Recognition: 2 theorem links
· Lean TheoremContour Refinement using Discrete Diffusion in Low Data Regime
Pith reviewed 2026-05-16 06:51 UTC · model grok-4.3
The pith
A lightweight discrete diffusion pipeline refines sparse contours into accurate boundaries using a CNN with self-attention conditioned on segmentation masks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
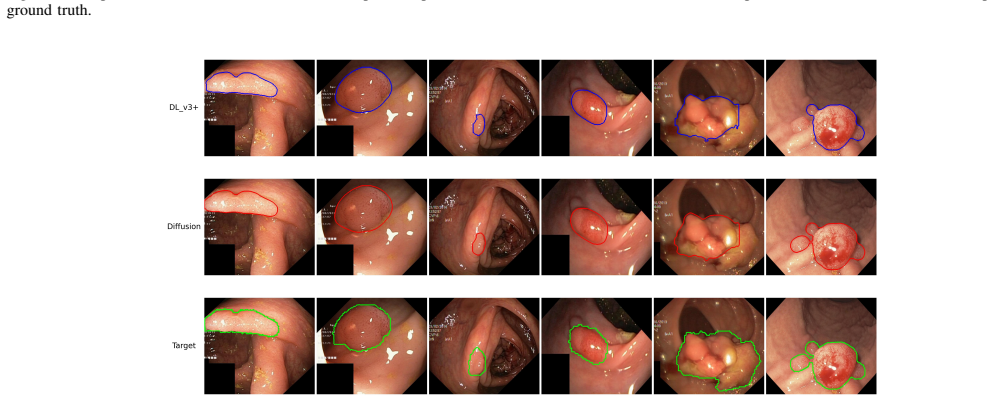
The authors show that a simplified discrete diffusion process, paired with a CNN architecture that includes self-attention layers and conditioned on an input segmentation mask, can iteratively denoise a sparse contour representation to yield a dense isolated boundary. The pipeline incorporates a streamlined diffusion schedule, a tailored network design, and minimal post-processing steps so that the entire refinement operates reliably on datasets smaller than 500 training images.
What carries the argument
The discrete diffusion contour refinement pipeline that iteratively denoises a sparse contour representation conditioned on a segmentation mask inside a customized CNN with self-attention layers.
If this is right
- Boundary detection becomes feasible for translucent objects in medical scans without collecting large annotated sets.
- Inference speed increases by a factor of 3.5 relative to prior contour methods while maintaining competitive accuracy.
- The same pipeline applies directly to environmental tasks such as delineating smoke plumes in wildfire imagery.
- Minimal post-processing requirements allow the output contours to be used immediately in downstream measurement or tracking systems.
Where Pith is reading between the lines
- The approach may reduce the annotation burden in any domain where precise edges matter more than full masks, such as industrial inspection of translucent parts.
- Because the diffusion steps are simplified, the method could be further accelerated or quantized for deployment on devices with tight memory limits.
- Testing the pipeline on video sequences would reveal whether temporal consistency emerges naturally from the per-frame contour refinement.
Load-bearing premise
The simplified diffusion schedule together with the custom CNN and self-attention layers will produce stable contour refinements across different low-data domains without overfitting or needing extensive extra tuning.
What would settle it
A clear drop in boundary accuracy or an increase in fragmented contours when the same pipeline is evaluated on a new dataset of fewer than 100 images drawn from a previously unseen object class would falsify the claim of robust low-data generalization.
Figures





read the original abstract
Boundary detection of irregular and translucent objects is an important problem with applications in medical imaging, environmental monitoring and manufacturing, where many of these applications are plagued with scarce labeled data and low in situ computational resources. While recent image segmentation studies focus on segmentation mask alignment with ground-truth, the task of boundary detection remains understudied, especially in the low data regime. In this work, we present a lightweight discrete diffusion contour refinement pipeline for robust boundary detection in the low data regime. We use a Convolutional Neural Network(CNN) architecture with self-attention layers as the core of our pipeline, and condition on a segmentation mask, iteratively denoising a sparse contour representation. We introduce multiple novel adaptations for improved low-data efficacy and inference efficiency, including using a simplified diffusion process, a customized model architecture, and minimal post processing to produce a dense, isolated contour given a dataset of size <500 training images. Our method outperforms several SOTA baselines on the medical imaging dataset KVASIR, is competitive on HAM10K and our custom wildfire dataset, Smoke, while improving inference framerate by 3.5X.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a lightweight discrete diffusion contour refinement pipeline for boundary detection of irregular objects in low-data regimes (<500 training images). It uses a CNN with self-attention layers conditioned on a segmentation mask to iteratively denoise a sparse contour representation, with adaptations including a simplified diffusion process, customized architecture, and minimal post-processing. The central claim is that this yields outperformance versus SOTA baselines on the KVASIR medical dataset, competitiveness on HAM10K and the custom Smoke wildfire dataset, and 3.5X faster inference.
Significance. If the performance and efficiency claims hold under scrutiny, the approach could address a practical gap in boundary detection for data-scarce domains such as medical imaging and environmental monitoring, where both accuracy and low-resource inference matter. The focus on simplified diffusion for low-data efficacy is a potentially useful engineering direction if supported by ablations.
major comments (3)
- [Abstract] Abstract: The claims of outperformance on KVASIR, competitiveness on HAM10K/Smoke, and 3.5X inference speedup are stated without any quantitative metrics, error bars, dataset sizes, baseline tables, or statistical tests, making it impossible to assess whether the central claim is supported by evidence.
- [§4 (Experiments)] §4 (Experiments): No ablation varying training-set cardinality is reported, nor any comparison against a standard (non-simplified) diffusion baseline; this leaves the low-data generalization assumption untested and the robustness to data scarcity unverified.
- [§3 (Method)] §3 (Method): The simplified diffusion process and self-attention CNN are presented as key for low-data efficacy, but without explicit equations showing the schedule or conditioning, or controls for overfitting, the load-bearing claim that these adaptations suffice for <500 images remains unsubstantiated.
minor comments (2)
- [§3 (Method)] The notation for the sparse contour representation and denoising steps should be formalized with equations to improve reproducibility.
- [§4 (Experiments)] Figure captions and table headers lack sufficient detail on metric definitions (e.g., which boundary-specific IoU or F-score variant is used).
Simulated Author's Rebuttal
We thank the referee for their valuable feedback. We believe the suggested revisions will strengthen the presentation of our work. We address each major comment below, indicating the changes made to the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claims of outperformance on KVASIR, competitiveness on HAM10K/Smoke, and 3.5X inference speedup are stated without any quantitative metrics, error bars, dataset sizes, baseline tables, or statistical tests, making it impossible to assess whether the central claim is supported by evidence.
Authors: We agree with this observation. To address this, we have revised the abstract to include key quantitative metrics from our experiments, such as the performance scores on KVASIR, dataset sizes, and the inference speedup, along with references to the relevant tables and figures. Error bars and details on statistical tests are now explicitly mentioned in the abstract and elaborated in Section 4. revision: yes
-
Referee: [§4 (Experiments)] §4 (Experiments): No ablation varying training-set cardinality is reported, nor any comparison against a standard (non-simplified) diffusion baseline; this leaves the low-data generalization assumption untested and the robustness to data scarcity unverified.
Authors: We acknowledge this limitation in the original submission. In the revised manuscript, we have included an ablation study that varies the training set cardinality (from 100 to the full <500 images) to verify the low-data generalization. We have also added a comparison against a standard (non-simplified) discrete diffusion baseline, which demonstrates the benefits of our simplifications in terms of both accuracy and efficiency in data-scarce settings. revision: yes
-
Referee: [§3 (Method)] §3 (Method): The simplified diffusion process and self-attention CNN are presented as key for low-data efficacy, but without explicit equations showing the schedule or conditioning, or controls for overfitting, the load-bearing claim that these adaptations suffice for <500 images remains unsubstantiated.
Authors: We have updated Section 3 with explicit equations for the simplified diffusion schedule and the conditioning mechanism. The forward and reverse processes are now formalized mathematically. Furthermore, we have included details on the self-attention integration and added controls for overfitting, such as the use of dropout layers, L2 regularization, and monitoring of validation loss to prevent overfitting on small datasets. revision: yes
Circularity Check
No circularity detected; empirical pipeline is self-contained engineering contribution
full rationale
The paper describes an applied method: a CNN with self-attention layers that iteratively denoises a sparse contour representation conditioned on a segmentation mask, using a simplified diffusion process and minimal post-processing. No equations or derivations are presented that reduce a claimed result to a fitted parameter or self-referential definition. Performance claims (outperformance on KVASIR, competitiveness on HAM10K/Smoke, 3.5X faster inference) rest on reported empirical evaluations rather than any quantity defined by construction from the inputs. No self-citation chains, uniqueness theorems, or ansatzes are invoked in a load-bearing way. The derivation chain consists of independent architectural and process choices for low-data regimes and is therefore self-contained.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We use a Convolutional Neural Network(CNN) architecture with self-attention layers as the core of our pipeline, and condition on a segmentation mask, iteratively denoising a sparse contour representation. We introduce multiple novel adaptations for improved low-data efficacy and inference efficiency, including using a simplified diffusion process
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Our losses consist of only the simple loss component (eq. (5)) , as in [14], since we find training with the full KL matching loss requires extensive amounts of data... In the low data setting, the DICE Loss is used instead of the full KL matching loss
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
SAM 2: Segment Anything in Images and Videos, Nikhila Ravi and Valentin Gabeur and Yuan-Ting Hu and Ronghang Hu and Chaitanya Ryali and Tengyu Ma and Haitham Khedr and Roman R ¨adle and Chloe Rolland and Laura Gustafson and Eric Mintun and Junting Pan and Kalyan Vasudev Alwala and Nicolas Carion and Chao-Yuan Wu and Ross Girshick and Piotr Doll ´ar and Ch...
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [2]
-
[3]
Mazurowski, 2024, 2403.10786, arXiv, eess.IV, https://arxiv.org/abs/2403.10786,
ContourDiff: Unpaired Image-to-Image Translation with Structural Con- sistency for Medical Imaging, Yuwen Chen and Nicholas Konz and Hanxue Gu and Haoyu Dong and Yaqian Chen and Lin Li and Jisoo Lee and Maciej A. Mazurowski, 2024, 2403.10786, arXiv, eess.IV, https://arxiv.org/abs/2403.10786,
-
[4]
Wei-Ying Ma and Manjunath, B.S., IEEE Transactions on Image Processing, EdgeFlow: a technique for boundary detection and image segmentation, 2000, 1375-1388, Image edge detection;Image segmentation;Predictive coding;Predictive models;Computer vision;Image retrieval;Content based retrieval;Gabor filters;Filtering;Application software, 10.1109/83.855433
-
[5]
Caselles, V . and Kimmel, R. and Sapiro, G., bookProceedings of IEEE International Conference on Computer Vision, Geodesic active contours, 1995, 694-699, 10.1109/ICCV .1995.466871
- [6]
-
[8]
Deep Smoke Segmentation, Feiniu Yuan and Lin Zhang and Xue Xia and Boyang Wan and Qinghua Huang and Xuelong Li, 2018, 1809.00774, arXiv, cs.CV, https://arxiv.org/abs/1809.00774,
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[9]
Li, Mengna and Zhang, Youmin and Mu, Lingxia and Jing, Xin and Yu, Ziquan and Jiao, Shangbin and Liu, Han and Xie, Guo and Yingmin, Yi, 2022, 01, 145-150, A Real-time Fire Segmentation Method Based on A Deep Learning Approach, 55, IFAC-PapersOnLine, 10.1016/j.ifacol.2022.07.120
-
[10]
Rethinking Atrous Convolution for Semantic Image Segmenta- tion, Liang-Chieh Chen and George Papandreou and Florian Schroff and Hartwig Adam, 2017, 1706.05587, arXiv, cs.CV, https://arxiv.org/abs/1706.05587,
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[11]
Using DUCK-Net for polyp image segmentation, 13, 2045-2322, http://dx.doi.org/10.1038/s41598-023-36940-5, 10.1038/s41598-023- 36940-5, 1, Scientific Reports, publisher=Springer Science and Business Media LLC, Dumitru, Razvan-Gabriel and Peteleaza, Darius and Craciun, Catalin, 2023, month=jun
-
[12]
Unpublished, Glenn Jocher and Jing Qiu, Ultralytics YOLO11, version = 11.0.0, 2024, https://github.com/ultralytics/ultralytics, 0000-0001-5950- 6979, 0000-0003-3783-7069, AGPL-3.0
work page 2024
-
[13]
Attention Is All You Need, Ashish Vaswani and Noam Shazeer and Niki Parmar and Jakob Uszkoreit and Llion Jones and Aidan N. Gomez and Lukasz Kaiser and Illia Polosukhin, 2023, 1706.03762, arXiv, cs.CL, https://arxiv.org/abs/1706.03762,
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[14]
Structured Denoising Diffusion Models in Discrete State-Spaces, Ja- cob Austin and Daniel D. Johnson and Jonathan Ho and Daniel Tarlow and Rianne van den Berg, 2023, 2107.03006, arXiv, cs.LG, https://arxiv.org/abs/2107.03006,
-
[15]
Zhang, T. Y . and Suen, C. Y ., A fast parallel algorithm for thinning digital patterns, 1984, issue date = March 1984, publisher = Association for Computing Machinery, address = New York, NY , USA, 27, 3, 0001- 0782, https://doi.org/10.1145/357994.358023, 10.1145/357994.358023, Commun. ACM, mar, 236–239, num4, parallel algorithm, skeletoniza- tion, thinn...
-
[16]
Generative Adversarial Networks, Ian J. Goodfellow and Jean Pouget- Abadie and Mehdi Mirza and Bing Xu and David Warde-Farley and Sherjil Ozair and Aaron Courville and Yoshua Bengio, 2014, 1406.2661, arXiv, stat.ML, https://arxiv.org/abs/1406.2661,
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[17]
The HAM10000 dataset, a large collection of multi-source der- matoscopic images of common pigmented skin lesions, 5, 2052- 4463, http://dx.doi.org/10.1038/sdata.2018.161, 10.1038/sdata.2018.161, 1, Scientific Data, publisher=Springer Science and Business Media LLC, Tschandl, Philipp and Rosendahl, Cliff and Kittler, Harald, 2018, month=aug
-
[18]
KV ASIR: A Multi-Class Image Dataset for Computer Aided Gastroin- testinal Disease Detection, Pogorelov, Konstantin and Randel, Kristin Ranheim and Griwodz, Carsten and Eskeland, Sigrun Losada and de Lange, Thomas and Johansen, Dag and Spampinato, Concetto and Dang-Nguyen, Duc-Tien and Lux, Mathias and Schmidt, Peter Thelin and Riegler, Michael and Halvor...
-
[19]
Denoising Diffusion Implicit Models, Jiaming Song and Chen- lin Meng and Stefano Ermon, 2022, 2010.02502, arXiv, cs.LG, https://arxiv.org/abs/2010.02502,
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[20]
Denoising Diffusion Probabilistic Models, Jonathan Ho and Ajay Jain and Pieter Abbeel, 2020, 2006.11239, arXiv, cs.LG, https://arxiv.org/abs/2006.11239,
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[21]
Deep Residual Learning for Image Recognition, Kaiming He and Xiangyu Zhang and Shaoqing Ren and Jian Sun, 2015, 1512.03385, arXiv, cs.CV, https://arxiv.org/abs/1512.03385,
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[22]
Polyak, B. T. and Juditsky, A. B., Acceleration of Stochastic Approxi- mation by Averaging, SIAM Journal on Control and Optimization, 30, 4, 838-855, 1992, 10.1137/0330046, https://doi.org/10.1137/0330046 ,
-
[23]
Decoupled Weight Decay Regularization, Ilya Loshchilov and Frank Hutter, 2019, 1711.05101, arXiv, cs.LG, https://arxiv.org/abs/1711.05101,
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[24]
Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation, Liang-Chieh Chen and Yukun Zhu and George Papandreou and Florian Schroff and Hartwig Adam, 2018, 1802.02611, arXiv, cs.CV, https://arxiv.org/abs/1802.02611,
work page internal anchor Pith review Pith/arXiv arXiv 2018
- [25]
- [26]
-
[27]
Active Shape Models-Their Training and Application, Computer Vision and Image Understanding, 61, 1, 38- 59, 1995, 1077-3142, https://doi.org/10.1006/cviu.1995.1004, https://www.sciencedirect.com/science/article/pii/S1077314285710041, T.F. Cootes and C.J. Taylor and D.H. Cooper and J. Graham,
-
[28]
Fast Edge Detection Using Structured Forests
Fast Edge Detection Using Structured Forests, Piotr Doll ´ar and C. Lawrence Zitnick, 2014, 1406.5549, arXiv, cs.CV, https://arxiv.org/abs/1406.5549,
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[29]
Canny, John, IEEE Transactions on Pattern Analysis and Ma- chine Intelligence, A Computational Approach to Edge Detection, 1986, PAMI-8, 6, 679-698, Image edge detection;Detectors;Machine vision;Shape measurement;Performance analysis;Uncertainty;Gaussian approximation;Signal to noise ratio;Signal synthesis;Feature extrac- tion;Edge detection;feature extra...
-
[30]
article, Sobel, Irwin and Feldman, Gary, 1973, 01, 271-272, A 3×3 isotropic gradient operator for image processing, Pattern Classification and Scene Analysis
work page 1973
-
[31]
Topological structural analysis of digitized binary images by border following, Computer Vision, Graphics, and Image Processing, 30, 1, 32- 46, 1985, 0734-189X, https://doi.org/10.1016/0734-189X(85)90016-7, https://www.sciencedirect.com/science/article/pii/0734189X85900167, Satoshi Suzuki and KeiichiA be,
-
[32]
FCN-Transformer Feature Fusion for Polyp Segmentation, ISBN=9783031120534, 1611-3349, http://dx.doi.org/10.1007/978- 3-031-12053-4 65, 10.1007/978-3-031-12053-4 65, bookMedical Image Understanding and Analysis, publisher=Springer International Publishing, Sanderson, Edward and Matuszewski, Bogdan J., 2022, 892–907
-
[33]
and Abolmaesumi, Purang and Stoyanov, Danail and Mateus, Diana and Zuluaga, Maria A
”Fan, Deng-Ping and Ji, Ge-Peng and Zhou, Tao and Chen, Geng and Fu, Huazhu and Shen, Jianbing and Shao, Ling”, editor=”Martel, Anne L. and Abolmaesumi, Purang and Stoyanov, Danail and Mateus, Diana and Zuluaga, Maria A. and Zhou, S. Kevin and Racoceanu, Daniel and Joskowicz, Leo”, ”PraNet: Parallel Reverse Attention Network for Polyp Segmentation”, book”...
work page 2020
-
[34]
HarDNet-DFUS: An Enhanced Harmonically-Connected Network for Diabetic Foot Ulcer Image Segmentation and Colonoscopy Polyp Seg- mentation, Ting-Yu Liao and Ching-Hui Yang and Yu-Wen Lo and Kuan- Ying Lai and Po-Huai Shen and Youn-Long Lin, 2022, 2209.07313, arXiv, eess.IV, https://arxiv.org/abs/2209.07313,
-
[35]
He, Jianzhong and Zhang, Shiliang and Yang, Ming and Shan, Yanhu and Huang, Tiejun, IEEE Transactions on Pattern Analy- sis and Machine Intelligence, BDCN: Bi-Directional Cascade Net- work for Perceptual Edge Detection, 2022, 44, 1, 100-113, Im- age edge detection;Task analysis;Bidirectional control;Fuses;Image seg- mentation;Feature extraction;Convolutio...
-
[36]
U-Net: Convolutional Networks for Biomedical Image Segmentation, Olaf Ronneberger and Philipp Fischer and Thomas Brox, 2015, 1505.04597, arXiv, cs.CV, https://arxiv.org/abs/1505.04597
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[37]
Holistically-Nested Edge Detection, Saining Xie and Zhuowen Tu, 2015, 1504.06375, arXiv, cs.CV, https://arxiv.org/abs/1504.06375,
work page internal anchor Pith review Pith/arXiv arXiv 2015
- [38]
- [39]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.