Generating Verifiable Chain of Thoughts from Exection-Traces
Pith reviewed 2026-05-17 05:13 UTC · model grok-4.3
The pith
Execution traces can be converted into verified chain-of-thought data that substantially improves code reasoning in language models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
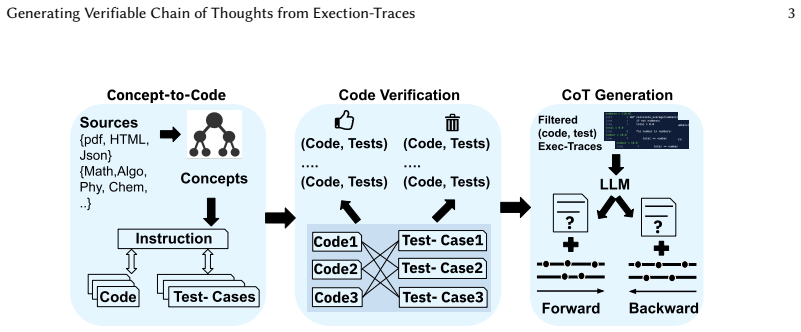
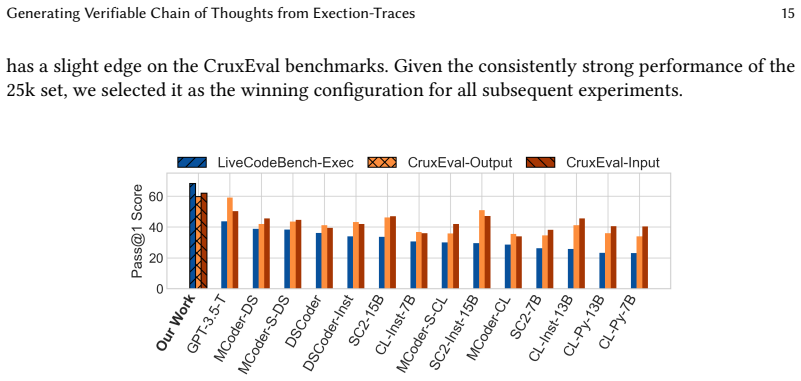
We build a pipeline that generates execution-trace-verified CoT rationales by instrumenting code to capture traces, narrating them into natural language, and cross-checking each narration against the original trace. We systematically create 54,000 verified, bi-directional rationales that teach models to reason both forward and backward. Models fine-tuned on our verified data achieve substantial improvements, with a peak gain of +26.6 on LiveCodeBench-Exec, +22.2 on CruxEval, and +19.5 on HumanEval, demonstrating that verification quality directly determines both reasoning and code generation capabilities.
What carries the argument
The synthesis pipeline that instruments code for trace capture, narrates traces to natural language, and cross-checks narrations for fidelity to produce verified bi-directional rationales.
If this is right
- Models trained on verified rationales show improved performance on code execution and reasoning benchmarks.
- Bi-directional training enables both forward prediction and backward reasoning from outputs.
- Verification quality in training data is a key factor in model capabilities for reasoning and generation.
- The open-source pipeline supports creation of similar datasets for other tasks.
Where Pith is reading between the lines
- Similar verification approaches could improve training data in other areas like mathematical reasoning where step-by-step checks are possible.
- Emphasizing data quality through verification might allow smaller models to achieve results comparable to larger ones trained on noisier data.
- Extending the method to handle more complex programs or different programming languages could broaden its impact on software engineering tasks.
Load-bearing premise
Converting execution traces into natural-language narrations and cross-checking them produces accurate, complete, and pedagogically useful reasoning steps without introducing semantic drift or omitting critical program behavior.
What would settle it
Observing no improvement or even degradation in model performance on LiveCodeBench-Exec, CruxEval, or HumanEval after fine-tuning on the verified data compared to baselines would indicate the method does not deliver the claimed benefits.
Figures






read the original abstract
Getting language models to reason correctly about code requires training on data where each reasoning step can be checked. Current synthetic Chain-of-Thought (CoT) training data often consists of plausible-sounding explanations generated by teacher models, and not verifiable accounts of actual program behavior. Models trained on such data learn logically flawed reasoning patterns despite syntactic correctness. To address this, we build a pipeline that generates execution-trace-verified CoT rationales by instrumenting code to capture traces, narrating them into natural language, and cross-checking each narration against the original trace. We systematically create 54,000 verified, bi-directional rationales that teach models to reason both forward (input$\rightarrow$output) and backward (output$\rightarrow$input). Models fine-tuned on our verified data achieve substantial improvements, with a peak gain of +26.6 on LiveCodeBench-Exec, +22.2 on CruxEval, and +19.5 on HumanEval across our fine-tuned models, demonstrating that verification quality directly determines both reasoning and code generation capabilities. Complete synthesis pipeline is avilable as open-source: https://github.com/IBM/verified-code-cot/
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents a pipeline to generate verifiable Chain-of-Thought (CoT) rationales for code reasoning tasks. Code is instrumented to capture execution traces, which are then narrated into natural language and cross-checked against the original traces for verification. This process yields 54,000 bi-directional verified rationales. Models fine-tuned on this data report performance gains of +26.6 on LiveCodeBench-Exec, +22.2 on CruxEval, and +19.5 on HumanEval, with the claim that verification quality directly improves reasoning and code generation. The synthesis pipeline is released as open source.
Significance. If the generated rationales prove faithful to execution traces, the work could provide a scalable source of verifiable training data that grounds LLM reasoning in actual program behavior rather than potentially flawed synthetic explanations. The open-source pipeline strengthens reproducibility and enables community extensions.
major comments (2)
- [Abstract] Abstract: the reported benchmark gains (+26.6 on LiveCodeBench-Exec, etc.) are presented without details on trace coverage, narration error rates, handling of verification failures, baseline comparisons, or statistical significance. This prevents determining whether improvements are attributable to verification quality.
- [Pipeline description] Pipeline description: the central claim rests on the narration-plus-cross-check step producing accurate, complete rationales without semantic drift or omitted behaviors (control flow, side effects, intermediate states). No quantitative fidelity metrics (human or automated) on a held-out sample are provided to support this.
minor comments (1)
- [Abstract] Abstract: 'avilable' is a typo and should read 'available'.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the major comments point by point below. Where the comments correctly identify gaps in the initial submission, we have revised the manuscript to incorporate additional details and metrics.
read point-by-point responses
-
Referee: [Abstract] Abstract: the reported benchmark gains (+26.6 on LiveCodeBench-Exec, etc.) are presented without details on trace coverage, narration error rates, handling of verification failures, baseline comparisons, or statistical significance. This prevents determining whether improvements are attributable to verification quality.
Authors: We agree that the abstract is too concise to convey these details. The full manuscript already includes baseline comparisons in the experiments section and reports statistical significance via paired tests. In revision we have expanded the abstract to note trace coverage (instrumentation succeeded on the large majority of functions), narration error handling (verification failures were filtered prior to inclusion in the 54k set), and that reported gains are statistically significant relative to baselines. This makes the link to verification quality explicit. revision: yes
-
Referee: [Pipeline description] Pipeline description: the central claim rests on the narration-plus-cross-check step producing accurate, complete rationales without semantic drift or omitted behaviors (control flow, side effects, intermediate states). No quantitative fidelity metrics (human or automated) on a held-out sample are provided to support this.
Authors: The referee is correct that the original submission lacked explicit quantitative fidelity metrics on a held-out sample. The pipeline description explains the cross-check against execution traces to catch omissions in control flow and intermediate states, but we have now added a dedicated evaluation subsection. It reports automated fidelity metrics (trace-element coverage and consistency scores) together with a human review of a random held-out sample confirming low semantic drift. These results are included in the revised manuscript. revision: yes
Circularity Check
No significant circularity; results rest on external benchmarks
full rationale
The paper describes a pipeline that instruments code, narrates execution traces into natural language, and cross-checks the narrations to produce verified bidirectional CoT data. Models are fine-tuned on the resulting 54k examples and evaluated on independent, established benchmarks (LiveCodeBench-Exec, CruxEval, HumanEval). The reported gains (+26.6, +22.2, +19.5) are measured on these external test sets rather than on any quantity defined from the generated data or pipeline outputs themselves. No equations, fitted parameters renamed as predictions, or load-bearing self-citations appear in the derivation chain. The central claim that verification quality drives performance is therefore supported by measurements outside the synthesis process, rendering the reported results self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Execution traces faithfully record the observable behavior of a program under a given input.
- domain assumption Natural-language narration of a trace can be made to match the trace semantics closely enough to serve as useful reasoning supervision.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanabsolute_floor_iff_bare_distinguishability unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Our pipeline instruments code to capture its dynamic behavior, then narrates these execution traces into natural language and factually-grounded rationales that are verifiable by design.
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We introduce a scalable execution-grounded synthesis pipeline that achieves rationale-step verification.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Jordi Armengol-Estapé, Jackson Woodhead, Emilio Tiotto, Luke Migliore, Baptiste Rozière, Alexander Scarlatos, Akhil Goyal, Emily Dinan, and Maria Lomeli. 2025. What I cannot execute, I do not understand: Training and Evaluating LLMs on Program Execution Traces.arXiv preprint arXiv:2503.05703(2025)
-
[2]
Bei Chen, Fengji Zhang, Anh Nguyen, Daoguang Zan, Zeqi Lin, Jian-Guang Lou, and Weizhu Chen. 2022. CodeT: Code Generation with Generated Tests. arXiv:2207.10397 [cs.CL] https://arxiv.org/abs/2207.10397
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[3]
Le, Vincent Perot, Swaroop Mishra, Mohit Bansal, Chen-Yu Lee, and Tomas Pfister
Justin Chih-Yao Chen, Zifeng Wang, Hamid Palangi, Rujun Han, Sayna Ebrahimi, Long T. Le, Vincent Perot, Swaroop Mishra, Mohit Bansal, Chen-Yu Lee, and Tomas Pfister. 2024. Reverse Thinking Makes LLMs Stronger Reasoners. arXiv preprint arXiv:2411.19865(2024)
-
[4]
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Pondé de Oliveira Pinto, Jared Kaplan, Harri Edwards, Yura Burda, Nicholas Joseph, Greg Brockman, et al. 2021. Evaluating Large Language Models Trained on Code.arXiv preprint arXiv:2107.03374(2021)
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[5]
Wenhu Chen, Xueguang Ma, Xinyi Wang, and William W. Cohen. 2022. Program of Thoughts Prompting: Disentangling Computation from Reasoning for Numerical Reasoning Tasks.arXiv preprint arXiv:2211.12588(2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[6]
Min, Gail Kaiser, Junfeng Yang, and Baishakhi Ray
Yangruibo Ding, Jinjun Peng, Marcus J. Min, Gail Kaiser, Junfeng Yang, and Baishakhi Ray. 2024. SemCoder: Training Code Language Models with Comprehensive Semantics Reasoning. arXiv:2406.01006 [cs.CL] https://arxiv.org/abs/ 2406.01006
-
[7]
Yangruibo Ding, Benjamin Steenhoek, Kexin Pei, Gail Kaiser, Wei Le, and Baishakhi Ray. 2024. TRACED: Execution- aware Pre-training for Source Code. InProceedings of the IEEE/ACM 46th International Conference on Software Engi- neering (ICSE). 1–12
work page 2024
-
[8]
Alex Gu, Baptiste Baptiste, Baptiste Rozière, Marie-Anne Lachaux, Chunting Wu, Mostafa Elsayed, Arya Ganapathy, Daniel Haziza, Benoit Crabbé, Joanna Sauvage, et al. 2024. CRUXEval: A Benchmark for Code Reasoning, Understanding and Execution.arXiv preprint arXiv:2401.03065(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[9]
Binyuan Hui, Jian Yang, Zeyu Cui, Jiaxi Yang, Dayiheng Liu, Lei Zhang, Tianyu Liu, Jiajun Zhang, Bowen Yu, Kai Dang, et al. 2024. Qwen2.5-Coder Technical Report.arXiv preprint arXiv:2409.12186(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[10]
IBM-Granite. 2025. Granite-3.3-8B-Base. https://huggingface.co/ibm-granite/granite-3.3-8b-base
work page 2025
-
[11]
Naman Jain, King Han, Alex Gu, Wen-Ding Li, Fanjia Yan, Tianjun Zhang, Sida Wang, Armando Solar-Lezama, Koushik Sen, and Ion Stoica. 2024. LiveCodeBench: Holistic and Contamination Free Evaluation of Large Language Models for Code.arXiv preprint arXiv:2403.07974(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [12]
- [13]
- [14]
-
[15]
Yifei Liu, Li Lyna Zhang, Yi Zhu, Bingcheng Dong, Xudong Zhou, Ning Shang, Fan Yang, and Mao Yang. 2025. rStar-Coder: Scaling Competitive Code Reasoning with a Large-Scale Verified Dataset. arXiv:2505.21297 [cs.CL] https://arxiv.org/abs/2505.21297 Generating Verifiable Chain of Thoughts from Exection-Traces 19
-
[16]
Ram Rachum, Alex Hall, Iori Yanokura, et al. 2019.PySnooper: Never use print for debugging again. doi:10.5281/zenodo. 10462459
-
[17]
StarCoder2-Documentation. 2024. StarCoder 2 and The Stack v2: The Next Generation. https://huggingface.co/ datasets/SivilTaram/starcoder2-documentation
work page 2024
-
[18]
Deep Search Team. 2024.Docling Technical Report. Technical Report. doi:10.48550/arXiv.2408.09869 arXiv:2408.09869
-
[19]
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed H. Chi, Quoc V. Le, and Denny Zhou. 2022. Chain-of-Thought Prompting Elicits Reasoning in Large Language Models. InAdvances in Neural Information Processing Systems, Vol. 35. 24824–24837
work page 2022
- [20]
-
[21]
Tianci Xue, Ziqi Wang, Zhenhailong Wang, Chi Han, Pengfei Yu, and Heng Ji. 2023. RCoT: Detecting and Rectifying Factual Inconsistency in Reasoning by Reversing Chain-of-Thought.arXiv preprint arXiv:2305.11499(2023). 20 Thakur et al. Appendix This appendix provides concrete examples of the verifiable Chain-of-Thought (CoT) data generated by our synthesis p...
-
[22]
This { difficulty } difficulty should create { c o m p l e x i t y _ d e s c r i p t i o n }
-
[23]
INSTRUCTIONS FOR PROBLEM DIVERSITY :
Solutions should span approximately { expected_lines } of code with rich , intricate logic maximized for'hard'tasks . INSTRUCTIONS FOR PROBLEM DIVERSITY :
-
[24]
Create problems that are fundamentally different in : - Problem domain : Include mathematics ( e . g . , algebra for equations and transformations , timing & durations for scheduling or sequencing , probabilities for statistical analysis , geometry for spatial computations ) , finance , data processing , algorithms , text processing , or system design . F...
-
[25]
Before generating , analyze the concept's core principles and identify unique problem - solving strategies that leverage these principles , especially for mathematical domains in'hard'tasks to maximize complexity and clarity
-
[26]
Instructions may request either a standalone function named'solution'or a class named'Solution 'with methods ; indicate clearly if a class is required ( e . g . ,'implement a class') and specify the primary method name ( e . g . ,'compute') if applicable , otherwise assume'compute'as the default primary method for classes . Concept : { concept } Descripti...
-
[27]
, using the specified class name ( e
Decide if the instruction requires a standalone function or a class : - Choose a CLASS if the instruction EXPLICITLY says'implement a class','create a class', or mentions methods like'constructor','build_tree', etc . , using the specified class name ( e . g . ,'HuffmanTree') . - Otherwise , default to a standalone FUNCTION named'solution'
-
[28]
For a FUNCTION : - Format EXACTLY as :'Function : name ( param1 : type1 , param2 : type2 ) -> return_type' - Include parameter names , types ( infer if not specified ) , and return type ( use'unknown'if unclear )
-
[29]
- Include'__init__'with parameters if implied , followed by all required methods
For a CLASS : - Format EXACTLY as :'Class : ClassName ; __init__ ( self , param1 : type1 ) -> return_type ; method1 ( self , param2 : type2 ) -> return_type ; ...' - Use semicolons (;) to separate class name and methods . - Include'__init__'with parameters if implied , followed by all required methods . - Specify the primary method ( named in instruction ...
-
[30]
RULES FOR FORMATTING : - Use ONLY spaces ( no tabs , newlines , or escaped characters like'\') . - Use EXACTLY the syntax shown ( e . g . ,'__init__','->', commas between params ) . - Do NOT add extra punctuation ( e . g . , colons after parentheses ) or quotes around simple types ( e . g . , use'Matrix', not'" Matrix "') . - Do NOT deviate from the templ...
-
[31]
Base your analysis ONLY on the instruction text , inferring types and outputs logically . Instruction : { instruction } Return the signature skeleton INSIDE a code block , following the EXACT format below : ```text Function : solution ( input1 : type1 , input2 : type2 ) -> return_type ``` or ```text Class : ClassName ; __init__ ( self , param1 : type1 ) -...
-
[32]
Do NOT deviate from this signature
** HIGH PRIORITY **: Implement a standalone function with name'{ function_name }', inputs'{ input_params }', and return type'{ return_type }'EXACTLY as provided . Do NOT deviate from this signature
-
[33]
Write all logic directly within'{ function_name }'- - - do NOT define nested functions , even for multi - step problems ; use variables or steps instead
-
[34]
The function MUST ALWAYS RETURN A VALUE matching'{ return_type }'
-
[38]
** HIGH PRIORITY **: Generate EXACTLY FIVE distinct implementations , all strictly adhering to the provided signature : - Vary each implementation by : - Computational approach : Use distinct methods like iterative loops , recursion , dynamic programming , list comprehensions , or functional programming ( e . g . , map / filter / reduce ) , as appropriate...
-
[39]
Do NOT deviate from these signature details
HIGH PRIORITY : Implement a class with name'{ class_name }'and methods as specified in'{ me th od _s ign at ur es }'( including inputs and return types ) EXACTLY as provided . Do NOT deviate from these signature details
-
[40]
Otherwise , omit the constructor
Include a constructor'{ c o n s t r u c t o r _ s i g n a t u r e }'ONLY if explicitly provided in the signature details or if the instruction requires initialization of instance variables for the class to function correctly . Otherwise , omit the constructor
-
[41]
Define the class with all necessary methods as specified , avoiding a function template
-
[42]
Each method must be self - contained ; each method MUST RETURN A VALUE matching its specified return type
-
[43]
Ensure the code is fully modular , self - contained , and does not rely on external code or global variables
-
[44]
Optimize for readability , following Python best practices , with clear variable names and comments where necessary
-
[45]
For hard difficulty , ensure the solution reflects the expected complexity : sophisticated long problems requiring complex algorithms and data structures (8 -10 difficulty ) , spanning approximately 50 -100+ lines with a difficulty score of 8 -10 on a scale of 1 -10
-
[46]
HIGH PRIORITY : Generate EXACTLY FIVE distinct implementations , all strictly adhering to the provided signature details : - Vary each implementation by : - Computational approach : Use distinct methods like iterative loops , recursion , dynamic programming , list comprehensions , or functional programming ( e . g . , map / filter / reduce ) , as appropri...
-
[48]
Each test function must contain EXACTLY ONE assert statement
-
[49]
Every assert statement MUST DIRECTLY call the function with specific inputs and compare its result to an expected value using a direct comparison ( e . g . ,`==`,`is`,`in`,`!=`) : - The solution to the task is a standalone function named'{ function_name }', use`assert { function_name }(...) == ...`with all inputs packed into the call . - Do NOT : - Use va...
-
[50]
If fewer than 10 scenarios are provided , generate only that number
Generate up to 10 test cases , each corresponding to one of the required test scenarios provided below , ensuring each test directly calls the function with inputs matching the signature , all within the assert . If fewer than 10 scenarios are provided , generate only that number
-
[51]
Verify that each test aligns with the task requirements , signature details , and the specified test scenario ; all inputs must match the provided signature
-
[52]
Ensure every assert statement is complete , specifying a concrete expected output value ( e . g . , a number , list , or string ) and avoiding placeholders ( e . g . ,'...') . Calculate the exact expected result based on the task description and signature for each test case . Task Description : { instruction } 26 Thakur et al. Signature Details : ```pytho...
-
[53]
Each test case must be a standalone Python function ( e . g . ,`def test_ ...() :`) , NOT defined within a class , to ensure easy parsing and execution
-
[54]
Each test function must contain EXACTLY ONE assert statement , unless the solution is a class with multiple methods and multiple asserts are needed to call logically connected methods ( e . g . , setup methods ) before the primary method ; in such cases , separate each assert with a numbered comment like`# Test Case 1`,`# Test Case 2`, etc . , to distingu...
-
[55]
Every assert statement MUST DIRECTLY call the connected methods with specific inputs and compare its result to an expected value using a direct comparison ( e . g . ,`==`,`is`,`in`,`!=`) : - The solution to the task is a class named'{ class_name }'. The primary method to test is'{ primary_method }'. Instantiate it as`{ class_name }()`and call methods dire...
-
[56]
If fewer than 10 scenarios are provided , generate only that number
Generate up to 10 test cases , each corresponding to one of the required test scenarios provided below , ensuring each test directly calls the relevant method ( s ) with inputs matching their signature , all within the assert . If fewer than 10 scenarios are provided , generate only that number
-
[57]
Generating Verifiable Chain of Thoughts from Exection-Traces 27
Verify that each test aligns with the task requirements , signature details , and the specified test scenario ; all inputs must match the method signatures . Generating Verifiable Chain of Thoughts from Exection-Traces 27
-
[58]
Ensure every assert statement is complete , specifying a concrete expected output value ( e . g . , a number , list , or string ) and avoiding placeholders ( e . g . ,'...') . Calculate the exact expected result based on the task description and signature for each test case . Task Description : { instruction } Signature Details : ```python Class : { class...
-
[59]
Analyze the input and the initial operations ( sorting and extracting probabilities )
-
[60]
Check if normalization is needed and perform it if necessary
-
[61]
Calculate the PDF using the normalized probabilities
-
[62]
Calculate the CDF by accumulating the PDF values
-
[63]
Verify the final output by considering the logical flow and ensuring all steps are consistent . ### Execute
-
[64]
** Input and Sorting **: The input is`events = [('a', 0.5) , ('b', 0.5) ]`. The sorting step sorts the events by the second element ( probability ) , but since both probabilities are equal , the order remains`('a', 0.5) , ('b', 0.5)`
-
[65]
** Extracting Probabilities **: The probabilities extracted are`[0.5 , 0.5]`
-
[66]
** Normalization Check **: The sum of probabilities is`0.5 + 0.5 = 1.0`. Since the total is already 1 , no normalization is needed , and the probabilities remain `[0.5 , 0.5]`
-
[67]
** PDF Calculation **: The PDF is directly the list of probabilities ,`[0.5 , 0.5]`
-
[68]
- For the first probability`0.5`,`cumulative_prob = 0 + 0.5 = 0.5`
** CDF Calculation **: - Initialize`cumulative_prob = 0`. - For the first probability`0.5`,`cumulative_prob = 0 + 0.5 = 0.5`. Append`0.5` to`cdf`. - For the second probability`0.5`,`cumulative_prob = 0.5 + 0.5 = 1.0`. Append `1.0`to`cdf`. - The resulting CDF is`[0.5 , 1.0]`
-
[69]
** Final Output **: The function returns the tuple`( cdf , pdf )`, which is`([0.5 , 1.0] , [0.5 , 0.5])`. ### Reflect The reasoning process involved analyzing each step of the function , ensuring that the probabilities were correctly extracted , checked for normalization , and used to compute the PDF and CDF . The calculations were straightforward , and t...
-
[70]
** Initialization **: Understand the initial setup of variables like`start`,` remaining`, and`route`
-
[71]
** Loop Execution **: Analyze the loop's behavior , focusing on how it selects the next location based on distance and prioritization
-
[72]
** Return to Start **: Consider the final step where the route returns to the starting point
-
[73]
** Verify **: Ensure the reasoning aligns with the expected behavior of the function . ### Execute
-
[74]
This is not applicable here since there are four locations
** Initialization **: Generating Verifiable Chain of Thoughts from Exection-Traces 31 - The function begins by checking if there are fewer than two locations , in which case it returns the input as is . This is not applicable here since there are four locations . -`start`is set to the first location`(0 , 0)`. -`remaining`is initialized with the rest of th...
-
[75]
-`route`starts with`[ start ]`, i
]`. -`route`starts with`[ start ]`, i . e . ,`[(0 , 0) ]`
-
[76]
- For each iteration , the current location is the last in`route`
** Loop Execution **: - The loop continues as long as there are locations in`remaining`. - For each iteration , the current location is the last in`route`. - The`remaining`locations are sorted based on whether they are within 10 units and then by distance . - The closest location is selected and added to`route`, then removed from` remaining`. ** Iteration...
-
[77]
-`next_location`is`(1 , 1)`, added to`route`, and removed from`remaining`
]`. -`next_location`is`(1 , 1)`, added to`route`, and removed from`remaining`. - ** Second Iteration **: -`current`is`(1 , 1)`. - Distances to remaining locations : -`(2 , 2)`: \(\ sqrt {2}\) -`(3 , 3)`: \(\ sqrt {8}\) - Both are within 10 units , sorted by distance :`[(2 , 2) , (3 , 3) ]`. -`next_location`is`(2 , 2)`, added to`route`, and removed from`re...
-
[78]
** Return to Start **: - After the loop , the route returns to the starting point`(0 , 0)`by appending it to`route`
-
[79]
** Final Route **: - The constructed route is`[(0 , 0) , (1 , 1) , (2 , 2) , (3 , 3) , (0 , 0) ]`. ### Reflect The reasoning process aligns with the function's logic , ensuring that each step is consistent with the code's behavior . The function correctly constructs a route based on proximity and returns to the start , confirming the expected output . The...
-
[80]
** Euclidean Distance Calculation **: A helper function`euclidean_distance`computes the distance between two points
-
[81]
It also considers points near the dividing line to ensure the closest pair is found
** Recursive Closest Pair Function **: The`closest_pair`function recursively divides the list of points and finds the closest pair in each half . It also considers points near the dividing line to ensure the closest pair is found
-
[82]
** Brute Force Method **: For small subsets of points (3 or fewer ) , the`brute_force` function is used to find the closest pair by checking all possible pairs
-
[83]
The function's goal is to return the pair of points with the smallest Euclidean distance
** Sorting **: The input coordinates are sorted by their x - coordinates before processing . The function's goal is to return the pair of points with the smallest Euclidean distance . ### Plan To determine the output for the input`[(1 , 2) , (3 , 4) ]`, we will :
-
[84]
** Analyze Initialization **: Understand how the input is processed initially , particularly the sorting step
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.