AtlasKV: Augmenting LLMs with Billion-Scale Knowledge Graphs in 20GB VRAM
Pith reviewed 2026-05-18 05:57 UTC · model grok-4.3
The pith
AtlasKV turns billion-scale knowledge graphs into key-value pairs that LLMs can use directly through their own attention layers.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
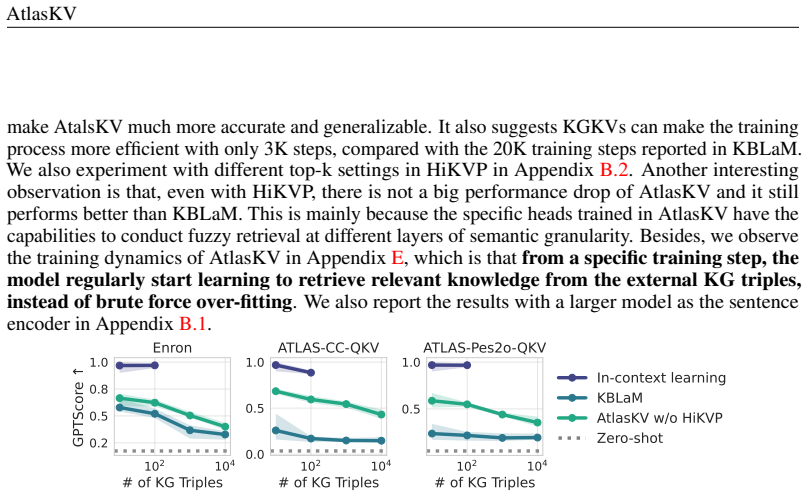
AtlasKV integrates KG triples into LLMs at scale with sub-linear time and memory complexity. It maintains strong knowledge grounding and generalization performance using the LLMs' inherent attention mechanism, and requires no external retrievers, long context priors, or retraining when adapting to new knowledge.
What carries the argument
KG2KV and HiKVP convert knowledge graph triples into key-value representations that plug into the LLM's existing attention mechanism for direct knowledge access.
Load-bearing premise
Converting KG triples into key-value representations via KG2KV and HiKVP lets the LLM's attention mechanism ground and generalize knowledge effectively without retraining or performance loss at billion-triple scale.
What would settle it
Measure whether answer accuracy on knowledge-intensive tasks stays high and VRAM usage remains below 20 GB when the same untuned model is given a 1-billion-triple knowledge graph.
Figures








read the original abstract
Retrieval-augmented generation (RAG) has shown some success in augmenting large language models (LLMs) with external knowledge. However, as a non-parametric knowledge integration paradigm for LLMs, RAG methods heavily rely on external retrieval modules and the retrieved textual context prior. Especially for very large scale knowledge augmentation, they would introduce substantial inference latency due to expensive searches and much longer relevant context. In this paper, we propose a parametric knowledge integration method, called \textbf{AtlasKV}, a scalable, effective, and general way to augment LLMs with billion-scale knowledge graphs (KGs) (e.g. 1B triples) using very little GPU memory cost (e.g. less than 20GB VRAM). In AtlasKV, we introduce KG2KV and HiKVP to integrate KG triples into LLMs at scale with sub-linear time and memory complexity. It maintains strong knowledge grounding and generalization performance using the LLMs' inherent attention mechanism, and requires no external retrievers, long context priors, or retraining when adapting to new knowledge.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes AtlasKV, a parametric knowledge integration method to augment LLMs with billion-scale knowledge graphs (e.g. 1B triples) at low memory cost (<20GB VRAM). It introduces KG2KV and HiKVP to convert KG triples into key-value representations integrated via the LLM's existing attention mechanism, claiming sub-linear time and memory complexity, strong knowledge grounding and generalization, and no need for retraining, external retrievers, or long-context priors.
Significance. If the central claims are substantiated, the work would offer a notable alternative to retrieval-augmented generation by enabling efficient, direct parametric incorporation of large structured KGs into frozen LLMs, potentially lowering inference latency and memory demands for knowledge-intensive tasks.
major comments (2)
- [Abstract] Abstract and method description: the core assumption that KG2KV/HiKVP synthetic KV pairs will receive meaningful attention from frozen pre-trained weights (without retraining or alignment adjustments) at 1B-triple scale is load-bearing for the no-retraining and performance-maintenance claims, yet no derivation, geometric analysis, or preliminary attention-map evidence is supplied to address potential misalignment with the model's learned query-key geometry.
- [Method] Scalability claims: the sub-linear time and memory complexity for 1B triples fitting in <20GB VRAM via HiKVP is asserted but lacks explicit complexity bounds, pseudocode, or memory-breakdown equations; this is central to the 20GB VRAM guarantee and requires concrete verification.
minor comments (2)
- The abstract refers to 'strong knowledge grounding and generalization performance' without naming the evaluation benchmarks, datasets, or metrics that would allow readers to assess the claim.
- Notation for KG2KV and HiKVP is introduced without immediate formal definitions or pseudocode, which could be clarified in an early section for readability.
Simulated Author's Rebuttal
We thank the referee for their thoughtful and constructive feedback. We address each major comment below with clarifications and commit to specific revisions that will strengthen the manuscript without altering its core contributions.
read point-by-point responses
-
Referee: [Abstract] Abstract and method description: the core assumption that KG2KV/HiKVP synthetic KV pairs will receive meaningful attention from frozen pre-trained weights (without retraining or alignment adjustments) at 1B-triple scale is load-bearing for the no-retraining and performance-maintenance claims, yet no derivation, geometric analysis, or preliminary attention-map evidence is supplied to address potential misalignment with the model's learned query-key geometry.
Authors: We acknowledge that a more explicit justification of this assumption would improve the paper. Our primary evidence remains empirical, with experiments demonstrating that the converted KV pairs integrate effectively into the frozen model's attention for knowledge-intensive tasks. In revision we will add a brief geometric intuition subsection explaining why the key-value conversion preserves directional compatibility with pre-trained query-key spaces, together with preliminary attention-map visualizations from smaller-scale controlled runs that illustrate non-trivial attention allocation to the synthetic pairs. revision: yes
-
Referee: [Method] Scalability claims: the sub-linear time and memory complexity for 1B triples fitting in <20GB VRAM via HiKVP is asserted but lacks explicit complexity bounds, pseudocode, or memory-breakdown equations; this is central to the 20GB VRAM guarantee and requires concrete verification.
Authors: We agree that the scalability claims require more formal presentation. The sub-linear behavior stems from HiKVP's hierarchical partitioning that limits the number of active KV pairs per attention head. In the revised manuscript we will insert a dedicated complexity-analysis subsection containing: explicit O(log N) time and memory bounds (N = number of triples), pseudocode for both KG2KV conversion and HiKVP construction/inference, and a memory-breakdown equation with concrete constants that shows how 1 B triples fit inside the stated 20 GB VRAM budget. revision: yes
Circularity Check
No significant circularity in AtlasKV proposal
full rationale
The paper presents AtlasKV as an original parametric construction that introduces KG2KV and HiKVP to convert KG triples into KV representations for direct use by a frozen LLM's attention mechanism. The abstract and context describe this as a new method achieving sub-linear scaling and knowledge grounding without retraining or external modules. No equations, derivations, fitted parameters renamed as predictions, or load-bearing self-citations appear that would reduce the central claims to their own inputs by construction. The approach stands as a self-contained engineering proposal rather than a tautological renaming or fit-based result.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLM attention mechanism can effectively utilize KG-derived key-value pairs for knowledge grounding without retraining
invented entities (2)
-
KG2KV
no independent evidence
-
HiKVP
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
KG2KV and HiKVP to integrate KG triples into LLMs at scale with sub-linear time and memory complexity... using the LLMs' inherent attention mechanism
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
rectangular attention... O((M+N)·N·D) ... AtlasKV O((Ct 3√M+N)·N·D)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Jiaxin Bai, Wei Fan, Qi Hu, Qing Zong, Chunyang Li, Hong Ting Tsang, Hongyu Luo, Yauwai Yim, Haoyu Huang, Xiao Zhou, et al. Autoschemakg: Autonomous knowledge graph construction through dynamic schema induction from web-scale corpora.arXiv preprint arXiv:2505.23628,
-
[2]
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners.Advances in neural information processing systems, 33:1877–1901,
work page 1901
-
[3]
Sparks of Artificial General Intelligence: Early experiments with GPT-4
10 AtlasKV Sébastien Bubeck, Varun Chandrasekaran, Ronen Eldan, Johannes Gehrke, Eric Horvitz, Ece Kamar, Peter Lee, Yin Tat Lee, Yuanzhi Li, Scott Lundberg, et al. Sparks of artificial general intelligence: Early experiments with gpt-4.arXiv preprint arXiv:2303.12712,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Jiaqi Cao, Jiarui Wang, Rubin Wei, Qipeng Guo, Kai Chen, Bowen Zhou, and Zhouhan Lin. Mem- ory decoder: A pretrained, plug-and-play memory for large language models.arXiv preprint arXiv:2508.09874,
-
[5]
GRAIL:Learning to Interact with Large Knowledge Graphs for Retrieval Augmented Reasoning
Ge Chang, Jinbo Su, Jiacheng Liu, Pengfei Yang, Yuhao Shang, Huiwen Zheng, Hongli Ma, Yan Liang, Yuanchun Li, and Yunxin Liu. Grail: Learning to interact with large knowledge graphs for retrieval augmented reasoning.arXiv preprint arXiv:2508.05498,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Shizhe Diao, Tianyang Xu, Ruijia Xu, Jiawei Wang, and Tong Zhang. Mixture-of-domain-adapters: Decoupling and injecting domain knowledge to pre-trained language models memories.arXiv preprint arXiv:2306.05406,
-
[7]
From Local to Global: A Graph RAG Approach to Query-Focused Summarization
Darren Edge, Ha Trinh, Newman Cheng, Joshua Bradley, Alex Chao, Apurva Mody, Steven Truitt, Dasha Metropolitansky, Robert Osazuwa Ness, and Jonathan Larson. From local to global: A graph rag approach to query-focused summarization.arXiv preprint arXiv:2404.16130,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Retrieval-Augmented Generation for Large Language Models: A Survey
Yunfan Gao, Yun Xiong, Xinyu Gao, Kangxiang Jia, Jinliu Pan, Yuxi Bi, Yixin Dai, Jiawei Sun, Haofen Wang, and Haofen Wang. Retrieval-augmented generation for large language models: A survey.arXiv preprint arXiv:2312.10997, 2(1),
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Transformer Feed-Forward Layers Are Key-Value Memories
Mor Geva, Roei Schuster, Jonathan Berant, and Omer Levy. Transformer feed-forward layers are key-value memories.arXiv preprint arXiv:2012.14913,
work page internal anchor Pith review Pith/arXiv arXiv 2012
-
[10]
LightRAG: Simple and Fast Retrieval-Augmented Generation
Zirui Guo, Lianghao Xia, Yanhua Yu, Tu Ao, and Chao Huang. Lightrag: Simple and fast retrieval- augmented generation.arXiv preprint arXiv:2410.05779,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Don’t stop pretraining: Adapt language models to domains and tasks.arXiv preprint arXiv:2004.10964,
Suchin Gururangan, Ana Marasovi ´c, Swabha Swayamdipta, Kyle Lo, Iz Beltagy, Doug Downey, and Noah A Smith. Don’t stop pretraining: Adapt language models to domains and tasks.arXiv preprint arXiv:2004.10964,
-
[12]
Efficient nearest neighbor language models.arXiv preprint arXiv:2109.04212, 2021a
Junxian He, Graham Neubig, and Taylor Berg-Kirkpatrick. Efficient nearest neighbor language models.arXiv preprint arXiv:2109.04212, 2021a. Ruidan He, Linlin Liu, Hai Ye, Qingyu Tan, Bosheng Ding, Liying Cheng, Jia-Wei Low, Lidong Bing, and Luo Si. On the effectiveness of adapter-based tuning for pretrained language model adaptation.arXiv preprint arXiv:21...
-
[13]
Can llms be good graph judge for knowledge graph construction?arXiv preprint arXiv:2411.17388,
Haoyu Huang, Chong Chen, Zeang Sheng, Yang Li, and Wentao Zhang. Can llms be good graph judge for knowledge graph construction?arXiv preprint arXiv:2411.17388,
-
[14]
Retrieval-augmented generation with hierarchical knowledge.arXiv preprint arXiv:2503.10150,
11 AtlasKV Haoyu Huang, Yongfeng Huang, Junjie Yang, Zhenyu Pan, Yongqiang Chen, Kaili Ma, Hongzhi Chen, and James Cheng. Retrieval-augmented generation with hierarchical knowledge.arXiv preprint arXiv:2503.10150,
-
[15]
Aaron Hurst, Adam Lerer, Adam P Goucher, Adam Perelman, Aditya Ramesh, Aidan Clark, AJ Os- trow, Akila Welihinda, Alan Hayes, Alec Radford, et al. Gpt-4o system card.arXiv preprint arXiv:2410.21276,
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
Unsupervised Dense Information Retrieval with Contrastive Learning
URLhttps://arxiv.org/abs/2112.09118. Yixin Ji, Kaixin Wu, Juntao Li, Wei Chen, Mingjie Zhong, Xu Jia, and Min Zhang. Retrieval and reasoning on kgs: Integrate knowledge graphs into large language models for complex question answering. InFindings of the Association for Computational Linguistics: EMNLP 2024, pp. 7598–7610,
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[17]
Chao Jin, Zili Zhang, Xuanlin Jiang, Fangyue Liu, Xin Liu, Xuanzhe Liu, and Xin Jin. Ragcache: Efficient knowledge caching for retrieval-augmented generation.arXiv preprint arXiv:2404.12457,
-
[18]
Urvashi Khandelwal, Omer Levy, Dan Jurafsky, Luke Zettlemoyer, and Mike Lewis. Generalization through memorization: Nearest neighbor language models.arXiv preprint arXiv:1911.00172,
-
[19]
Knowledge graph-enhanced large language models via path selection.arXiv preprint arXiv:2406.13862,
Haochen Liu, Song Wang, Yaochen Zhu, Yushun Dong, and Jundong Li. Knowledge graph-enhanced large language models via path selection.arXiv preprint arXiv:2406.13862,
-
[20]
Lost in the Middle: How Language Models Use Long Contexts
Nelson F Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, and Percy Liang. Lost in the middle: How language models use long contexts.arXiv preprint arXiv:2307.03172,
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
Decoupled Weight Decay Regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization.arXiv preprint arXiv:1711.05101,
work page internal anchor Pith review Pith/arXiv arXiv
-
[22]
Gnn-rag: Graph neural retrieval for large language model reasoning.arXiv preprint arXiv:2405.20139,
Costas Mavromatis and George Karypis. Gnn-rag: Graph neural retrieval for large language model reasoning.arXiv preprint arXiv:2405.20139,
-
[23]
Kggen: Extracting knowledge graphs from plain text with language models
Belinda Mo, Kyssen Yu, Joshua Kazdan, Proud Mpala, Lisa Yu, Chris Cundy, Charilaos Kanatsoulis, and Sanmi Koyejo. Kggen: Extracting knowledge graphs from plain text with language models. arXiv preprint arXiv:2502.09956,
-
[24]
How much do language models memorize? arXiv preprint arXiv:2505.24832,
12 AtlasKV John X Morris, Chawin Sitawarin, Chuan Guo, Narine Kokhlikyan, G Edward Suh, Alexander M Rush, Kamalika Chaudhuri, and Saeed Mahloujifar. How much do language models memorize? arXiv preprint arXiv:2505.24832,
-
[25]
Language Models as Knowledge Bases?
Fabio Petroni, Tim Rocktäschel, Patrick Lewis, Anton Bakhtin, Yuxiang Wu, Alexander H Miller, and Sebastian Riedel. Language models as knowledge bases?arXiv preprint arXiv:1909.01066,
work page internal anchor Pith review Pith/arXiv arXiv 1909
-
[26]
Scaling Language Models: Methods, Analysis & Insights from Training Gopher
Jack W Rae, Sebastian Borgeaud, Trevor Cai, Katie Millican, Jordan Hoffmann, Francis Song, John Aslanides, Sarah Henderson, Roman Ring, Susannah Young, et al. Scaling language models: Methods, analysis & insights from training gopher.arXiv preprint arXiv:2112.11446,
work page internal anchor Pith review Pith/arXiv arXiv
-
[27]
Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks
Nils Reimers and Iryna Gurevych. Sentence-bert: Sentence embeddings using siamese bert-networks. arXiv preprint arXiv:1908.10084,
work page internal anchor Pith review Pith/arXiv arXiv 1908
-
[28]
Xiangqing Shen, Fanfan Wang, and Rui Xia. Reason-align-respond: Aligning llm reasoning with knowledge graphs for kgqa.arXiv preprint arXiv:2505.20971,
-
[29]
REPLUG: Retrieval-Augmented Black-Box Language Models
Weijia Shi, Sewon Min, Michihiro Yasunaga, Minjoon Seo, Rich James, Mike Lewis, Luke Zettle- moyer, and Wen-tau Yih. Replug: Retrieval-augmented black-box language models.arXiv preprint arXiv:2301.12652,
work page internal anchor Pith review Pith/arXiv arXiv
-
[30]
Xingwei Tan, Yuxiang Zhou, Gabriele Pergola, and Yulan He. Set-aligning framework for auto- regressive event temporal graph generation.arXiv preprint arXiv:2404.01532,
-
[31]
LLaMA: Open and Efficient Foundation Language Models
Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, et al. Llama: Open and efficient foundation language models.arXiv preprint arXiv:2302.13971,
work page internal anchor Pith review Pith/arXiv arXiv
-
[32]
Pat Verga, Haitian Sun, Livio Baldini Soares, and William W Cohen. Facts as experts: Adaptable and interpretable neural memory over symbolic knowledge.arXiv preprint arXiv:2007.00849,
-
[33]
Wenhui Wang, Hangbo Bao, Shaohan Huang, Li Dong, and Furu Wei. Minilmv2: Multi-head self-attention relation distillation for compressing pretrained transformers.arXiv preprint arXiv:2012.15828, 2020a. Wenhui Wang, Furu Wei, Li Dong, Hangbo Bao, Nan Yang, and Ming Zhou. Minilm: Deep self- attention distillation for task-agnostic compression of pre-trained ...
-
[34]
Aser: A large-scale eventuality knowledge graph
Hongming Zhang, Xin Liu, Haojie Pan, Yangqiu Song, and Cane Wing-Ki Leung. Aser: A large-scale eventuality knowledge graph. InProceedings of the web conference 2020, pp. 201–211,
work page 2020
-
[35]
Nan Zhang, Prafulla Kumar Choubey, Alexander Fabbri, Gabriel Bernadett-Shapiro, Rui Zhang, Prasenjit Mitra, Caiming Xiong, and Chien-Sheng Wu. Sirerag: Indexing similar and related information for multihop reasoning.arXiv preprint arXiv:2412.06206, 2024a. Qinggang Zhang, Junnan Dong, Hao Chen, Daochen Zha, Zailiang Yu, and Xiao Huang. Knowgpt: Knowledge g...
-
[36]
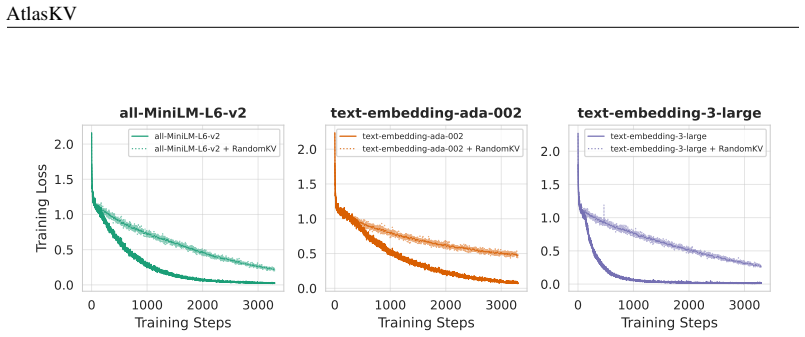
all-MiniLM-L6-v2 (Wang et al., 2020b) 1 to serve as the sentence encoder here. In the generation relevance experiments, we need stronger sentence encoder to let the value embeddings in KGKV2 have enough semantics. So in these experiments, we select a bigger OpenAI sentence encoder text-embedding-3-large through API. And we also demonstrate in Appendix B.1...
work page 2024
-
[37]
As shown in Figure 6, we can see that the knowledge grounding accuracy of AtlasKV will be significantly improved if we increase kR. And the performance will first improve and then slightly decrease when we increase kI or kL. This suggests that the accurate retrieval ability of AtlasKV is stronger than the fuzzy retrieval ability of it. And the reason why ...
work page 2000
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.