Recognition: no theorem link
"Tab, Tab, Bug": Security Pitfalls of Next Edit Suggestions in AI-Integrated IDEs
Pith reviewed 2026-05-16 06:50 UTC · model grok-4.3
The pith
Next Edit Suggestions in AI IDEs expand context retrieval in ways that enable poisoning attacks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
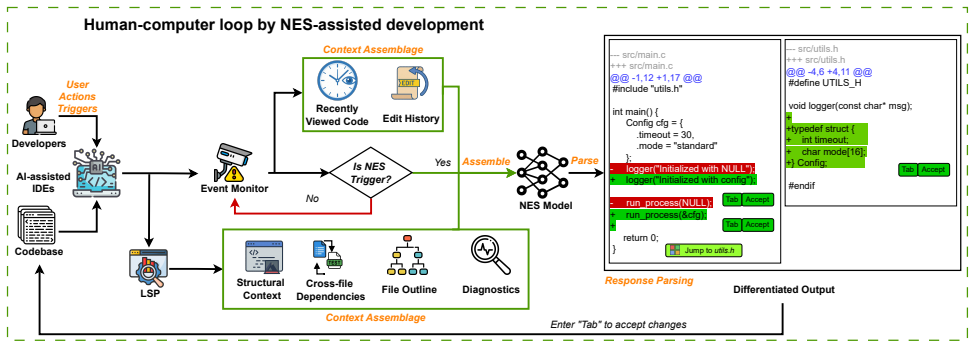
NES systems retrieve significantly expanded context from recent interactions and global codebase to suggest modifications, which exposes them to context poisoning attacks. They prove sensitive to transactional edits and human-IDE interactions. Professional developers generally lack awareness of these security pitfalls.
What carries the argument
The context retrieval mechanism in NES, which incorporates imperceptible user actions and broader codebase data to generate proactive edit suggestions.
If this is right
- Attackers can poison the context to insert vulnerable or malicious code via NES suggestions.
- Transactional edits can be manipulated to trigger unintended suggestions.
- Human interactions with the IDE create additional vectors for exploitation.
- Improved security countermeasures are required in AI-integrated IDEs.
Where Pith is reading between the lines
- Real-world deployment of NES might amplify these risks beyond lab settings due to larger codebases.
- Integration with version control could propagate poisoned suggestions across teams.
- Similar vulnerabilities may exist in other proactive AI coding features.
Load-bearing premise
The in-lab attack scenarios and survey responses accurately reflect real-world attacker capabilities and developer behavior without significant bias.
What would settle it
Demonstrating that NES in production AI IDEs resists context poisoning attempts under realistic conditions or finding that most developers are aware of the risks would falsify the central claims.
Figures




read the original abstract
Modern AI-integrated IDEs are shifting from passive code completion to proactive Next Edit Suggestions (NES). Unlike traditional autocompletion, NES is designed to construct a richer context from both recent user interactions and the broader codebase to suggest multi-line, cross-line, or even cross-file modifications. This evolution significantly streamlines the programming workflow into a tab-by-tab interaction and enhances developer productivity. Consequently, NES introduces a more complex context retrieval mechanism and sophisticated interaction patterns. However, existing studies focus almost exclusively on the security implications of standalone LLM-based code generation, ignoring the potential attack vectors posed by NES in modern AI-integrated IDEs. The underlying mechanisms of NES remain under-explored, and their security implications are not yet fully understood. In this paper, we conduct the first systematic security study of NES systems. First, we perform an in-depth dissection of the NES mechanisms to understand the newly introduced threat vectors. It is found that NES retrieves a significantly expanded context, including inputs from imperceptible user actions and global codebase retrieval, which increases the attack surfaces. Second, we conduct a comprehensive in-lab study to evaluate the security implications of NES. The evaluation results reveal that NES is susceptible to context poisoning and is sensitive to transactional edits and human-IDE interactions. Third, we perform a large-scale online survey involving over 200 professional developers to assess the perceptions of NES security risks in real-world development workflows. The survey results indicate a general lack of awareness regarding the potential security pitfalls associated with NES, highlighting the need for increased education and improved security countermeasures in AI-integrated IDEs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to present the first systematic security study of Next Edit Suggestions (NES) in AI-integrated IDEs. It dissects NES mechanisms to identify expanded context retrieval from imperceptible user actions and global codebase retrieval as new attack surfaces, reports an in-lab study demonstrating susceptibility to context poisoning along with sensitivity to transactional edits and human-IDE interactions, and presents results from a survey of over 200 professional developers indicating low awareness of these risks.
Significance. If the empirical findings hold after addressing methodological gaps, the work would be significant for the security of emerging AI coding tools. It identifies proactive, multi-line suggestion systems as introducing distinct threat vectors beyond those in standalone LLM code generation, and the combination of mechanism analysis, attack demonstrations, and developer perception data could inform both defensive designs and user education in AI-integrated IDEs.
major comments (2)
- [§4] §4 (in-lab study): The evaluation provides no details on experimental controls, statistical methods, or quantitative attack success rates for the context-poisoning scenarios, leaving the central claim of susceptibility only partially supported by the described mechanisms.
- [§5] §5 (survey): The methodology for the >200-developer survey does not address selection bias, response framing effects, or validation against real-world behavior, which undermines the load-bearing claim of general lack of awareness in development workflows.
minor comments (2)
- The abstract and introduction could more explicitly delineate the scope limitations of the in-lab attacks relative to closed-source production NES engines.
- Figure captions describing NES context retrieval would benefit from explicit callouts to the imperceptible-action and global-codebase components.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which helps strengthen the empirical components of our work. We address each major comment below and will revise the manuscript to provide the requested methodological details.
read point-by-point responses
-
Referee: [§4] §4 (in-lab study): The evaluation provides no details on experimental controls, statistical methods, or quantitative attack success rates for the context-poisoning scenarios, leaving the central claim of susceptibility only partially supported by the described mechanisms.
Authors: We agree that §4 would benefit from greater transparency. In the revised version we will add a new subsection detailing the experimental controls (including baseline conditions without poisoning, fixed IDE configurations, and isolation of user actions), the statistical methods used (descriptive statistics supplemented by significance testing where appropriate), and quantitative attack success rates (e.g., success percentages across repeated trials for each poisoning vector). These additions will directly support the susceptibility claims with concrete numbers and controls. revision: yes
-
Referee: [§5] §5 (survey): The methodology for the >200-developer survey does not address selection bias, response framing effects, or validation against real-world behavior, which undermines the load-bearing claim of general lack of awareness in development workflows.
Authors: We acknowledge these methodological gaps. The revised §5 will include: (1) a description of recruitment channels and demographic breakdown to address selection bias, (2) an explanation of question phrasing and piloting steps taken to reduce framing effects, and (3) an explicit limitations paragraph noting the absence of direct behavioral validation while clarifying that the survey is intended as indicative evidence of awareness levels rather than definitive proof. These changes will improve the robustness of the awareness findings. revision: yes
Circularity Check
Empirical security study with no derivations or self-referential reductions
full rationale
The paper conducts a security analysis of Next Edit Suggestions through mechanism dissection, in-lab attack evaluations, and a developer survey. No mathematical equations, fitted parameters, predictions derived from inputs, or load-bearing self-citations are present in the described work. Central claims rest directly on the reported experimental observations and survey data rather than any chain that reduces to its own definitions or prior author results by construction. This is a standard empirical study whose validity depends on experimental design and external generalizability, not internal circularity.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption NES retrieves significantly expanded context from imperceptible user actions and global codebase retrieval
Reference graph
Works this paper leans on
-
[1]
Bonnie Brinton Anderson, C. Brock Kirwan, Jeffrey L. Jenkins, David Eargle, Seth Howard, and Anthony Vance. How polymorphic warnings reduce habituation in the brain: Insights from an fmri study. InProceedings of the 33rd Annual ACM Conference on Human Factors in Computing Systems. Association for Computing Ma- chinery, 2015.doi:10.1145/2702123.2702322
-
[2]
Efficient training of language models to fill in the middle, 2022
Mohammad Bavarian, Heewoo Jun, Nikolas Tezak, John Schulman, Christine McLeavey, Jerry Tworek, and Mark Chen. Efficient training of language models to fill in the middle, 2022. URL: https://arxiv.org/abs/2207 .14255,arXiv:2207.14255
-
[3]
Purple llama cyberseceval: A secure coding benchmark for language models, 2023
Manish Bhatt, Sahana Chennabasappa, Cyrus Niko- laidis, Shengye Wan, Ivan Evtimov, Dominik Gabi, Daniel Song, Faizan Ahmad, Cornelius Aschermann, Lorenzo Fontana, Sasha Frolov, Ravi Prakash Giri, Dhaval Kapil, Yiannis Kozyrakis, David LeBlanc, James Milazzo, Aleksandar Straumann, Gabriel Synnaeve, Varun V ontimitta, Spencer Whitman, and Joshua Saxe. Purpl...
-
[4]
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde de Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brock- man, Alex Ray, Raul Puri, Gretchen Krueger, Michael Petrov, Heidy Khlaaf, Girish Sastry, Pamela Mishkin, Brooke Chan, Scott Gray, Nick Ryder, Mikhail Pavlov, Alethea Power, Lukasz Kaiser, Mohammad Bavari...
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[5]
An efficient and adaptive next edit suggestion framework with zero human instructions in ides, 2025
Xinfang Chen, Siyang Xiao, Xianying Zhu, Junhong Xie, Ming Liang, Dajun Chen, Wei Jiang, Yong Li, and Peng Di. An efficient and adaptive next edit suggestion framework with zero human instructions in ides, 2025. URL: https://arxiv.org/abs/2508.02473 , arXi v:2508.02473
-
[6]
Windsurf - the best ai for coding.https: //windsurf.com/, 2024
Cognition, Inc. Windsurf - the best ai for coding.https: //windsurf.com/, 2024. Accessed: 2025-12-17
work page 2024
- [7]
-
[8]
Cursor issue: Cursor ai view code leak
Cursor. Cursor issue: Cursor ai view code leak. https: //forum.cursor.com/t/big-security-risk-cur sorignore-doesnt-seem-to-work-envs-files -being-sent-as-context/14027 , 2025. Accessed 2025-12-17
work page 2025
-
[9]
Cursor. Cursor issue: Cursor keeps trying to access sensitive env variables even though .env is ignored.http s://forum.cursor.com/t/cursor-keeps-tryin g-to-access-sensitive-env-variables-even-t hough-env-is-ignored/145607 , 2025. Accessed 2025-12-17
work page 2025
-
[10]
Cursor issue: Cursor reads .env even though it is on .cursorignore
Cursor. Cursor issue: Cursor reads .env even though it is on .cursorignore. https://forum.cursor.com/t /cursor-reads-env-even-though-it-is-on-cur sorignore/136998, 2025. Accessed 2025-12-17
work page 2025
-
[11]
Questions on .gitignore, .cursorignore, .cursor- ban
Cursor. Questions on .gitignore, .cursorignore, .cursor- ban. https://forum.cursor.com/t/questions -on-gitignore-cursorignore-cursorban/34713 ,
-
[12]
Neal Dickert and Christine Grady. What’s the price of a research subject? approaches to payment for research participation.The New England journal of medicine,
-
[13]
URL: https://api.semanticscholar.org/ CorpusID:45204547
-
[14]
GitHub, Inc. Code scanning with codeql. https://co deql.github.com/, 2021. Accessed 2025-12-17
work page 2021
-
[15]
Github copilot · your ai pair programmer
GitHub, Inc. Github copilot · your ai pair programmer. https://github.com/features/copilot , 2024. Accessed 2025-12-17
work page 2024
-
[16]
Introducing github copilot agent mode (preview)
GitHub, Inc. Introducing github copilot agent mode (preview). https://code.visualstudio.com/blog s/2025/02/24/introducing-copilot-agent-mod e, 2025. Accessed 2025-12-17
work page 2025
-
[17]
Tree-sitter: An incremental parsing system for programming tools
GitHub, Inc. Tree-sitter: An incremental parsing system for programming tools. https://github.com/tre e-sitter/tree-sitter, 2026. Accessed 2025-12-17
work page 2026
-
[18]
Daya Guo, Qihao Zhu, Dejian Yang, Zhenda Xie, Kai Dong, Wentao Zhang, Guanting Chen, Xiao Bi, Y . Wu, Y . K. Li, Fuli Luo, Yingfei Xiong, and Wenfeng Liang. Deepseek-coder: When the large language model meets programming – the rise of code intelligence, 2024. URL: https://arxiv.org/abs/2401.14196, arXiv:2401 .14196
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[19]
Jason Huang, Paul Curran, Jessica Keeney, Elizabeth Poposki, and Richard DeShon. Detecting and deterring 14 insufficient effort responding to surveys.Journal of Business and Psychology, 2012. doi:10.1007/s108 69-011-9231-8
-
[20]
Qwen2.5-Coder Technical Report
Binyuan Hui, Jian Yang, Zeyu Cui, Jiaxi Yang, Dayi- heng Liu, Lei Zhang, Tianyu Liu, Jiajun Zhang, Bowen Yu, Keming Lu, Kai Dang, Yang Fan, Yichang Zhang, An Yang, Rui Men, Fei Huang, Bo Zheng, Yibo Miao, Shanghaoran Quan, Yunlong Feng, Xingzhang Ren, Xu- ancheng Ren, Jingren Zhou, and Junyang Lin. Qwen2.5- coder technical report, 2024. URL: https://arxiv...
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [21]
-
[22]
https://survey.stackoverflow.co/2025/a i, 2025. Accessed 2025-12-17
work page 2025
-
[23]
How Secure is Code Generated by ChatGPT?
Raphaël Khoury, Anderson R. Avila, Jacob Brunelle, and Baba Mamadou Camara. How secure is code gen- erated by chatgpt?, 2023. URL: https://arxiv.org/ abs/2304.09655,arXiv:2304.09655
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[24]
Jon A. Krosnick. Response strategies for coping with the cognitive demands of attitude measures in surveys. Applied Cognitive Psychology, 1991. URL: https: //onlinelibrary.wiley.com/doi/abs/10.1002/ acp.2350050305,doi:10.1002/acp.2350050305
-
[25]
Starcoder: may the source be with you!Transac- tions on Machine Learning Research, 2023
Raymond Li, Loubna Ben allal, Yangtian Zi, Niklas Muennighoff, Denis Kocetkov, Chenghao Mou, Marc Marone, Christopher Akiki, Jia LI, Jenny Chim, Qian Liu, Evgenii Zheltonozhskii, Terry Yue Zhuo, Thomas Wang, Olivier Dehaene, Joel Lamy-Poirier, Joao Mon- teiro, Nicolas Gontier, Ming-Ho Yee, Logesh Kumar Umapathi, Jian Zhu, Ben Lipkin, Muhtasham Oblokulov, ...
work page 2023
-
[26]
J. Lin. Divergence measures based on the shannon entropy.IEEE Transactions on Information Theory, 1991.doi:10.1109/18.61115
-
[27]
Chris J. Maddison and Daniel Tarlow. Structured gener- ative models of natural source code. InProceedings of the 31st International Conference on International Con- ference on Machine Learning - Volume 32, ICML’14,
-
[28]
URL:https://arxiv.org/abs/1401.0514
work page internal anchor Pith review Pith/arXiv arXiv
-
[29]
Adam Meade and Bart Craig. Identifying careless re- sponses in survey data.Psychological Methods, 17:437– 455, 04 2012.doi:10.1037/a0028085
-
[30]
Microsoft. Language server protocol. https://micr osoft.github.io/language-server-protocol/ ,
-
[31]
Accessed: 2025-12-17
work page 2025
-
[32]
Visual studio code intellisense
Microsoft. Visual studio code intellisense. https: //code.visualstudio.com/docs/editing/intel lisense, 2025. Accessed: 2025-12-17
work page 2025
-
[33]
Sanghak Oh, Kiho Lee, Seonhye Park, Doowon Kim, and Hyoungshick Kim. Poisoned ChatGPT Finds Work for Idle Hands: Exploring Developers’ Coding Practices with Insecure Suggestions from Poisoned AI Models . In2024 IEEE Symposium on Security and Privacy (SP),
-
[34]
org/10.1109/SP54263.2024.00046
URL: https://doi.ieeecomputersociety. org/10.1109/SP54263.2024.00046
-
[35]
OpenAI. Introducing codex. https://openai.c om/index/introducing-codex/ , 2025. Accessed: 2025-12-17
work page 2025
-
[36]
Oppenheimer, Tom Meyvis, and Nicolas Davidenko
Daniel M. Oppenheimer, Tom Meyvis, and Nicolas Davidenko. Instructional manipulation checks: De- tecting satisficing to increase statistical power.Jour- nal of Experimental Social Psychology, 2009. URL: https://www.sciencedirect.com/science/arti cle/pii/S0022103109000766 , doi:10.1016/j.je sp.2009.03.009
-
[37]
Long Ouyang, Jeff Wu, Xu Jiang, Diogo Almeida, Car- roll L. Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, John Schulman, Jacob Hilton, Fraser Kelton, Luke Miller, Maddie Simens, Amanda Askell, Peter Welinder, Paul Christiano, Jan Leike, and Ryan Lowe. Training lan- guage models to follow instructions with human feed-...
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[38]
Xml external entity (xxe) pro- cessing, 2024
OWASP Foundation. Xml external entity (xxe) pro- cessing, 2024. Accessed: 2025-12-17. URL: https: //owasp.org/www-community/vulnerabilities/X ML_External_Entity_(XXE)_Processing
work page 2024
-
[39]
Asleep at the key- board? assessing the security of github copilot’s code contributions
Hammond Pearce, Baleegh Ahmad, Benjamin Tan, Bren- dan Dolan-Gavitt, and Ramesh Karri. Asleep at the key- board? assessing the security of github copilot’s code contributions. In2022 IEEE Symposium on Security and Privacy (SP), pages 754–768. IEEE Computer Society,
- [40]
-
[41]
The Impact of AI on Developer Productivity: Evidence from GitHub Copilot
Sida Peng, Eirini Kalliamvakou, Peter Cihon, and Mert Demirer. The impact of ai on developer productivity: Evidence from github copilot, 2023. URL: https:// arxiv.org/abs/2302.06590,arXiv:2302.06590
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[42]
Neil Perry, Megha Srivastava, Deepak Kumar, and Dan Boneh. Do users write more insecure code with ai assistants? InProceedings of the 2023 ACM SIGSAC Conference on Computer and Communications Security, 2023.doi:10.1145/3576915.3623157
-
[43]
Lost at c: a user study on the security implications of large language model code assistants
Gustavo Sandoval, Hammond Pearce, Teo Nys, Ramesh Karri, Siddharth Garg, and Brendan Dolan-Gavitt. Lost at c: a user study on the security implications of large language model code assistants. InProceedings of the 32nd USENIX Conference on Security Symposium, 2023. URL: https://dl.acm.org/doi/10.5555/3620237 .3620361
-
[44]
You autocomplete me: Poisoning vul- nerabilities in neural code completion
Roei Schuster, Congzheng Song, Eran Tromer, and Vi- taly Shmatikov. You autocomplete me: Poisoning vul- nerabilities in neural code completion. In30th USENIX Security Symposium (USENIX Security 21), 2021. URL: https://www.usenix.org/conference/usenixse curity21/presentation/schuster
work page 2021
-
[45]
Guy Stecklov, Alex Weinreb, and Gero Carletto. Can incentives improve survey data quality in developing countries?: Results from a field experiment in india. Journal of the Royal Statistical Society: Series A (Statis- tics in Society), 2017.doi:10.1111/rssa.12333
-
[46]
TRAE. Trae: The real ai engineer. https://www.trae .ai/, 2025. Accessed 2025-12-17
work page 2025
-
[47]
Gomez, Łukasz Kaiser, and Illia Polosukhin
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. In Proceedings of the 31st International Conference on Neural Information Processing Systems, NIPS’17, page 6000–6010, 2017. URL: https://dl.acm.org/doi /10.5555/3295222.3295349
-
[48]
Zed - code at the speed of thought
Zed Industries. Zed - code at the speed of thought. https://github.com/zed-industries/zed , 2024. Accessed: 2025-12-17
work page 2024
-
[49]
Zed Industries. Zeta. https://huggingface.co/zed -industries/zeta, 2024. Accessed: 2025-12-17. A Detection Logic for Insecure NES Sugges- tions To systematically validate the security risks in NES sugges- tions, we developed a detection framework that combines automated pattern matching with semantic analysis. Table 4 summarizes the specific code patterns...
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.