End-to-end Contrastive Language-Speech Pretraining Model For Long-form Spoken Question Answering
Pith reviewed 2026-05-17 22:41 UTC · model grok-4.3
The pith
CLSR improves long-form spoken question answering by converting acoustic features to text-like representations before alignment.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
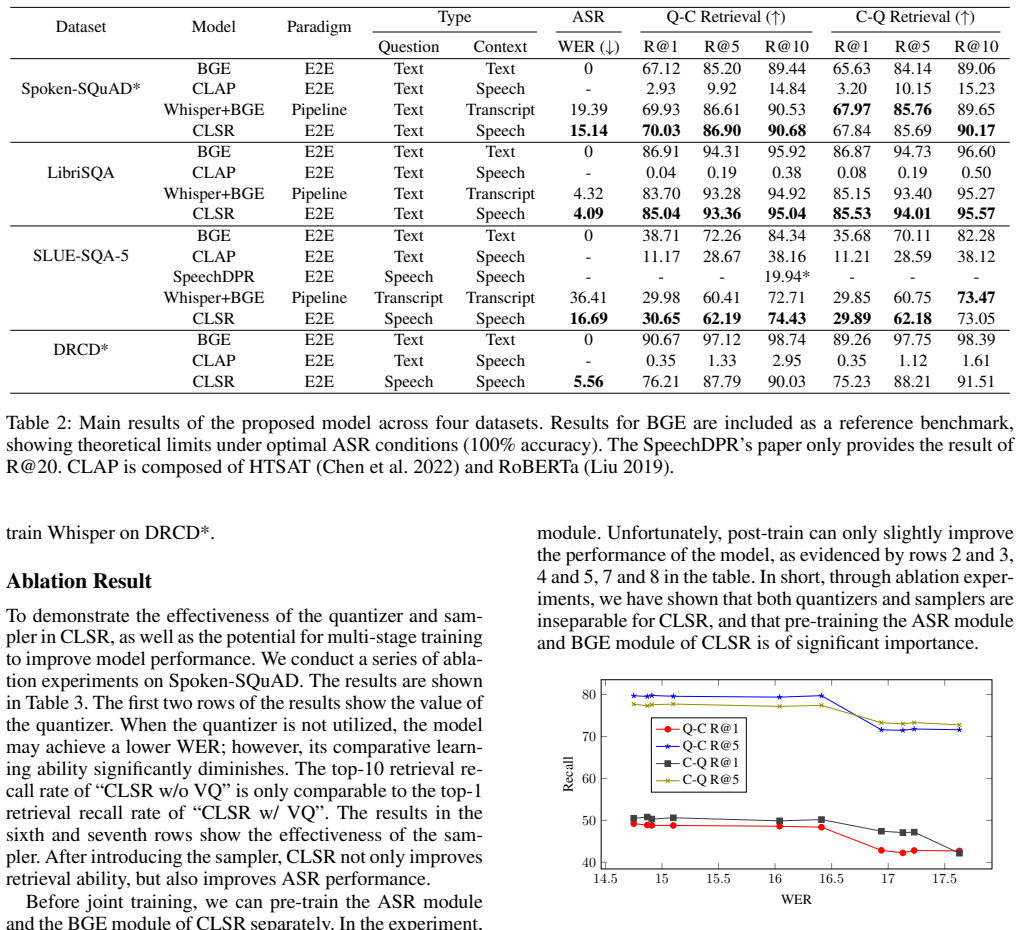
CLSR is an end-to-end contrastive language-speech retriever that efficiently extracts question-relevant segments from long audio recordings for downstream SQA task. Unlike conventional speech-text contrastive models, CLSR incorporates an intermediate step that converts acoustic features into text-like representations prior to alignment, thereby more effectively bridging the gap between modalities. Experimental results across four cross-modal retrieval datasets demonstrate that CLSR surpasses both end-to-end speech related retrievers and pipeline approaches combining speech recognition with text retrieval.
What carries the argument
The intermediate conversion step that turns acoustic features into text-like representations before performing contrastive alignment in the CLSR model.
If this is right
- CLSR can serve as a preprocessing retriever to handle long audio inputs for spoken question answering systems.
- It provides better performance than existing end-to-end speech retrievers on cross-modal tasks.
- The approach offers a stronger base than ASR pipelines for practical long-form SQA applications.
- Retrieval quality improvements should translate to better answers in retrieval-augmented spoken QA pipelines.
Where Pith is reading between the lines
- If the text-like intermediate representation is the key advantage, similar conversion steps might improve other speech-to-text or audio-language tasks beyond retrieval.
- Testing CLSR on recordings longer than those in the four datasets could reveal whether the gains hold at extreme lengths.
- The method might extend to multilingual settings if the conversion step generalizes across languages.
Load-bearing premise
Converting acoustic features into text-like representations prior to alignment bridges the modality gap more effectively than either direct alignment or ASR-plus-text pipelines.
What would settle it
A controlled test on the same four datasets where a version of CLSR without the intermediate conversion step matches or exceeds the full model's retrieval accuracy would show the conversion is not necessary.
Figures





read the original abstract
Significant progress has been made in spoken question answering (SQA) in recent years. However, many existing methods, including large audio language models, struggle with processing long audio. Follow the success of retrieval augmented generation, a speech-related retriever shows promising in help preprocessing long-form speech. But the performance of existing speech-related retrievers is lacking. To address this challenge, we propose CLSR, an end-to-end contrastive language-speech retriever that efficiently extracts question-relevant segments from long audio recordings for downstream SQA task. Unlike conventional speech-text contrastive models, CLSR incorporates an intermediate step that converts acoustic features into text-like representations prior to alignment, thereby more effectively bridging the gap between modalities. Experimental results across four cross-modal retrieval datasets demonstrate that CLSR surpasses both end-to-end speech related retrievers and pipeline approaches combining speech recognition with text retrieval, providing a robust foundation for advancing practical long-form SQA applications.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes CLSR, an end-to-end contrastive language-speech retriever for long-form spoken question answering. Unlike standard speech-text contrastive models, it incorporates an intermediate conversion of acoustic features into text-like representations prior to alignment to better bridge modality gaps. It reports experimental results showing superiority over both end-to-end speech retrievers and ASR-plus-text pipeline approaches across four cross-modal retrieval datasets, positioning the model as a foundation for practical long-form SQA via improved retrieval.
Significance. If the reported gains hold under scrutiny, the work offers a practical advance for retrieval-augmented spoken question answering by addressing long-audio processing limitations. The end-to-end design and explicit acoustic-to-text-like conversion step represent a targeted architectural choice that could influence future cross-modal pretraining if supported by clear ablations and reproducible metrics.
major comments (2)
- [Methods] Methods section: the central motivation for the acoustic-to-text-like conversion step is presented as key to bridging the modality gap, yet no ablation is reported that isolates its contribution relative to direct alignment or standard contrastive baselines; this leaves the load-bearing justification for the intermediate representation under-supported given the abstract's emphasis on it.
- [Experiments] Experiments section: while standard retrieval metrics are used, the manuscript does not report error bars, statistical significance tests, or variance across runs for the claimed improvements over baselines on the four datasets, weakening the strength of the superiority conclusion.
minor comments (2)
- [Abstract] Abstract: the superiority claim would be strengthened by including at least one key quantitative result (e.g., recall@10 or MRR delta) rather than a purely qualitative statement.
- [Experiments] Ensure dataset statistics, preprocessing details, and exact baseline implementations are fully specified to support reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and the recommendation for minor revision. We address each major comment below and have revised the manuscript to strengthen the presentation of our contributions.
read point-by-point responses
-
Referee: [Methods] Methods section: the central motivation for the acoustic-to-text-like conversion step is presented as key to bridging the modality gap, yet no ablation is reported that isolates its contribution relative to direct alignment or standard contrastive baselines; this leaves the load-bearing justification for the intermediate representation under-supported given the abstract's emphasis on it.
Authors: We agree that an explicit ablation isolating the acoustic-to-text-like conversion would provide stronger support for its role. In the revised manuscript, we have added an ablation study in the Experiments section comparing CLSR to a direct-alignment variant (removing the intermediate conversion) and to standard contrastive baselines. The results show consistent gains from the intermediate step across datasets, and we have updated the Methods discussion to reference these findings. revision: yes
-
Referee: [Experiments] Experiments section: while standard retrieval metrics are used, the manuscript does not report error bars, statistical significance tests, or variance across runs for the claimed improvements over baselines on the four datasets, weakening the strength of the superiority conclusion.
Authors: We acknowledge the value of reporting variance and significance for the claimed improvements. In the revised manuscript, we now include standard deviations computed over five independent runs for all metrics on the four datasets. We have also added paired t-test results with p-values to the tables, confirming that the gains over baselines are statistically significant (p < 0.05) in the majority of cases. revision: yes
Circularity Check
No significant circularity
full rationale
The paper advances an empirical end-to-end contrastive retriever (CLSR) whose central claim rests on experimental comparisons against baselines across four datasets. The intermediate acoustic-to-text-like conversion is presented as an architectural choice motivated in the methods, not derived from or equivalent to the target performance metric by construction. No equations, fitted parameters renamed as predictions, or load-bearing self-citations appear in the derivation chain; the argument is self-contained against external retrieval benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Contrastive learning objectives can align speech and language modalities when an appropriate bridging representation is used.
Reference graph
Works this paper leans on
-
[1]
, " * write output.state after.block = add.period write newline
ENTRY address archivePrefix author booktitle chapter edition editor eid eprint howpublished institution isbn journal key month note number organization pages publisher school series title type volume year label extra.label sort.label short.list INTEGERS output.state before.all mid.sentence after.sentence after.block FUNCTION init.state.consts #0 'before.a...
-
[2]
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION word.in bbl.in capitalize " " * FUNCT...
-
[3]
Bengio, Y.; L \'e onard, N.; and Courville, A. 2013. Estimating or propagating gradients through stochastic neurons for conditional computation. arXiv preprint arXiv:1308.3432
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[4]
Brown, T. B. 2020. Language models are few-shot learners. arXiv preprint arXiv:2005.14165
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[5]
Chen, J.; Xiao, S.; Zhang, P.; Luo, K.; Lian, D.; and Liu, Z. 2024. Bge m3-embedding: Multi-lingual, multi-functionality, multi-granularity text embeddings through self-knowledge distillation. arXiv preprint arXiv:2402.03216
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[6]
Chen, K.; Du, X.; Zhu, B.; Ma, Z.; Berg-Kirkpatrick, T.; and Dubnov, S. 2022. Hts-at: A hierarchical token-semantic audio transformer for sound classification and detection. In ICASSP 2022-2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 646--650. IEEE
work page 2022
-
[7]
Chu, Y.; Xu, J.; Zhou, X.; Yang, Q.; Zhang, S.; Yan, Z.; Zhou, C.; and Zhou, J. 2023. Qwen-audio: Advancing universal audio understanding via unified large-scale audio-language models. arXiv preprint arXiv:2311.07919
work page internal anchor Pith review Pith/arXiv arXiv 2023
- [8]
-
[9]
Devlin, J.; Chang, M.-W.; Lee, K.; and Toutanova, K. 2019. Bert: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the 2019 conference of the North American chapter of the association for computational linguistics: human language technologies, volume 1 (long and short papers), 4171--4186
work page 2019
-
[10]
Dong, L.; and Xu, B. 2020. Cif: Continuous integrate-and-fire for end-to-end speech recognition. In ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 6079--6083. IEEE
work page 2020
- [11]
- [12]
- [13]
-
[14]
Guo, J.; Li, Z.; Wu, J.; Wang, Q.; Li, Y.; Zhang, L.; Zhao, H.; and Yang, Y. 2025. ToM: Leveraging Tree-oriented MapReduce for Long-Context Reasoning in Large Language Models. In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, 17804--17823
work page 2025
-
[15]
C.; Ontanon, S.; Ni, J.; Sung, Y.-H.; and Yang, Y
Guo, M.; Ainslie, J.; Uthus, D. C.; Ontanon, S.; Ni, J.; Sung, Y.-H.; and Yang, Y. 2022. LongT5: Efficient text-to-text transformer for long sequences. In Findings of the Association for Computational Linguistics: NAACL 2022, 724--736
work page 2022
- [16]
-
[17]
H.; Lakhotia, K.; Salakhutdinov, R.; and Mohamed, A
Hsu, W.-N.; Bolte, B.; Tsai, Y.-H. H.; Lakhotia, K.; Salakhutdinov, R.; and Mohamed, A. 2021. Hubert: Self-supervised speech representation learning by masked prediction of hidden units. IEEE/ACM transactions on audio, speech, and language processing, 29: 3451--3460
work page 2021
-
[18]
Johnson, A.; Plantinga, P.; Sun, P.; Gadiyaram, S.; Girma, A.; and Emami, A. 2024. Efficient SQA from Long Audio Contexts: A Policy-driven Approach. In Proc. Interspeech 2024, 1350--1354
work page 2024
-
[19]
K \"o hn, A.; Stegen, F.; and Baumann, T. 2016. Mining the spoken wikipedia for speech data and beyond. In Proceedings of the Tenth International Conference on Language Resources and Evaluation (LREC'16), 4644--4647
work page 2016
-
[20]
Lee, C.-H.; Chen, Y.-N.; and Lee, H.-Y. 2019. Mitigating the impact of speech recognition errors on spoken question answering by adversarial domain adaptation. In ICASSP 2019-2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 7300--7304. IEEE
work page 2019
-
[21]
Lee, C.-H.; Wang, S.-M.; Chang, H.-C.; and Lee, H.-Y. 2018. ODSQA: Open-domain spoken question answering dataset. In 2018 IEEE Spoken Language Technology Workshop (SLT), 949--956. IEEE
work page 2018
-
[22]
u ttler, H.; Lewis, M.; Yih, W.-t.; Rockt \
Lewis, P.; Perez, E.; Piktus, A.; Petroni, F.; Karpukhin, V.; Goyal, N.; K \"u ttler, H.; Lewis, M.; Yih, W.-t.; Rockt \"a schel, T.; et al. 2020. Retrieval-augmented generation for knowledge-intensive nlp tasks. Advances in neural information processing systems, 33: 9459--9474
work page 2020
-
[23]
Li, C.-H.; Wu, S.-L.; Liu, C.-L.; and Lee, H.-y. 2018. Spoken SQuAD: A study of mitigating the impact of speech recognition errors on listening comprehension. arXiv preprint arXiv:1804.00320
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[24]
Li, N.; Liu, Y.; Wu, Y.; Liu, S.; Zhao, S.; and Liu, M. 2020. Robutrans: A robust transformer-based text-to-speech model. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 34, 8228--8235
work page 2020
-
[25]
Li, Q.; Xiao, T.; Li, Z.; Wang, P.; Shen, M.; and Zhao, H. 2025. Dialogue-rag: Enhancing retrieval for llms via node-linking utterance rewriting. In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 24423--24438
work page 2025
- [26]
-
[27]
Lin, C.-J.; Lin, G.-T.; Chuang, Y.-S.; Wu, W.-L.; Li, S.-W.; Mohamed, A.; Lee, H.-y.; and Lee, L.-S. 2024. SpeechDPR: End-To-End Spoken Passage Retrieval For Open-Domain Spoken Question Answering. In ICASSP 2024-2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 12476--12480. IEEE
work page 2024
-
[28]
Liu, Y. 2019. Roberta: A robustly optimized bert pretraining approach. arXiv preprint arXiv:1907.11692, 364
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[29]
Panayotov, V.; Chen, G.; Povey, D.; and Khudanpur, S. 2015. Librispeech: an asr corpus based on public domain audio books. In 2015 IEEE international conference on acoustics, speech and signal processing (ICASSP), 5206--5210. IEEE
work page 2015
-
[30]
W.; Xu, T.; Brockman, G.; McLeavey, C.; and Sutskever, I
Radford, A.; Kim, J. W.; Xu, T.; Brockman, G.; McLeavey, C.; and Sutskever, I. 2023. Robust speech recognition via large-scale weak supervision. In International Conference on Machine Learning, 28492--28518. PMLR
work page 2023
-
[31]
Rajpurkar, P. 2016. Squad: 100,000+ questions for machine comprehension of text. arXiv preprint arXiv:1606.05250
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[32]
DRCD: a Chinese Machine Reading Comprehension Dataset
Shao, C. C.; Liu, T.; Lai, Y.; Tseng, Y.; and Tsai, S. 2018. DRCD: A Chinese machine reading comprehension dataset. arXiv preprint arXiv:1806.00920
work page internal anchor Pith review Pith/arXiv arXiv 2018
- [33]
-
[34]
Shih, Y.-J.; Wang, H.-F.; Chang, H.-J.; Berry, L.; Lee, H.-y.; and Harwath, D. 2023 b . Speechclip: Integrating speech with pre-trained vision and language model. In 2022 IEEE Spoken Language Technology Workshop (SLT), 715--722. IEEE
work page 2023
- [35]
-
[36]
Touvron, H.; Lavril, T.; Izacard, G.; Martinet, X.; Lachaux, M.-A.; Lacroix, T.; Rozi \`e re, B.; Goyal, N.; Hambro, E.; Azhar, F.; et al. 2023. Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[37]
N.; Kaiser, .; and Polosukhin, I
Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A. N.; Kaiser, .; and Polosukhin, I. 2017. Attention is all you need. Advances in neural information processing systems, 30
work page 2017
-
[38]
Wang, M.; Shafran, I.; Soltau, H.; Han, W.; Cao, Y.; Yu, D.; and El Shafey, L. 2024. Retrieval Augmented End-to-End Spoken Dialog Models. In ICASSP 2024-2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 12056--12060. IEEE
work page 2024
-
[39]
Wu, Y.; Chen, K.; Zhang, T.; Hui, Y.; Berg-Kirkpatrick, T.; and Dubnov, S. 2023. Large-scale contrastive language-audio pretraining with feature fusion and keyword-to-caption augmentation. In ICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 1--5. IEEE
work page 2023
-
[40]
Yang, H.; Zhang, M.; Wei, D.; and Guo, J. 2024. Srag: speech retrieval augmented generation for spoken language understanding. In 2024 IEEE 2nd International Conference on Control, Electronics and Computer Technology (ICCECT), 370--374. IEEE
work page 2024
-
[41]
Yao, Y.; Li, Z.; and Zhao, H. 2024. SirLLM: Streaming Infinite Retentive LLM. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 2611--2624
work page 2024
- [42]
-
[43]
Zhao, Y.; Li, Z.; Zhao, H.; Qi, B.; and Guoming, L. 2025. DAC: A Dynamic Attention-aware Approach for Task-Agnostic Prompt Compression. In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 19395--19407
work page 2025
-
[44]
Zhao, Z.; Jiang, Y.; Liu, H.; Wang, Y.; and Wang, Y. 2024. LibriSQA: A Novel Dataset and Framework for Spoken Question Answering with Large Language Models. IEEE Transactions on Artificial Intelligence
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.