, J. Tompson, Q. Vuong, T. Yu, W. Huanget al., “Palm-e: An embodied multimodal language model,” 2023
work page 2023
-
[8]
Cot-vla: Visual chain-of-thought reasoning for vision-language-action models,
Q. Zhao, Y . Lu, M. J. Kim, Z. Fu, Z. Zhang, Y . Wu, Z. Li, Q. Ma, S. Han, C. Finnet al., “Cot-vla: Visual chain-of-thought reasoning for vision-language-action models,” inProceedings of the Computer Vision and Pattern Recognition Conference, 2025, pp. 1702–1713
work page 2025
-
[9]
RT-H: Action Hierarchies Using Language
S. Belkhale, T. Ding, T. Xiao, P. Sermanet, Q. Vuong, J. Tompson, Y . Chebotar, D. Dwibedi, and D. Sadigh, “Rt-h: Action hierarchies using language,”arXiv preprint arXiv:2403.01823, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[10]
$\pi_0$: A Vision-Language-Action Flow Model for General Robot Control
K. Black, N. Brown, D. Driess, A. Esmail, M. Equi, C. Finn, N. Fusai, L. Groom, K. Hausman, B. Ichteret al., “pi 0: A vision-language-action flow model for general robot control,”arXiv preprint arXiv:2410.24164, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[11]
Diffusion policy: Visuomotor policy learning via action diffusion,
C. Chi, Z. Xu, S. Feng, E. Cousineau, Y . Du, B. Burchfiel, R. Tedrake, and S. Song, “Diffusion policy: Visuomotor policy learning via action diffusion,”The International Journal of Robotics Research, p. 02783649241273668, 2023
work page 2023
-
[12]
Vlm-tdp: Vlm- guided trajectory-conditioned diffusion policy for robust long-horizon manipulation,
K. Huang, T. Li, Y . Liu, Z. Zhang, J. Wang, and L. Han, “Vlm-tdp: Vlm- guided trajectory-conditioned diffusion policy for robust long-horizon manipulation,”arXiv preprint arXiv:2507.04524, 2025
-
[13]
GR00T N1: An Open Foundation Model for Generalist Humanoid Robots
J. Bjorck, F. Casta˜neda, N. Cherniadev, X. Da, R. Ding, L. Fan, Y . Fang, D. Fox, F. Hu, S. Huanget al., “Gr00t n1: An open foundation model for generalist humanoid robots,”arXiv preprint arXiv:2503.14734, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[14]
C. J. Watkins and P. Dayan, “Q-learning,”Machine learning, vol. 8, no. 3, pp. 279–292, 1992
work page 1992
-
[15]
Proximal Policy Optimization Algorithms
J. Schulman, F. Wolski, P. Dhariwal, A. Radford, and O. Klimov, “Prox- imal policy optimization algorithms,”arXiv preprint arXiv:1707.06347, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[16]
Direct preference optimization: Your language model is secretly a reward model,
R. Rafailov, A. Sharma, E. Mitchell, C. D. Manning, S. Ermon, and C. Finn, “Direct preference optimization: Your language model is secretly a reward model,”Advances in neural information processing systems, vol. 36, pp. 53 728–53 741, 2023
work page 2023
-
[17]
Reinbot: Amplifying robot visual-language manipulation with reinforcement learning,
H. Zhang, Z. Zhuang, H. Zhao, P. Ding, H. Lu, and D. Wang, “Reinbot: Amplifying robot visual-language manipulation with reinforcement learning,”arXiv preprint arXiv:2505.07395, 2025
-
[18]
Offline Reinforcement Learning with Implicit Q-Learning
I. Kostrikov, A. Nair, and S. Levine, “Offline reinforcement learning with implicit q-learning,”arXiv preprint arXiv:2110.06169, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[19]
Kan vs mlp for offline reinforcement learning,
H. Guo, F. Li, J. Li, and H. Liu, “Kan vs mlp for offline reinforcement learning,” inICASSP 2025-2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2025, pp. 1–5
work page 2025
-
[21]
Balancing signal and variance: Adaptive offline rl post-training for vla flow models,
H. Zhang, S. Zhang, J. Jin, Q. Zeng, Y . Qiao, H. Lu, and D. Wang, “Balancing signal and variance: Adaptive offline rl post-training for vla flow models,”arXiv preprint arXiv:2509.04063, 2025
-
[22]
D. Huang, Z. Fang, T. Zhang, Y . Li, L. Zhao, and C. Xia, “Co-rft: Efficient fine-tuning of vision-language-action models through chunked offline reinforcement learning,”arXiv preprint arXiv:2508.02219, 2025
-
[23]
VLA-RL: Towards Masterful and General Robotic Manipulation with Scalable Reinforcement Learning
G. Lu, W. Guo, C. Zhang, Y . Zhou, H. Jiang, Z. Gao, Y . Tang, and Z. Wang, “Vla-rl: Towards masterful and general robotic manipulation with scalable reinforcement learning,”arXiv preprint arXiv:2505.18719, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[24]
Improving vision-language-action model with online reinforcement learning,
Y . Guo, J. Zhang, X. Chen, X. Ji, Y .-J. Wang, Y . Hu, and J. Chen, “Improving vision-language-action model with online reinforcement learning,”arXiv preprint arXiv:2501.16664, 2025
-
[25]
Conrft: A reinforced fine-tuning method for vla models via consistency policy,
Y . Chen, S. Tian, S. Liu, Y . Zhou, H. Li, and D. Zhao, “Conrft: A reinforced fine-tuning method for vla models via consistency policy,” arXiv preprint arXiv:2502.05450, 2025
-
[26]
Learning transferable visual models from natural language supervision,
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clarket al., “Learning transferable visual models from natural language supervision,” inInternational conference on machine learning. PmLR, 2021, pp. 8748–8763
work page 2021
-
[27]
H. Liu, C. Li, Q. Wu, and Y . J. Lee, “Visual instruction tuning,” Advances in neural information processing systems, vol. 36, pp. 34 892– 34 916, 2023
work page 2023
-
[28]
PaLI: A Jointly-Scaled Multilingual Language-Image Model
X. Chen, X. Wang, S. Changpinyo, A. J. Piergiovanni, P. Padlewski, D. Salz, S. Goodman, A. Grycner, B. Mustafa, L. Beyeret al., “Pali: A jointly-scaled multilingual language-image model,”arXiv preprint arXiv:2209.06794, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[29]
A. Hurst, A. Lerer, A. P. Goucher, A. Perelman, A. Ramesh, A. Clark, A. Ostrow, A. Welihinda, A. Hayes, A. Radfordet al., “Gpt-4o system card,”arXiv preprint arXiv:2410.21276, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[30]
J. Li, D. Li, C. Xiong, and S. Hoi, “Blip: Bootstrapping language-image pre-training for unified vision-language understanding and generation,” inInternational conference on machine learning. PMLR, 2022, pp. 12 888–12 900
work page 2022
-
[31]
Do As I Can, Not As I Say: Grounding Language in Robotic Affordances
M. Ahn, A. Brohan, N. Brown, Y . Chebotar, O. Cortes, B. David, C. Finn, C. Fu, K. Gopalakrishnan, K. Hausmanet al., “Do as i can, not as i say: Grounding language in robotic affordances,”arXiv preprint arXiv:2204.01691, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[32]
Embodiedgpt: Vision-language pre-training via embodied chain of thought,
Y . Mu, Q. Zhang, M. Hu, W. Wang, M. Ding, J. Jin, B. Wang, J. Dai, Y . Qiao, and P. Luo, “Embodiedgpt: Vision-language pre-training via embodied chain of thought,”Advances in Neural Information Processing Systems, vol. 36, pp. 25 081–25 094, 2023
work page 2023
-
[33]
Grape: Generalizing robot policy via preference alignment,
Z. Zhang, K. Zheng, Z. Chen, J. Jang, Y . Li, S. Han, C. Wang, M. Ding, D. Fox, and H. Yao, “Grape: Generalizing robot policy via preference alignment,”arXiv preprint arXiv:2411.19309, 2024
-
[34]
A. Leanza, A. Moroncelli, G. Vizzari, F. Braghin, L. Roveda, and B. Spahiu, “Conceptbot: Enhancing robot’s autonomy through task decomposition with large language models and knowledge graph,” arXiv preprint arXiv:2509.00570, 2025
-
[35]
L. Liu, S. Zhang, Y . Jiang, J. Guo, and W. Zhao, “Task decomposition and self-evaluation mechanisms for home healthcare robots using large language models,”IEEE Access, 2025
work page 2025
-
[36]
Delta: Decomposed efficient long-term robot task planning using large language models,
Y . Liu, L. Palmieri, S. Koch, I. Georgievski, and M. Aiello, “Delta: Decomposed efficient long-term robot task planning using large language models,” in2025 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2025, pp. 10 995–11 001
work page 2025
-
[37]
Roboclip: One demonstration is enough to learn robot policies,
S. Sontakke, J. Zhang, S. Arnold, K. Pertsch, E. Bıyık, D. Sadigh, C. Finn, and L. Itti, “Roboclip: One demonstration is enough to learn robot policies,”Advances in Neural Information Processing Systems, vol. 36, pp. 55 681–55 693, 2023
work page 2023
-
[38]
Liv: Language-image representations and rewards for robotic control,
Y . J. Ma, V . Kumar, A. Zhang, O. Bastani, and D. Jayaraman, “Liv: Language-image representations and rewards for robotic control,” in International Conference on Machine Learning. PMLR, 2023, pp. 23 301–23 320
work page 2023
-
[39]
Rl-vlm-f: Reinforcement learning from vision language foundation model feedback,
Y . Wang, Z. Sun, J. Zhang, Z. Xian, E. Biyik, D. Held, and Z. Erickson, “Rl-vlm-f: Reinforcement learning from vision language foundation model feedback,”arXiv preprint arXiv:2402.03681, 2024
-
[40]
Z. Huang, Z. Sheng, Y . Qu, J. You, and S. Chen, “Vlm-rl: A unified vision language models and reinforcement learning framework for safe autonomous driving,”Transportation Research Part C: Emerging Technologies, vol. 180, p. 105321, 2025
work page 2025
-
[41]
Tuning large multimodal models for videos using reinforcement learning from ai feedback,
D. Ahn, Y . Choi, Y . Yu, D. Kang, and J. Choi, “Tuning large multimodal models for videos using reinforcement learning from ai feedback,” inProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 2024, pp. 923– 940
work page 2024
-
[42]
Libero: Benchmarking knowledge transfer for lifelong robot learning,
B. Liu, Y . Zhu, C. Gao, Y . Feng, Q. Liu, Y . Zhu, and P. Stone, “Libero: Benchmarking knowledge transfer for lifelong robot learning,” Advances in Neural Information Processing Systems, vol. 36, pp. 44 776– 44 791, 2023
work page 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.