Revisiting the Reliability of Language Models in Instruction-Following
Pith reviewed 2026-05-16 22:49 UTC · model grok-4.3
The pith
Language models lose up to 61.8 percent instruction-following accuracy on prompts with subtle phrasing changes that preserve intent.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Current language models exhibit substantial insufficiency in nuance-oriented reliability, with their instruction-following performance dropping by up to 61.8 percent under nuanced prompt modifications that convey analogous user intents, as quantified by the reliable@k metric on the IFEval++ benchmark constructed through automated data augmentation.
What carries the argument
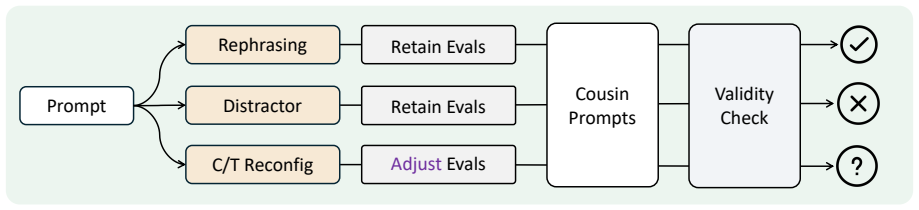
the reliable@k metric, which measures a model's consistent instruction-following accuracy across multiple cousin prompts that preserve original user intent
If this is right
- Standard benchmarks such as IFEval overestimate real-world reliability because they evaluate only single fixed prompts.
- Both proprietary and open-source models require new training or evaluation methods to achieve consistent performance under prompt variation.
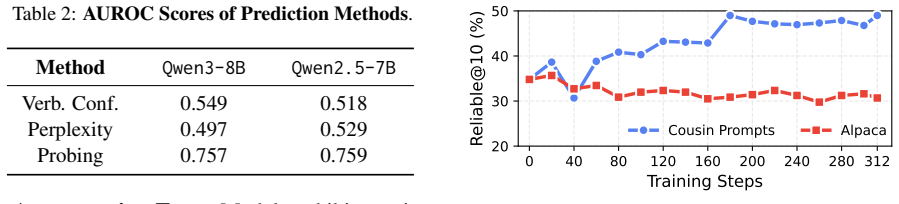
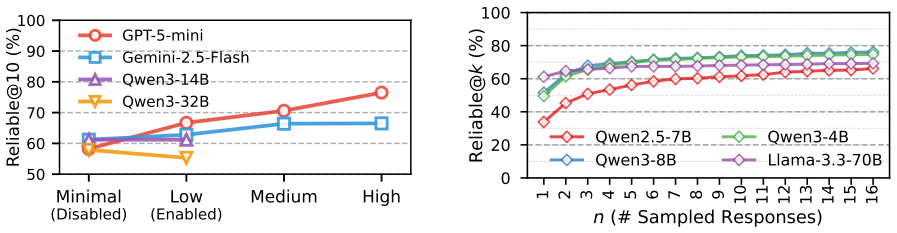
- The three improvement recipes explored in the paper offer concrete directions for raising reliable@k scores without changing base model size.
- Deployed LLM services need multi-variant testing to ensure dependable behavior when users naturally vary their instructions.
Where Pith is reading between the lines
- The reliability shortfall may explain inconsistent results in interactive applications where users iterate on prompts rather than using exact benchmark wording.
- Applying the same cousin-prompt generation method to other tasks such as reasoning or code generation could reveal whether nuance sensitivity is widespread.
- Training data that explicitly includes many intent-preserving variants might close the gap more effectively than post-hoc fixes.
Load-bearing premise
The automated data-augmentation pipeline produces cousin prompts that preserve the original user intent without changing task difficulty or introducing new ambiguities.
What would settle it
A human verification study in which raters judge that the generated cousin prompts alter perceived task difficulty or intent would show that the measured drops do not stem from nuance sensitivity alone.
Figures


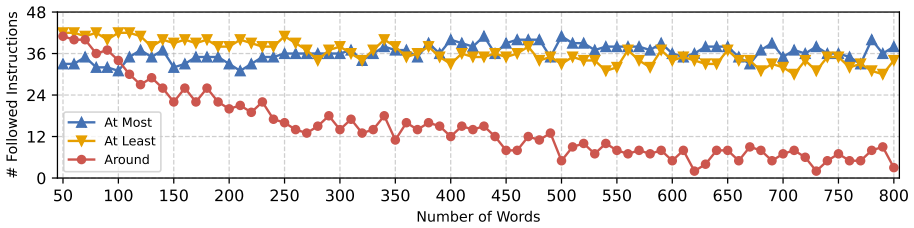

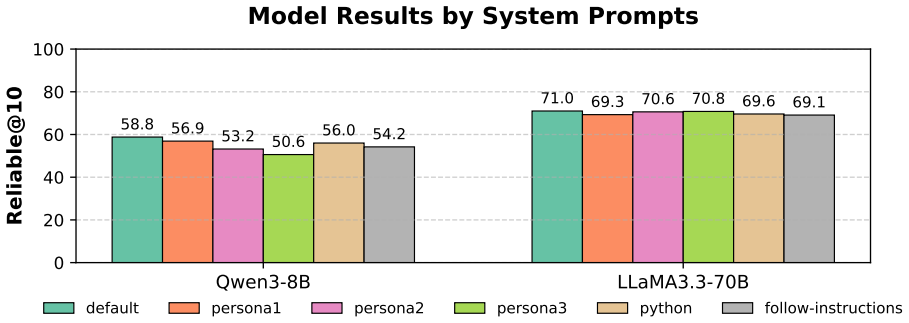

read the original abstract
Advanced LLMs have achieved near-ceiling instruction-following accuracy on benchmarks such as IFEval. However, these impressive scores do not necessarily translate to reliable services in real-world use, where users often vary their phrasing, contextual framing, and task formulations. In this paper, we study nuance-oriented reliability: whether models exhibit consistent competence across cousin prompts that convey analogous user intents but with subtle nuances. To quantify this, we introduce a new metric, reliable@k, and develop an automated pipeline that generates high-quality cousin prompts via data augmentation. Building upon this, we construct IFEval++ for systematic evaluation. Across 20 proprietary and 26 open-source LLMs, we find that current models exhibit substantial insufficiency in nuance-oriented reliability -- their performance can drop by up to 61.8% with nuanced prompt modifications. What's more, we characterize it and explore three potential improvement recipes. Our findings highlight nuance-oriented reliability as a crucial yet underexplored next step toward more dependable and trustworthy LLM behavior. Our code and benchmark are accessible: https://github.com/jianshuod/IFEval-pp.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that LLMs exhibit substantial nuance-oriented unreliability in instruction-following: across 46 models (20 proprietary, 26 open-source), performance on IFEval-style tasks drops by up to 61.8% when evaluated on automatically generated 'cousin' prompts that convey the same intent with subtle phrasing or framing variations. It introduces the reliable@k metric, an automated data-augmentation pipeline to create IFEval++, and explores three improvement recipes, arguing that standard benchmarks like IFEval overestimate real-world reliability.
Significance. If the cousin prompts are shown to preserve intent, difficulty, and ambiguity levels, the work would usefully highlight a practical gap between benchmark performance and robust instruction-following. The scale of the evaluation (46 models) and the public release of code and benchmark are clear strengths that enable follow-up work. The result would shift attention from raw accuracy to consistency under realistic prompt variation.
major comments (3)
- [§3] §3 (Automated Pipeline and IFEval++ construction): The headline 61.8% drop rests entirely on the assumption that the data-augmentation pipeline produces cousin prompts that preserve original user intent, task difficulty, and introduce no new ambiguities. No human validation, semantic-equivalence checks, or difficulty-parity assessment is reported for the generated set; without these, the observed gaps cannot be confidently attributed to model unreliability rather than prompt artifacts.
- [§4] §4 (Results and reliable@k definition): The maximum drop of 61.8% is presented without accompanying statistical controls (e.g., variance across multiple prompt generations per original, or difficulty-matched baselines). It is therefore unclear whether the reported insufficiency is systematic or driven by a small number of outlier prompt pairs.
- [§5] §5 (Improvement recipes): The three proposed recipes for improving nuance-oriented reliability are evaluated only on the same automatically generated cousins. This creates a circularity risk: any gains may reflect overfitting to the augmentation heuristics rather than genuine robustness gains.
minor comments (2)
- [§2] The notation for reliable@k is introduced without an explicit equation; adding a formal definition (e.g., as an average over k cousins) would improve clarity.
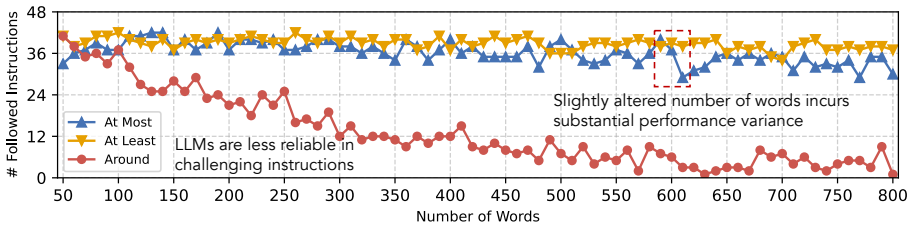
- [§4] Figure 2 (model-wise drops) would benefit from error bars or per-model variance to show consistency of the effect.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. The comments have prompted us to strengthen the validation, statistical analysis, and evaluation aspects of the work. We have made major revisions to address all points raised, as detailed in the point-by-point responses below. We believe these changes significantly improve the rigor of the paper.
read point-by-point responses
-
Referee: [§3] §3 (Automated Pipeline and IFEval++ construction): The headline 61.8% drop rests entirely on the assumption that the data-augmentation pipeline produces cousin prompts that preserve original user intent, task difficulty, and introduce no new ambiguities. No human validation, semantic-equivalence checks, or difficulty-parity assessment is reported for the generated set; without these, the observed gaps cannot be confidently attributed to model unreliability rather than prompt artifacts.
Authors: We agree that explicit validation of the cousin prompts is important for attributing the performance drops to model behavior rather than artifacts. In the revised manuscript, we have added a human evaluation study involving three annotators who assessed a random sample of 200 prompt pairs for intent preservation, difficulty equivalence, and absence of new ambiguities. The results show high agreement rates (over 85% for intent preservation), which we now report in §3 along with the annotation guidelines and inter-annotator agreement statistics. This strengthens our claim that the observed drops reflect nuance-oriented unreliability. revision: yes
-
Referee: [§4] §4 (Results and reliable@k definition): The maximum drop of 61.8% is presented without accompanying statistical controls (e.g., variance across multiple prompt generations per original, or difficulty-matched baselines). It is therefore unclear whether the reported insufficiency is systematic or driven by a small number of outlier prompt pairs.
Authors: We appreciate this observation. To provide better statistical grounding, we have extended the analysis in §4 to include: (1) results from multiple independent generations of cousin prompts for each original (with variance reported), (2) difficulty-matched baselines using prompts of similar complexity, and (3) confidence intervals for the reliable@k metric across the model suite. The maximum drop of 61.8% remains an observed value, but we now emphasize the distribution of drops and confirm that the insufficiency is systematic rather than outlier-driven. revision: yes
-
Referee: [§5] §5 (Improvement recipes): The three proposed recipes for improving nuance-oriented reliability are evaluated only on the same automatically generated cousins. This creates a circularity risk: any gains may reflect overfitting to the augmentation heuristics rather than genuine robustness gains.
Authors: We acknowledge the potential for circularity in evaluating improvements solely on the augmented data. In the revised version, we have introduced an additional evaluation on a set of 50 human-rephrased nuanced prompts (distinct from the automated pipeline) to test the improvement recipes. The results, now presented in §5, show that the gains from the recipes transfer to these human-crafted variations, mitigating concerns of overfitting to the augmentation process. We have also clarified the distinction between the training/augmentation and evaluation sets. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper introduces reliable@k as a direct empirical metric computed from model outputs on prompts generated by an automated augmentation pipeline for IFEval++. No equations, fitted parameters, or self-referential definitions are described that would reduce the reported performance drops (e.g., 61.8%) to inputs by construction. The central claim rests on external evaluation of LLMs rather than any self-definitional loop, fitted-input prediction, or load-bearing self-citation chain. This is a standard empirical benchmark study with independent measurement steps.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Cousin prompts generated via data augmentation preserve the original user intent
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.