Complement Submodular Information Measures for Balanced and Robust Data Selection
Pith reviewed 2026-06-30 13:15 UTC · model grok-4.3
The pith
Complement Submodular Information objectives preserve balanced structure between a data subset and its complement, outperforming classical submodular functions in robust selection.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
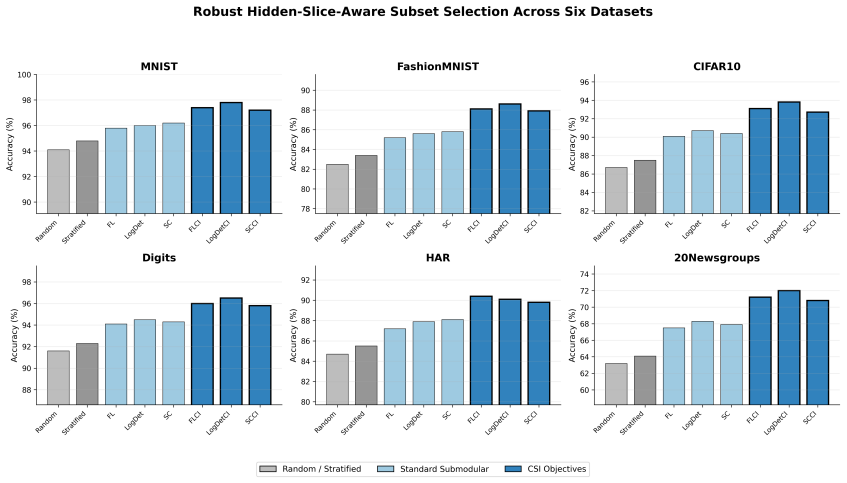
CSI objectives quantify shared structural information between a subset and its complement, inducing complement-aware variants of classical submodular functions that exhibit approximate monotonicity under bounded curvature conditions and achieve near-(1-1/e) greedy approximation guarantees, while empirically outperforming standard objectives by preserving coherent rare/tail semantic structure and suppressing noisy outliers.
What carries the argument
Complement Submodular Information (CSI), which quantifies shared structural information between a subset and its complement to produce balanced variants of submodular functions.
If this is right
- CSI objectives achieve near-(1-1/e) approximation guarantees for the greedy algorithm under bounded curvature conditions.
- They improve preservation of coherent rare/tail semantic structure compared with standard submodular objectives.
- They suppress noisy and isolated outliers more effectively during subset selection.
- This results in substantially improved downstream predictive performance on machine learning tasks.
- Different CSI instantiations capture complementary aspects of representativeness, diversity, connectivity, and balanced neighborhood preservation.
Where Pith is reading between the lines
- CSI could be applied to train/validation/test splitting to produce more representative machine learning benchmarks.
- The framework may extend to other combinatorial selection problems where balance with the unselected portion matters.
- Synthetic results suggest CSI could guide construction of new submodular functions matched to particular data distributions.
- Large-scale tests on additional real-world datasets would check whether the observed gains hold beyond the reported experiments.
Load-bearing premise
The quality of a selection depends critically on preserving balanced structure across both the selected subset and its complement.
What would settle it
A controlled hidden-slice-aware subset selection experiment in which CSI variants show no improvement over classical submodular objectives in tail-structure preservation or downstream accuracy.
Figures

read the original abstract
Submodular optimization has become a fundamental paradigm for data selection, retrieval, summarization, and representation learning due to its ability to model coverage, diversity, and representativeness. However, classical submodular objectives optimize only the selected subset and do not explicitly preserve structural information between the selected subset and the remaining data. In many modern machine learning applications, including train/validation/test splitting, benchmark construction, and robust subset selection, the quality of a selection depends critically on preserving balanced structure across both the selected subset and its complement. In this work, we introduce Complement Submodular Information (CSI), a new class of complement-aware submodular objectives that quantify shared structural information between a subset and its complement. Our framework induces complement-aware variants of several classical submodular functions including Facility Location, Graph Cut, LogDet, Saturated Coverage, Set Cover, Probabilistic Set Cover, and Feature Based Functions. We analyze the theoretical properties of CSI objectives and show that they exhibit approximate monotonicity under bounded curvature conditions, leading to near-$(1-1/e)$ greedy approximation guarantees. Empirically, CSI objectives consistently outperform standard submodular objectives on robust hidden-slice-aware subset selection. In particular, CSI objectives significantly improve preservation of coherent rare/tail semantic structure while simultaneously suppressing noisy and isolated outliers, leading to substantially improved downstream predictive performance. Synthetic experiments further illustrate how different CSI instantiations capture complementary notions of representativeness, diversity, connectivity, and balanced neighborhood preservation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Complement Submodular Information (CSI), a new class of complement-aware submodular objectives that extend classical functions (Facility Location, Graph Cut, LogDet, etc.) to quantify shared structural information between a subset and its complement. It claims these objectives exhibit approximate monotonicity under bounded curvature, yielding near-(1-1/e) greedy approximation guarantees, and empirically outperform standard submodular objectives on robust hidden-slice-aware subset selection by better preserving coherent rare/tail semantic structure while suppressing outliers, leading to improved downstream performance.
Significance. If the theoretical guarantees and empirical attributions hold, the framework addresses a genuine gap in submodular data selection by explicitly modeling complement structure, which is relevant for train/test splitting and robust subset selection. The extension to multiple classical functions and the synthetic experiments illustrating complementary notions of representativeness are strengths; reproducible code or parameter-free derivations would further strengthen it, but none are mentioned.
major comments (2)
- [Abstract / Experiments] Abstract and experiments section: the central empirical claim that CSI 'significantly improve[s] preservation of coherent rare/tail semantic structure while simultaneously suppressing noisy and isolated outliers' is load-bearing for attributing gains to the complement-aware property, yet no isolated quantitative metric (e.g., tail-class coverage ratio, coherence score, or outlier suppression statistic independent of accuracy/F1) is defined; downstream performance alone does not isolate the effect from hyperparameter or dataset confounds.
- [Theoretical analysis] Theoretical analysis section: the statement that CSI objectives 'exhibit approximate monotonicity under bounded curvature conditions, leading to near-(1-1/e) greedy approximation guarantees' requires explicit curvature bounds and the precise approximation factor derivation; without these details the guarantee cannot be verified as non-vacuous.
minor comments (2)
- [Framework definition] Notation for the CSI variants of the classical functions should be introduced with explicit formulas rather than descriptive lists to improve readability.
- [Abstract] The abstract mentions 'synthetic experiments further illustrate...' but does not reference specific figures or tables; cross-references would help.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below and will revise the manuscript accordingly to strengthen the presentation of both empirical and theoretical contributions.
read point-by-point responses
-
Referee: [Abstract / Experiments] Abstract and experiments section: the central empirical claim that CSI 'significantly improve[s] preservation of coherent rare/tail semantic structure while simultaneously suppressing noisy and isolated outliers' is load-bearing for attributing gains to the complement-aware property, yet no isolated quantitative metric (e.g., tail-class coverage ratio, coherence score, or outlier suppression statistic independent of accuracy/F1) is defined; downstream performance alone does not isolate the effect from hyperparameter or dataset confounds.
Authors: We agree that the current reliance on downstream performance metrics alone does not fully isolate the contribution of the complement-aware property from potential confounds. In the revised version we will define and report additional isolated metrics, including a tail-class coverage ratio and an outlier suppression statistic computed independently of accuracy or F1, and will update both the abstract and experiments section to present these results. revision: yes
-
Referee: [Theoretical analysis] Theoretical analysis section: the statement that CSI objectives 'exhibit approximate monotonicity under bounded curvature conditions, leading to near-(1-1/e) greedy approximation guarantees' requires explicit curvature bounds and the precise approximation factor derivation; without these details the guarantee cannot be verified as non-vacuous.
Authors: We acknowledge that explicit curvature bounds and the full derivation of the approximation factor are necessary for verifiability. The revised manuscript will expand the theoretical analysis section to state the precise curvature bounds for each CSI function and include the complete derivation showing how bounded curvature yields the near-(1-1/e) guarantee. revision: yes
Circularity Check
No circularity: CSI definitions and guarantees are independent of target results
full rationale
The paper defines CSI objectives explicitly as complement-aware variants of standard submodular functions (Facility Location, Graph Cut, etc.) and derives their monotonicity/approximation properties from the external bounded-curvature condition in classical submodular theory. No equations reduce a claimed prediction or uniqueness result to a fitted parameter or self-citation chain; empirical outperformance is measured on downstream tasks rather than by construction. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Submodular objectives exhibit approximate monotonicity under bounded curvature conditions
invented entities (1)
-
Complement Submodular Information (CSI)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Optical recognition of handwritten digits data set.UCI Machine Learning Repository, 1998
Ethem Alpaydin and Cevdet Kaynak. Optical recognition of handwritten digits data set.UCI Machine Learning Repository, 1998
1998
-
[2]
A public domain dataset for human activity recognition using smartphones.ESANN, 2013
Davide Anguita, Alessandro Ghio, Luca Oneto, Xavier Parra, and Jorge Reyes-Ortiz. A public domain dataset for human activity recognition using smartphones.ESANN, 2013
2013
-
[3]
arXiv preprint arXiv:2202.00132 , year =
Jeff Bilmes. Submodularity in machine learning and artificial intelligence.arXiv preprint arXiv:2202.00132, 2022
-
[4]
Submodular set functions, matroids and the greedy algorithm: tight worst-case bounds and some generalizations of the rado-edmonds theorem
Michele Conforti and Gérard Cornuéjols. Submodular set functions, matroids and the greedy algorithm: tight worst-case bounds and some generalizations of the rado-edmonds theorem. Discrete applied mathematics, 7(3):251–274, 1984
1984
-
[5]
The uncapicitated facility location problem
Gérard Cornuéjols, George Nemhauser, and Laurence Wolsey. The uncapicitated facility location problem. Technical report, Cornell University Operations Research and Industrial Engineering, 1983
1983
-
[6]
A threshold of ln n for approximating set cover.Journal of the ACM (JACM), 45 (4):634–652, 1998
Uriel Feige. A threshold of ln n for approximating set cover.Journal of the ACM (JACM), 45 (4):634–652, 1998
1998
-
[7]
Elsevier, 2005
Satoru Fujishige.Submodular functions and optimization. Elsevier, 2005. 12
2005
-
[8]
Deep residual learning for image recognition
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 770–778, 2016
2016
-
[9]
Polyhedral aspects of Submodularity, Convexity and Concavity
Rishabh Iyer and Jeff Bilmes. Polyhedral aspects of submodularity, convexity and concavity. arXiv preprint arXiv:1506.07329, 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[10]
A memoization framework for scaling submodular optimization to large scale problems
Rishabh Iyer and Jeffrey Bilmes. A memoization framework for scaling submodular optimization to large scale problems. InThe 22nd International Conference on Artificial Intelligence and Statistics, pages 2340–2349. PMLR, 2019
2019
-
[11]
Submodular combina- torial information measures with applications in machine learning
Rishabh Iyer, Ninad Khargoankar, Jeff Bilmes, and Himanshu Asanani. Submodular combina- torial information measures with applications in machine learning. InAlgorithmic Learning Theory, pages 722–754. PMLR, 2021
2021
-
[12]
Rishabh Iyer, Ninad Khargonkar, Jeff Bilmes, and Himanshu Asnani. Generalized submod- ular information measures: Theoretical properties, examples, optimization algorithms, and applications.IEEE Transactions on Information Theory, 68(2):752–781, 2021
2021
-
[13]
Curvature and optimal algorithms for learning and minimizing submodular functions.Advances in neural information processing systems, 26, 2013
Rishabh K Iyer, Stefanie Jegelka, and Jeff A Bilmes. Curvature and optimal algorithms for learning and minimizing submodular functions.Advances in neural information processing systems, 26, 2013
2013
-
[14]
PhD thesis, 2015
Rishabh Krishnan Iyer.Submodular optimization and machine learning: Theoretical results, unifying and scalable algorithms, and applications. PhD thesis, 2015
2015
-
[15]
Orient: Submod- ular mutual information measures for data subset selection under distribution shift.Advances in neural information processing systems, 35:31796–31808, 2022
Athresh Karanam, Krishnateja Killamsetty, Harsha Kokel, and Rishabh Iyer. Orient: Submod- ular mutual information measures for data subset selection under distribution shift.Advances in neural information processing systems, 35:31796–31808, 2022
2022
-
[16]
Similar: Sub- modular information measures based active learning in realistic scenarios.Advances in Neural Information Processing Systems, 34:18685–18697, 2021
Suraj Kothawade, Nathan Beck, Krishnateja Killamsetty, and Rishabh Iyer. Similar: Sub- modular information measures based active learning in realistic scenarios.Advances in Neural Information Processing Systems, 34:18685–18697, 2021
2021
-
[17]
Suraj Kothawade, Shivang Chopra, Saikat Ghosh, and Rishabh Iyer. Active data discovery: Miningunknowndatausingsubmodularinformationmeasures.arXiv preprint arXiv:2206.08566, 2022
-
[18]
Talisman: targeted active learning for object detection with rare classes and slices using submodular mutual information
Suraj Kothawade, Saikat Ghosh, Sumit Shekhar, Yu Xiang, and Rishabh Iyer. Talisman: targeted active learning for object detection with rare classes and slices using submodular mutual information. InEuropean Conference on Computer Vision, pages 1–16. Springer, 2022
2022
-
[19]
Submodular function maximization.Tractability, 2014
Andreas Krause and Daniel Golovin. Submodular function maximization.Tractability, 2014
2014
-
[20]
Near-optimal sensor placements in gaussian processes: Theory, efficient algorithms and empirical studies.Journal of Machine Learning Research, 9(2):235–284, 2008
Andreas Krause, Ajit Singh, and Carlos Guestrin. Near-optimal sensor placements in gaussian processes: Theory, efficient algorithms and empirical studies.Journal of Machine Learning Research, 9(2):235–284, 2008
2008
-
[21]
Learning multiple layers of features from tiny images
Alex Krizhevsky. Learning multiple layers of features from tiny images. Technical report, University of Toronto, 2009
2009
-
[22]
Determinantal point processes for machine learning.Foundations and Trends®in Machine Learning, 5(2-3):123–286, 2012
Alex Kulesza and Ben Taskar. Determinantal point processes for machine learning.Foundations and Trends®in Machine Learning, 5(2-3):123–286, 2012. 13
2012
-
[23]
Newsweeder: Learning to filter netnews.Machine Learning Proceedings, pages 331–339, 1995
Ken Lang. Newsweeder: Learning to filter netnews.Machine Learning Proceedings, pages 331–339, 1995
1995
-
[24]
Gradient-based learning applied to document recognition.Proceedings of the IEEE, 86(11):2278–2324, 1998
Yann LeCun, Léon Bottou, Yoshua Bengio, and Patrick Haffner. Gradient-based learning applied to document recognition.Proceedings of the IEEE, 86(11):2278–2324, 1998
1998
-
[25]
Multi-document summarization via budgeted maximization of submodular functions
Hui Lin and Jeff Bilmes. Multi-document summarization via budgeted maximization of submodular functions. InHuman Language Technologies: The 2010 Annual conference of the North American chapter of the association for computational linguistics, pages 912–920, 2010
2010
-
[26]
Accelerated greedy algorithms for maximizing submodular set functions
Michel Minoux. Accelerated greedy algorithms for maximizing submodular set functions. In Optimization Techniques: Proceedings of the 8th IFIP Conference on Optimization Techniques Würzburg, September 5–9, 1978, pages 234–243. Springer, 1978
1978
-
[27]
An analysis of approximations for maximizing submodular set functions—i.Mathematical programming, 14:265–294, 1978
George L Nemhauser, Laurence A Wolsey, and Marshall L Fisher. An analysis of approximations for maximizing submodular set functions—i.Mathematical programming, 14:265–294, 1978
1978
-
[28]
Minimizing symmetric submodular functions.Mathematical programming, 82(1):3–12, 1998
Maurice Queyranne. Minimizing symmetric submodular functions.Mathematical programming, 82(1):3–12, 1998
1998
-
[29]
Learning representations by back-propagating errors.Nature, 323(6088):533–536, 1986
David E Rumelhart, Geoffrey E Hinton, and Ronald J Williams. Learning representations by back-propagating errors.Nature, 323(6088):533–536, 1986
1986
-
[30]
Term-weighting approaches in automatic text retrieval
Gerard Salton and Christopher Buckley. Term-weighting approaches in automatic text retrieval. Information Processing & Management, 24(5):513–523, 1988
1988
-
[31]
Submodular Benchmark Selection
Alexander Smola. Submodular benchmark selection.arXiv preprint arXiv:2605.02209, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[32]
Unsupervised submodular subset selection for speech data
Kai Wei, Yuzong Liu, Katrin Kirchhoff, and Jeff Bilmes. Unsupervised submodular subset selection for speech data. In2014 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 4107–4111. IEEE, 2014
2014
-
[33]
Fashion-MNIST: a Novel Image Dataset for Benchmarking Machine Learning Algorithms
Han Xiao, Kashif Rasul, and Roland Vollgraf. Fashion-mnist: a novel image dataset for benchmarking machine learning algorithms.arXiv preprint arXiv:1708.07747, 2017. 14 A Appendix A: Additional Proofs Due to space limitations, we provide additional proofs and derivations omitted from the main paper. A.1 Proof of Symmetry Proposition 3.For any normalized m...
work page internal anchor Pith review Pith/arXiv arXiv 2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.