LLM-Enhanced Reinforcement Learning for Long-Term User Satisfaction in Interactive Recommendation
Pith reviewed 2026-05-16 10:38 UTC · model grok-4.3
The pith
A new hierarchical framework combines LLM planning with reinforcement learning to improve long-term satisfaction in interactive recommendations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
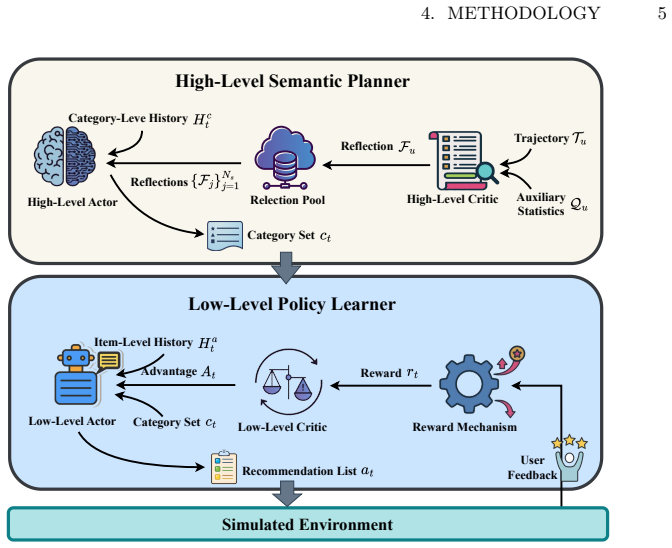
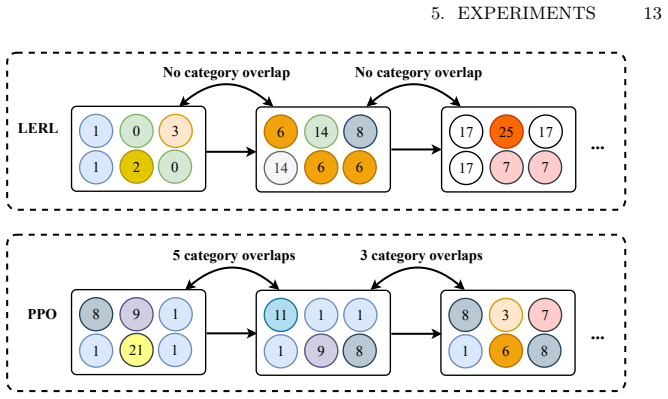
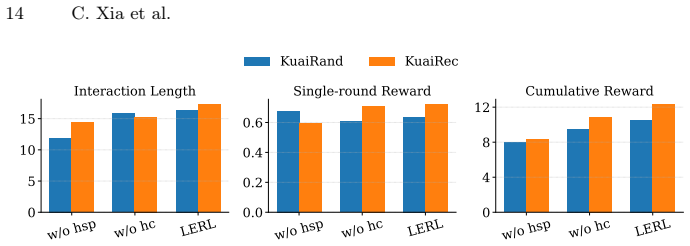
The authors claim that their LERL framework, consisting of an LLM-based high-level planner for selecting semantically diverse content categories and a low-level RL policy for personalized item recommendation within the selected space, significantly improves long-term user satisfaction by narrowing the action space, enhancing planning efficiency, and mitigating content homogeneity in interactive recommender systems.
What carries the argument
The LERL hierarchical architecture that delegates semantic category selection to an LLM and item-level decisions to RL.
If this is right
- Reduces the effective action space for reinforcement learning, allowing faster convergence in sparse data settings.
- Promotes content diversity at the category level to prevent filter bubbles over extended interactions.
- Supports better modeling of long-term user interest evolution compared to flat RL policies.
- Outperforms state-of-the-art baselines on real-world datasets in long-term satisfaction metrics.
Where Pith is reading between the lines
- This two-level split might transfer to other recommendation-like tasks such as sequential content generation or adaptive interfaces.
- Stronger future LLMs could make the planner more robust, potentially removing the need for hand-crafted rules in planning.
- Deployed systems using this method could see reduced user churn by maintaining engagement across multiple sessions.
Load-bearing premise
The LLM planner must accurately identify categories that reflect the user's long-term interests rather than introducing planning mistakes or new biases.
What would settle it
A test replacing the LLM planner with random or short-term-only category selection and checking if the long-term satisfaction improvements vanish in the same experimental setup.
Figures


read the original abstract
Interactive recommender systems can dynamically adapt to user feedback, but often suffer from content homogeneity and filter bubble effects due to overfitting short-term user preferences. While recent efforts aim to improve content diversity, they predominantly operate in static or one-shot settings, neglecting the long-term evolution of user interests. Reinforcement learning provides a principled framework for optimizing long-term user satisfaction by modeling sequential decision-making processes. However, its application in recommendation is hindered by sparse, long-tailed user-item interactions and limited semantic planning capabilities. In this work, we propose LLM-Enhanced Reinforcement Learning (LERL), a novel hierarchical recommendation framework that integrates the semantic planning power of LLM with the fine-grained adaptability of RL. LERL consists of a high-level LLM-based planner that selects semantically diverse content categories, and a low-level RL policy that recommends personalized items within the selected semantic space. This hierarchical design narrows the action space, enhances planning efficiency, and mitigates overexposure to redundant content. Extensive experiments on real-world datasets demonstrate that LERL significantly improves long-term user satisfaction when compared with state-of-the-art baselines. The implementation of LERL is available at https://github.com/1163710212/LERL.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes LLM-Enhanced Reinforcement Learning (LERL), a hierarchical framework that uses an LLM-based high-level planner to select semantically diverse content categories and a low-level RL policy to recommend personalized items within those categories. The goal is to optimize long-term user satisfaction in interactive recommender systems while mitigating content homogeneity and filter bubbles; the authors report that extensive experiments on real-world datasets show significant improvements over state-of-the-art baselines.
Significance. If the empirical results can be shown to hold under evaluation that directly measures evolving user interests, the work would offer a concrete way to combine LLM semantic planning with RL for sequential recommendation, potentially improving diversity and long-term engagement metrics in production systems. The public GitHub implementation is a clear strength for reproducibility.
major comments (2)
- [Abstract and Experiments] Abstract and Experiments section: The headline claim that LERL 'significantly improves long-term user satisfaction' rests on offline evaluation of static interaction logs. These logs contain no closed-loop user responses to the LLM planner's category selections, so any reported gains are necessarily computed on fixed sequences using proxy metrics whose correlation with actual multi-step preference evolution is untested. This directly weakens support for the central claim.
- [Method] Method section (hierarchical planner description): The assumption that the LLM high-level planner reliably selects categories aligned with long-term interests without introducing new biases or planning errors is stated but not accompanied by any ablation, error analysis, or sensitivity study on planner outputs. Because this assumption is load-bearing for the hierarchical design's claimed benefits, its empirical validation is required.
minor comments (1)
- [Abstract] Abstract: The claim of 'significant improvement' is presented without any numerical results, dataset sizes, or statistical details; adding at least one key quantitative finding would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our evaluation methodology and the validation of the LLM planner. We address each major comment below, providing our strongest honest defense while outlining planned revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract and Experiments] The headline claim that LERL 'significantly improves long-term user satisfaction' rests on offline evaluation of static interaction logs. These logs contain no closed-loop user responses to the LLM planner's category selections, so any reported gains are necessarily computed on fixed sequences using proxy metrics whose correlation with actual multi-step preference evolution is untested. This directly weakens support for the central claim.
Authors: We agree that offline evaluation on static logs cannot fully capture closed-loop user dynamics or evolving preferences in response to the LLM planner. This is a standard limitation in sequential recommendation research, as online closed-loop studies with real users are costly and raise ethical issues. Our proxy metrics (cumulative reward, diversity, and homogeneity measures) follow established practices in the field and have been shown in prior work to correlate with long-term satisfaction. To strengthen the paper, we will revise the abstract and experiments section to explicitly qualify the claims as improvements under offline simulation, add a dedicated limitations subsection discussing the absence of closed-loop validation, and include further analysis of how the hierarchical design reduces homogeneity on the fixed logs. We cannot perform new online experiments at this stage. revision: partial
-
Referee: [Method] The assumption that the LLM high-level planner reliably selects categories aligned with long-term interests without introducing new biases or planning errors is stated but not accompanied by any ablation, error analysis, or sensitivity study on planner outputs. Because this assumption is load-bearing for the hierarchical design's claimed benefits, its empirical validation is required.
Authors: We acknowledge that the reliability of the LLM planner requires direct empirical support. In the revised manuscript, we will add: (1) an ablation study comparing full LERL against a variant without the LLM planner (using random or heuristic category selection), (2) an error analysis measuring the alignment of selected categories with long-term user interests inferred from interaction logs, and (3) a sensitivity study varying LLM prompts, temperature, and model versions to quantify planning errors and biases. These additions will provide concrete evidence for the planner's contribution and address the load-bearing assumption. revision: yes
- Direct closed-loop online evaluation measuring real user responses to the LLM planner's category selections and evolving interests, which would require a new user study beyond the current offline experimental scope.
Circularity Check
No significant circularity; claims rest on external dataset evaluation rather than self-referential definitions or fitted predictions
full rationale
The paper presents LERL as a hierarchical framework (LLM high-level planner selecting categories + low-level RL policy) and supports its long-term satisfaction claims solely through experiments on real-world datasets. No equations, derivations, or parameter-fitting steps are described that would reduce the reported improvements to quantities defined inside the paper itself. No self-citation chains, uniqueness theorems, or ansatzes are invoked as load-bearing premises. The evaluation uses proxy metrics on static logs, but this is an external validity concern rather than a circular reduction in the derivation chain.
Axiom & Free-Parameter Ledger
free parameters (1)
- RL policy hyperparameters
axioms (1)
- domain assumption LLM can select semantically diverse categories aligned with long-term interests
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
LERL consists of a high-level LLM-based planner that selects semantically diverse content categories, and a low-level RL policy that recommends personalized items within the selected semantic space.
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We adopt a Transformer-based encoder... PPO algorithm
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Achiam, J., Adler, S., et al.: Gpt-4 technical report. arXiv preprint arXiv:2303.08774 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
Wiley Interdisciplinary Reviews: Data Mining and Knowledge Discovery13(6), e1512 (2023)
Areeb, Q.M., Nadeem, M., et al.: Filter bubbles in recommender systems: Fact or fallacy—a systematic review. Wiley Interdisciplinary Reviews: Data Mining and Knowledge Discovery13(6), e1512 (2023)
work page 2023
-
[3]
In: Proceedings of the 14th ACM con- ference on Recommender Systems
Aridor, G., Goncalves, D., Sikdar, S.: Deconstructing the filter bubble: User decision-making and recommender systems. In: Proceedings of the 14th ACM con- ference on Recommender Systems. pp. 82–91 (2020)
work page 2020
-
[4]
Information Processing & Management58(6), 102721 (2021)
Du, Y., Ranwez, S., Sutton-Charani, N., Ranwez, V.: Is diversity optimization alwayssuitable?towardabetterunderstandingofdiversitywithinrecommendation approaches. Information Processing & Management58(6), 102721 (2021)
work page 2021
-
[5]
Dubey, A., Jauhri, A., et al.: The llama 3 herd of models. arXiv e-prints pp. arXiv– 2407 (2024)
work page 2024
-
[6]
In: Proceedings of the International conference on machine learning
Fujimoto, S., Hoof, H., Meger, D.: Addressing function approximation error in actor-critic methods. In: Proceedings of the International conference on machine learning. pp. 1587–1596. PMLR (2018)
work page 2018
-
[7]
Gao, C., Huang, K., et al.: Alleviating matthew effect of offline reinforcement learning in interactive recommendation. In: Proceedings of the 46th International ACM SIGIR Conference on Research and Development in Information Retrieval. pp. 238–248 (2023)
work page 2023
-
[8]
In: Proceedings of the 31st ACM International Conference on Information & Knowledge Management
Gao, C., Li, S., Zhang, Y., et al.: Kuairand: An unbiased sequential recommen- dation dataset with randomly exposed videos. In: Proceedings of the 31st ACM International Conference on Information & Knowledge Management. pp. 3953– 3957 (2022)
work page 2022
-
[9]
In: Proceedings of the 31st ACM International Conference on Information & Knowledge Management
Gao, C., Li, S., et al.: Kuairec: A fully-observed dataset and insights for evaluating recommender systems. In: Proceedings of the 31st ACM International Conference on Information & Knowledge Management. pp. 540–550 (2022)
work page 2022
-
[10]
ACM Transactions on Information Sys- tems42(1), 1–27 (2023)
Gao, C., Wang, S., Li, S., Chen, J., et al.: Cirs: Bursting filter bubbles by counter- factual interactive recommender system. ACM Transactions on Information Sys- tems42(1), 1–27 (2023)
work page 2023
-
[11]
Gao, Z., Shen, T., et al.: Mitigating the filter bubble while maintaining relevance: Targeted diversification with vae-based recommender systems. In: Proceedings of the 45th International ACM SIGIR Conference on Research and Development in Information Retrieval. pp. 2524–2531 (2022)
work page 2022
-
[12]
Advances in Neural Information Processing Systems12(1999)
Konda, V., Tsitsiklis, J.: Actor-critic algorithms. Advances in Neural Information Processing Systems12(1999)
work page 1999
-
[13]
IEEE Transactions on Visualization and Computer Graphics29(1), 95–105 (2022)
Li, Y., Qi, Y., Shi, Y., Chen, Q., Cao, N., Chen, S.: Diverse interaction recom- mendation for public users exploring multi-view visualization using deep learning. IEEE Transactions on Visualization and Computer Graphics29(1), 95–105 (2022)
work page 2022
-
[14]
In: Proceedings of the ACM web conference
Li, Z., Dong, Y., Gao, C., et al.: Breaking filter bubble: A reinforcement learning framework of controllable recommender system. In: Proceedings of the ACM web conference. pp. 4041–4049 (2023)
work page 2023
-
[15]
In: Proceedings of the 28th International Conference on Intelligent User Interfaces
Liang, Y., Ponnada, A., Lamere, P., Daskalova, N.: Enabling goal-focused explo- ration of podcasts in interactive recommender systems. In: Proceedings of the 28th International Conference on Intelligent User Interfaces. pp. 142–155 (2023)
work page 2023
-
[16]
Continuous control with deep reinforcement learning
Lillicrap, T.: Continuous control with deep reinforcement learning. arXiv preprint arXiv:1509.02971 (2015)
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[17]
IEEE Transactions on Neural Networks and Learning Systems35(10), 13164–13184 (2024)
Lin, Y., Liu, Y., Lin, F., Zou, L., Wu, P., Zeng, W., Chen, H., Miao, C.: A survey on reinforcement learning for recommender systems. IEEE Transactions on Neural Networks and Learning Systems35(10), 13164–13184 (2024)
work page 2024
-
[18]
Liu, H., Cai, K., Li, P., Qian, C., Zhao, P., Wu, X.: Redrl: A review-enhanced deep reinforcementlearningmodelforinteractiverecommendation.ExpertSystemswith Applications213, 118926 (2023)
work page 2023
-
[19]
In: Proceedings of the ACM Web Conference
Liu, S., Cai, Q., Sun, B., Wang, Y., Jiang, J., Zheng, D., Jiang, P., Gai, K., Zhao, X., Zhang, Y.: Exploration and regularization of the latent action space in recom- mendation. In: Proceedings of the ACM Web Conference. pp. 833–844 (2023)
work page 2023
-
[20]
Tsinghua Science and Technology 28(4), 786–798 (2023)
Ma, D., Wang, Y., Ma, J., Jin, Q.: Sgnr: A social graph neural network based inter- active recommendation scheme for e-commerce. Tsinghua Science and Technology 28(4), 786–798 (2023)
work page 2023
-
[21]
IEEE Transactions on Multimedia26, 1129–1142 (2023)
Nie, W., Wen, X., Liu, J., Chen, J., Wu, J., Jin, G., Lu, J., Liu, A.A.: Knowledge- enhanced causal reinforcement learning model for interactive recommendation. IEEE Transactions on Multimedia26, 1129–1142 (2023)
work page 2023
-
[22]
ACM Transactions on Information Systems42(2), 1–24 (2023)
Quan, Y., Ding, J., Gao, C., et al.: Alleviating video-length effect for micro-video recommendation. ACM Transactions on Information Systems42(2), 1–24 (2023)
work page 2023
-
[23]
Proximal Policy Optimization Algorithms
Schulman, J., Wolski, F., Dhariwal, P., Radford, A., Klimov, O.: Proximal policy optimization algorithms. arXiv preprint arXiv:1707.06347 (2017) 16 C. Xia et al
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[24]
IEEE Transactions on Services Computing17(3), 1029–1043 (2024)
Shi, X., Liu, Q., Xie, H., Bai, Y., Shang, M.: Maximum entropy policy for long- term fairness in interactive recommender systems. IEEE Transactions on Services Computing17(3), 1029–1043 (2024)
work page 2024
-
[25]
ACM Transactions on Information Systems42(2), 1–30 (2023)
Shi, X., Liu, Q., et al.: Relieving popularity bias in interactive recommendation: A diversity-novelty-aware reinforcement learning approach. ACM Transactions on Information Systems42(2), 1–30 (2023)
work page 2023
-
[26]
Journal of Intelligent & Fuzzy Systems pp
Tahir Kidwai, U., Akhtar, N., et al.: Mitigating filter bubbles: Diverse and ex- plainable recommender systems. Journal of Intelligent & Fuzzy Systems pp. JIFS– 219416 (2024)
work page 2024
-
[27]
In: Proceedings of the 15th ACM Confer- ence on Recommender Systems
Tommasel, A., Rodriguez, J.M., Godoy, D.: I want to break free! recommending friends from outside the echo chamber. In: Proceedings of the 15th ACM Confer- ence on Recommender Systems. pp. 23–33 (2021)
work page 2021
-
[28]
Frontiers of Computer Science18(6), 186345 (2024)
Wang, L., Ma, C., Feng, X., et al.: A survey on large language model based au- tonomous agents. Frontiers of Computer Science18(6), 186345 (2024)
work page 2024
-
[29]
Wei, H., Zhang, Z., He, S., Xia, T., Pan, S., Liu, F.: Plangenllms: A modern survey of llm planning capabilities. In: Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). pp. 19497–19521 (2025)
work page 2025
-
[30]
In: Proceedings of the 17th ACM International Conference on Web Search and Data Mining
Wei, W., Ren, X., et al.: Llmrec: Large language models with graph augmentation for recommendation. In: Proceedings of the 17th ACM International Conference on Web Search and Data Mining. pp. 806–815 (2024)
work page 2024
-
[31]
Machine learning8, 229–256 (1992)
Williams, R.J.: Simple statistical gradient-following algorithms for connectionist reinforcement learning. Machine learning8, 229–256 (1992)
work page 1992
-
[32]
In: Proceedings of the 18th ACM Confer- ence on Recommender Systems
Xi, Y., Liu, W., et al.: Towards open-world recommendation with knowledge aug- mentation from large language models. In: Proceedings of the 18th ACM Confer- ence on Recommender Systems. pp. 12–22 (2024)
work page 2024
-
[33]
Xia, C., Shi, X., Xie, H., Lu, Y., Li, P., Shang, M.: Beyond trade-offs: Lever- aging spatiotemporal heterogeneity of user preference for long-term fairness and accuracy in interactive recommendation. ACM Trans. Web (Sep 2025). https://doi.org/10.1145/3769471
-
[34]
In: Proceedings of IEEE International Conference on Web Services
Xia, C., Shi, X., et al.: Hierarchical reinforcement learning for long-term fairness in interactive recommendation. In: Proceedings of IEEE International Conference on Web Services. pp. 300–309. IEEE (2024)
work page 2024
-
[35]
ACM Transactions on Knowledge Discovery from Data14(4), 1–25 (2020)
Xu, Y., Yang, Y., et al.: Neural serendipity recommendation: Exploring the balance between accuracy and novelty with sparse explicit feedback. ACM Transactions on Knowledge Discovery from Data14(4), 1–25 (2020)
work page 2020
-
[36]
Yu, Y., Gao, C., Chen, J., et al.: Easyrl4rec: An easy-to-use library for reinforce- ment learning based recommender systems. In: Proceedings of the 47th Interna- tional ACM SIGIR Conference on Research and Development in Information Re- trieval. pp. 977–987 (2024)
work page 2024
-
[37]
ACM Transactions on Infor- mation Systems43(5), 1–37 (2025)
Zhang, J., Xie, R., et al.: Recommendation as instruction following: A large lan- guage model empowered recommendation approach. ACM Transactions on Infor- mation Systems43(5), 1–37 (2025)
work page 2025
-
[38]
Advances in Neural Information Processing Systems36, 44880–44897 (2023)
Zhao, K., et al.: Kuaisim: A comprehensive simulator for recommender systems. Advances in Neural Information Processing Systems36, 44880–44897 (2023)
work page 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.