Recognition: no theorem link
3AM: 3egment Anything with Geometric Consistency in Videos
Pith reviewed 2026-05-16 14:16 UTC · model grok-4.3
The pith
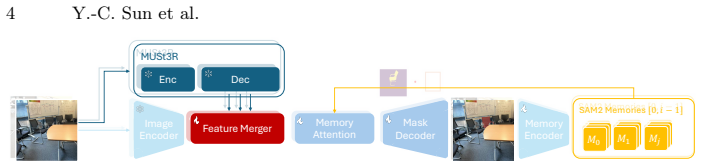
3AM integrates 3D-aware features from MUSt3R into SAM2 to achieve geometry-consistent video object segmentation from RGB alone.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By fusing MUSt3R multi-level features into SAM2 through a Feature Merger, 3AM produces geometry-consistent segmentation in videos grounded in both spatial position and visual similarity, outperforming prior VOS methods by large margins on datasets with wide-baseline motion while requiring no camera poses or depth at test time.
What carries the argument
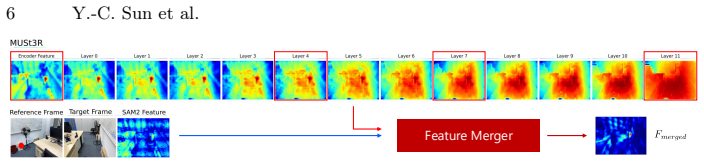
The Feature Merger fuses multi-level MUSt3R features encoding implicit geometric correspondence with SAM2 appearance features to enable consistent recognition.
If this is right
- Video object segmentation becomes robust to large viewpoint changes without explicit 3D inputs at inference.
- Tracking recall improves by over 30 points on selected challenging subsets such as ScanNet++.
- The approach eliminates the need for camera pose estimation or depth preprocessing.
- Geometry-consistent recognition holds across frames observing spatially consistent object regions.
Where Pith is reading between the lines
- This fusion strategy could extend to other memory-based video models that currently rely only on appearance.
- Implicit geometry from multi-view features may help in dynamic scenes where explicit reconstruction is unreliable.
- Real-time robotics applications could benefit from the RGB-only inference requirement.
Load-bearing premise
Multi-level features from MUSt3R reliably encode implicit geometric correspondence that fuses effectively with appearance features to maintain consistency without any 3D data at inference.
What would settle it
If removing the MUSt3R features causes 3AM performance to fall to SAM2 levels on wide-baseline datasets like ScanNet++, the contribution of the geometric fusion would be disproven.
Figures














read the original abstract
Video object segmentation methods like SAM2 achieve strong performance through memory-based architectures but struggle under large viewpoint changes due to reliance on appearance features. Traditional 3D instance segmentation methods address viewpoint consistency but require camera poses, depth maps, and expensive preprocessing. We introduce 3AM, a training-time enhancement that integrates 3D-aware features from MUSt3R into SAM2. Our lightweight Feature Merger fuses multi-level MUSt3R features that encode implicit geometric correspondence. Combined with SAM2's appearance features, the model achieves geometry-consistent recognition grounded in both spatial position and visual similarity. We propose a field-of-view aware sampling strategy ensuring frames observe spatially consistent object regions for reliable 3D correspondence learning. Critically, our method requires only RGB input at inference, with no camera poses or preprocessing. On challenging datasets with wide-baseline motion (ScanNet++, Replica), 3AM substantially outperforms SAM2 and extensions, achieving 90.6% IoU and 71.7% Tracking Recall on ScanNet++'s Selected Subset, improving over state-of-the-art VOS methods by +15.9 and +30.4 points. Project page: https://jayisaking.github.io/3AM-Page/
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents 3AM, a training-time enhancement to SAM2 for video object segmentation that fuses multi-level features from the pretrained MUSt3R model via a lightweight Feature Merger to inject implicit geometric correspondence. It employs a field-of-view aware sampling strategy during training and claims to deliver geometry-consistent recognition using only RGB input at inference, with no camera poses or depth required. On wide-baseline datasets such as ScanNet++ and Replica, the method reports 90.6% IoU and 71.7% Tracking Recall on ScanNet++'s Selected Subset, outperforming SAM2 and state-of-the-art VOS methods by +15.9 and +30.4 points respectively.
Significance. If the performance gains are shown to arise specifically from the geometric fusion rather than extraneous factors, the work would meaningfully advance video object segmentation by offering a practical route to viewpoint-consistent tracking without explicit 3D inputs at test time. This could benefit applications requiring robust segmentation under large motions, such as robotics and augmented reality.
major comments (3)
- [Method] Method section: The Feature Merger is introduced only at a conceptual level with no equations, pseudocode, or architectural specifications detailing how MUSt3R multi-level features are combined with SAM2 appearance features; this leaves the central fusion mechanism unverifiable.
- [Experiments] Experiments section: No ablation studies isolate the contribution of MUSt3R features (e.g., replacing them with appearance-matched controls or ablating the merger); without such controls, the headline gains of +15.9 IoU and +30.4 Tracking Recall cannot be attributed to geometric consistency rather than added capacity or training schedule differences.
- [Results] Results section: The reported metrics on ScanNet++ Selected Subset and Replica lack implementation details for the SAM2 baselines and extensions, exact evaluation protocols, multiple-run statistics, or error analysis, undermining assessment of whether the data support the central performance claim.
minor comments (2)
- [Title] Title: '3egment' appears to be a typographical error and should read 'Segment'.
- [Abstract] Abstract: The acronym 3AM is not expanded, and the description of the field-of-view aware sampling is too brief to convey its role in enabling reliable 3D correspondence learning.
Simulated Author's Rebuttal
We appreciate the referee's detailed feedback on our manuscript. We address each of the major comments below and commit to making the necessary revisions to strengthen the paper.
read point-by-point responses
-
Referee: [Method] Method section: The Feature Merger is introduced only at a conceptual level with no equations, pseudocode, or architectural specifications detailing how MUSt3R multi-level features are combined with SAM2 appearance features; this leaves the central fusion mechanism unverifiable.
Authors: We agree with this observation. The current manuscript describes the Feature Merger at a high level to maintain focus on the overall approach. In the revised version, we will expand the Method section to include the mathematical formulation of the fusion process, a detailed architecture diagram specifying input/output dimensions for each layer, and pseudocode outlining the step-by-step combination of MUSt3R multi-level features with SAM2's appearance features. This will make the central mechanism fully verifiable and reproducible. revision: yes
-
Referee: [Experiments] Experiments section: No ablation studies isolate the contribution of MUSt3R features (e.g., replacing them with appearance-matched controls or ablating the merger); without such controls, the headline gains of +15.9 IoU and +30.4 Tracking Recall cannot be attributed to geometric consistency rather than added capacity or training schedule differences.
Authors: This is a valid point. While the manuscript emphasizes the geometric consistency through the integration of MUSt3R features, we did not include explicit ablations in the initial submission. We will add comprehensive ablation studies in the revised manuscript, including: (1) a control where MUSt3R features are replaced with appearance-matched but geometrically uninformative features, (2) an ablation removing the Feature Merger entirely, and (3) comparisons with increased capacity in the baseline SAM2. These will help attribute the performance gains specifically to the geometric fusion. revision: yes
-
Referee: [Results] Results section: The reported metrics on ScanNet++ Selected Subset and Replica lack implementation details for the SAM2 baselines and extensions, exact evaluation protocols, multiple-run statistics, or error analysis, undermining assessment of whether the data support the central performance claim.
Authors: We acknowledge the need for greater transparency in the results. In the revision, we will include: detailed implementation specifications for the SAM2 baselines (including any modifications made), the precise definition and selection criteria for the ScanNet++ Selected Subset, the full evaluation protocol (e.g., frame sampling, IoU computation details), statistics from multiple runs with standard deviations where applicable, and an error analysis discussing failure cases and their relation to viewpoint changes. This will provide stronger support for the reported performance claims. revision: yes
Circularity Check
No circularity: core claims rest on external pretrained models and empirical results
full rationale
The paper presents 3AM as a training-time fusion of features from two independently pretrained external models (SAM2 and MUSt3R) into a lightweight merger module. No equations, parameters, or predictions are shown to be fitted to the target metrics and then re-reported as outputs. The field-of-view aware sampling is described strictly as a data curation step for training, not as a derived prediction. No self-citations appear as load-bearing justifications for uniqueness or geometric correspondence; the performance numbers (IoU, Tracking Recall) are reported against external benchmarks without reduction to quantities defined inside the paper. The derivation chain therefore remains self-contained against external references and does not collapse by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption MUSt3R features encode implicit geometric correspondence usable for video object segmentation
invented entities (1)
-
Feature Merger
no independent evidence
Reference graph
Works this paper leans on
-
[1]
In: European Confer- ence on Computer Vision
Avetisyan, A., Xie, C., Howard-Jenkins, H., Yang, T.Y., Aroudj, S., Patra, S., Zhang, F., Frost, D., Holland, L., Orme, C., et al.: Scenescript: Reconstructing scenes with an autoregressive structured language model. In: European Confer- ence on Computer Vision. pp. 247–263. Springer (2024)
work page 2024
-
[2]
Advances in Neural Information Processing Systems37, 6833–6859 (2024)
Bai, Z., He, T., Mei, H., Wang, P., Gao, Z., Chen, J., Zhang, Z., Shou, M.Z.: One token to seg them all: Language instructed reasoning segmentation in videos. Advances in Neural Information Processing Systems37, 6833–6859 (2024)
work page 2024
-
[3]
Advances in Neural Information Processing Systems35, 25102– 25116 (2022)
Bautista, M.A., Guo, P., Abnar, S., Talbott, W., Toshev, A., Chen, Z., Dinh, L., Zhai, S., Goh, H., Ulbricht, D., et al.: Gaudi: A neural architect for immersive 3d scene generation. Advances in Neural Information Processing Systems35, 25102– 25116 (2022)
work page 2022
-
[4]
In: European Conference on Computer Vision
Bhat, G., Lawin, F.J., Danelljan, M., Robinson, A., Felsberg, M., Van Gool, L., Timofte, R.: Learning what to learn for video object segmentation. In: European Conference on Computer Vision. pp. 777–794. Springer (2020)
work page 2020
-
[5]
Boudjoghra, M.E.A., Dai, A., Lahoud, J., Cholakkal, H., Anwer, R.M., Khan, S., Khan,F.S.:Open-yolo3d:Towardsfastandaccurateopen-vocabulary3dinstance segmentation. arXiv preprint arXiv:2406.02548 (2024)
-
[6]
In: The Thirteenth International Conference on Learning Representations (2025)
Boudjoghra, M.E.A., Dai, A., Lahoud, J., Cholakkal, H., Anwer, R.M., Khan, S., Khan, F.S.: Open-YOLO 3d: Towards fast and accurate open-vocabulary 3d instance segmentation. In: The Thirteenth International Conference on Learning Representations (2025)
work page 2025
-
[7]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Cabon, Y., Stoffl, L., Antsfeld, L., Csurka, G., Chidlovskii, B., Revaud, J., Leroy, V.: Must3r: Multi-view network for stereo 3d reconstruction. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 1050–1060 (2025)
work page 2025
-
[8]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
Caelles, S., Maninis, K.K., Pont-Tuset, J., Leal-Taixé, L., Cremers, D., Van Gool, L.: One-shot video object segmentation. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 221–230 (2017) 16 Y.-C. Sun et al
work page 2017
-
[9]
In: Proceed- ings of the IEEE/CVF conference on computer vision and pattern recognition
Charatan, D., Li, S.L., Tagliasacchi, A., Sitzmann, V.: pixelsplat: 3d gaussian splats from image pairs for scalable generalizable 3d reconstruction. In: Proceed- ings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 19457–19467 (2024)
work page 2024
-
[10]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Chen, X., Chen, Y., Xiu, Y., Geiger, A., Chen, A.: Easi3r: Estimating disen- tangled motion from dust3r without training. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 9158–9168 (2025)
work page 2025
-
[11]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Chen, Z., Qin, M., Yuan, T., Liu, Z., Zhao, H.: Long3r: Long sequence streaming 3d reconstruction. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 5273–5284 (2025)
work page 2025
-
[12]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Cheng, H.K., Oh, S.W., Price, B., Lee, J.Y., Schwing, A.: Putting the object back into video object segmentation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 3151–3161 (2024)
work page 2024
-
[13]
In: European conference on computer vision
Cheng, H.K., Schwing, A.G.: Xmem: Long-term video object segmentation with an atkinson-shiffrin memory model. In: European conference on computer vision. pp. 640–658. Springer (2022)
work page 2022
-
[14]
Advances in neu- ral information processing systems34, 11781–11794 (2021)
Cheng, H.K., Tai, Y.W., Tang, C.K.: Rethinking space-time networks with im- proved memory coverage for efficient video object segmentation. Advances in neu- ral information processing systems34, 11781–11794 (2021)
work page 2021
-
[15]
In: Proceedings of the Com- puter Vision and Pattern Recognition Conference
Cuttano, C., Trivigno, G., Rosi, G., Masone, C., Averta, G.: Samwise: Infusing wisdom in sam2 for text-driven video segmentation. In: Proceedings of the Com- puter Vision and Pattern Recognition Conference. pp. 3395–3405 (2025)
work page 2025
-
[16]
Ding, H., Liu, C., He, S., Jiang, X., Torr, P.H., Bai, S.: MOSE: A new dataset for video object segmentation in complex scenes. In: ICCV (2023)
work page 2023
-
[17]
arXiv preprint arXiv:2508.05630 (2025)
Ding, H., Ying, K., Liu, C., He, S., Jiang, X., Jiang, Y.G., Torr, P.H., Bai, S.: Mosev2: A more challenging dataset for video object segmentation in complex scenes. arXiv preprint arXiv:2508.05630 (2025)
-
[18]
Ding,S.,Qian,R.,Dong,X.,Zhang,P.,Zang,Y.,Cao,Y.,Guo,Y.,Lin,D.,Wang, J.: Sam2long: Enhancing sam 2 for long video segmentation with a training-free memory tree. arXiv preprint arXiv:2410.16268 (2024)
-
[19]
In: 2025 International Conference on 3D Vision (3DV)
Duisterhof, B.P., Zust, L., Weinzaepfel, P., Leroy, V., Cabon, Y., Revaud, J.: Mast3r-sfm: a fully-integrated solution for unconstrained structure-from-motion. In: 2025 International Conference on 3D Vision (3DV). pp. 1–10. IEEE (2025)
work page 2025
-
[20]
arXiv preprint arXiv:2404.03650 (2024)
Engelmann, F., Manhardt, F., Niemeyer, M., Tateno, K., Pollefeys, M., Tombari, F.: Opennerf: Open set 3d neural scene segmentation with pixel-wise features and rendered novel views. arXiv preprint arXiv:2404.03650 (2024)
-
[21]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Fan, C.D., Chang, C.W., Liu, Y.R., Lee, J.Y., Huang, J.L., Tseng, Y.C., Liu, Y.L.: Spectromotion: Dynamic 3d reconstruction of specular scenes. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 21328–21338 (2025)
work page 2025
-
[22]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Fan, H., Lin, L., Yang, F., Chu, P., Deng, G., Yu, S., Bai, H., Xu, Y., Liao, C., Ling, H.: Lasot: A high-quality benchmark for large-scale single object tracking. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 5374–5383 (2019)
work page 2019
-
[23]
Advances in neural information processing systems37, 40212–40229 (2024)
Fan, Z., Zhang, J., Cong, W., Wang, P., Li, R., Wen, K., Zhou, S., Kadambi, A., Wang, Z., Xu, D., et al.: Large spatial model: End-to-end unposed images to semantic 3d. Advances in neural information processing systems37, 40212–40229 (2024)
work page 2024
-
[24]
In: European conference on computer vision
Gu, Q., Lv, Z., Frost, D., Green, S., Straub, J., Sweeney, C.: Egolifter: Open-world 3d segmentation for egocentric perception. In: European conference on computer vision. pp. 382–400. Springer (2024) 3AM 17
work page 2024
-
[25]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Han, L., Zheng, T., Xu, L., Fang, L.: Occuseg: Occupancy-aware 3d instance segmentation. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 2940–2949 (2020)
work page 2020
-
[26]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Hong, L., Chen, W., Liu, Z., Zhang, W., Guo, P., Chen, Z., Zhang, W.: Lvos: A benchmark for long-term video object segmentation. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 13480–13492 (2023)
work page 2023
-
[27]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Hsu, P.H., Zhang, K., Wang, F.E., Tu, T., Li, M.F., Liu, Y.L., Chen, A.Y., Sun, M., Kuo, C.H.: Openm3d: Open vocabulary multi-view indoor 3d object detec- tion without human annotations. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 8688–8698 (2025)
work page 2025
-
[28]
In: Proceedings of the Computer Vision and Pattern Recognition Conference (CVPR)
Huang, N., Zheng, W., Xu, C., Keutzer, K., Zhang, S., Kanazawa, A., Wang, Q.: Segment any motion in videos. In: Proceedings of the Computer Vision and Pattern Recognition Conference (CVPR). pp. 3406–3416 (June 2025)
work page 2025
-
[29]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Jain, A., Katara, P., Gkanatsios, N., Harley, A.W., Sarch, G., Aggarwal, K., Chaudhary, V., Fragkiadaki, K.: Odin: A single model for 2d and 3d segmentation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 3564–3574 (2024)
work page 2024
-
[30]
cc/virtual/2025/loc/san-diego/poster/119228
Jayanti,R.,Agrawal,S.,Garg,V.,Tourani,S.,Khan,M.H.,Garg,S.,Krishna,M.: Segmast3r: Geometry grounded segment matching38(2025),https://neurips. cc/virtual/2025/loc/san-diego/poster/119228
work page 2025
-
[31]
In: European Conference on Computer Vision
Jia, B., Chen, Y., Yu, H., Wang, Y., Niu, X., Liu, T., Li, Q., Huang, S.: Scen- everse: Scaling 3d vision-language learning for grounded scene understanding. In: European Conference on Computer Vision. pp. 289–310. Springer (2024)
work page 2024
-
[32]
In: Proceedings of the IEEE/CVF Conference on Com- puter Vision and Pattern Recognition
Jiang, H., Liu, L., Cheng, T., Wang, X., Lin, T., Su, Z., Liu, W., Wang, X.: Gausstr: Foundation model-aligned gaussian transformer for self-supervised 3d spatial understanding. In: Proceedings of the IEEE/CVF Conference on Com- puter Vision and Pattern Recognition. pp. 11960–11970 (2025)
work page 2025
-
[33]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Jiang, L., Shi, S., Schiele, B.: Open-vocabulary 3d semantic segmentation with foundation models. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 21284–21294 (2024)
work page 2024
-
[34]
In: Proceedings of the IEEE/CVF confer- ence on computer vision and Pattern recognition
Jiang, L., Zhao, H., Shi, S., Liu, S., Fu, C.W., Jia, J.: Pointgroup: Dual-set point grouping for 3d instance segmentation. In: Proceedings of the IEEE/CVF confer- ence on computer vision and Pattern recognition. pp. 4867–4876 (2020)
work page 2020
-
[35]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Jung, S., Zheng, J., Zhang, K., Qiao, N., Chen, A.Y., Xia, L., Liu, C., Sun, Y., Zeng, X., Huang, H.W., et al.: Details matter for indoor open-vocabulary 3d in- stance segmentation. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 9627–9637 (2025)
work page 2025
-
[36]
In: Proceedings of the IEEE/CVF international con- ference on computer vision
Kerr, J., Kim, C.M., Goldberg, K., Kanazawa, A., Tancik, M.: Lerf: Language embedded radiance fields. In: Proceedings of the IEEE/CVF international con- ference on computer vision. pp. 19729–19739 (2023)
work page 2023
-
[37]
In: Proceedings of the IEEE/CVF Confer- ence on Computer Vision and Pattern Recognition
Kim, C.M., Wu, M., Kerr, J., Goldberg, K., Tancik, M., Kanazawa, A.: Garfield: Group anything with radiance fields. In: Proceedings of the IEEE/CVF Confer- ence on Computer Vision and Pattern Recognition. pp. 21530–21539 (2024)
work page 2024
-
[38]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Kolodiazhnyi, M., Vorontsova, A., Konushin, A., Rukhovich, D.: Oneformer3d: One transformer for unified point cloud segmentation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 20943– 20953 (2024)
work page 2024
-
[39]
In: European Conference on Computer Vision
Leroy, V., Cabon, Y., Revaud, J.: Grounding image matching in 3d with mast3r. In: European Conference on Computer Vision. pp. 71–91. Springer (2024) 18 Y.-C. Sun et al
work page 2024
-
[40]
arXiv preprint arXiv:2509.23541 (2025)
Li, H., Qu, J., Zhang, L.: Ovseg3r: Learn open-vocabulary instance segmentation from 2d via 3d reconstruction. arXiv preprint arXiv:2509.23541 (2025)
-
[41]
In: European Conference on Computer Vision
Li, M.F., Ku, Y.F., Yen, H.X., Liu, C., Liu, Y.L., Chen, A.Y., Kuo, C.H., Sun, M.: Genrc: Generative 3d room completion from sparse image collections. In: European Conference on Computer Vision. pp. 146–163. Springer (2024)
work page 2024
-
[42]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Li, M., Li, S., Zhang, X., Zhang, L.: Univs: Unified and universal video segmen- tation with prompts as queries. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 3227–3238 (2024)
work page 2024
-
[43]
In: European Conference on Computer Vision
Li, W., Guo, P., Zhou, X., Hong, L., He, Y., Zheng, X., Zhang, W., Zhang, W.: Onevos: unifying video object segmentation with all-in-one transformer frame- work. In: European Conference on Computer Vision. pp. 20–40. Springer (2024)
work page 2024
-
[44]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Lin, C.Y., Sun, C., Yang, F.E., Chen, M.H., Lin, Y.Y., Liu, Y.L.: Longsplat: Robust unposed 3d gaussian splatting for casual long videos. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 27412–27422 (2025)
work page 2025
-
[45]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
Lin, T.Y., Dollár, P., Girshick, R., He, K., Hariharan, B., Belongie, S.: Feature pyramid networks for object detection. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 2117–2125 (2017)
work page 2017
-
[46]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Liu, Q., Wang, J., Yang, Z., Li, L., Lin, K., Niethammer, M., Wang, L.: Livos: Light video object segmentation with gated linear matching. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 8668–8678 (2025)
work page 2025
-
[47]
In: European Conference on Computer Vision
Liu, Y., Yu, R., Yin, F., Zhao, X., Zhao, W., Xia, W., Yang, Y.: Learning quality- aware dynamic memory for video object segmentation. In: European Conference on Computer Vision. pp. 468–486. Springer (2022)
work page 2022
-
[48]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Liu, Y.L., Gao, C., Meuleman, A., Tseng, H.Y., Saraf, A., Kim, C., Chuang, Y.Y., Kopf, J., Huang, J.B.: Robust dynamic radiance fields. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 13–23 (2023)
work page 2023
-
[49]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Mahadevan, S., Zulfikar, I.E., Voigtlaender, P., Leibe, B.: Point-vos: Pointing up video object segmentation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 22217–22226 (2024)
work page 2024
-
[50]
Advances in Neural Information Processing Systems37, 76819–76847 (2024)
Man, Y., Zheng, S., Bao, Z., Hebert, M., Gui, L., Wang, Y.X.: Lexicon3d: Probing visual foundation models for complex 3d scene understanding. Advances in Neural Information Processing Systems37, 76819–76847 (2024)
work page 2024
-
[51]
IEEE transactions on pattern analysis and machine intelligence41(6), 1515–1530 (2018)
Maninis, K.K., Caelles, S., Chen, Y., Pont-Tuset, J., Leal-Taixé, L., Cremers, D., Van Gool, L.: Video object segmentation without temporal information. IEEE transactions on pattern analysis and machine intelligence41(6), 1515–1530 (2018)
work page 2018
-
[52]
Misra, I., Girdhar, R., Joulin, A.: An end-to-end transformer model for 3d object detection.In:ProceedingsoftheIEEE/CVFinternationalconferenceoncomputer vision. pp. 2906–2917 (2021)
work page 2021
-
[53]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Murai, R., Dexheimer, E., Davison, A.J.: Mast3r-slam: Real-time dense slam with 3d reconstruction priors. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 16695–16705 (2025)
work page 2025
-
[54]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Nguyen, P., Ngo, T.D., Kalogerakis, E., Gan, C., Tran, A., Pham, C., Nguyen, K.: Open3dis: Open-vocabulary 3d instance segmentation with 2d mask guidance. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 4018–4028 (2024)
work page 2024
-
[55]
In: Proceedings of the IEEE/CVF international confer- ence on computer vision
Oh, S.W., Lee, J.Y., Xu, N., Kim, S.J.: Video object segmentation using space- time memory networks. In: Proceedings of the IEEE/CVF international confer- ence on computer vision. pp. 9226–9235 (2019) 3AM 19
work page 2019
-
[56]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Park, K., Woo, S., Oh, S.W., Kweon, I.S., Lee, J.Y.: Per-clip video object seg- mentation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 1352–1361 (2022)
work page 2022
-
[57]
arXiv preprint arXiv:2410.07577 (2024)
Peng, Q., Planche, B., Gao, Z., Zheng, M., Choudhuri, A., Chen, T., Chen, C., Wu, Z.: 3d vision-language gaussian splatting. arXiv preprint arXiv:2410.07577 (2024)
-
[58]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Peng, S., Genova, K., Jiang, C., Tagliasacchi, A., Pollefeys, M., Funkhouser, T., et al.: Openscene: 3d scene understanding with open vocabularies. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 815–824 (2023)
work page 2023
-
[59]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
Perazzi, F., Pont-Tuset, J., McWilliams, B., Van Gool, L., Gross, M., Sorkine- Hornung, A.: A benchmark dataset and evaluation methodology for video object segmentation. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 724–732 (2016)
work page 2016
-
[60]
Piekenbrinck, J., Schmidt, C., Hermans, A., Vaskevicius, N., Linder, T., Leibe, B.:Opensplat3d:Open-vocabulary3dinstancesegmentationusinggaussiansplat- ting.In:ProceedingsoftheComputerVisionandPatternRecognitionConference. pp. 5246–5255 (2025)
work page 2025
-
[61]
The 2017 DAVIS Challenge on Video Object Segmentation
Pont-Tuset, J., Perazzi, F., Caelles, S., Arbeláez, P., Sorkine-Hornung, A., Van Gool, L.: The 2017 davis challenge on video object segmentation. arXiv:1704.00675 (2017)
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[62]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Qin, M., Li, W., Zhou, J., Wang, H., Pfister, H.: Langsplat: 3d language gaussian splatting. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 20051–20060 (2024)
work page 2024
-
[63]
SAM 2: Segment Anything in Images and Videos
Ravi, N., Gabeur, V., Hu, Y.T., Hu, R., Ryali, C., Ma, T., Khedr, H., Rädle, R., Rolland, C., Gustafson, L., Mintun, E., Pan, J., Alwala, K.V., Carion, N., Wu, C.Y., Girshick, R., Dollár, P., Feichtenhofer, C.: Sam 2: Segment anything in images and videos. arXiv preprint arXiv:2408.00714 (2024),https://arxiv. org/abs/2408.00714
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[64]
Ryali, C., Hu, Y.T., Bolya, D., Wei, C., Fan, H., Huang, P.Y., Aggarwal, V., Chowdhury, A., Poursaeed, O., Hoffman, J., Malik, J., Li, Y., Feichtenhofer, C.: Hiera: A hierarchical vision transformer without the bells-and-whistles. ICML (2023)
work page 2023
-
[65]
Schult, J., Engelmann, F., Hermans, A., Litany, O., Tang, S., Leibe, B.: Mask3d: Mask transformer for 3d semantic instance segmentation. arXiv preprint arXiv:2210.03105 (2022)
-
[66]
In: European Conference on Computer Vision
Shen, Q., Yang, X., Wang, X.: Flashsplat: 2d to 3d gaussian splatting segmenta- tion solved optimally. In: European Conference on Computer Vision. pp. 456–472. Springer (2024)
work page 2024
-
[67]
In: Proceedings of the SIGGRAPH Asia 2025 Conference Papers
Shih, M.L., Chen, Y.H., Liu, Y.L., Curless, B.: Prior-enhanced gaussian splat- ting for dynamic scene reconstruction from casual video. In: Proceedings of the SIGGRAPH Asia 2025 Conference Papers. pp. 1–13 (2025)
work page 2025
-
[68]
Splatt3R: Zero-shot Gaussian Splatting from Uncalibrated Image Pairs
Smart, B., Zheng, C., Laina, I., Prisacariu, V.A.: Splatt3r: Zero-shot gaussian splatting from uncalibrated image pairs. arXiv preprint arXiv:2408.13912 (2024)
work page internal anchor Pith review arXiv 2024
-
[69]
The Replica Dataset: A Digital Replica of Indoor Spaces
Straub, J., Whelan, T., Ma, L., Chen, Y., Wijmans, E., Green, S., Engel, J.J., Mur-Artal, R., Ren, C., Verma, S., Clarkson, A., Yan, M., Budge, B., Yan, Y., Pan, X., Yon, J., Zou, Y., Leon, K., Carter, N., Briales, J., Gillingham, T., Mueg- gler, E., Pesqueira, L., Savva, M., Batra, D., Strasdat, H.M., Nardi, R.D., Goesele, M., Lovegrove, S., Newcombe, R....
work page internal anchor Pith review Pith/arXiv arXiv 1906
-
[70]
In: ACM SIGGRAPH 2024 Conference Papers
Su, C.H., Hu, C.Y., Tsai, S.R., Lee, J.Y., Lin, C.Y., Liu, Y.L.: Boostmvsnerfs: Boosting mvs-based nerfs to generalizable view synthesis in large-scale scenes. In: ACM SIGGRAPH 2024 Conference Papers. pp. 1–12 (2024)
work page 2024
-
[71]
In: Proceedings of the AAAI Conference on Artificial Intelligence
Sun, J., Qing, C., Tan, J., Xu, X.: Superpoint transformer for 3d scene instance segmentation. In: Proceedings of the AAAI Conference on Artificial Intelligence. vol. 37, pp. 2393–2401 (2023)
work page 2023
-
[72]
Sun, X., Jiang, H., Liu, L., Nam, S., Kang, G., Wang, X., Sui, W., Su, Z., Liu, W., Wang, X., et al.: Uni3r: Unified 3d reconstruction and semantic understanding via generalizable gaussian splatting from unposed multi-view images. arXiv preprint arXiv:2508.03643 (2025)
-
[73]
Open- mask3d: Open-vocabulary 3d instance segmentation.arXiv preprint arXiv:2306.13631, 2023
Takmaz, A., Fedele, E., Sumner, R.W., Pollefeys, M., Tombari, F., Engelmann, F.: Openmask3d: Open-vocabulary 3d instance segmentation. arXiv preprint arXiv:2306.13631 (2023)
-
[74]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Tang, Z., Fan, Y., Wang, D., Xu, H., Ranjan, R., Schwing, A., Yan, Z.: Mv- dust3r+: Single-stage scene reconstruction from sparse views in 2 seconds. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 5283–5293 (2025)
work page 2025
-
[75]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Tokmakov, P., Li, J., Gaidon, A.: Breaking the" object" in video object segmen- tation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 22836–22845 (2023)
work page 2023
-
[76]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Tu, T., Chuang, S.P., Liu, Y.L., Sun, C., Zhang, K., Roy, D., Kuo, C.H., Sun, M.: Imgeonet: Image-induced geometry-aware voxel representation for multi-view 3d object detection. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 6996–7007 (2023)
work page 2023
-
[77]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Videnovic, J., Lukezic, A., Kristan, M.: A distractor-aware memory for visual object tracking with sam2. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 24255–24264 (2025)
work page 2025
-
[78]
In: Proceed- ings of the IEEE/CVF conference on computer vision and pattern recognition
Voigtlaender, P., Chai, Y., Schroff, F., Adam, H., Leibe, B., Chen, L.C.: Feelvos: Fast end-to-end embedding learning for video object segmentation. In: Proceed- ings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 9481–9490 (2019)
work page 2019
-
[79]
Nesf: Neural semantic fields for generalizable semantic segmentation of 3d scenes
Vora, S., Radwan, N., Greff, K., Meyer, H., Genova, K., Sajjadi, M.S., Pot, E., Tagliasacchi, A., Duckworth, D.: Nesf: Neural semantic fields for generalizable semantic segmentation of 3d scenes. arXiv preprint arXiv:2111.13260 (2021)
-
[80]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Vu, T., Kim, K., Luu, T.M., Nguyen, T., Yoo, C.D.: Softgroup for 3d instance segmentation on point clouds. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 2708–2717 (2022)
work page 2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.