IGen: Scalable Data Generation for Robot Learning from Open-World Images
Pith reviewed 2026-05-17 02:54 UTC · model grok-4.3
The pith
Open-world images can be converted into scalable, executable robot training data that produces policies matching real-world performance.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
IGen converts unstructured open-world images into structured 3D scene representations, then applies vision-language models to produce high-level plans and low-level SE(3) end-effector pose sequences; these poses are used to synthesize dynamic scene evolution and render temporally coherent visual observations, yielding visuomotor data whose quality is high enough that policies trained solely on it achieve performance comparable to policies trained on real-world robot data.
What carries the argument
The IGen pipeline that lifts 2D pixels into 3D representations and uses vision-language models to generate high-level plans together with low-level SE(3) end-effector pose sequences for synthesizing realistic dynamic trajectories.
If this is right
- Robot training data can be generated at large scale from any collection of open-world images without physical robot runs.
- Policies gain exposure to far greater scene diversity than is feasible with conventional on-robot collection.
- Generated actions are specified as executable SE(3) pose sequences that can be transferred directly to real robots.
- Temporally coherent rendered observations support training of policies that must act over sequences of frames.
- The overall need for labor-intensive real-world data collection for generalist policies is reduced.
Where Pith is reading between the lines
- If IGen data matches real performance, mixing small amounts of real data with large IGen sets could improve robustness at lower cost.
- The same image-to-3D-to-action pipeline could be tested on navigation or mobile manipulation by adapting the pose generation step.
- Internet-scale photo collections could become a primary resource for robot datasets if the synthesis quality generalizes across domains.
- Future experiments could measure how much additional real data is still needed to close any remaining performance gap.
Load-bearing premise
The vision-language model outputs and subsequent rendering steps produce actions and scene changes that remain close enough to real robot execution to avoid large distribution shifts.
What would settle it
Train identical policy architectures on IGen-generated data versus real robot trajectories for the same manipulation tasks in matched environments and measure whether the IGen-trained policy reaches at least 80 percent of the real-data policy's success rate.
Figures



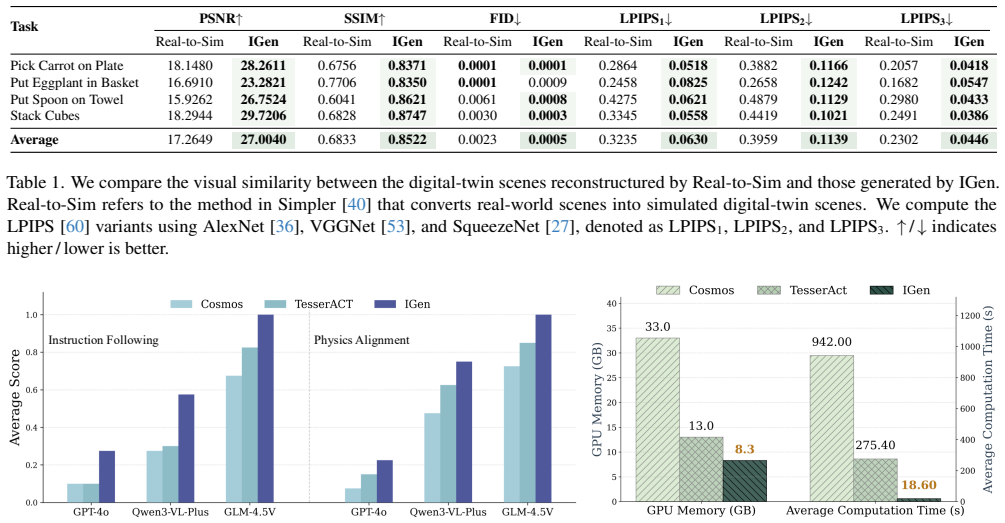

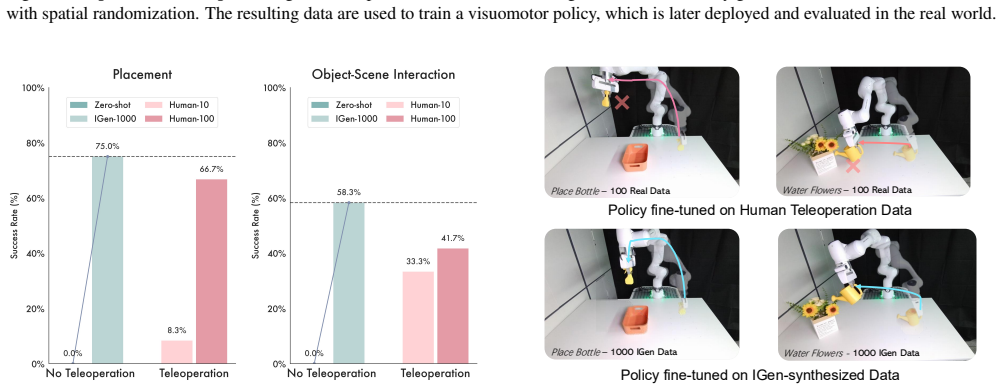








read the original abstract
The rise of generalist robotic policies has created an exponential demand for large-scale training data. However, on-robot data collection is labor-intensive and often limited to specific environments. In contrast, open-world images capture a vast diversity of real-world scenes that naturally align with robotic manipulation tasks, offering a promising avenue for low-cost, large-scale robot data acquisition. Despite this potential, the lack of associated robot actions hinders the practical use of open-world images for robot learning, leaving this rich visual resource largely unexploited. To bridge this gap, we propose IGen, a framework that scalably generates realistic visual observations and executable actions from open-world images. IGen first converts unstructured 2D pixels into structured 3D scene representations suitable for scene understanding and manipulation. It then leverages the reasoning capabilities of vision-language models to transform scene-specific task instructions into high-level plans and generate low-level actions as SE(3) end-effector pose sequences. From these poses, it synthesizes dynamic scene evolution and renders temporally coherent visual observations. Experiments validate the high quality of visuomotor data generated by IGen, and show that policies trained solely on IGen-synthesized data achieve performance comparable to those trained on real-world data. This highlights the potential of IGen to support scalable data generation from open-world images for generalist robotic policy training.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces IGen, a pipeline that converts open-world 2D images into structured 3D scene representations, employs vision-language models to derive high-level task plans and low-level SE(3) end-effector pose sequences from scene-specific instructions, synthesizes dynamic scene evolution from those poses, and renders temporally coherent visual observations. The central claim is that the resulting visuomotor data is high-quality and that policies trained exclusively on IGen-generated data achieve performance comparable to policies trained on real-world robot data.
Significance. If the comparability claim is substantiated with quantitative evidence, IGen would provide a scalable route to leverage abundant open-world images for robot learning, substantially lowering the cost and environmental constraints of on-robot data collection for generalist policies.
major comments (2)
- [Abstract] Abstract: the statement that 'experiments validate the high quality of visuomotor data generated by IGen, and show that policies trained solely on IGen-synthesized data achieve performance comparable to those trained on real-world data' is unsupported by any reported metrics, baselines, success rates, task suite definitions, trial counts, or controls for distribution shift. This directly undermines the central claim and requires explicit quantitative comparison (e.g., success-rate deltas and ablation removing dynamics synthesis).
- [Method / Experiments] Method and Experiments: the pipeline assumes that VLM-generated SE(3) pose sequences, when used to drive 3D scene evolution and rendering, produce observation-action pairs whose distribution matches real robot execution closely enough for zero-shot policy transfer. No ablation or control (e.g., rendered vs. real images under identical policies, or contact/occlusion statistics) is described to test this assumption, which is load-bearing for the sim-to-real transfer result.
minor comments (2)
- [Method] Clarify the precise algorithm or parameters used for synthesizing dynamic scene evolution from the SE(3) pose sequences (e.g., interpolation method, physics model).
- [Experiments] Add a table or figure summarizing the exact policy architectures, training hyperparameters, and evaluation environments used in the comparability experiments.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. We address each of the major comments below and outline the revisions we will make to the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the statement that 'experiments validate the high quality of visuomotor data generated by IGen, and show that policies trained solely on IGen-synthesized data achieve performance comparable to those trained on real-world data' is unsupported by any reported metrics, baselines, success rates, task suite definitions, trial counts, or controls for distribution shift. This directly undermines the central claim and requires explicit quantitative comparison (e.g., success-rate deltas and ablation removing dynamics synthesis).
Authors: We agree with the referee that the abstract's claim would be strengthened by explicit quantitative evidence. We will revise the abstract and add to the experiments section detailed metrics including success rates, baselines, task suite definitions, trial counts, and an ablation removing the dynamics synthesis component to support the comparability to real-world data. revision: yes
-
Referee: [Method / Experiments] Method and Experiments: the pipeline assumes that VLM-generated SE(3) pose sequences, when used to drive 3D scene evolution and rendering, produce observation-action pairs whose distribution matches real robot execution closely enough for zero-shot policy transfer. No ablation or control (e.g., rendered vs. real images under identical policies, or contact/occlusion statistics) is described to test this assumption, which is load-bearing for the sim-to-real transfer result.
Authors: We agree that additional controls are necessary to substantiate the key assumption in our pipeline. We will revise the experiments section to include ablations such as training identical policies on rendered versus real images and reporting contact and occlusion statistics. This will help demonstrate the closeness of the generated data distribution to real robot executions. revision: yes
Circularity Check
No circularity detected; forward pipeline from images to data with empirical validation
full rationale
The paper describes IGen as a sequential, forward pipeline: 2D-to-3D conversion, VLM-based high-level planning and SE(3) pose sequence generation, dynamic scene synthesis, and rendering of observations. The claim that policies trained on IGen data achieve comparable performance is presented as an empirical experimental outcome rather than a mathematical derivation. No equations, fitted parameters, or steps reduce by construction to the inputs or to self-citations; the method does not invoke uniqueness theorems, ansatzes smuggled via prior work, or renamings of known results in a load-bearing way. The derivation chain remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Vision-language models can produce executable robot plans from scene descriptions
- domain assumption 3D scene representations extracted from 2D images are accurate enough for manipulation
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
IGen first converts unstructured 2D pixels into structured 3D scene representations... leverages... VLMs to transform... into high-level plans and generate low-level actions as SE(3) end-effector pose sequences... synthesizes dynamic scene evolution and renders temporally coherent visual observations.
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanembed_injective unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
policies trained solely on IGen-synthesized data achieve performance comparable to those trained on real-world data
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 2 Pith papers
-
MesonGS++: Post-training Compression of 3D Gaussian Splatting with Hyperparameter Searching
MesonGS++ achieves over 34x compression of 3D Gaussian Splatting models with preserved or improved PSNR by using size-aware joint optimization of pruning and quantization hyperparameters via discrete sampling and 0-1 ...
-
MesonGS++: Post-training Compression of 3D Gaussian Splatting with Hyperparameter Searching
MesonGS++ achieves over 34x compression of 3D Gaussian Splatting models post-training while preserving or exceeding original rendering quality through size-aware hyperparameter optimization.
Reference graph
Works this paper leans on
-
[1]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report.arXiv preprint arXiv:2303.08774, 2023. 2, 3, 4, 6, 8
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
Cosmos World Foundation Model Platform for Physical AI
Niket Agarwal, Arslan Ali, Maciej Bala, Yogesh Balaji, Erik Barker, Tiffany Cai, Prithvijit Chattopadhyay, Yongxin Chen, Yin Cui, Yifan Ding, et al. Cosmos world foundation model platform for physical ai.arXiv preprint arXiv:2501.03575,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, et al. Qwen2. 5-vl technical report.arXiv preprint arXiv:2502.13923, 2025. 2, 3, 4, 6, 8
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
GR00T N1: An Open Foundation Model for Generalist Humanoid Robots
Johan Bjorck, Fernando Casta ˜neda, Nikita Cherniadev, Xingye Da, Runyu Ding, Linxi Fan, Yu Fang, Dieter Fox, Fengyuan Hu, Spencer Huang, et al. Gr00t n1: An open foun- dation model for generalist humanoid robots.arXiv preprint arXiv:2503.14734, 2025. 2, 3
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
$\pi_0$: A Vision-Language-Action Flow Model for General Robot Control
Kevin Black, Noah Brown, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, Niccolo Fusai, Lachy Groom, Karol Hausman, Brian Ichter, et al. pi 0: A vision-language- action flow model for general robot control.arXiv preprint arXiv:2410.24164, 2024. 2, 3, 8
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[6]
Genie: Generative interactive environments
Jake Bruce, Michael D Dennis, Ashley Edwards, Jack Parker- Holder, Yuge Shi, Edward Hughes, Matthew Lai, Aditi Mavalankar, Richie Steigerwald, Chris Apps, et al. Genie: Generative interactive environments. InForty-first Interna- tional Conference on Machine Learning, 2024. 2
work page 2024
-
[7]
Fast-in-slow: a dual-system founda- tion model unifying fast manipulation within slow reasoning,
Hao Chen, Jiaming Liu, Chenyang Gu, Zhuoyang Liu, Ren- rui Zhang, Xiaoqi Li, Xiao He, Yandong Guo, Chi-Wing Fu, Shanghang Zhang, et al. Fast-in-slow: A dual-system founda- tion model unifying fast manipulation within slow reasoning. arXiv preprint arXiv:2506.01953, 2025. 3
-
[8]
Hanzhi Chen, Boyang Sun, Anran Zhang, Marc Pollefeys, and Stefan Leutenegger. Vidbot: Learning generalizable 3d actions from in-the-wild 2d human videos for zero-shot robotic manipulation. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 27661–27672,
-
[9]
Object-centric dexterous manipulation from human motion data.arXiv preprint arXiv:2411.04005, 2024
Yuanpei Chen, Chen Wang, Yaodong Yang, and C Karen Liu. Object-centric dexterous manipulation from human motion data.arXiv preprint arXiv:2411.04005, 2024. 3
-
[10]
Xuxin Cheng, Jialong Li, Shiqi Yang, Ge Yang, and Xiaolong Wang. Open-television: Teleoperation with immersive active visual feedback.arXiv preprint arXiv:2407.01512, 2024. 3
-
[11]
Cheng Chi, Zhenjia Xu, Siyuan Feng, Eric Cousineau, Yilun Du, Benjamin Burchfiel, Russ Tedrake, and Shuran Song. Diffusion policy: Visuomotor policy learning via action diffu- sion.The International Journal of Robotics Research, page 02783649241273668, 2023. 2
work page 2023
-
[12]
Universal Manipulation Interface: In-The-Wild Robot Teaching Without In-The-Wild Robots
Cheng Chi, Zhenjia Xu, Chuer Pan, Eric Cousineau, Ben- jamin Burchfiel, Siyuan Feng, Russ Tedrake, and Shu- ran Song. Universal manipulation interface: In-the-wild robot teaching without in-the-wild robots.arXiv preprint arXiv:2402.10329, 2024. 3
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[13]
Auto- mated creation of digital cousins for robust policy learning
Tianyuan Dai, Josiah Wong, Yunfan Jiang, Chen Wang, Cem Gokmen, Ruohan Zhang, Jiajun Wu, and Li Fei-Fei. Auto- mated creation of digital cousins for robust policy learning. arXiv preprint arXiv:2410.07408, 2024. 3
-
[14]
Runyu Ding, Yuzhe Qin, Jiyue Zhu, Chengzhe Jia, Shiqi Yang, Ruihan Yang, Xiaojuan Qi, and Xiaolong Wang. Bunny- visionpro: Real-time bimanual dexterous teleoperation for imitation learning.arXiv preprint arXiv:2407.03162, 2024. 3
-
[15]
Ar2-d2: Training a robot without a robot.arXiv preprint arXiv:2306.13818,
Jiafei Duan, Yi Ru Wang, Mohit Shridhar, Dieter Fox, and Ranjay Krishna. Ar2-d2: Training a robot without a robot. arXiv preprint arXiv:2306.13818, 2023. 3
-
[16]
Bridge Data: Boosting Generalization of Robotic Skills with Cross-Domain Datasets
Frederik Ebert, Yanlai Yang, Karl Schmeckpeper, Bernadette Bucher, Georgios Georgakis, Kostas Daniilidis, Chelsea Finn, and Sergey Levine. Bridge data: Boosting generalization of robotic skills with cross-domain datasets.arXiv preprint arXiv:2109.13396, 2021. 3
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[17]
Graspnet-1billion: A large-scale benchmark for general object grasping
Hao-Shu Fang, Chenxi Wang, Minghao Gou, and Cewu Lu. Graspnet-1billion: A large-scale benchmark for general object grasping. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 11444–11453,
-
[18]
Hao-Shu Fang, Hongjie Fang, Zhenyu Tang, Jirong Liu, Chenxi Wang, Junbo Wang, Haoyi Zhu, and Cewu Lu. Rh20t: A comprehensive robotic dataset for learning diverse skills in one-shot.arXiv preprint arXiv:2307.00595, 2023. 3
-
[19]
Mobile ALOHA: Learning Bimanual Mobile Manipulation with Low-Cost Whole-Body Teleoperation
Zipeng Fu, Tony Z Zhao, and Chelsea Finn. Mobile aloha: Learning bimanual mobile manipulation with low-cost whole- body teleoperation.arXiv preprint arXiv:2401.02117, 2024. 2
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[20]
Jensen Gao, Annie Xie, Ted Xiao, Chelsea Finn, and Dorsa Sadigh. Efficient data collection for robotic manip- ulation via compositional generalization.arXiv preprint arXiv:2403.05110, 2024. 3
-
[21]
Nicklas Hansen, Zhecheng Yuan, Yanjie Ze, Tongzhou Mu, Aravind Rajeswaran, Hao Su, Huazhe Xu, and Xiao- long Wang. On pre-training for visuo-motor control: Re- visiting a learning-from-scratch baseline.arXiv preprint arXiv:2212.05749, 2022. 2
-
[22]
LoRA: Low-rank adaptation of large language models
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen- Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. LoRA: Low-rank adaptation of large language models. In International Conference on Learning Representations, 2022. 8, 2
work page 2022
-
[23]
Mu Hu, Wei Yin, Chi Zhang, Zhipeng Cai, Xiaoxiao Long, Hao Chen, Kaixuan Wang, Gang Yu, Chunhua Shen, and Shaojie Shen. Metric3d v2: A versatile monocular geometric foundation model for zero-shot metric depth and surface nor- mal estimation.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2024. 3, 1
work page 2024
-
[24]
Huang Huang, Fangchen Liu, Letian Fu, Tingfan Wu, Mustafa Mukadam, Jitendra Malik, Ken Goldberg, and Pieter Abbeel. Otter: A vision-language-action model with text-aware visual feature extraction.arXiv preprint arXiv:2503.03734, 2025. 3
-
[25]
VoxPoser: Composable 3D Value Maps for Robotic Manipulation with Language Models
Wenlong Huang, Chen Wang, Ruohan Zhang, Yunzhu Li, Jiajun Wu, and Li Fei-Fei. V oxposer: Composable 3d value maps for robotic manipulation with language models.arXiv preprint arXiv:2307.05973, 2023. 3 9
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[26]
ReKep: Spatio-Temporal Reasoning of Relational Keypoint Constraints for Robotic Manipulation
Wenlong Huang, Chen Wang, Yunzhu Li, Ruohan Zhang, and Li Fei-Fei. Rekep: Spatio-temporal reasoning of relational keypoint constraints for robotic manipulation.arXiv preprint arXiv:2409.01652, 2024. 3
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[27]
SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and <0.5MB model size
Forrest N Iandola, Song Han, Matthew W Moskewicz, Khalid Ashraf, William J Dally, and Kurt Keutzer. Squeezenet: Alexnet-level accuracy with 50x fewer parameters and¡ 0.5 mb model size.arXiv preprint arXiv:1602.07360, 2016. 6
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[28]
$\pi_{0.5}$: a Vision-Language-Action Model with Open-World Generalization
Physical Intelligence, Kevin Black, Noah Brown, James Darpinian, Karan Dhabalia, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, Niccolo Fusai, et al. pi 0.5: a vision-language-action model with open-world generalization. arXiv preprint arXiv:2504.16054, 2025. 3
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[29]
Joel Jang, Seonghyeon Ye, Zongyu Lin, Jiannan Xiang, Jo- han Bjorck, Yu Fang, Fengyuan Hu, Spencer Huang, Kaushil Kundalia, Yen-Chen Lin, et al. Dreamgen: Unlocking gener- alization in robot learning through neural trajectories.arXiv e-prints, pages arXiv–2505, 2025. 2, 3, 6, 7
work page 2025
-
[30]
Yufei Jia, Guangyu Wang, Yuhang Dong, Junzhe Wu, Yu- pei Zeng, Haonan Lin, Zifan Wang, Haizhou Ge, Weibin Gu, Kairui Ding, et al. Discoverse: Efficient robot simula- tion in complex high-fidelity environments.arXiv preprint arXiv:2507.21981, 2025. 2, 3
-
[31]
Ditto: Build- ing digital twins of articulated objects from interaction
Zhenyu Jiang, Cheng-Chun Hsu, and Yuke Zhu. Ditto: Build- ing digital twins of articulated objects from interaction. In Proceedings of the IEEE/CVF Conference on Computer Vi- sion and Pattern Recognition, pages 5616–5626, 2022. 3
work page 2022
-
[32]
Dexmimicgen: Automated data generation for bimanual dex- terous manipulation via imitation learning
Zhenyu Jiang, Yuqi Xie, Kevin Lin, Zhenjia Xu, Weikang Wan, Ajay Mandlekar, Linxi Jim Fan, and Yuke Zhu. Dexmimicgen: Automated data generation for bimanual dex- terous manipulation via imitation learning. In2025 IEEE In- ternational Conference on Robotics and Automation (ICRA), pages 16923–16930. IEEE, 2025. 3
work page 2025
-
[33]
OpenVLA: An Open-Source Vision-Language-Action Model
Moo Jin Kim, Karl Pertsch, Siddharth Karamcheti, Ted Xiao, Ashwin Balakrishna, Suraj Nair, Rafael Rafailov, Ethan Foster, Grace Lam, Pannag Sanketi, et al. Openvla: An open-source vision-language-action model.arXiv preprint arXiv:2406.09246, 2024. 2, 3
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[34]
Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer White- head, Alexander C Berg, Wan-Yen Lo, et al. Segment any- thing. InProceedings of the IEEE/CVF international confer- ence on computer vision, pages 4015–4026, 2023. 3, 1
work page 2023
-
[35]
Po-Chen Ko, Jiayuan Mao, Yilun Du, Shao-Hua Sun, and Joshua B Tenenbaum. Learning to act from actionless videos through dense correspondences.arXiv preprint arXiv:2310.08576, 2023. 3
-
[36]
Im- agenet classification with deep convolutional neural networks
Alex Krizhevsky, Ilya Sutskever, and Geoffrey E Hinton. Im- agenet classification with deep convolutional neural networks. Advances in neural information processing systems, 25, 2012. 6
work page 2012
-
[37]
Hugo Laurenc ¸on, L´eo Tronchon, Matthieu Cord, and Victor Sanh. What matters when building vision-language mod- els?Advances in Neural Information Processing Systems, 37: 87874–87907, 2024. 2
work page 2024
-
[38]
Any6d: Model-free 6d pose estimation of novel objects
Taeyeop Lee, Bowen Wen, Minjun Kang, Gyuree Kang, In So Kweon, and Kuk-Jin Yoon. Any6d: Model-free 6d pose estimation of novel objects. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 11633– 11643, 2025. 4
work page 2025
-
[39]
Phantom: Training robots without robots using only human videos.arXiv preprint arXiv:2503.00779,
Marion Lepert, Jiaying Fang, and Jeannette Bohg. Phan- tom: Training robots without robots using only human videos. arXiv preprint arXiv:2503.00779, 2025. 3
-
[40]
Evaluating Real-World Robot Manipulation Policies in Simulation
Xuanlin Li, Kyle Hsu, Jiayuan Gu, Karl Pertsch, Oier Mees, Homer Rich Walke, Chuyuan Fu, Ishikaa Lunawat, Isabel Sieh, Sean Kirmani, et al. Evaluating real-world robot manipulation policies in simulation.arXiv preprint arXiv:2405.05941, 2024. 3, 6
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[41]
Xinhai Li, Jialin Li, Ziheng Zhang, Rui Zhang, Fan Jia, Tian- cai Wang, Haoqiang Fan, Kuo-Kun Tseng, and Ruiping Wang. Robogsim: A real2sim2real robotic gaussian splatting simu- lator.arXiv preprint arXiv:2411.11839, 2024. 2, 3
-
[42]
HybridVLA: Collaborative Diffusion and Autoregression in a Unified Vision-Language-Action Model
Jiaming Liu, Hao Chen, Pengju An, Zhuoyang Liu, Renrui Zhang, Chenyang Gu, Xiaoqi Li, Ziyu Guo, Sixiang Chen, Mengzhen Liu, et al. Hybridvla: Collaborative diffusion and autoregression in a unified vision-language-action model. arXiv preprint arXiv:2503.10631, 2025. 3
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[43]
Robo-gs: A physics consistent spatial- temporal model for robotic arm with hybrid representation
Haozhe Lou, Yurong Liu, Yike Pan, Yiran Geng, Jianteng Chen, Wenlong Ma, Chenglong Li, Lin Wang, Hengzhen Feng, Lu Shi, et al. Robo-gs: A physics consistent spatial- temporal model for robotic arm with hybrid representation. In2025 IEEE International Conference on Robotics and Au- tomation (ICRA), pages 15379–15386. IEEE, 2025. 2, 3
work page 2025
-
[44]
DeepSeek-VL: Towards Real-World Vision-Language Understanding
Haoyu Lu, Wen Liu, Bo Zhang, Bingxuan Wang, Kai Dong, Bo Liu, Jingxiang Sun, Tongzheng Ren, Zhuoshu Li, Hao Yang, et al. Deepseek-vl: towards real-world vision-language understanding.arXiv preprint arXiv:2403.05525, 2024. 2, 3
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[45]
MimicGen: A Data Generation System for Scalable Robot Learning using Human Demonstrations
Ajay Mandlekar, Soroush Nasiriany, Bowen Wen, Iretiayo Akinola, Yashraj Narang, Linxi Fan, Yuke Zhu, and Dieter Fox. Mimicgen: A data generation system for scalable robot learning using human demonstrations.arXiv preprint arXiv:2310.17596, 2023. 3
work page internal anchor Pith review arXiv 2023
-
[46]
So you think you can scale up autonomous robot data collection?arXiv preprint arXiv:2411.01813, 2024
Suvir Mirchandani, Suneel Belkhale, Joey Hejna, Evelyn Choi, Md Sazzad Islam, and Dorsa Sadigh. So you think you can scale up autonomous robot data collection?arXiv preprint arXiv:2411.01813, 2024. 2, 3
-
[47]
Adithyavairavan Murali, Balakumar Sundaralingam, Yu-Wei Chao, Wentao Yuan, Jun Yamada, Mark Carlson, Fabio Ramos, Stan Birchfield, Dieter Fox, and Clemens Eppner. Graspgen: A diffusion-based framework for 6-dof grasping with on-generator training.arXiv preprint arXiv:2507.13097,
-
[48]
DINOv2: Learning Robust Visual Features without Supervision
Maxime Oquab, Timoth´ee Darcet, Th´eo Moutakanni, Huy V o, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, et al. Dinov2: Learning robust visual features without supervision.arXiv preprint arXiv:2304.07193, 2023. 3
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[49]
Open x-embodiment: Robotic learning datasets and rt-x models: Open x-embodiment collaboration 0
Abby O’Neill, Abdul Rehman, Abhiram Maddukuri, Ab- hishek Gupta, Abhishek Padalkar, Abraham Lee, Acorn Poo- ley, Agrim Gupta, Ajay Mandlekar, Ajinkya Jain, et al. Open x-embodiment: Robotic learning datasets and rt-x models: Open x-embodiment collaboration 0. In2024 IEEE Interna- tional Conference on Robotics and Automation (ICRA), pages 6892–6903. IEEE, ...
work page 2024
-
[50]
Mingjie Pan, Jiyao Zhang, Tianshu Wu, Yinghao Zhao, Wen- long Gao, and Hao Dong. Omnimanip: Towards general robotic manipulation via object-centric interaction primitives as spatial constraints. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 17359–17369,
-
[51]
Shivansh Patel, Xinchen Yin, Wenlong Huang, Shubham Garg, Hooshang Nayyeri, Li Fei-Fei, Svetlana Lazebnik, and Yunzhu Li. A real-to-sim-to-real approach to robotic manipu- lation with vlm-generated iterative keypoint rewards.arXiv preprint arXiv:2502.08643, 2025. 3
-
[52]
Splatsim: Zero- shot sim2real transfer of rgb manipulation policies using gaus- sian splatting
M Nomaan Qureshi, Sparsh Garg, Francisco Yandun, David Held, George Kantor, and Abhisesh Silwal. Splatsim: Zero- shot sim2real transfer of rgb manipulation policies using gaus- sian splatting. In2025 IEEE International Conference on Robotics and Automation (ICRA), pages 6502–6509. IEEE,
-
[53]
Very Deep Convolutional Networks for Large-Scale Image Recognition
Karen Simonyan and Andrew Zisserman. Very deep convo- lutional networks for large-scale image recognition.arXiv preprint arXiv:1409.1556, 2014. 6
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[54]
Hand-object interaction pretraining from videos
Himanshu Gaurav Singh, Antonio Loquercio, Carmelo Sfer- razza, Jane Wu, Haozhi Qi, Pieter Abbeel, and Jitendra Malik. Hand-object interaction pretraining from videos. In2025 IEEE International Conference on Robotics and Automation (ICRA), pages 3352–3360. IEEE, 2025. 3
work page 2025
-
[55]
Gemini Robotics: Bringing AI into the Physical World
Gemini Robotics Team, Saminda Abeyruwan, Joshua Ainslie, Jean-Baptiste Alayrac, Montserrat Gonzalez Arenas, Travis Armstrong, Ashwin Balakrishna, Robert Baruch, Maria Bauza, Michiel Blokzijl, et al. Gemini robotics: Bringing ai into the physical world.arXiv preprint arXiv:2503.20020,
work page internal anchor Pith review Pith/arXiv arXiv
-
[56]
Octo: An Open-Source Generalist Robot Policy
Octo Model Team, Dibya Ghosh, Homer Walke, Karl Pertsch, Kevin Black, Oier Mees, Sudeep Dasari, Joey Hejna, Tobias Kreiman, Charles Xu, et al. Octo: An open-source generalist robot policy.arXiv preprint arXiv:2405.12213, 2024. 3
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[57]
Zachary Teed and Jia Deng. Droid-slam: Deep visual slam for monocular, stereo, and rgb-d cameras.Advances in neural information processing systems, 34:16558–16569, 2021. 3
work page 2021
-
[58]
Robot learning with super-linear scaling.arXiv preprint arXiv:2412.01770, 2024
Marcel Torne, Arhan Jain, Jiayi Yuan, Vidaaranya Macha, Lars Ankile, Anthony Simeonov, Pulkit Agrawal, and Ab- hishek Gupta. Robot learning with super-linear scaling.arXiv preprint arXiv:2412.01770, 2024. 2, 3
-
[59]
Lirui Wang, Yiyang Ling, Zhecheng Yuan, Mohit Shridhar, Chen Bao, Yuzhe Qin, Bailin Wang, Huazhe Xu, and Xiao- long Wang. Gensim: Generating robotic simulation tasks via large language models.arXiv preprint arXiv:2310.01361,
-
[60]
Eugene P Wigner et al. The unreasonable effectiveness of mathematics in the natural sciences.Mathematics and science, 13:1–14, 1990. 6
work page 1990
-
[61]
Structured 3d latents for scalable and versatile 3d gen- eration
Jianfeng Xiang, Zelong Lv, Sicheng Xu, Yu Deng, Ruicheng Wang, Bowen Zhang, Dong Chen, Xin Tong, and Jiaolong Yang. Structured 3d latents for scalable and versatile 3d gen- eration. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 21469–21480, 2025. 3, 1
work page 2025
-
[62]
Zhengrong Xue, Shuying Deng, Zhenyang Chen, Yixuan Wang, Zhecheng Yuan, and Huazhe Xu. Demogen: Synthetic demonstration generation for data-efficient visuomotor policy learning.arXiv preprint arXiv:2502.16932, 2025. 3
-
[63]
Learning Interactive Real-World Simulators
Mengjiao Yang, Yilun Du, Kamyar Ghasemipour, Jonathan Tompson, Dale Schuurmans, and Pieter Abbeel. Learn- ing interactive real-world simulators.arXiv preprint arXiv:2310.06114, 1(2):6, 2023. 2, 3
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[64]
CogVideoX: Text-to-Video Diffusion Models with An Expert Transformer
Zhuoyi Yang, Jiayan Teng, Wendi Zheng, Ming Ding, Shiyu Huang, Jiazheng Xu, Yuanming Yang, Wenyi Hong, Xiao- han Zhang, Guanyu Feng, et al. Cogvideox: Text-to-video diffusion models with an expert transformer.arXiv preprint arXiv:2408.06072, 2024. 7
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[65]
Weirui Ye, Fangchen Liu, Zheng Ding, Yang Gao, Oleh Ry- bkin, and Pieter Abbeel. Video2policy: Scaling up manip- ulation tasks in simulation through internet videos.arXiv preprint arXiv:2502.09886, 2025. 3
-
[66]
Inpaint anything: Segment anything meets image inpainting
Tao Yu, Runseng Feng, Ruoyu Feng, Jinming Liu, Xin Jin, Wenjun Zeng, and Zhibo Chen. Inpaint anything: Seg- ment anything meets image inpainting.arXiv preprint arXiv:2304.06790, 2023. 3
-
[67]
Zhecheng Yuan, Tianming Wei, Langzhe Gu, Pu Hua, Tianhai Liang, Yuanpei Chen, and Huazhe Xu. Hermes: Human-to-robot embodied learning from multi-source mo- tion data for mobile dexterous manipulation.arXiv preprint arXiv:2508.20085, 2025. 3
-
[68]
3D Diffusion Policy: Generalizable Visuomotor Policy Learning via Simple 3D Representations
Yanjie Ze, Gu Zhang, Kangning Zhang, Chenyuan Hu, Muhan Wang, and Huazhe Xu. 3d diffusion policy: Generalizable visuomotor policy learning via simple 3d representations. arXiv preprint arXiv:2403.03954, 2024. 2
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[69]
GLM-4.5: Agentic, Reasoning, and Coding (ARC) Foundation Models
Aohan Zeng, Xin Lv, Qinkai Zheng, Zhenyu Hou, Bin Chen, Chengxing Xie, Cunxiang Wang, Da Yin, Hao Zeng, Jiajie Zhang, et al. Glm-4.5: Agentic, reasoning, and coding (arc) foundation models.arXiv preprint arXiv:2508.06471, 2025. 6, 8
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[70]
Qiyuan Zeng, Chengmeng Li, Jude St John, Zhongyi Zhou, Junjie Wen, Guorui Feng, Yichen Zhu, and Yi Xu. Activeumi: Robotic manipulation with active perception from robot-free human demonstrations.arXiv preprint arXiv:2510.01607,
-
[71]
Hongxin Zhang, Zeyuan Wang, Qiushi Lyu, Zheyuan Zhang, Sunli Chen, Tianmin Shu, Behzad Dariush, Kwonjoon Lee, Yilun Du, and Chuang Gan. Combo: compositional world models for embodied multi-agent cooperation.arXiv preprint arXiv:2404.10775, 2024. 2
-
[72]
Han Zhang, Songbo Hu, Zhecheng Yuan, and Huazhe Xu. Doglove: Dexterous manipulation with a low-cost open-source haptic force feedback glove.arXiv preprint arXiv:2502.07730, 2025. 3
-
[73]
Jingyi Zhang, Jiaxing Huang, Sheng Jin, and Shijian Lu. Vision-language models for vision tasks: A survey.IEEE transactions on pattern analysis and machine intelligence, 46 (8):5625–5644, 2024. 2
work page 2024
-
[74]
Robot learning from any images
Siheng Zhao, Jiageng Mao, Wei Chow, Zeyu Shangguan, Tianheng Shi, Rong Xue, Yuxi Zheng, Yijia Weng, Yang You, Daniel Seita, et al. Robot learning from any images. In Conference on Robot Learning, pages 4226–4245. PMLR,
-
[75]
Learning Fine-Grained Bimanual Manipulation with Low-Cost Hardware
Tony Z Zhao, Vikash Kumar, Sergey Levine, and Chelsea Finn. Learning fine-grained bimanual manipulation with low- cost hardware.arXiv preprint arXiv:2304.13705, 2023. 2
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[76]
Tesseract: learning 4d embodied world models.arXiv preprint arXiv:2504.20995,
Haoyu Zhen, Qiao Sun, Hongxin Zhang, Junyan Li, Siyuan Zhou, Yilun Du, and Chuang Gan. Tesseract: learning 4d embodied world models.arXiv preprint arXiv:2504.20995,
-
[77]
Extraneousness-aware imitation learning
Ray Chen Zheng, Kaizhe Hu, Zhecheng Yuan, Boyuan Chen, and Huazhe Xu. Extraneousness-aware imitation learning. arXiv preprint arXiv:2210.01379, 2022. 2
-
[78]
RoboDreamer: Learning Compositional World Models for Robot Imagination
Siyuan Zhou, Yilun Du, Jiaben Chen, Yandong Li, Dit-Yan Yeung, and Chuang Gan. Robodreamer: Learning composi- tional world models for robot imagination.arXiv preprint arXiv:2404.12377, 2024. 2, 3
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[79]
Junzhe Zhu, Yuanchen Ju, Junyi Zhang, Muhan Wang, Zhecheng Yuan, Kaizhe Hu, and Huazhe Xu. Dense- matcher: Learning 3d semantic correspondence for category- level manipulation from a single demo.arXiv preprint arXiv:2412.05268, 2024. 3
-
[80]
Grs: Generating robotic simulation tasks from real-world images
Alex Zook, Fan-Yun Sun, Josef Spjut, Valts Blukis, Stan Birchfield, and Jonathan Tremblay. Grs: Generating robotic simulation tasks from real-world images. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 594–603, 2025. 3 12 Appendix A. Single-Image Scene Reconstruction Details In this section, we describe how IGen reconstruc...
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.