Generative AI Meets 6G and Beyond: Diffusion Models for Semantic Communications
Pith reviewed 2026-05-17 23:36 UTC · model grok-4.3
The pith
Diffusion models can serve as foundational engines for semantic communications in 6G and beyond by turning minimal meaning cues into full reconstructions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper claims that diffusion models, thanks to their generation quality and theoretical foundations, provide a systematic way to implement generative semantic communications through score-based methods, conditional controllable generation, accelerated inference techniques, cross-domain adaptations, and an inverse problem view that treats semantic decoding as posterior inference.
What carries the argument
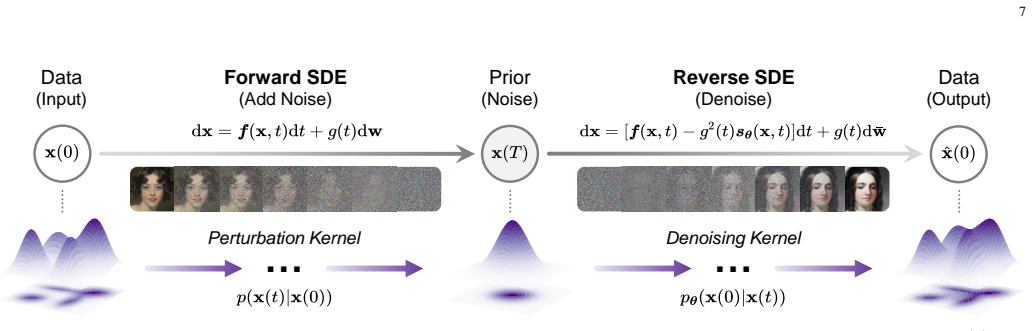
Score-based diffusion models that reverse a gradual noising process to produce samples, applied here to reconstruct semantically faithful content from sparse cues sent over wireless channels.
If this is right
- Semantic communications achieve much higher compression ratios while keeping meaning intact for human-centric uses such as media delivery.
- Machine-centric tasks gain accurate reconstructions suited to specific objectives through conditioned diffusion.
- Agent-centric coordination in networks benefits from robust generative priors that handle channel variations.
- The inverse problem framing allows borrowing reconstruction methods from imaging to improve decoding under impairments.
Where Pith is reading between the lines
- System designers could build standard protocols around semantic encoders paired with diffusion decoders rather than traditional bit pipelines.
- Real deployments might require channel-aware fine-tuning or hybrid models to meet latency targets in live networks.
- Similar generative techniques could extend to other resource-constrained settings like edge computing or sensor networks.
Load-bearing premise
Diffusion models trained on general data can be conditioned and adapted to preserve semantic fidelity across varied communication scenarios and channel conditions without major extra training or custom losses.
What would settle it
Measurements showing that diffusion-based reconstructions lose essential meaning or become unstable under realistic wireless noise, fading, or interference would indicate the approach does not reliably support semantic communications.
Figures











read the original abstract
Semantic communications mark a paradigm shift from bit-accurate transmission toward meaning-centric communication, essential as wireless systems approach theoretical capacity limits. The emergence of generative AI has catalyzed generative semantic communications, where receivers reconstruct content from minimal semantic cues by leveraging learned priors. Among generative approaches, diffusion models stand out for their superior generation quality, stable training dynamics, and rigorous theoretical foundations. However, the field currently lacks systematic guidance connecting diffusion techniques to communication system design, forcing researchers to navigate disparate literatures. This article provides the first comprehensive tutorial on diffusion models for generative semantic communications. We present score-based diffusion foundations and systematically review three technical pillars: conditional diffusion for controllable generation, efficient diffusion for accelerated inference, and generalized diffusion for cross-domain adaptation. In addition, we introduce an inverse problem perspective that reformulates semantic decoding as posterior inference, bridging semantic communications with computational imaging. Through analysis of human-centric, machine-centric, and agent-centric scenarios, we illustrate how diffusion models enable extreme compression while maintaining semantic fidelity and robustness. By bridging generative AI innovations with communication system design, this article aims to establish diffusion models as foundational components of next-generation wireless networks and beyond.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. This tutorial manuscript provides a systematic review of diffusion models for generative semantic communications in 6G and beyond. It covers score-based diffusion foundations, reviews three technical pillars (conditional diffusion for controllable generation, efficient diffusion for accelerated inference, and generalized diffusion for cross-domain adaptation), introduces an inverse-problem reformulation of semantic decoding as posterior inference, and analyzes applications across human-centric, machine-centric, and agent-centric scenarios to illustrate extreme compression while preserving semantic fidelity and robustness.
Significance. If the synthesis holds, the paper offers valuable guidance by bridging generative AI and communication system design literatures, with the inverse-problem perspective providing a useful conceptual link to computational imaging. As a tutorial without new empirical results or parameter-free derivations, its primary contribution is organizational rather than foundational; credit is due for the structured coverage of the three pillars and scenario analysis.
major comments (2)
- [conditional diffusion pillar] Section on conditional diffusion (pillar 1): the review relies on standard conditioning mechanisms and score-matching derivations from general generative modeling; it does not derive or cite channel-aware likelihood models that replace the forward diffusion process with realistic wireless impairments (fading, interference, non-Gaussian noise), which is required for the posterior-inference claim to remain accurate under varying SNR and mobility conditions.
- [inverse problem perspective] Inverse-problem reformulation section: while semantic decoding is recast as posterior inference, the manuscript presents only standard techniques and existing citations without demonstrating or referencing adaptations that preserve semantic fidelity when the diffusion noise is supplanted by wireless channel statistics, leaving the central generalization unvalidated.
minor comments (2)
- [efficient diffusion pillar] The efficient diffusion pillar would benefit from quantitative tables comparing sampling steps or latency against communication-relevant metrics such as end-to-end delay under different channel conditions.
- [generalized diffusion pillar] Notation for the generalized diffusion pillar could be clarified to explicitly distinguish domain-adaptation losses from standard diffusion objectives.
Simulated Author's Rebuttal
We are grateful to the referee for the thorough review and valuable suggestions. The feedback helps us improve the manuscript by strengthening the discussion on realistic wireless conditions. We provide detailed responses to the major comments and indicate the revisions we will implement.
read point-by-point responses
-
Referee: [conditional diffusion pillar] Section on conditional diffusion (pillar 1): the review relies on standard conditioning mechanisms and score-matching derivations from general generative modeling; it does not derive or cite channel-aware likelihood models that replace the forward diffusion process with realistic wireless impairments (fading, interference, non-Gaussian noise), which is required for the posterior-inference claim to remain accurate under varying SNR and mobility conditions.
Authors: We appreciate this observation. As a tutorial paper, our aim is to synthesize and organize existing techniques rather than derive new models. The section on conditional diffusion reviews standard mechanisms and their use in semantic communications. We acknowledge the importance of channel-aware adaptations for accurate modeling under wireless impairments. In the revised version, we will expand this section to include a discussion of channel-aware likelihood models, citing relevant literature on diffusion models adapted for wireless channels and semantic communications under fading and noise conditions. This will better justify the posterior inference approach in practical scenarios. revision: yes
-
Referee: [inverse problem perspective] Inverse-problem reformulation section: while semantic decoding is recast as posterior inference, the manuscript presents only standard techniques and existing citations without demonstrating or referencing adaptations that preserve semantic fidelity when the diffusion noise is supplanted by wireless channel statistics, leaving the central generalization unvalidated.
Authors: Thank you for highlighting this point. The inverse-problem perspective is introduced to bridge semantic communications with computational imaging by reformulating decoding as posterior inference. While we present standard techniques, we agree that more explicit references to adaptations for wireless channel statistics are needed to maintain semantic fidelity. We will revise this section to reference and discuss existing works that adapt diffusion models to replace Gaussian diffusion noise with channel-induced distortions, including examples from literature on robust semantic decoding. This will provide better support for the generalization without requiring new empirical validation, consistent with the tutorial nature of the manuscript. revision: yes
Circularity Check
Tutorial review of diffusion models for semantic communications is self-contained with no circular derivations
full rationale
The manuscript is structured as a tutorial that presents score-based diffusion foundations drawn from prior literature and systematically reviews three established technical pillars (conditional diffusion, efficient diffusion, generalized diffusion) plus an inverse-problem reformulation of semantic decoding. All load-bearing technical content is attributed to external references rather than derived from parameters fitted inside this paper or from self-referential equations that rename inputs as outputs. No self-definitional steps, fitted-input predictions, or uniqueness theorems imported solely via author self-citation appear in the derivation chain. The work therefore remains independent of its own fitted values and is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Recent contributions to the mathematical theory of communication,
W. Weaver, “Recent contributions to the mathematical theory of communication,”ETC: A Review of General Semantics, vol. 10, no. 4, pp. 261–281, 1953
work page 1953
-
[2]
A survey on semantic communication networks: Architecture, security, and privacy,
S. Guo, Y . Wang, N. Zhang, Z. Su, T. H. Luan, Z. Tian, and X. Shen, “A survey on semantic communication networks: Architecture, security, and privacy,”IEEE Commun. Surv. Tut., vol. 27, no. 5, pp. 2860–2894, 2024
work page 2024
-
[3]
L. X. Nguyen, A. D. Raha, P. S. Aung, D. Niyato, Z. Han, and C. S. Hong, “A contemporary survey on semantic communications: Theory of mind, generative AI, and deep joint source-channel coding,”IEEE Commun. Surv. Tut., 2025, Early Access
work page 2025
-
[4]
P. Zhang, W. Xu, Y . Liu, X. Qin, K. Niu, S. Cui, G. Shi, Z. Qin, X. Xu, F. Wang, et al., “Intellicise wireless networks from semantic communications: A survey, research issues, and challenges,”IEEE Commun. Surv. Tut., vol. 27, no. 3, pp. 2051–2084, 2024
work page 2051
-
[5]
Less data, more knowledge: Building next-generation semantic communication networks,
C. Chaccour, W. Saad, M. Debbah, Z. Han, and H. V . Poor, “Less data, more knowledge: Building next-generation semantic communication networks,”IEEE Commun. Surv. Tut., vol. 27, no. 1, pp. 37–76, 2024
work page 2024
-
[6]
L. von Rueden, S. Mayer, K. Beckh, B. Georgiev, S. Giesselbach, R. Heese, B. Kirsch, J. Pfrommer, A. Pick, R. Ramamurthy, et al., “Informed machine learning–a taxonomy and survey of integrating prior knowledge into learning systems,”IEEE Trans. Knowl. Data Eng., vol. 35, no. 1, pp. 614–633, 2021
work page 2021
-
[7]
Generative AI meets semantic communication: Evolution and revolution of communication tasks,
E. Grassucci, J. Park, S. Barbarossa, S. L. Kim, J. Choi, and D. Com- miniello, “Generative AI meets semantic communication: Evolution and revolution of communication tasks,”arXiv preprint arXiv:2401.06803, 2024
-
[8]
Generative semantic communication: Architec- tures, technologies, and applications,
J. Ren, Y . Sun, H. Du, W. Yuan, C. Wang, X. Wang, Y . Zhou, Z. Zhu, F. Wang, and S. Cui, “Generative semantic communication: Architec- tures, technologies, and applications,”arXiv preprint arXiv:2412.08642, 2024
-
[9]
Deep generative modeling reshapes compression and transmission: From efficiency to resiliency,
J. Dai, X. Qin, S. Wang, L. Xu, K. Niu, and P. Zhang, “Deep generative modeling reshapes compression and transmission: From efficiency to resiliency,”IEEE Wireless Commun., vol. 31, no. 4, pp. 48–56, 2024
work page 2024
-
[10]
Improving language understanding by generative pre-training,
A. Radford, K. Narasimhan, T. Salimans, and I. Sutskever, “Improving language understanding by generative pre-training,” Tech. Rep., OpenAI, 2018
work page 2018
-
[11]
Language models are unsupervised multitask learners,
A. Radford, J. Wu, R. Child, D. Luan, D. Amodei, and I. Sutskever, “Language models are unsupervised multitask learners,”OpenAI Blog, vol. 1, no. 8, pp. 9, 2019
work page 2019
-
[12]
Language models are few-shot learners,
T. Brown, B. Mann, N. Ryder, M. Subbiah, J. D. Kaplan, P. Dhariwal, A. Neelakantan, P. Shyam, G. Sastry, A. Askell, et al., “Language models are few-shot learners,” inProc. Int. Conf. Neural Inf. Process. Syst. (NeurIPS), 2020, pp. 1877–1901
work page 2020
-
[13]
Deep unsupervised learning using nonequilibrium thermodynamics,
J. Sohl-Dickstein, E. Weiss, N. Maheswaranathan, and S. Ganguli, “Deep unsupervised learning using nonequilibrium thermodynamics,” in Proc. Int. Conf. Mach. Learn. (ICML). PMLR, 2015, pp. 2256–2265
work page 2015
-
[14]
Diffusion-aided joint source channel coding for high realism wireless image transmission,
M. Yang, B. Liu, B. Wang, and H. S. Kim, “Diffusion-aided joint source channel coding for high realism wireless image transmission,” arXiv preprint arXiv:2404.17736, 2024
-
[15]
CDDM: Channel denoising diffusion models for wireless semantic communications,
T. Wu, Z. Chen, D. He, L. Qian, Y . Xu, M. Tao, and W. Zhang, “CDDM: Channel denoising diffusion models for wireless semantic communications,”IEEE Trans. Wireless Commun., vol. 23, no. 9, pp. 11168–11183, 2024
work page 2024
-
[16]
Diffusion-driven semantic communication for generative models with bandwidth constraints,
L. Guo, W. Chen, Y . Sun, B. Ai, N. Pappas, and T. Q. S. Quek, “Diffusion-driven semantic communication for generative models with bandwidth constraints,”IEEE Trans. Wireless Commun., vol. 24, no. 8, pp. 6490–6503, 2025
work page 2025
-
[17]
H. Du, R. Zhang, Y . Liu, J. Wang, Y . Lin, Z. Li, D. Niyato, J. Kang, Z. Xiong, S. Cui, et al., “Enhancing deep reinforcement learning: A tutorial on generative diffusion models in network optimization,”IEEE Commun. Surv. Tut., vol. 26, no. 4, pp. 2611–2646, 2024
work page 2024
-
[18]
Generative diffusion models for wireless networks: Fundamental, architecture, and state-of-the-art,
D. Fan, R. Meng, X. Xu, Y . Liu, G. Nan, C. Feng, S. Han, S. Gao, B. Xu, D. Niyato, et al., “Generative diffusion models for wireless networks: Fundamental, architecture, and state-of-the-art,”arXiv preprint arXiv:2507.16733, 2025
-
[19]
DiffSG: A generative solver for network optimization with diffusion model,
R. Liang, B. Yang, Z. Yu, B. Guo, X. Cao, M. Debbah, H. V . Poor, and C. Yuen, “DiffSG: A generative solver for network optimization with diffusion model,”IEEE Commun. Mag., vol. 63, no. 6, pp. 16–24, 2025
work page 2025
-
[20]
An introduction to variational autoencoders,
D. P. Kingma and M. Welling, “An introduction to variational autoencoders,”Found. Trends Mach. Learn., vol. 12, no. 4, pp. 307–392, 2019
work page 2019
-
[21]
Estimation of non-normalized statistical models by score matching,
A. Hyv ¨arinen, “Estimation of non-normalized statistical models by score matching,”J. Mach. Learn. Res., vol. 6, no. 24, pp. 695–709, 2005
work page 2005
-
[22]
A tutorial on energy-based learning,
Y . LeCun, S. Chopra, R. Hadsell, M. Ranzato, and F. Huang, “A tutorial on energy-based learning,” inPredicting Structured Data, G. Bakir, T. Hofmann, B. Sch ¨olkopf, A. Smola, and B. Taskar, Eds. MIT Press, 2006
work page 2006
-
[23]
A learning algorithm for Boltzmann machines,
D. H. Ackley, G. E. Hinton, and T. J. Sejnowski, “A learning algorithm for Boltzmann machines,”Cogn. Sci., vol. 9, no. 1, pp. 147–169, 1985
work page 1985
-
[24]
A simple introduction to Markov Chain Monte Carlo sampling,
D. van Ravenzwaaij, P. Cassey, and S. D. Brown, “A simple introduction to Markov Chain Monte Carlo sampling,”Psychon. Bull. Rev., vol. 25, no. 1, pp. 143–154, 2018
work page 2018
-
[25]
R. M. Neal, “Annealed importance sampling,”Stat. Comput., vol. 11, no. 2, pp. 125–139, 2001
work page 2001
-
[26]
Autoregressive models in vision: A survey,
J. Xiong, G. Liu, L. Huang, C. Wu, T. Wu, Y . Mu, Y . Yao, H. Shen, Z. Wan, J. Huang, et al., “Autoregressive models in vision: A survey,” arXiv preprint arXiv:2411.05902, 2024
-
[27]
Auto-encoding variational Bayes,
D. P. Kingma and M. Welling, “Auto-encoding variational Bayes,” in Proc. Int. Conf. Learn. Represent. (ICLR), 2014
work page 2014
-
[28]
Pixel recurrent neural networks,
A. van den Oord, N. Kalchbrenner, and K. Kavukcuoglu, “Pixel recurrent neural networks,” inProc. Int. Conf. Mach. Learn. (ICML). PMLR, 2016, pp. 1747–1756
work page 2016
-
[29]
I. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu, D. Warde-Farley, S. Ozair, A. Courville, and Y . Bengio, “Generative adversarial nets,” inProc. Int. Conf. Neural Inf. Process. Syst. (NeurIPS), 2014
work page 2014
-
[30]
Improved techniques for training GANs,
T. Salimans, I. Goodfellow, W. Zaremba, V . Cheung, A. Radford, and X. Chen, “Improved techniques for training GANs,” inProc. Int. Conf. Neural Inf. Process. Syst. (NeurIPS), 2016
work page 2016
-
[31]
C. Stein, “A bound for the error in the normal approximation to the distribution of a sum of dependent random variables,” inProc. Sixth Berkeley Symp. Math. Statist. Probab.University of California Press, 1972, vol. 6, pp. 583–603
work page 1972
-
[32]
How to train your energy-based models,
Y . Song and D. P. Kingma, “How to train your energy-based models,” arXiv preprint arXiv:2101.03288, 2021
-
[33]
The Principles of Diffusion Models
C. H. Lai, Y . Song, D. Kim, Y . Mitsufuji, and S. Ermon, “The principles of diffusion models,”arXiv preprint arXiv:2510.21890, 2025
work page internal anchor Pith review arXiv 2025
-
[34]
A connection between score matching and denoising autoencoders,
P. Vincent, “A connection between score matching and denoising autoencoders,”Neural Comput., vol. 23, no. 7, pp. 1661–1674, 2011
work page 2011
-
[35]
Bayesian learning via stochastic gradient Langevin dynamics,
M. Welling and Y . W. Teh, “Bayesian learning via stochastic gradient Langevin dynamics,” inProc. Int. Conf. Mach. Learn. (ICML). PMLR, 2011, pp. 681–688
work page 2011
-
[36]
Score-based generative modeling through stochastic differential equations,
Y . Song, J. Sohl-Dickstein, D. P. Kingma, A. Kumar, S. Ermon, and B. Poole, “Score-based generative modeling through stochastic differential equations,” inProc. Int. Conf. Learn. Represent. (ICLR), 2021
work page 2021
-
[37]
Reverse-time diffusion equation models,
B. D. O. Anderson, “Reverse-time diffusion equation models,”Stochas- tic Process. Appl., vol. 12, no. 3, pp. 313–326, 1982. 28
work page 1982
-
[38]
G. Ohayon, T. J. Adrai, M. Elad, and T. Michaeli, “Reasons for the superiority of stochastic estimators over deterministic ones: Robustness, consistency and perceptual quality,” inProc. Int. Conf. Mach. Learn. (ICML). PMLR, 2023, pp. 26474–26494
work page 2023
-
[39]
Generative modeling by estimating gradients of the data distribution,
Y . Song and S. Ermon, “Generative modeling by estimating gradients of the data distribution,” inProc. Int. Conf. Neural Inf. Process. Syst. (NeurIPS), 2019
work page 2019
-
[40]
Denoising diffusion probabilistic models,
J. Ho, A. Jain, and P. Abbeel, “Denoising diffusion probabilistic models,” inProc. Int. Conf. Neural Inf. Process. Syst. (NeurIPS), 2020, pp. 6840–6851
work page 2020
-
[41]
Neural ordinary differential equations,
R. T. Q. Chen, Y . Rubanova, J. Bettencourt, and D. K. Duvenaud, “Neural ordinary differential equations,” inProc. Int. Conf. Neural Inf. Process. Syst. (NeurIPS), 2018
work page 2018
-
[42]
Diffusion models beat GANs on image synthesis,
P. Dhariwal and A. Nichol, “Diffusion models beat GANs on image synthesis,” inProc. Int. Conf. Neural Inf. Process. Syst. (NeurIPS), 2021, pp. 8780–8794
work page 2021
-
[43]
ILVR: Condi- tioning method for denoising diffusion probabilistic models,
J. Choi, S. Kim, Y . Jeong, Y . Gwon, and S. Yoon, “ILVR: Condi- tioning method for denoising diffusion probabilistic models,” inProc. IEEE/CVF Int. Conf. Comput. Vis. (ICCV), 2021, pp. 14367–14376
work page 2021
-
[44]
SDEdit: Guided image synthesis and editing with stochastic differential equations,
C. Meng, Y . He, Y . Song, J. Song, J. Wu, J. Y . Zhu, and S. Ermon, “SDEdit: Guided image synthesis and editing with stochastic differential equations,” inProc. Int. Conf. Learn. Represent. (ICLR), 2022
work page 2022
-
[45]
RePaint: Inpainting using denoising diffusion probabilistic models,
A. Lugmayr, M. Danelljan, A. Romero, F. Yu, R. Timofte, and L. Van Gool, “RePaint: Inpainting using denoising diffusion probabilistic models,” inProc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), 2022, pp. 11461–11471
work page 2022
-
[46]
Denoising diffusion restoration models,
B. Kawar, M. Elad, S. Ermon, and J. Song, “Denoising diffusion restoration models,” inProc. Int. Conf. Neural Inf. Process. Syst. (NeurIPS), 2022, pp. 23593–23606
work page 2022
-
[47]
Improving diffusion models for inverse problems using manifold constraints,
H. Chung, B. Sim, D. Ryu, and J. C. Ye, “Improving diffusion models for inverse problems using manifold constraints,” inProc. Int. Conf. Neural Inf. Process. Syst. (NeurIPS), 2022, pp. 25683–25696
work page 2022
-
[48]
FreeDoM: Training- free energy-guided conditional diffusion model,
J. Yu, Y . Wang, C. Zhao, B. Ghanem, and J. Zhang, “FreeDoM: Training- free energy-guided conditional diffusion model,” inProc. IEEE/CVF Int. Conf. Comput. Vis. (ICCV), 2023, pp. 23174–23184
work page 2023
-
[49]
Refining generative process with discriminator guidance in score-based diffusion models,
D. Kim, Y . Kim, S. J. Kwon, W. Kang, and I. C. Moon, “Refining generative process with discriminator guidance in score-based diffusion models,” inProc. Int. Conf. Mach. Learn. (ICML), 2023, vol. 202, pp. 16567–16598
work page 2023
-
[50]
Diffusion posterior sampling for general noisy inverse problems,
H. Chung, J. Kim, M. T. Mccann, M. L. Klasky, and J. C. Ye, “Diffusion posterior sampling for general noisy inverse problems,” inProc. Int. Conf. Learn. Represent. (ICLR), 2023
work page 2023
-
[51]
Pseudoinverse-guided diffusion models for inverse problems,
J. Song, A. Vahdat, M. Mardani, and J. Kautz, “Pseudoinverse-guided diffusion models for inverse problems,” inProc. Int. Conf. Learn. Represent. (ICLR), 2023
work page 2023
-
[52]
Solving linear inverse problems provably via posterior sampling with latent diffusion models,
L. Rout, N. Raoof, G. Daras, C. Caramanis, A. Dimakis, and S. Shakkot- tai, “Solving linear inverse problems provably via posterior sampling with latent diffusion models,” inProc. Int. Conf. Neural Inf. Process. Syst. (NeurIPS), 2024
work page 2024
-
[53]
A variational perspective on solving inverse problems with diffusion models,
M. Mardani, J. Song, J. Kautz, and A. Vahdat, “A variational perspective on solving inverse problems with diffusion models,” inProc. Int. Conf. Learn. Represent. (ICLR), 2024
work page 2024
-
[54]
Deep equilibrium diffusion restoration with parallel sampling,
J. Cao, Y . Shi, K. Zhang, Y . Zhang, R. Timofte, and L. Van Gool, “Deep equilibrium diffusion restoration with parallel sampling,” inProc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), 2024, pp. 2824–2834
work page 2024
-
[55]
Improving diffusion inverse problem solving with decoupled noise annealing,
B. Zhang, W. Chu, J. Berner, C. Meng, A. Anandkumar, and Y . Song, “Improving diffusion inverse problem solving with decoupled noise annealing,” inProc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), 2025, pp. 20895–20905
work page 2025
-
[56]
SitCom: Step-wise triple-consistent diffusion sampling for inverse problems,
I. Alkhouri, S. Liang, C. H. Huang, J. Dai, Q. Qu, S. Ravishankar, and R. Wang, “SitCom: Step-wise triple-consistent diffusion sampling for inverse problems,” inProc. Int. Conf. Mach. Learn. (ICML), 2025
work page 2025
-
[57]
Classifier-free diffusion guidance,
J. Ho and T. Salimans, “Classifier-free diffusion guidance,” inProc. Int. Conf. Neural Inf. Process. Syst. (NeurIPS), 2021
work page 2021
-
[58]
High- resolution image synthesis with latent diffusion models,
R. Rombach, A. Blattmann, D. Lorenz, P. Esser, and B. Ommer, “High- resolution image synthesis with latent diffusion models,” inProc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), 2022, pp. 10684–10695
work page 2022
-
[59]
GLIGEN: Open-set grounded text-to-image generation,
Y . Li, H. Liu, Q. Wu, F. Mu, J. Yang, J. Gao, C. Li, and Y . J. Lee, “GLIGEN: Open-set grounded text-to-image generation,” in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), 2023, pp. 22511–22521
work page 2023
-
[60]
InstructPix2Pix: Learning to follow image editing instructions,
T. Brooks, A. Holynski, and A. A. Efros, “InstructPix2Pix: Learning to follow image editing instructions,” inProc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), 2023, pp. 18392–18402
work page 2023
-
[61]
Shap-E: Generating Conditional 3D Implicit Functions
H. Jun and A. Nichol, “Shap-E: Generating conditional 3D implicit functions,”arXiv preprint arXiv:2305.02463, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[62]
Scalable diffusion models with transformers,
W. Peebles and S. Xie, “Scalable diffusion models with transformers,” in Proc. IEEE/CVF Int. Conf. Comput. Vis. (ICCV), 2023, pp. 4195–4205
work page 2023
-
[63]
MDTv2: Masked diffusion transformer is a strong image synthesizer,
S. Gao, P. Zhou, M. M. Cheng, and S. Yan, “MDTv2: Masked diffusion transformer is a strong image synthesizer,” inProc. IEEE Int. Conf. Comput. Vis. (ICCV), 2023
work page 2023
-
[64]
Adding conditional control to text-to-image diffusion models,
L. Zhang, A. Rao, and M. Agrawala, “Adding conditional control to text-to-image diffusion models,” inProc. IEEE/CVF Int. Conf. Comput. Vis. (ICCV), 2023, pp. 3836–3847
work page 2023
-
[65]
C. Mou, X. Wang, L. Xie, Y . Wu, J. Zhang, Z. Qi, and Y . Shan, “T2I- Adapter: Learning adapters to dig out more controllable ability for text-to-image diffusion models,” inProc. AAAI Conf. Artif. Intell., 2024, vol. 38, pp. 4296–4304
work page 2024
-
[66]
AnimateDiff: Animate your personalized text-to- image diffusion models without specific tuning,
Y . Guo, C. Yang, A. Rao, Z. Liang, Y . Wang, Y . Qiao, M. Agrawala, D. Lin, and B. Dai, “AnimateDiff: Animate your personalized text-to- image diffusion models without specific tuning,” inProc. Int. Conf. Learn. Represent. (ICLR), 2024
work page 2024
-
[67]
LLM-grounded video diffusion models,
L. Lian, B. Shi, A. Yala, T. Darrell, and B. Li, “LLM-grounded video diffusion models,” inProc. Int. Conf. Learn. Represent. (ICLR), 2024
work page 2024
-
[68]
SEINE: Short-to-long video diffusion model for generative transition and prediction,
X. Chen, Y . Wang, L. Zhang, S. Zhuang, X. Ma, J. Yu, Y . Wang, D. Lin, Y . Qiao, and Z. Liu, “SEINE: Short-to-long video diffusion model for generative transition and prediction,” inProc. Int. Conf. Learn. Represent. (ICLR), 2024
work page 2024
-
[69]
PixArt- σ: Weak-to-strong training of diffusion transformer for 4K text-to-image generation,
J. Chen, C. Ge, E. Xie, Y . Wu, L. Yao, X. Ren, Z. Wang, P. Luo, H. Lu, and Z. Li, “PixArt- σ: Weak-to-strong training of diffusion transformer for 4K text-to-image generation,” inProc. Eur. Conf. Comput. Vis. (ECCV). Springer, 2024, pp. 74–91
work page 2024
-
[70]
K. Zheng, Y . Chen, H. Chen, G. He, M. Y . Liu, J. Zhu, and Q. Zhang, “Direct discriminative optimization: Your likelihood-based visual generative model is secretly a GAN discriminator,” inProc. Int. Conf. Mach. Learn. (ICML), 2025
work page 2025
-
[71]
J. Li, Q. Long, J. Zheng, X. Gao, R. Piramuthu, W. Chen, and W. Y . Wang, “T2V-Turbo-v2: Enhancing video generation model post-training through data, reward, and conditional guidance design,” inProc. Int. Conf. Learn. Represent. (ICLR), 2025
work page 2025
-
[72]
Denoising diffusion implicit models,
J. Song, C. Meng, and S. Ermon, “Denoising diffusion implicit models,” inProc. Int. Conf. Learn. Represent. (ICLR), 2021
work page 2021
-
[73]
Sparse MRI: The application of compressed sensing for rapid MR imaging,
M. Lustig, D. Donoho, and J. M. Pauly, “Sparse MRI: The application of compressed sensing for rapid MR imaging,”Magn. Reson. Med., vol. 58, no. 6, pp. 1182–1195, 2007
work page 2007
-
[74]
Tweedie’s formula and selection bias,
B. Efron, “Tweedie’s formula and selection bias,”J. Amer. Statist. Assoc., vol. 106, no. 496, pp. 1602–1614, 2011
work page 2011
-
[75]
Parallel diffusion models of operator and image for blind inverse problems,
H. Chung, J. Kim, S. Kim, and J. C. Ye, “Parallel diffusion models of operator and image for blind inverse problems,” inProc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), 2023, pp. 6059–6069
work page 2023
-
[76]
Reduce, reuse, recycle: Compositional generation with energy-based diffusion models and MCMC,
Y . Du, C. Durkan, R. Strudel, J. B. Tenenbaum, S. Dieleman, R. Fergus, J. Sohl-Dickstein, A. Doucet, and W. S. Grathwohl, “Reduce, reuse, recycle: Compositional generation with energy-based diffusion models and MCMC,” inProc. Int. Conf. Mach. Learn. (ICML). PMLR, 2023, pp. 8489–8510
work page 2023
-
[77]
A Survey on Diffusion Models for Inverse Problems
G. Daras, H. Chung, C. H. Lai, Y . Mitsufuji, J. C. Ye, P. Milanfar, A. G. Dimakis, and M. Delbracio, “A survey on diffusion models for inverse problems,”arXiv preprint arXiv:2410.00083, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[78]
Wavelet score-based generative modeling,
F. Guth, S. Coste, V . De Bortoli, and S. Mallat, “Wavelet score-based generative modeling,” inProc. Int. Conf. Neural Inf. Process. Syst. (NeurIPS), 2022, pp. 478–491
work page 2022
-
[79]
Wavelet diffusion models are fast and scalable image generators,
H. Phung, Q. Dao, and A. Tran, “Wavelet diffusion models are fast and scalable image generators,” inProc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), 2023, pp. 10199–10208
work page 2023
-
[80]
LMD: Faster image reconstruction with latent masking diffusion,
Z. Ma, Z. Yu, J. Li, and B. Zhou, “LMD: Faster image reconstruction with latent masking diffusion,” inProc. AAAI Conf. Artif. Intell., 2024, vol. 38, pp. 4145–4153
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.