Recognition: no theorem link
Beyond Fixed Psychological Personas: State Beats Trait, but Language Models are State-Blind
Pith reviewed 2026-05-16 12:03 UTC · model grok-4.3
The pith
States account for 74% of variation in user psychological profiles while traits account for only 26%, yet language models respond only to traits.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
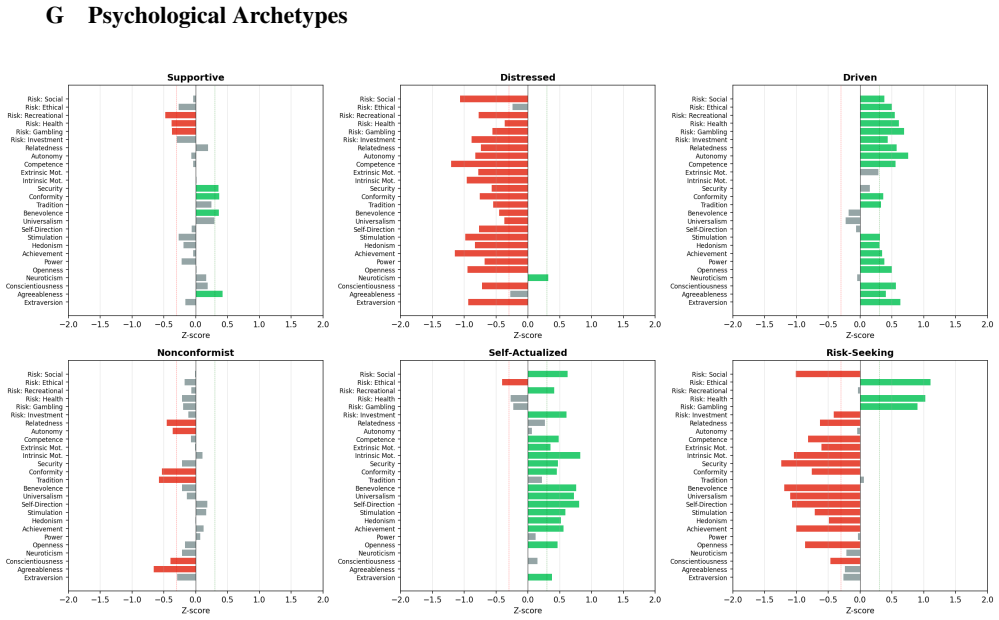
Using the Chameleon dataset of 5,001 contextual psychological profiles from 1,667 Reddit users, variance decomposition finds 74% within-person (state) and 26% between-person (trait). Language models focus exclusively on trait and produce similar responses across states. Reward models react to state but in opposite directions depending on the model.
What carries the argument
The Chameleon dataset, which supplies repeated contextual measurements per user to support state-trait variance decomposition.
If this is right
- Fixed-persona training data will leave models insensitive to the majority source of user variation.
- RLHF reward models must be evaluated separately for state consistency rather than trait-only signals.
- Personalized dialogue systems require context-aware profile updates instead of static user embeddings.
Where Pith is reading between the lines
- Providing models with explicit current-state labels at inference time may close part of the performance gap without retraining.
- Datasets that collect repeated measures across contexts could become standard for alignment research.
- Inconsistent reward-model behavior across states suggests that current RLHF pipelines may amplify or suppress certain user groups depending on momentary context.
Load-bearing premise
The Reddit-sourced profiles cleanly separate state from trait without platform biases or self-report distortions, and the variance method correctly assigns the 74/26 split to state versus trait.
What would settle it
Give language models explicit state descriptions drawn from the same users and measure whether response variation then matches the 74% within-person human pattern.
Figures








read the original abstract
User interactions with language models vary due to static properties of the user (trait) and the specific context of the interaction (state). However, existing persona datasets (like PersonaChat, PANDORA etc.) capture only trait, and ignore the impact of state. We introduce Chameleon, a dataset of 5,001 contextual psychological profiles from 1,667 Reddit users, each measured across multiple contexts. Using the Chameleon dataset, we present three key findings. First, inspired by Latent State-Trait theory, we decompose variance and find that 74% is within-person(state) while only 26% is between-person (trait). Second, we find that LLMs are state-blind: they focus on trait only, and produce similar responses regardless of state. Third, we find that reward models react to user state, but inconsistently: different models favor or penalize the same users in opposite directions. We release Chameleon to support research on affective computing, personalized dialogue, and RLHF alignment.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces the Chameleon dataset of 5,001 contextual psychological profiles drawn from 1,667 Reddit users across multiple contexts. Inspired by Latent State-Trait theory, the authors decompose profile variance and report that 74% is attributable to within-person (state) variation while 26% is between-person (trait) variation. They further claim that LLMs are state-blind, generating similar responses irrespective of user state, whereas reward models exhibit inconsistent reactions to the same states across different models. The dataset is released to support research on affective computing, personalized dialogue, and RLHF.
Significance. If the variance decomposition and model evaluations hold after addressing measurement concerns, the work would provide a useful empirical demonstration that state effects dominate fixed traits in user psychological profiles, with direct implications for moving beyond static persona modeling in conversational systems. The public release of Chameleon could enable reproducible follow-up studies on dynamic user modeling and more context-sensitive alignment techniques.
major comments (3)
- [Variance decomposition analysis] Variance decomposition analysis (results section): The 74/26 within/between split on single inferred profiles per context does not follow the multi-wave, multi-indicator design required by Latent State-Trait theory to isolate latent state from measurement error and method effects; subreddit-topic variation and inference noise are likely folded into the within-person term, inflating the reported state percentage and weakening the central claim that this split reflects psychological state as defined by the theory.
- [LLM state-blindness experiments] LLM state-blindness experiments (evaluation section): The claim that models produce similar responses regardless of state requires explicit description of the state manipulation procedure, similarity metric, and controls for trait-level content; without these, it is unclear whether the observed similarity stems from true state-blindness or from prompt construction that fails to isolate state.
- [Reward model inconsistency results] Reward model inconsistency results (evaluation section): The finding that different reward models favor or penalize the same users in opposite directions needs clarification on the exact scoring protocol, whether trait was held constant, and statistical significance testing; the current description leaves open the possibility that observed inconsistency reflects model-specific trait biases rather than state sensitivity.
minor comments (2)
- [Abstract] Abstract: The three findings are summarized numerically but the abstract should briefly note the number of contexts per user and the exact variance decomposition method to allow readers to assess the 74/26 claim at a glance.
- [Dataset description] Dataset description: Provide a table or appendix entry listing the psychological dimensions measured and the exact prompting or annotation procedure used to infer profiles from Reddit posts.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which have helped us identify areas for improvement in the manuscript. We address each major comment below.
read point-by-point responses
-
Referee: [Variance decomposition analysis] Variance decomposition analysis (results section): The 74/26 within/between split on single inferred profiles per context does not follow the multi-wave, multi-indicator design required by Latent State-Trait theory to isolate latent state from measurement error and method effects; subreddit-topic variation and inference noise are likely folded into the within-person term, inflating the reported state percentage and weakening the central claim that this split reflects psychological state as defined by the theory.
Authors: We acknowledge the referee's point regarding the application of Latent State-Trait theory. Our dataset provides one inferred profile per context per user, which does not include multiple indicators to fully separate measurement error. Nevertheless, the large within-person variance across contexts supports the dominance of state effects. In the revised version, we will include a dedicated limitations paragraph explaining that the within-person term may incorporate some inference noise and subreddit-specific variation, and we will emphasize that our results are an approximation inspired by LST theory rather than a strict implementation. This constitutes a partial revision. revision: partial
-
Referee: [LLM state-blindness experiments] LLM state-blindness experiments (evaluation section): The claim that models produce similar responses regardless of state requires explicit description of the state manipulation procedure, similarity metric, and controls for trait-level content; without these, it is unclear whether the observed similarity stems from true state-blindness or from prompt construction that fails to isolate state.
Authors: We agree that the evaluation section would benefit from more explicit details. In the revision, we will describe the state manipulation procedure by detailing how context-specific psychological profiles are incorporated into the prompts while holding trait information constant. We will specify the similarity metric as the average cosine similarity between response embeddings generated under different states for the same user. Additionally, we will include controls such as trait-only prompt baselines to isolate the effect of state. These changes will clarify the evidence for state-blindness. revision: yes
-
Referee: [Reward model inconsistency results] Reward model inconsistency results (evaluation section): The finding that different reward models favor or penalize the same users in opposite directions needs clarification on the exact scoring protocol, whether trait was held constant, and statistical significance testing; the current description leaves open the possibility that observed inconsistency reflects model-specific trait biases rather than state sensitivity.
Authors: We will expand the description of the reward model evaluation to include the exact scoring protocol, which involves generating responses to user queries under varying state conditions and scoring them with each reward model. Trait is held constant by using the same user trait profile across all state variations. We will also add statistical significance testing using repeated measures ANOVA to assess the inconsistency across models and states. This will strengthen the claim that the observed effects are due to state sensitivity rather than trait biases. revision: yes
Circularity Check
No circularity: empirical results from new dataset and direct variance decomposition
full rationale
The paper introduces a new Chameleon dataset of 5,001 contextual profiles from 1,667 Reddit users measured across multiple contexts. The central 74%/26% within-person (state) versus between-person (trait) split is obtained by applying a standard variance decomposition directly to this fresh data, inspired by but not derived from Latent State-Trait theory. LLM state-blindness and reward-model inconsistency findings are produced by running the models on the new profiles. No equations reduce a claimed prediction to a fitted input by construction, no load-bearing self-citations close the derivation chain, and the results are not equivalent to the inputs by definition. The analysis is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Latent State-Trait theory applies to the psychological profiles collected from Reddit users and correctly partitions variance into state and trait components.
Reference graph
Works this paper leans on
-
[1]
Matej Gjurkovi´c, Vanja M Karan, Iva Vukojevi´c, Mi- haela Bošnjak, and Jan Šnajder
Bias and fairness in large language models: A survey.Computational Linguistics, 50(3):1097– 1179. Matej Gjurkovi´c, Vanja M Karan, Iva Vukojevi´c, Mi- haela Bošnjak, and Jan Šnajder. 2021. Pandora talks: Personality and demographics on reddit. InProceed- ings of the ninth international workshop on natural language processing for social media, pages 138– 1...
work page 2021
-
[2]
Social biases in NLP models as barriers for persons with disabilities. InProceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 5491–5501, Online. Association for Computational Linguistics. Hang Jiang, Xiajie Zhang, Xubo Cao, Cynthia Breazeal, Deb Roy, and Jad Kabbara. 2023. Personallm: Investigating the ability of ...
-
[3]
Psychometric properties of the Intrinsic Mo- tivation Inventory in a competitive sport setting: A confirmatory factor analysis.Research Quarterly for Exercise and Sport, 60(1):48–58. Walter Mischel and Yuichi Shoda. 1995. A cognitive- affective system theory of personality: reconceptual- izing situations, dispositions, dynamics, and invari- ance in person...
work page internal anchor Pith review Pith/arXiv arXiv 1995
-
[4]
Towards Understanding Sycophancy in Language Models
Automatic personality assessment through social media language.Journal of personality and social psychology, 108(6):934. James W Pennebaker, Ryan L Boyd, Kayla Jordan, and Kate Blackburn. 2015. The development and psycho- metric properties of LIWC2015. Ethan Perez, Sam Ringer, Kamile Lukosiute, Karina Nguyen, Edwin Chen, Scott Heiner, Craig Pettit, Cather...
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[5]
Saizheng Zhang, Emily Dinan, Jack Urbanek, Arthur Szlam, Douwe Kiela, and Jason Weston
A domain-specific risk-attitude scale: Measur- ing risk perceptions and risk behaviors.Journal of behavioral decision making, 15(4):263–290. Saizheng Zhang, Emily Dinan, Jack Urbanek, Arthur Szlam, Douwe Kiela, and Jason Weston. 2018. Per- sonalizing dialogue agents: I have a dog, do you have pets too? InProceedings of the 56th Annual Meeting of the Assoc...
work page 2018
-
[6]
and extended by SEANCE (Crossley et al.,
-
[7]
compute features through lexicon matching against validated dictionaries. These methods offer high reproducibility and interpretability but limited sensitivity to context and pragmatics. Machine learning approachestrained classi- fiers on labeled personality data, demonstrating that Big Five traits can be predicted from social media text (Schwartz et al.,...
work page 2013
-
[8]
This design explicitly treats within-user variation as measurement error to be averaged away
extracts Big Five personality from Reddit users by aggregating across all their posts, produc- ing one static profile per user. This design explicitly treats within-user variation as measurement error to be averaged away. Recent work has expanded beyond fixed per- sonas to address related challenges in personal- ization and pluralistic alignment. LaMP (Sa...
work page 2024
-
[9]
evaluates pluralistic alignment by creating synthetic personas with diverse demographic and psychographic attributes drawn from US census data. However, both retain implicit stability as- sumptions: LaMP treats user preferences as con- sistent over time, while PERSONA assigns fixed psychological profiles (including Big Five traits) to each synthetic perso...
work page 2025
- [10]
-
[11]
Have no single “correct” answer
-
[12]
Represent realistic decisions users face Category Scenarios Honesty vs. Social Harmony (agreeableness, conflict avoid- ance) • Is it acceptable to lie to protect someone’s feelings? • Should you tell a friend their new haircut looks bad? • Should you always tell the truth, even if it hurts? • Should you tell someone they have food in their teeth? • Is it ...
work page 1959
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.