Recognition: 2 theorem links
· Lean TheoremSee, Hear, and Understand: Benchmarking Audiovisual Human Speech Understanding in Multimodal Large Language Models
Pith reviewed 2026-05-17 02:08 UTC · model grok-4.3
The pith
A new benchmark shows Gemini models lead in audiovisual human speech understanding while open models lag in fusion.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
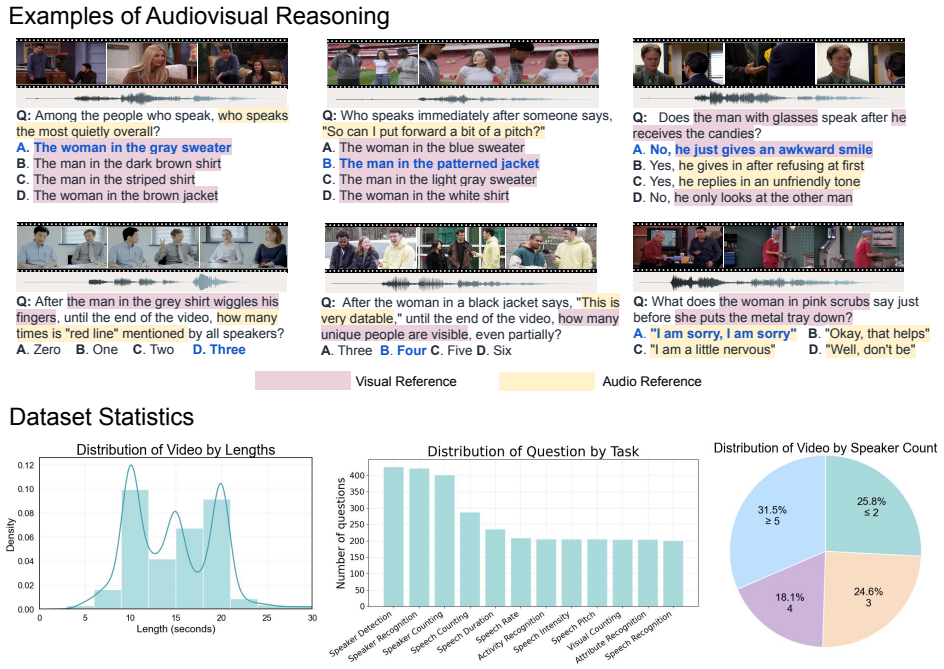
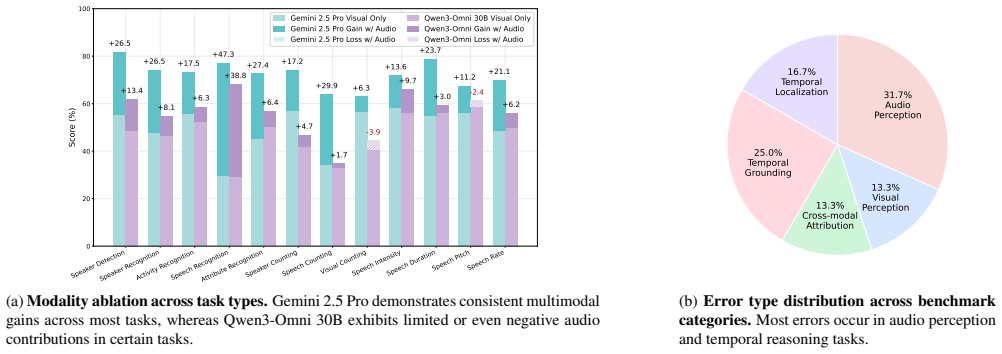
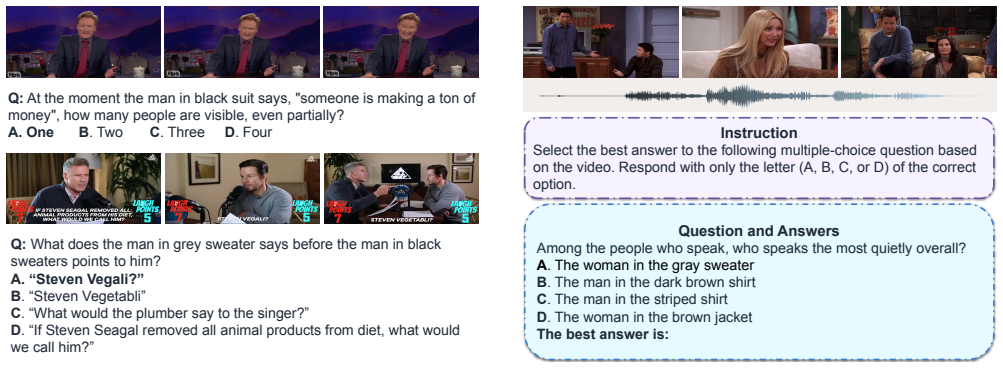
We introduce AV-SpeakerBench, a curated benchmark of 3,212 multiple-choice questions focused on speaker-centric audiovisual reasoning in real-world videos. It features a speaker-centered formulation that treats speakers as the core reasoning unit, fusion-grounded question design embedding audiovisual dependencies, and expert-curated annotations ensuring temporal precision and cross-modal validity. Comprehensive evaluations show that the Gemini family consistently outperforms open-source systems, with Gemini 2.5 Pro achieving the best results. Among open models, Qwen3-Omni-30B approaches Gemini 2.0 Flash but remains far behind Gemini 2.5 Pro, primarily due to weaker audiovisual fusion rather.
What carries the argument
AV-SpeakerBench benchmark with speaker-centered formulation and fusion-grounded questions that force integration of who speaks, what is said, and when.
If this is right
- Gemini 2.5 Pro represents the current best performance on fine-grained audiovisual speech tasks.
- Open-source multimodal models require advances in audiovisual fusion to approach closed model capabilities.
- Benchmarks for MLLMs should incorporate questions that cannot be solved by single modalities or coarse information.
- Development of future systems should emphasize temporal alignment between visual and audio speech elements.
Where Pith is reading between the lines
- Enhanced fusion techniques could improve model utility in applications like automated video summarization or accessibility tools.
- The benchmark design could inspire similar tests for other multimodal challenges involving timing and identity.
- Training open models with more synchronized audiovisual data might reduce the observed performance gap.
Load-bearing premise
The expert-curated questions and fusion-grounded design embed true audiovisual dependencies that prevent solving them with visual cues or coarse speech information alone.
What would settle it
A test where models are evaluated on the same questions but with audio removed or timing disrupted; high performance in that case would falsify the claim that the benchmark measures fusion.
Figures









read the original abstract
Multimodal large language models (MLLMs) are expected to jointly interpret vision, audio, and language, yet existing video benchmarks rarely assess fine-grained reasoning about human speech. Many tasks remain visually solvable or only coarsely evaluate speech, offering limited insight into whether models can align who speaks, what is said, and when it occurs. We introduce AV-SpeakerBench, a curated benchmark of 3,212 multiple-choice questions focused on speaker-centric audiovisual reasoning in real-world videos. It features: (1) a speaker-centered formulation that treats speakers-not scenes-as the core reasoning unit; (2) fusion-grounded question design embedding audiovisual dependencies into question semantics; and (3) expert-curated annotations ensuring temporal precision and cross-modal validity. Comprehensive evaluations show that the Gemini family consistently outperforms open-source systems, with Gemini 2.5 Pro achieving the best results. Among open models, Qwen3-Omni-30B approaches Gemini 2.0 Flash but remains far behind Gemini 2.5 Pro, primarily due to weaker audiovisual fusion rather than visual perception. We believe AV-SpeakerBench establishes a rigorous foundation for advancing fine-grained audiovisual reasoning in future multimodal systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces AV-SpeakerBench, a benchmark of 3,212 expert-curated multiple-choice questions targeting fine-grained audiovisual reasoning about human speech in real-world videos. It emphasizes a speaker-centered formulation and fusion-grounded question design that embeds dependencies between speaker identity, speech content, and timing. Comprehensive evaluations across models conclude that the Gemini family leads, with Gemini 2.5 Pro strongest overall, while open-source models such as Qwen3-Omni-30B trail primarily due to weaker audiovisual fusion rather than deficits in visual perception.
Significance. If the benchmark questions are shown to require genuine cross-modal fusion, the work would provide a useful diagnostic tool for multimodal LLMs and help quantify gaps between proprietary and open systems in speaker-centric audiovisual understanding. The scale, expert curation, and focus on temporal and cross-modal validity are positive contributions that could guide future model development.
major comments (2)
- [Benchmark Construction] The fusion-grounded question design and speaker-centered formulation are presented as ensuring audiovisual dependencies, yet no validation details (inter-annotator agreement, question difficulty controls, or checks that questions cannot be solved unimodally) are provided. This directly undermines the load-bearing claim in the results that performance gaps reflect audiovisual fusion deficits rather than visual or coarse-audio shortcuts.
- [Results and Analysis] The diagnostic conclusion that Qwen3-Omni-30B approaches Gemini 2.0 Flash but lags Gemini 2.5 Pro 'primarily due to weaker audiovisual fusion rather than visual perception' lacks supporting evidence. No unimodal baselines (video-only, audio-masked) or ablation results are reported to confirm that single-modality accuracy remains near chance on the 3,212 questions.
minor comments (2)
- [Abstract] The abstract and introduction would benefit from a brief explicit statement of the total number of models evaluated and the precise accuracy metric used for all comparisons.
- [Figures and Tables] Figure captions and table headers could more clearly distinguish between overall accuracy and per-category breakdowns to aid quick interpretation of the fusion-related claims.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback on our work introducing AV-SpeakerBench. We address each of the major comments in detail below, providing clarifications and outlining the revisions we plan to incorporate to strengthen the manuscript.
read point-by-point responses
-
Referee: [Benchmark Construction] The fusion-grounded question design and speaker-centered formulation are presented as ensuring audiovisual dependencies, yet no validation details (inter-annotator agreement, question difficulty controls, or checks that questions cannot be solved unimodally) are provided. This directly undermines the load-bearing claim in the results that performance gaps reflect audiovisual fusion deficits rather than visual or coarse-audio shortcuts.
Authors: We agree that providing explicit validation details is important for substantiating the benchmark's design. The expert curation process involved multiple annotators to ensure temporal precision and cross-modal validity, as described in the manuscript. In the revised version, we will report inter-annotator agreement metrics, details on question difficulty controls via iterative review, and preliminary unimodal checks demonstrating that questions are not solvable from single modalities alone. This will directly address the concern and reinforce that performance differences stem from audiovisual fusion capabilities. revision: yes
-
Referee: [Results and Analysis] The diagnostic conclusion that Qwen3-Omni-30B approaches Gemini 2.0 Flash but lags Gemini 2.5 Pro 'primarily due to weaker audiovisual fusion rather than visual perception' lacks supporting evidence. No unimodal baselines (video-only, audio-masked) or ablation results are reported to confirm that single-modality accuracy remains near chance on the 3,212 questions.
Authors: We acknowledge that the current manuscript relies on comparative model performances and error analysis to infer the role of audiovisual fusion. To provide stronger evidence, we will add unimodal baseline experiments in the revision, including video-only and audio-masked settings across the evaluated models. These results are expected to show near-chance performance on the benchmark questions, thereby supporting our diagnostic conclusion regarding fusion deficits in open-source models like Qwen3-Omni-30B. revision: yes
Circularity Check
No circularity: empirical benchmark evaluation is self-contained
full rationale
The paper introduces AV-SpeakerBench as a new expert-curated benchmark of 3,212 questions with speaker-centered and fusion-grounded design, then reports direct empirical evaluations of existing MLLMs such as Gemini and Qwen3-Omni on it. No equations, parameter fitting, derivations, or predictions appear in the provided text. The performance gap attribution follows from observed results and the benchmark's stated design rather than reducing to any self-definitional loop, fitted input renamed as prediction, or load-bearing self-citation chain. The derivation chain is therefore independent of its own outputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Expert-curated annotations ensure temporal precision and cross-modal validity of questions.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We introduce AV-SpeakerBench, a curated benchmark of 3,212 multiple-choice questions focused on speaker-centric audiovisual reasoning in real-world videos... fusion-grounded question design embedding audiovisual dependencies into question semantics
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Gemini 2.5 Pro... remains far behind... primarily due to weaker audiovisual fusion rather than visual perception
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Lrs3-ted: a large-scale dataset for visual speech recog- nition, 2018
Triantafyllos Afouras, Joon Son Chung, and Andrew Zisser- man. Lrs3-ted: a large-scale dataset for visual speech recog- nition, 2018. 2
work page 2018
-
[2]
Vqa: Visual question answering
Stanislaw Antol, Aishwarya Agrawal, Jiasen Lu, Margaret Mitchell, Dhruv Batra, C Lawrence Zitnick, and Devi Parikh. Vqa: Visual question answering. InProceedings of the IEEE international conference on computer vision, pages 2425– 2433, 2015. 2
work page 2015
-
[3]
Mu Cai, Reuben Tan, Jianrui Zhang, Bocheng Zou, Kai Zhang, Feng Yao, Fangrui Zhu, Jing Gu, Yiwu Zhong, Yuzhang Shang, et al. Temporalbench: Benchmarking fine- grained temporal understanding for multimodal video mod- els.arXiv preprint arXiv:2410.10818, 2024. 2
-
[4]
Vggsound: A large-scale audio-visual dataset, 2020
Honglie Chen, Weidi Xie, Andrea Vedaldi, and Andrew Zis- serman. Vggsound: A large-scale audio-visual dataset, 2020. 2
work page 2020
-
[5]
VideoLLaMA 2: Advancing Spatial-Temporal Modeling and Audio Understanding in Video-LLMs
Zesen Cheng, Sicong Leng, Hang Zhang, Yifei Xin, Xin Li, Guanzheng Chen, Yongxin Zhu, Wenqi Zhang, Ziyang Luo, Deli Zhao, and Lidong Bing. Videollama 2: Advancing spatial-temporal modeling and audio understanding in video- llms.arXiv preprint arXiv:2406.07476, 2024. 3, 5, 6
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[6]
J. S. Chung, A. Nagrani, and A. Zisserman. V oxceleb2: Deep speaker recognition. InINTERSPEECH, 2018. 2
work page 2018
-
[7]
Wenliang Dai, Junnan Li, Dongxu Li, Anthony Tiong, Junqi Zhao, Weisheng Wang, Boyang Li, Pascale N Fung, and Steven Hoi. Instructblip: Towards general-purpose vision- language models with instruction tuning.Advances in neural information processing systems, 36:49250–49267, 2023. 1, 3
work page 2023
-
[8]
Scaling egocentric vision: The epic-kitchens dataset
Dima Damen, Hazel Doughty, Giovanni Maria Farinella, Sanja Fidler, Antonino Furnari, Evangelos Kazakos, Davide Moltisanti, Jonathan Munro, Toby Perrett, Will Price, et al. Scaling egocentric vision: The epic-kitchens dataset. In Proceedings of the European conference on computer vision (ECCV), pages 720–736, 2018. 2
work page 2018
-
[9]
Mmbench-video: A long-form multi-shot benchmark for holistic video under- standing
Xinyu Fang, Kangrui Mao, Haodong Duan, Xiangyu Zhao, Yining Li, Dahua Lin, and Kai Chen. Mmbench-video: A long-form multi-shot benchmark for holistic video under- standing. InAdvances in Neural Information Processing Sys- tems, pages 89098–89124. Curran Associates, Inc., 2024. 3
work page 2024
-
[10]
Vita: Towards open-source interactive omni multimodal llm.arXiv preprint arXiv:2408.05211, 2024
Chaoyou Fu, Haojia Lin, Zuwei Long, Yunhang Shen, Meng Zhao, Yifan Zhang, Shaoqi Dong, Xiong Wang, Di Yin, Long Ma, et al. Vita: Towards open-source interactive omni multimodal llm.arXiv preprint arXiv:2408.05211, 2024. 3, 5, 6
-
[11]
Mme: A comprehensive evaluation bench- mark for multimodal large language models
Chaoyou Fu, Peixian Chen, Yunhang Shen, Yulei Qin, Mengdan Zhang, Xu Lin, Jinrui Yang, Xiawu Zheng, Ke Li, Xing Sun, et al. Mme: A comprehensive evaluation bench- mark for multimodal large language models. InThe Thirty- ninth Annual Conference on Neural Information Processing Systems Datasets and Benchmarks Track, 2025. 2
work page 2025
-
[12]
Video- mme: The first-ever comprehensive evaluation benchmark of multi-modal llms in video analysis
Chaoyou Fu, Yuhan Dai, Yongdong Luo, Lei Li, Shuhuai Ren, Renrui Zhang, Zihan Wang, Chenyu Zhou, Yunhang Shen, Mengdan Zhang, Peixian Chen, Yanwei Li, Shao- hui Lin, Sirui Zhao, Ke Li, Tong Xu, Xiawu Zheng, En- hong Chen, Caifeng Shan, Ran He, and Xing Sun. Video- mme: The first-ever comprehensive evaluation benchmark of multi-modal llms in video analysis...
work page 2025
-
[13]
Video-mme: The first-ever comprehensive evaluation benchmark of multi-modal llms in video analysis
Chaoyou Fu, Yuhan Dai, Yongdong Luo, Lei Li, Shuhuai Ren, Renrui Zhang, Zihan Wang, Chenyu Zhou, Yunhang Shen, Mengdan Zhang, et al. Video-mme: The first-ever comprehensive evaluation benchmark of multi-modal llms in video analysis. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 24108–24118, 2025. 1, 3
work page 2025
-
[14]
Vita-1.5: Towards gpt-4o level real-time vision and speech interaction
Chaoyou Fu, Haojia Lin, Xiong Wang, Yi-Fan Zhang, Yun- hang Shen, Xiaoyu Liu, Yangze Li, Zuwei Long, Het- ing Gao, Ke Li, et al. Vita-1.5: Towards gpt-4o level real-time vision and speech interaction.arXiv preprint arXiv:2501.01957, 2025. 5, 6
-
[15]
Google Gemini Team. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities, 2025. 2, 6, 7
work page 2025
-
[16]
Gemini: A family of highly capable multimodal models, 2025
Google Gemini Team. Gemini: A family of highly capable multimodal models, 2025. 3, 5, 6, 7
work page 2025
-
[17]
Jort F. Gemmeke, Daniel P. W. Ellis, Dylan Freedman, Aren Jansen, Wade Lawrence, R. Channing Moore, Manoj Plakal, and Marvin Ritter. Audio set: An ontology and human- labeled dataset for audio events. InProc. IEEE ICASSP 2017, New Orleans, LA, 2017. 2
work page 2017
-
[18]
Sreyan Ghosh, Sonal Kumar, Ashish Seth, Chandra Ki- ran Reddy Evuru, Utkarsh Tyagi, S Sakshi, Oriol Nieto, Ramani Duraiswami, and Dinesh Manocha. Gama: A large audio-language model with advanced audio under- standing and complex reasoning abilities.arXiv preprint arXiv:2406.11768, 2024. 1
-
[19]
Av-odyssey bench: Can your multimodal llms really understand audio-visual in- formation?, 2024
Kaixiong Gong, Kaituo Feng, Bohao Li, Yibing Wang, Mo- fan Cheng, Shijia Yang, Jiaming Han, Benyou Wang, Yutong Bai, Zhuoran Yang, and Xiangyu Yue. Av-odyssey bench: Can your multimodal llms really understand audio-visual in- formation?, 2024. 2, 3
work page 2024
-
[20]
Making the v in vqa matter: Elevating the role of image understanding in visual question answer- ing
Yash Goyal, Tejas Khot, Douglas Summers-Stay, Dhruv Ba- tra, and Devi Parikh. Making the v in vqa matter: Elevating the role of image understanding in visual question answer- ing. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 6904–6913, 2017. 2
work page 2017
-
[21]
Ego4d: Around the world in 3,000 hours of egocentric video
Kristen Grauman, Andrew Westbury, Eugene Byrne, Zachary Chavis, Antonino Furnari, Rohit Girdhar, Jackson Hamburger, Hao Jiang, Miao Liu, Xingyu Liu, et al. Ego4d: Around the world in 3,000 hours of egocentric video. In 9 Proceedings of the IEEE/CVF conference on computer vi- sion and pattern recognition, pages 18995–19012, 2022. 2
work page 2022
-
[22]
Onellm: One framework to align all modalities with language
Jiaming Han, Kaixiong Gong, Yiyuan Zhang, Jiaqi Wang, Kaipeng Zhang, Dahua Lin, Yu Qiao, Peng Gao, and Xi- angyu Yue. Onellm: One framework to align all modalities with language. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 26584– 26595, 2024. 1, 6
work page 2024
-
[23]
Onellm: One framework to align all modalities with language, 2025
Jiaming Han, Kaixiong Gong, Yiyuan Zhang, Jiaqi Wang, Kaipeng Zhang, Dahua Lin, Yu Qiao, Peng Gao, and Xi- angyu Yue. Onellm: One framework to align all modalities with language, 2025. 3, 5
work page 2025
-
[24]
WorldSense: Evaluating Real-world Omnimodal Understanding for Multimodal LLMs
Jack Hong, Shilin Yan, Jiayin Cai, Xiaolong Jiang, Yao Hu, and Weidi Xie. Worldsense: Evaluating real-world omni- modal understanding for multimodal llms.arXiv preprint arXiv:2502.04326, 2025. 2
work page internal anchor Pith review arXiv 2025
-
[25]
Worldsense: Evaluating real-world omni- modal understanding for multimodal llms, 2025
Jack Hong, Shilin Yan, Jiayin Cai, Xiaolong Jiang, Yao Hu, and Weidi Xie. Worldsense: Evaluating real-world omni- modal understanding for multimodal llms, 2025. 3
work page 2025
-
[26]
Talknce: Improving active speaker detection with talk-aware contrastive learning
Chaeyoung Jung, Suyeon Lee, Kihyun Nam, Kyeongha Rho, You Jin Kim, Youngjoon Jang, and Joon Son Chung. Talknce: Improving active speaker detection with talk-aware contrastive learning. InICASSP 2024-2024 IEEE Interna- tional Conference on Acoustics, Speech and Signal Process- ing (ICASSP), pages 8391–8395. IEEE, 2024. 1, 2
work page 2024
-
[27]
Look who’s talking: Active speaker detec- tion in the wild.arXiv preprint arXiv:2108.07640, 2021
You Jin Kim, Hee-Soo Heo, Soyeon Choe, Soo-Whan Chung, Yoohwan Kwon, Bong-Jin Lee, Youngki Kwon, and Joon Son Chung. Look who’s talking: Active speaker detec- tion in the wild.arXiv preprint arXiv:2108.07640, 2021. 1, 2, 5
-
[28]
Zhifeng Kong, Arushi Goel, Rohan Badlani, Wei Ping, Rafael Valle, and Bryan Catanzaro. Audio flamingo: A novel audio language model with few-shot learning and dialogue abilities.arXiv preprint arXiv:2402.01831, 2024. 1
-
[29]
SEED-Bench: Benchmarking Multimodal LLMs with Generative Comprehension
Bohao Li, Rui Wang, Guangzhi Wang, Yuying Ge, Yix- iao Ge, and Ying Shan. Seed-bench: Benchmarking mul- timodal llms with generative comprehension.arXiv preprint arXiv:2307.16125, 2023. 2
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[30]
Learning to answer questions in dynamic audio-visual scenarios
Guangyao Li, Yake Wei, Yapeng Tian, Chenliang Xu, Ji- Rong Wen, and Di Hu. Learning to answer questions in dynamic audio-visual scenarios. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 19108–19118, 2022. 1, 3
work page 2022
-
[31]
Junnan Li, Dongxu Li, Silvio Savarese, and Steven Hoi. Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models. InIn- ternational conference on machine learning, pages 19730– 19742. PMLR, 2023. 3
work page 2023
-
[32]
Mvbench: A comprehensive multi- modal video understanding benchmark
Kunchang Li, Yali Wang, Yinan He, Yizhuo Li, Yi Wang, Yi Liu, Zun Wang, Jilan Xu, Guo Chen, Ping Luo, Limin Wang, and Yu Qiao. Mvbench: A comprehensive multi- modal video understanding benchmark. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 22195–22206, 2024. 2, 3
work page 2024
-
[33]
Omnibench: Towards the future of univer- sal omni-language models, 2025
Yizhi Li, Ge Zhang, Yinghao Ma, Ruibin Yuan, Kang Zhu, Hangyu Guo, Yiming Liang, Jiaheng Liu, Zekun Wang, Jian Yang, Siwei Wu, Xingwei Qu, Jinjie Shi, Xinyue Zhang, Zhenzhu Yang, Xiangzhou Wang, Zhaoxiang Zhang, Zachary Liu, Emmanouil Benetos, Wenhao Huang, and Chenghua Lin. Omnibench: Towards the future of univer- sal omni-language models, 2025. 3
work page 2025
-
[34]
Video-llava: Learning united visual repre- sentation by alignment before projection
Bin Lin, Yang Ye, Bin Zhu, Jiaxi Cui, Munan Ning, Peng Jin, and Li Yuan. Video-llava: Learning united visual repre- sentation by alignment before projection. InProceedings of the 2024 Conference on Empirical Methods in Natural Lan- guage Processing, pages 5971–5984, 2024. 1
work page 2024
-
[35]
Visual instruction tuning.Advances in neural information processing systems, 36:34892–34916, 2023
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning.Advances in neural information processing systems, 36:34892–34916, 2023. 1, 3
work page 2023
-
[36]
Improved baselines with visual instruction tuning
Haotian Liu, Chunyuan Li, Yuheng Li, and Yong Jae Lee. Improved baselines with visual instruction tuning. InCVPR,
-
[37]
Yuan Liu, Haodong Duan, Yuanhan Zhang, Bo Li, Songyang Zhang, Wangbo Zhao, Yike Yuan, Jiaqi Wang, Conghui He, Ziwei Liu, et al. Mmbench: Is your multi-modal model an all-around player? InEuropean conference on computer vi- sion, pages 216–233. Springer, 2024. 2
work page 2024
-
[38]
TempCompass: Do Video LLMs Really Understand Videos?
Yuanxin Liu, Shicheng Li, Yi Liu, Yuxiang Wang, Shuhuai Ren, Lei Li, Sishuo Chen, Xu Sun, and Lu Hou. Tempcom- pass: Do video llms really understand videos?arXiv preprint arXiv:2403.00476, 2024. 2
work page internal anchor Pith review arXiv 2024
-
[39]
Ola: Pushing the frontiers of omni-modal language model, 2025
Zuyan Liu, Yuhao Dong, Jiahui Wang, Ziwei Liu, Winston Hu, Jiwen Lu, and Yongming Rao. Ola: Pushing the frontiers of omni-modal language model, 2025. 3, 5, 6
work page 2025
-
[40]
Jiasen Lu, Christopher Clark, Sangho Lee, Zichen Zhang, Savya Khosla, Ryan Marten, Derek Hoiem, and Aniruddha Kembhavi. Unified-io 2: Scaling autoregressive multimodal models with vision, language, audio, and action, 2023. 3, 5, 6
work page 2023
-
[41]
Egoschema: A diagnostic benchmark for very long- form video language understanding
Karttikeya Mangalam, Raiymbek Akshulakov, and Jitendra Malik. Egoschema: A diagnostic benchmark for very long- form video language understanding. InAdvances in Neural Information Processing Systems, pages 46212–46244. Cur- ran Associates, Inc., 2023. 2, 3
work page 2023
-
[42]
Chartqa: A benchmark for question answer- ing about charts with visual and logical reasoning
Ahmed Masry, Xuan Long Do, Jia Qing Tan, Shafiq Joty, and Enamul Hoque. Chartqa: A benchmark for question answer- ing about charts with visual and logical reasoning. InFind- ings of the association for computational linguistics: ACL 2022, pages 2263–2279, 2022. 2
work page 2022
-
[43]
Docvqa: A dataset for vqa on document images
Minesh Mathew, Dimosthenis Karatzas, and CV Jawahar. Docvqa: A dataset for vqa on document images. InProceed- ings of the IEEE/CVF winter conference on applications of computer vision, pages 2200–2209, 2021. 2
work page 2021
-
[44]
Microsoft. Phi-4-mini technical report: Compact yet power- ful multimodal language models via mixture-of-loras, 2025. 3, 5, 6
work page 2025
-
[45]
A. Nagrani, J. S. Chung, and A. Zisserman. V oxceleb: a large-scale speaker identification dataset. InINTER- SPEECH, 2017. 2
work page 2017
-
[46]
Le Thien Phuc Nguyen, Zhuoran Yu, Khoa Quang Nhat Cao, Yuwei Guo, Tu Ho Manh Pham, Tuan Tai Nguyen, Toan Ngo Duc V o, Lucas Poon, Soochahn Lee, and Yong Jae Lee. Unitalk: Towards universal active speaker detection in real world scenarios.arXiv preprint arXiv:2505.21954, 2025. 1, 2, 5 10
-
[47]
Le Thien Phuc Nguyen, Zhuoran Yu, and Yong Jae Lee. Laser: Lip landmark assisted speaker detection for robust- ness.arXiv preprint arXiv:2501.11899, 2025. 1, 2
-
[48]
Munan Ning, Bin Zhu, Yujia Xie, Bin Lin, Jiaxi Cui, Lu Yuan, Dongdong Chen, and Li Yuan. Video-bench: A com- prehensive benchmark and toolkit for evaluating video-based large language models, 2023. 3
work page 2023
-
[49]
Ava active speaker: An audio-visual dataset for active speaker detection
Joseph Roth, Sourish Chaudhuri, Ondrej Klejch, Rad- hika Marvin, Andrew Gallagher, Liat Kaver, Sharadh Ramaswamy, Arkadiusz Stopczynski, Cordelia Schmid, Zhonghua Xi, et al. Ava active speaker: An audio-visual dataset for active speaker detection. InICASSP 2020-2020 IEEE international conference on acoustics, speech and sig- nal processing (ICASSP), pages...
work page 2020
-
[50]
Towards vqa models that can read
Amanpreet Singh, Vivek Natarajan, Meet Shah, Yu Jiang, Xinlei Chen, Dhruv Batra, Devi Parikh, and Marcus Rohrbach. Towards vqa models that can read. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 8317–8326, 2019. 2
work page 2019
-
[51]
PandaGPT: One Model To Instruction-Follow Them All
Yixuan Su, Tian Lan, Huayang Li, Jialu Xu, Yan Wang, and Deng Cai. Pandagpt: One model to instruction-follow them all.arXiv preprint arXiv:2305.16355, 2023. 1, 3, 5, 6
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[52]
Guangzhi Sun, Wenyi Yu, Changli Tang, Xianzhao Chen, Tian Tan, Wei Li, Lu Lu, Zejun Ma, Yuxuan Wang, and Chao Zhang. video-salmonn: Speech-enhanced audio-visual large language models.arXiv preprint arXiv:2406.15704, 2024. 1
-
[53]
Coin: A large-scale dataset for comprehensive instructional video analysis
Yansong Tang, Dajun Ding, Yongming Rao, Yu Zheng, Danyang Zhang, Lili Zhao, Jiwen Lu, and Jie Zhou. Coin: A large-scale dataset for comprehensive instructional video analysis. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 1207– 1216, 2019. 2
work page 2019
-
[54]
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution
Peng Wang, Shuai Bai, Sinan Tan, Shijie Wang, Zhihao Fan, Jinze Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, et al. Qwen2-vl: Enhancing vision-language model’s perception of the world at any resolution.arXiv preprint arXiv:2409.12191, 2024. 1
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[55]
Loconet: Long-short context network for active speaker detection
Xizi Wang, Feng Cheng, and Gedas Bertasius. Loconet: Long-short context network for active speaker detection. In Proceedings of the IEEE/CVF conference on computer vi- sion and pattern recognition, pages 18462–18472, 2024. 1, 2
work page 2024
-
[56]
Zirui Wang, Mengzhou Xia, Luxi He, Howard Chen, Yitao Liu, Richard Zhu, Kaiqu Liang, Xindi Wu, Haotian Liu, Sad- hika Malladi, et al. Charxiv: Charting gaps in realistic chart understanding in multimodal llms.Advances in Neural In- formation Processing Systems, 37:113569–113697, 2024. 2
work page 2024
-
[57]
Next-qa: Next phase of question-answering to explaining temporal actions
Junbin Xiao, Xindi Shang, Angela Yao, and Tat-Seng Chua. Next-qa: Next phase of question-answering to explaining temporal actions. InProceedings of the IEEE/CVF con- ference on computer vision and pattern recognition, pages 9777–9786, 2021. 2
work page 2021
-
[58]
Video question answer- ing via gradually refined attention over appearance and mo- tion
Dejing Xu, Zhou Zhao, Jun Xiao, Fei Wu, Hanwang Zhang, Xiangnan He, and Yueting Zhuang. Video question answer- ing via gradually refined attention over appearance and mo- tion. InProceedings of the 25th ACM International Confer- ence on Multimedia, page 1645–1653, New York, NY , USA,
-
[59]
Association for Computing Machinery. 3
-
[60]
Jin Xu, Zhifang Guo, Jinzheng He, Hangrui Hu, Ting He, Shuai Bai, Keqin Chen, Jialin Wang, Yang Fan, Kai Dang, et al. Qwen2. 5-omni technical report.arXiv preprint arXiv:2503.20215, 2025. 1, 5, 6, 7
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[61]
Jin Xu, Zhifang Guo, Hangrui Hu, Yunfei Chu, Xiong Wang, Jinzheng He, Yuxuan Wang, Xian Shi, Ting He, Xinfa Zhu, et al. Qwen3-omni technical report.arXiv preprint arXiv:2509.17765, 2025. 1, 2, 3, 5, 6, 7
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[62]
Avqa: A dataset for audio-visual question answering on videos
Pinci Yang, Xin Wang, Xuguang Duan, Hong Chen, Runze Hou, Cong Jin, and Wenwu Zhu. Avqa: A dataset for audio-visual question answering on videos. InProceedings of the 30th ACM International Conference on Multimedia, page 3480–3491, New York, NY , USA, 2022. Association for Computing Machinery. 1, 3
work page 2022
-
[63]
Zhou Yu, Dejing Xu, Jun Yu, Ting Yu, Zhou Zhao, Yuet- ing Zhuang, and Dacheng Tao. Activitynet-qa: A dataset for understanding complex web videos via question answer- ing.Proceedings of the AAAI Conference on Artificial Intel- ligence, 33(01):9127–9134, 2019. 3
work page 2019
-
[64]
Anygpt: Unified multimodal llm with discrete sequence modeling, 2025
Jun Zhan, Junqi Dai, Jiasheng Ye, Yunhua Zhou, Dong Zhang, Zhigeng Liu, Xin Zhang, Ruibin Yuan, Ge Zhang, Linyang Li, Hang Yan, Jie Fu, Tao Gui, Tianxiang Sun, Yu- Gang Jiang, and Xipeng Qiu. Anygpt: Unified multimodal llm with discrete sequence modeling, 2025. 3, 5, 6
work page 2025
-
[65]
Speechgpt: Empowering large language models with intrinsic cross- modal conversational abilities,
Dong Zhang, Shimin Li, Xin Zhang, Jun Zhan, Pengyu Wang, Yaqian Zhou, and Xipeng Qiu. Speechgpt: Empow- ering large language models with intrinsic cross-modal con- versational abilities.arXiv preprint arXiv:2305.11000, 2023. 1
-
[67]
Video-LLaMA: An Instruction-tuned Audio-Visual Language Model for Video Understanding
Hang Zhang, Xin Li, and Lidong Bing. Video-llama: An instruction-tuned audio-visual language model for video un- derstanding.arXiv preprint arXiv:2306.02858, 2023. 1
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[68]
Shaolei Zhang, Shoutao Guo, Qingkai Fang, Yan Zhou, and Yang Feng. Stream-omni: Simultaneous multimodal in- teractions with large language-vision-speech model.arXiv preprint arXiv:2506.13642, 2025. 3
-
[69]
Daily-omni: Towards audio-visual reasoning with temporal alignment across modalities, 2025
Ziwei Zhou, Rui Wang, and Zuxuan Wu. Daily-omni: Towards audio-visual reasoning with temporal alignment across modalities, 2025. 3
work page 2025
-
[70]
MiniGPT-4: Enhancing Vision-Language Understanding with Advanced Large Language Models
Deyao Zhu, Jun Chen, Xiaoqian Shen, Xiang Li, and Mo- hamed Elhoseiny. Minigpt-4: Enhancing vision-language understanding with advanced large language models.arXiv preprint arXiv:2304.10592, 2023. 1
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[71]
Daniil Zverev, Thadd ¨aus Wiedemer, Ameya Prabhu, Matthias Bethge, Wieland Brendel, and A Koepke. Vg- gsounder: Audio-visual evaluations for foundation models. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 1027–1037, 2025. 1, 2, 3 11 See, Hear, and Understand: Benchmarking Audiovisual Human Speech Understanding in Multim...
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.