Recognition: no theorem link
Adapting MLLMs for Nuanced Video Retrieval
Pith reviewed 2026-05-16 22:16 UTC · model grok-4.3
The pith
Repurposing an MLLM with text-only contrastive training on hard negatives creates embeddings that achieve state-of-the-art nuanced video retrieval.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We repurpose a Multimodal Large Language Model (MLLM) trained to generate text into an embedding model. We fine-tune it with a contrastive loss on text alone with carefully sampled hard negatives that instill the desired nuances in the learned embedding space. Despite the text-only training, our method achieves state of the art performance on all benchmarks for nuanced video retrieval. We also analyze how this improvement is achieved, and show that text-only training reduces the modality gap between text and video embeddings leading to better organization of the embedding space.
What carries the argument
Contrastive fine-tuning of an MLLM on hard-negative text pairs that force learning of temporal, negation, and composed distinctions.
If this is right
- The model reliably separates temporally opposite actions such as opening a door versus closing a door.
- Queries containing explicit negators like 'not' or 'none' are handled correctly without retrieving unwanted content.
- Composed retrieval works when the query combines an example video with a text edit instruction.
- Text and video embeddings sit closer together in the space, improving overall organization for retrieval.
Where Pith is reading between the lines
- Large language models trained only on text appear to already contain much of the logical and temporal structure needed for video distinctions.
- The same adaptation pattern could be tested on other modalities or tasks where paired data is scarce but text descriptions are abundant.
- Systematic expansion of the hard-negative sampling strategy to cover more complex logical combinations might further strengthen performance.
Load-bearing premise
Hard negatives sampled from text data alone are sufficient to instill temporal, negation, and multimodal distinctions that transfer effectively to video embeddings.
What would settle it
If the text-only model scores below existing video-trained baselines on any of the temporal, negation, or composed retrieval benchmarks, the claim that text hard negatives suffice would not hold.
Figures


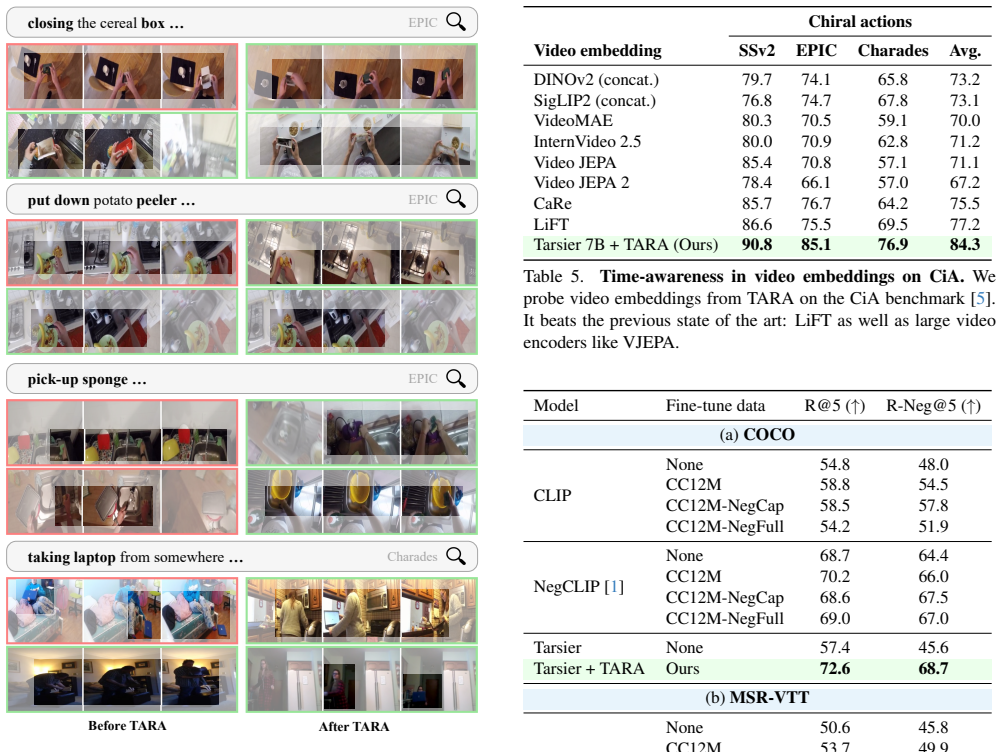





read the original abstract
Our objective is to build an embedding model that captures the nuanced relationship between a search query and candidate videos. We cover three aspects of nuanced retrieval: (i) temporal, (ii) negation, and (iii) multimodal. For temporal nuance, we consider chiral actions that need distinguishing between temporally opposite actions like "opening a door" vs. "closing a door". For negation, we consider queries with negators such as "not", "none" that allow user to specify what they do not want. For multimodal nuance, we consider the task of composed retrieval where the query comprises a video along with a text edit instruction. The goal is to develop a unified embedding model that handles such nuances effectively. To that end, we repurpose a Multimodal Large Language Model (MLLM) trained to generate text into an embedding model. We fine-tune it with a contrastive loss on text alone with carefully sampled hard negatives that instill the desired nuances in the learned embedding space. Despite the text-only training, our method achieves state of the art performance on all benchmarks for nuanced video retrieval. We also analyze how this improvement is achieved, and show that text-only training reduces the modality gap between text and video embeddings leading to better organization of the embedding space.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes repurposing a Multimodal Large Language Model (MLLM) as an embedding model for nuanced video retrieval by fine-tuning it with contrastive loss exclusively on text data. Hard negatives are sampled to target three nuances: temporal distinctions (e.g., chiral actions such as 'opening a door' vs. 'closing a door'), negation (queries containing 'not' or 'none'), and multimodal composed retrieval (video plus text edit instruction). The central claim is that this text-only training yields state-of-the-art performance on all relevant benchmarks while reducing the modality gap between text and video embeddings.
Significance. If the results and analysis hold, the work would be significant for showing that targeted text-only contrastive fine-tuning can instill transferable temporal, negation, and compositional distinctions in MLLM embeddings without paired video data, providing an efficient path to adapt large models for complex cross-modal retrieval and potentially reducing reliance on expensive multimodal training corpora.
major comments (2)
- [Abstract] Abstract: The assertion of 'state of the art performance on all benchmarks' and 'modality-gap reduction' supplies no quantitative metrics, benchmark names, hard-negative sampling procedure, or error analysis, leaving the central empirical claim unevidenced in the provided text.
- [Experiments] Experiments/Analysis section: No ablation isolates whether text-only hard negatives (e.g., chiral or negated pairs) actually separate video embeddings at inference time. A direct comparison of pre- vs. post-training video-video similarities for opposite actions, or video-only vs. text-only negative variants, is required to substantiate that distinctions survive the modality gap rather than arising from text clustering alone.
minor comments (2)
- [Method] Clarify the precise MLLM backbone, the exact contrastive loss formulation (including temperature and margin hyperparameters), and the criteria used to sample hard negatives from text.
- [Method] Add explicit notation for the embedding extraction process from the MLLM (e.g., which token or layer is used) to improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We agree that the abstract would be strengthened by including quantitative metrics and that targeted ablations would better isolate the effect of text-only hard negatives on video embeddings. We address each major comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: The assertion of 'state of the art performance on all benchmarks' and 'modality-gap reduction' supplies no quantitative metrics, benchmark names, hard-negative sampling procedure, or error analysis, leaving the central empirical claim unevidenced in the provided text.
Authors: We agree the abstract is high-level and lacks specific numbers. The full manuscript reports SOTA results with concrete recall@K metrics on the relevant temporal, negation, and multimodal benchmarks, along with modality-gap analysis via cosine similarities and t-SNE visualizations. In the revision we will expand the abstract to include key quantitative improvements (e.g., recall gains), name the benchmarks, briefly describe the hard-negative sampling strategy, and reference the error analysis already present in the experiments section. revision: yes
-
Referee: [Experiments] Experiments/Analysis section: No ablation isolates whether text-only hard negatives (e.g., chiral or negated pairs) actually separate video embeddings at inference time. A direct comparison of pre- vs. post-training video-video similarities for opposite actions, or video-only vs. text-only negative variants, is required to substantiate that distinctions survive the modality gap rather than arising from text clustering alone.
Authors: This observation is correct; the current manuscript shows overall retrieval gains and modality-gap reduction but does not include an explicit pre-/post-training video-video similarity ablation for chiral or negated pairs, nor a video-only versus text-only negative variant comparison. We will add this ablation in the revised Experiments section, reporting average cosine similarities between video embeddings of opposite actions before and after training, as well as results when negatives are drawn from video versus text sources, to demonstrate that the distinctions transfer across the modality gap. revision: yes
Circularity Check
No circularity: empirical fine-tuning evaluated on external benchmarks
full rationale
The paper presents an empirical adaptation of an MLLM into an embedding model via contrastive fine-tuning on text-only data with hard negatives, claiming improved video retrieval performance on external benchmarks. No derivation chain, equations, or load-bearing steps reduce to self-defined quantities, fitted inputs renamed as predictions, or self-citation chains. The modality-gap reduction is reported as an observed outcome of training rather than a constructed identity, and the method is validated against independent test sets without internal circular reduction.
Axiom & Free-Parameter Ledger
free parameters (1)
- contrastive loss hyperparameters
axioms (1)
- domain assumption Hard negatives sampled from text can instill temporal, negation, and multimodal distinctions that generalize to video.
Reference graph
Works this paper leans on
-
[1]
Vision-language models do not understand negation
Kumail Alhamoud, Shaden Alshammari, Yonglong Tian, Guohao Li, Philip HS Torr, Yoon Kim, and Marzyeh Ghas- semi. Vision-language models do not understand negation. InCVPR, 2025. 6, 7, 8, 4
work page 2025
-
[2]
Localizing mo- ments in video with natural language
Lisa Anne Hendricks, Oliver Wang, Eli Shechtman, Josef Sivic, Trevor Darrell, and Bryan Russell. Localizing mo- ments in video with natural language. InICCV, 2017. 2
work page 2017
-
[3]
Localizing Mo- ments in Video with Natural Language
Lisa Anne Hendricks, Oliver Wang, Eli Shechtman, Josef Sivic, Trevor Darrell, and Bryan Russell. Localizing Mo- ments in Video with Natural Language. InICCV, 2017. 1, 8
work page 2017
-
[4]
Claude 4 system card: Claude opus 4 and claude sonnet 4, 2025
Anthropic. Claude 4 system card: Claude opus 4 and claude sonnet 4, 2025. Accessed: 2025-11-13. 4
work page 2025
-
[5]
Piyush Bagad and Andrew Zisserman. Chirality in action: Time-aware video representation learning by latent straight- ening.arXiv preprint arXiv:2509.08502, 2025. 2, 3, 4, 5, 7, 8
-
[6]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, et al. Qwen2. 5-vl technical report.arXiv preprint arXiv:2502.13923, 2025. 2, 6
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[7]
Frozen in Time: A Joint Video and Image Encoder for End-to-end Retrieval
Max Bain, Arsha Nagrani, G ¨ul Varol, and Andrew Zisser- man. Frozen in Time: A Joint Video and Image Encoder for End-to-end Retrieval. InICCV, 2021. 1, 2
work page 2021
-
[8]
Speednet: Learning the Speediness in Videos
Sagie Benaim, Ariel Ephrat, Oran Lang, Inbar Mosseri, William T Freeman, Michael Rubinstein, Michal Irani, and Tali Dekel. Speednet: Learning the Speediness in Videos. In CVPR, 2020. 2
work page 2020
-
[9]
Perception Encoder: The best visual embeddings are not at the output of the network
Daniel Bolya, Po-Yao Huang, Peize Sun, Jang Hyun Cho, Andrea Madotto, Tengyu Ma, Jiale Zhi, Jathushan Ra- jasegaran, Hanoona Rasheed, et al. Perception encoder: The best visual embeddings are not at the output of the network. arXiv preprint arXiv:2504.13181, 2025. 6
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[10]
Revisiting the” Video” in Video-Language Understanding
Shyamal Buch, Crist ´obal Eyzaguirre, Adrien Gaidon, Jiajun Wu, Li Fei-Fei, and Juan Carlos Niebles. Revisiting the” Video” in Video-Language Understanding. InCVPR, 2022. 1, 2, 3
work page 2022
-
[11]
Quo Vadis, Action Recognition? A New Model and the Kinetics Dataset
Joao Carreira and Andrew Zisserman. Quo Vadis, Action Recognition? A New Model and the Kinetics Dataset. In CVPR, 2017. 1, 2, 8
work page 2017
-
[12]
Collecting highly paral- lel data for paraphrase evaluation
David Chen and William B Dolan. Collecting highly paral- lel data for paraphrase evaluation. InProceedings of the 49th annual meeting of the association for computational linguis- tics: human language technologies, 2011. 2
work page 2011
-
[13]
Collecting highly paral- lel data for paraphrase evaluation
David Chen and William B Dolan. Collecting highly paral- lel data for paraphrase evaluation. InProceedings of the 49th annual meeting of the association for computational linguis- tics: human language technologies, 2011. 1, 2, 8
work page 2011
-
[14]
Are we on the right way for evaluating large vision-language models?NeurIPS, 37, 2024
Lin Chen, Jinsong Li, Xiaoyi Dong, Pan Zhang, Yuhang Zang, Zehui Chen, Haodong Duan, Jiaqi Wang, Yu Qiao, Dahua Lin, et al. Are we on the right way for evaluating large vision-language models?NeurIPS, 37, 2024. 2
work page 2024
-
[15]
Unfolding Videos Dynamics Via Tay- lor Expansion.arXiv preprint arXiv:2409.02371, 2024
Siyi Chen, Minkyu Choi, Zesen Zhao, Kuan Han, Qing Qu, and Zhongming Liu. Unfolding Videos Dynamics Via Tay- lor Expansion.arXiv preprint arXiv:2409.02371, 2024. 2
-
[16]
Lost in time: A new temporal benchmark for videollms.arXiv preprint arXiv:2410.07752, 2024
Daniel Cores, Michael Dorkenwald, Manuel Mucientes, Cees GM Snoek, and Yuki M Asano. Lost in time: A new temporal benchmark for videollms.arXiv preprint arXiv:2410.07752, 2024. 1, 2
-
[17]
Tvbench: Redesigning video-language evaluation.Arxiv, 2024
Daniel Cores, Michael Dorkenwald, Manuel Mucientes, Cees GM Snoek, and Yuki M Asano. Tvbench: Redesigning video-language evaluation.Arxiv, 2024. 2
work page 2024
-
[18]
Think then embed: Generative context improves multimodal embedding.arXiv preprint arXiv:2510.05014,
Xuanming Cui, Jianpeng Cheng, Hong-you Chen, Satya Narayan Shukla, Abhijeet Awasthi, Xichen Pan, Chaitanya Ahuja, Shlok Kumar Mishra, Qi Guo, Ser-Nam Lim, et al. Think then embed: Generative context improves multimodal embedding.arXiv preprint arXiv:2510.05014,
-
[19]
Scaling Egocentric Vision: The EPIC-Kitchens Dataset
Dima Damen, Hazel Doughty, Giovanni Maria Farinella, Sanja Fidler, Antonino Furnari, Evangelos Kazakos, Davide Moltisanti, Jonathan Munro, Toby Perrett, Will Price, et al. Scaling Egocentric Vision: The EPIC-Kitchens Dataset. In ECCV, 2018. 2, 7, 8, 5
work page 2018
-
[20]
Ishan Dave, Rohit Gupta, Mamshad Nayeem Rizve, and Mubarak Shah. TCLR: Temporal Contrastive Learning for Video Representation.Computer Vision and Image Under- standing, 2022. 2
work page 2022
-
[21]
Molmo and pixmo: Open weights and open data for state-of-the-art vision-language models
Matt Deitke, Christopher Clark, Sangho Lee, Rohun Tri- pathi, Yue Yang, Jae Sung Park, Mohammadreza Salehi, Niklas Muennighoff, Kyle Lo, Luca Soldaini, et al. Molmo and pixmo: Open weights and open data for state-of-the-art vision-language models. InCVPR, 2025. 2
work page 2025
-
[22]
How do you do it? fine-grained action understanding with pseudo-adverbs
Hazel Doughty and Cees GM Snoek. How do you do it? fine-grained action understanding with pseudo-adverbs. In CVPR, 2022. 2, 7, 8, 5
work page 2022
-
[23]
Action modifiers: Learning from adverbs in instructional videos
Hazel Doughty, Ivan Laptev, Walterio Mayol-Cuevas, and Dima Damen. Action modifiers: Learning from adverbs in instructional videos. InCVPR, 2020. 8
work page 2020
-
[24]
Reversed in time: A novel temporal-emphasized benchmark for cross-modal video-text retrieval
Yang Du, Yuqi Liu, and Qin Jin. Reversed in time: A novel temporal-emphasized benchmark for cross-modal video-text retrieval. InACM MM, 2024. 2, 5, 6, 8
work page 2024
-
[25]
Temporal Cycle- Consistency Learning
Debidatta Dwibedi, Yusuf Aytar, Jonathan Tompson, Pierre Sermanet, and Andrew Zisserman. Temporal Cycle- Consistency Learning. InCVPR, 2019. 2
work page 2019
-
[26]
ColPali: Efficient Document Retrieval with Vision Language Models
Manuel Faysse, Hugues Sibille, Tony Wu, Bilel Omrani, Gautier Viaud, C ´eline Hudelot, and Pierre Colombo. Col- pali: Efficient document retrieval with vision language mod- els.arXiv preprint arXiv:2407.01449, 2024. 8
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[27]
SimCSE: Simple Contrastive Learning of Sentence Embeddings
Tianyu Gao, Xingcheng Yao, and Danqi Chen. Simcse: Simple contrastive learning of sentence embeddings.arXiv preprint arXiv:2104.08821, 2021. 3, 4
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[28]
Video Time: Properties, Encoders and Evaluation
Amir Ghodrati, Efstratios Gavves, and Cees GM Snoek. Video Time: Properties, Encoders and Evaluation.arXiv preprint arXiv:1807.06980, 2018. 2 9
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[29]
The” Something Something” Video Database for Learning and Evaluating Visual Common Sense
Raghav Goyal, Samira Ebrahimi Kahou, Vincent Michal- ski, Joanna Materzynska, Susanne Westphal, Heuna Kim, Valentin Haenel, Ingo Fruend, Peter Yianilos, Moritz Mueller-Freitag, et al. The” Something Something” Video Database for Learning and Evaluating Visual Common Sense. InICCV, 2017. 2, 8, 5
work page 2017
-
[30]
Ego4d: Around the World in 3,000 Hours of Egocentric Video
Kristen Grauman, Andrew Westbury, Eugene Byrne, Zachary Chavis, Antonino Furnari, Rohit Girdhar, Jackson Hamburger, Hao Jiang, Miao Liu, Xingyu Liu, et al. Ego4d: Around the World in 3,000 Hours of Egocentric Video. In CVPR, 2022. 2, 4
work page 2022
-
[31]
Zhuoning Guo, Mingxin Li, Yanzhao Zhang, Dingkun Long, Pengjun Xie, and Xiaowen Chu. Towards univer- sal video retrieval: Generalizing video embedding via syn- thesized multimodal pyramid curriculum.arXiv preprint arXiv:2510.27571, 2025. 6
-
[32]
De-An Huang, Vignesh Ramanathan, Dhruv Mahajan, Lorenzo Torresani, Manohar Paluri, Li Fei-Fei, and Juan Carlos Niebles. What makes a video a video: Ana- lyzing temporal information in video understanding models and datasets. InCVPR, 2018. 2
work page 2018
-
[33]
Space-Time Correspondence as a Contrastive Random Walk.NeurIPS,
Allan Jabri, Andrew Owens, and Alexei Efros. Space-Time Correspondence as a Contrastive Random Walk.NeurIPS,
-
[34]
Slow and Steady Feature Analysis: Higher Order Temporal Coherence in Video
Dinesh Jayaraman and Kristen Grauman. Slow and Steady Feature Analysis: Higher Order Temporal Coherence in Video. InCVPR, 2016. 2
work page 2016
-
[35]
Scaling sentence embeddings with large language models
Ting Jiang, Shaohan Huang, Zhongzhi Luan, Deqing Wang, and Fuzhen Zhuang. Scaling sentence embeddings with large language models. InFindings of the Association for Compu- tational Linguistics: EMNLP 2024, 2024. 3
work page 2024
-
[36]
E5-V: Universal Embeddings with Multimodal Large Language Models
Ting Jiang, Minghui Song, Zihan Zhang, Haizhen Huang, Weiwei Deng, Feng Sun, Qi Zhang, Deqing Wang, and Fuzhen Zhuang. E5-v: Universal embeddings with multimodal large language models.arXiv preprint arXiv:2407.12580, 2024. 1, 2, 3, 6, 5
work page internal anchor Pith review arXiv 2024
-
[37]
Ziyan Jiang, Rui Meng, Xinyi Yang, Semih Yavuz, Yingbo Zhou, and Wenhu Chen. Vlm2vec: Training vision-language models for massive multimodal embedding tasks.arXiv preprint arXiv:2410.05160, 2024. 2, 8
-
[38]
Dinov2 meets text: A unified framework for image-and pixel-level vision-language alignment
Cijo Jose, Th ´eo Moutakanni, Dahyun Kang, Federico Baldassarre, Timoth ´ee Darcet, Hu Xu, Daniel Li, Marc Szafraniec, Micha ¨el Ramamonjisoa, Maxime Oquab, et al. Dinov2 meets text: A unified framework for image-and pixel-level vision-language alignment. InCVPR, 2025. 6, 8
work page 2025
-
[39]
Victr: Video-conditioned text representa- tions for activity recognition
Kumara Kahatapitiya, Anurag Arnab, Arsha Nagrani, and Michael S Ryoo. Victr: Video-conditioned text representa- tions for activity recognition. InCVPR, 2024. 2
work page 2024
-
[40]
Amita Kamath, Jack Hessel, and Kai-Wei Chang. Text encoders bottleneck compositionality in contrastive vision- language models.arXiv preprint arXiv:2305.14897, 2023. 2
-
[41]
Self- supervised Video Representation Learning with Space-Time Cubic Puzzles
Dahun Kim, Donghyeon Cho, and In So Kweon. Self- supervised Video Representation Learning with Space-Time Cubic Puzzles. InAAAI, 2019. 2
work page 2019
-
[42]
HMDB: A Large Video Database for Human Motion Recognition
Hildegard Kuehne, Hueihan Jhuang, Est ´ıbaliz Garrote, Tomaso Poggio, and Thomas Serre. HMDB: A Large Video Database for Human Motion Recognition. InICCV, 2011. 2, 8
work page 2011
-
[43]
The language of actions: Recovering the syntax and semantics of goal- directed human activities
Hilde Kuehne, Ali Arslan, and Thomas Serre. The language of actions: Recovering the syntax and semantics of goal- directed human activities. InCVPR, 2014. 8
work page 2014
-
[44]
arXiv preprint arXiv:2206.03428 , year=
Jie Lei, Tamara L Berg, and Mohit Bansal. Reveal- ing Single Frame Bias for Video-and-Language Learning. arXiv:2206.03428, 2022. 1, 3, 6
-
[45]
Revealing single frame bias for video-and-language learning
Jie Lei, Tamara Berg, and Mohit Bansal. Revealing single frame bias for video-and-language learning. InProceedings of the 61st Annual Meeting of the Association for Computa- tional Linguistics (Volume 1: Long Papers), 2023. 2
work page 2023
-
[46]
Unmasked teacher: Towards training-efficient video foundation models
Kunchang Li, Yali Wang, Yizhuo Li, Yi Wang, Yinan He, Limin Wang, and Yu Qiao. Unmasked teacher: Towards training-efficient video foundation models. InICCV, 2023. 6
work page 2023
-
[47]
Mvbench: A Comprehensive Multi-modal Video Under- standing Benchmark
Kunchang Li, Yali Wang, Yinan He, Yizhuo Li, Yi Wang, Yi Liu, Zun Wang, Jilan Xu, Guo Chen, Ping Luo, et al. Mvbench: A Comprehensive Multi-modal Video Under- standing Benchmark. InCVPR, 2024. 2
work page 2024
-
[48]
Victor Weixin Liang, Yuhui Zhang, Yongchan Kwon, Serena Yeung, and James Y Zou. Mind the gap: Understanding the modality gap in multi-modal contrastive representation learning.NeurIPS, 35, 2022. 3, 5
work page 2022
-
[49]
Egocentric video-language pretraining.NeurIPS, 35, 2022
Kevin Qinghong Lin, Jinpeng Wang, Mattia Soldan, Michael Wray, Rui Yan, Eric Z Xu, Difei Gao, Rong-Cheng Tu, Wen- zhe Zhao, Weijie Kong, et al. Egocentric video-language pretraining.NeurIPS, 35, 2022. 2
work page 2022
-
[50]
Mm-embed: Universal multimodal retrieval with multimodal llms.arXiv preprint arXiv:2411.02571, 2024
Sheng-Chieh Lin, Chankyu Lee, Mohammad Shoeybi, Jimmy Lin, Bryan Catanzaro, and Wei Ping. Mm-embed: Universal multimodal retrieval with multimodal llms.arXiv preprint arXiv:2411.02571, 2024. 2
-
[51]
Lamra: Large multimodal model as your advanced retrieval assistant
Yikun Liu, Yajie Zhang, Jiayin Cai, Xiaolong Jiang, Yao Hu, Jiangchao Yao, Yanfeng Wang, and Weidi Xie. Lamra: Large multimodal model as your advanced retrieval assistant. In CVPR, 2025. 3, 6, 8
work page 2025
-
[52]
Huaishao Luo, Lei Ji, Ming Zhong, Yang Chen, Wen Lei, Nan Duan, and Tianrui Li. Clip4clip: An empirical study of clip for end to end video clip retrieval.arXiv preprint arXiv:2104.08860, 2021. 6
-
[53]
X-clip: End-to-end multi-grained con- trastive learning for video-text retrieval
Yiwei Ma, Guohai Xu, Xiaoshuai Sun, Ming Yan, Ji Zhang, and Rongrong Ji. X-clip: End-to-end multi-grained con- trastive learning for video-text retrieval. InACM MM, 2022. 2, 6
work page 2022
-
[54]
Foundation mod- els for video understanding: A survey.arXiv preprint arXiv:2405.03770, 2024
Neelu Madan, Andreas Møgelmose, Rajat Modi, Yogesh S Rawat, and Thomas B Moeslund. Foundation mod- els for video understanding: A survey.arXiv preprint arXiv:2405.03770, 2024. 2
-
[55]
Rui Meng, Ziyan Jiang, Ye Liu, Mingyi Su, Xinyi Yang, Yuepeng Fu, Can Qin, Zeyuan Chen, Ran Xu, Caiming Xiong, et al. Vlm2vec-v2: Advancing multimodal em- bedding for videos, images, and visual documents.arXiv preprint arXiv:2507.04590, 2025. 2, 3, 6, 8
-
[56]
Howto100m: Learning a Text-Video Embedding by Watching Hundred Million Narrated Video Clips
Antoine Miech, Dimitri Zhukov, Jean-Baptiste Alayrac, Makarand Tapaswi, Ivan Laptev, and Josef Sivic. Howto100m: Learning a Text-Video Embedding by Watching Hundred Million Narrated Video Clips. InICCV,
-
[57]
Verbs in Action: Im- proving Verb Understanding in Video-Language Models
Liliane Momeni, Mathilde Caron, Arsha Nagrani, Andrew Zisserman, and Cordelia Schmid. Verbs in Action: Im- proving Verb Understanding in Video-Language Models. In ICCV, 2023. 2, 7, 8, 4
work page 2023
-
[58]
Per- ception test: A diagnostic benchmark for multimodal video models.NeurIPS, 36, 2023
Viorica Patraucean, Lucas Smaira, Ankush Gupta, Adria Re- casens, Larisa Markeeva, Dylan Banarse, Skanda Koppula, Mateusz Malinowski, Yi Yang, Carl Doersch, et al. Per- ception test: A diagnostic benchmark for multimodal video models.NeurIPS, 36, 2023. 2
work page 2023
-
[59]
Spatiotem- poral Contrastive Video Representation Learning
Rui Qian, Tianjian Meng, Boqing Gong, Ming-Hsuan Yang, Huisheng Wang, Serge Belongie, and Yin Cui. Spatiotem- poral Contrastive Video Representation Learning. InCVPR,
-
[60]
Learning Transferable Visual Models from Natural Language Supervi- sion
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning Transferable Visual Models from Natural Language Supervi- sion. InICML, 2021. 2, 6, 8
work page 2021
-
[61]
Direct preference optimization: Your language model is secretly a reward model.NeurIPS, 36, 2023
Rafael Rafailov, Archit Sharma, Eric Mitchell, Christo- pher D Manning, Stefano Ermon, and Chelsea Finn. Direct preference optimization: Your language model is secretly a reward model.NeurIPS, 36, 2023. 3
work page 2023
-
[62]
Broaden Your Views for Self-supervised Video Learning
Adria Recasens, Pauline Luc, Jean-Baptiste Alayrac, Luyu Wang, Florian Strub, Corentin Tallec, Mateusz Malinowski, Viorica P ˘atr˘aucean, Florent Altch ´e, Michal Valko, et al. Broaden Your Views for Self-supervised Video Learning. In ICCV, 2021. 2
work page 2021
-
[63]
Veloc- iti: Benchmarking video-language compositional reasoning with strict entailment
Darshana Saravanan, Varun Gupta, Darshan Singh, Zee- shan Khan, Vineet Gandhi, and Makarand Tapaswi. Veloc- iti: Benchmarking video-language compositional reasoning with strict entailment. InCVPR, 2025. 2
work page 2025
-
[64]
Hollywood in Homes: Crowdsourcing Data Collection for Activity Under- standing
Gunnar A Sigurdsson, G ¨ul Varol, Xiaolong Wang, Ali Farhadi, Ivan Laptev, and Abhinav Gupta. Hollywood in Homes: Crowdsourcing Data Collection for Activity Under- standing. InECCV, 2016. 2, 5
work page 2016
-
[65]
UCF101: A Dataset of 101 Human Actions Classes From Videos in The Wild
K Soomro. UCF101: A Dataset of 101 Human Actions Classes from Videos in the Wild.arXiv:1212.0402, 2012. 2, 8
work page internal anchor Pith review Pith/arXiv arXiv 2012
-
[66]
Shashanka Venkataramanan, Mamshad Nayeem Rizve, Jo ˜ao Carreira, Yuki M Asano, and Yannis Avrithis. Is ImageNet Worth 1 Video? Learning Strong Image Encoders from 1 Long Unlabelled Video.arXiv preprint arXiv:2310.08584,
-
[67]
Covr: Learning composed video retrieval from web video captions
Lucas Ventura, Antoine Yang, Cordelia Schmid, and G ¨ul Varol. Covr: Learning composed video retrieval from web video captions. InAAAI, 2024. 2, 3
work page 2024
-
[68]
Lucas Ventura, Antoine Yang, Cordelia Schmid, and G ¨ul Varol. Covr-2: Automatic data construction for composed video retrieval.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2024. 3
work page 2024
-
[69]
Jiawei Wang, Liping Yuan, Yuchen Zhang, and Haomiao Sun. Tarsier: Recipes for training and evaluating large video description models.arXiv preprint arXiv:2407.00634, 2024. 2, 5
-
[70]
Actionclip: A new paradigm for video action recognition
Mengmeng Wang, Jiazheng Xing, and Yong Liu. Actionclip: A new paradigm for video action recognition.arXiv preprint arXiv:2109.08472, 2021. 2
-
[71]
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution
Peng Wang, Shuai Bai, Sinan Tan, Shijie Wang, Zhihao Fan, Jinze Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, et al. Qwen2-vl: Enhancing vision-language model’s perception of the world at any resolution.arXiv preprint arXiv:2409.12191, 2024. 6
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[72]
Vatex: A large-scale, high- quality multilingual dataset for video-and-language research
Xin Wang, Jiawei Wu, Junkun Chen, Lei Li, Yuan-Fang Wang, and William Yang Wang. Vatex: A large-scale, high- quality multilingual dataset for video-and-language research. InICCV, 2019. 8
work page 2019
-
[73]
InternVid: A Large-scale Video-Text Dataset for Multimodal Understanding and Generation
Yi Wang, Yinan He, Yizhuo Li, Kunchang Li, Jiashuo Yu, Xin Ma, Xinhao Li, Guo Chen, Xinyuan Chen, Yaohui Wang, et al. Internvid: A large-scale video-text dataset for multimodal understanding and generation.arXiv preprint arXiv:2307.06942, 2023. 2, 6
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[74]
Internvideo2: Scaling Foundation Models for Mul- timodal Video Understanding
Yi Wang, Kunchang Li, Xinhao Li, Jiashuo Yu, Yinan He, Guo Chen, Baoqi Pei, Rongkun Zheng, Zun Wang, Yansong Shi, et al. Internvideo2: Scaling Foundation Models for Mul- timodal Video Understanding. InECCV, 2024. 6
work page 2024
-
[75]
InternVideo2.5: Empowering Video MLLMs with Long and Rich Context Modeling
Yi Wang, Xinhao Li, Ziang Yan, Yinan He, Jiashuo Yu, Xi- angyu Zeng, Chenting Wang, Changlian Ma, Haian Huang, Jianfei Gao, et al. Internvideo2. 5: Empowering video mllms with long and rich context modeling.arXiv preprint arXiv:2501.12386, 2025. 2
work page internal anchor Pith review arXiv 2025
-
[76]
Pax- ion: Patching action knowledge in video-language founda- tion models.NeurIPS, 36, 2023
Zhenhailong Wang, Ansel Blume, Sha Li, Genglin Liu, Jaemin Cho, Zineng Tang, Mohit Bansal, and Heng Ji. Pax- ion: Patching action knowledge in video-language founda- tion models.NeurIPS, 36, 2023. 2
work page 2023
-
[77]
Learning and Using the Arrow of Time
Donglai Wei, Joseph J Lim, Andrew Zisserman, and William T Freeman. Learning and Using the Arrow of Time. InCVPR, 2018. 2
work page 2018
-
[78]
Next-qa: Next phase of question-answering to explaining temporal actions
Junbin Xiao, Xindi Shang, Angela Yao, and Tat-Seng Chua. Next-qa: Next phase of question-answering to explaining temporal actions. InCVPR, 2021. 2
work page 2021
-
[79]
arXiv preprint arXiv:2109.14084 , year=
Hu Xu, Gargi Ghosh, Po-Yao Huang, Dmytro Okhonko, Armen Aghajanyan, Florian Metze, Luke Zettlemoyer, and Christoph Feichtenhofer. Videoclip: Contrastive pre-training for zero-shot video-text understanding.arXiv preprint arXiv:2109.14084, 2021. 2
-
[80]
Msr-vtt: A large video description dataset for bridging video and language
Jun Xu, Tao Mei, Ting Yao, and Yong Rui. Msr-vtt: A large video description dataset for bridging video and language. In CVPR, 2016. 1, 2, 8
work page 2016
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.