Recognition: no theorem link
VLRS-Bench: A Vision-Language Reasoning Benchmark for Remote Sensing
Pith reviewed 2026-05-16 08:03 UTC · model grok-4.3
The pith
VLRS-Bench is the first benchmark built exclusively for complex vision-language reasoning in remote sensing.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
VLRS-Bench is the first benchmark exclusively dedicated to complex RS reasoning, structured across the three core dimensions of Cognition, Decision, and Prediction, comprising 2000 question-answer pairs with an average question length of 130.19 words, spanning 14 tasks and up to eight temporal phases, and constructed via a specialized pipeline that integrates RS-specific priors and expert knowledge to ensure geospatial realism and reasoning complexity.
What carries the argument
The specialized pipeline that integrates RS-specific priors and expert knowledge to generate realistic, multi-phase questions across Cognition, Decision, and Prediction dimensions.
If this is right
- Current state-of-the-art MLLMs encounter significant performance bottlenecks when handling complex RS reasoning tasks.
- The benchmark supplies a concrete testbed for measuring progress on cognitively demanding remote sensing applications.
- Insights from model failures on the 14 tasks can direct targeted improvements in multimodal reasoning for geospatial data.
- The three-dimension structure enables systematic comparison of model capabilities in cognition versus decision-making versus prediction.
Where Pith is reading between the lines
- The expert-knowledge pipeline used here could be adapted to create similar reasoning benchmarks in other image-heavy domains such as medical or environmental monitoring.
- Fine-tuning models on VLRS-Bench questions may improve their ability to handle temporal sequences in real satellite data streams.
- Extending the benchmark with additional sensor types or geographic regions would test whether the observed bottlenecks generalize beyond the current data distribution.
Load-bearing premise
The specialized pipeline that integrates RS-specific priors and expert knowledge produces questions with genuine geospatial realism and reasoning complexity.
What would settle it
An evaluation in which current state-of-the-art MLLMs achieve accuracy rates on VLRS-Bench comparable to their scores on simple perception benchmarks would show that the claimed reasoning bottlenecks do not exist.
Figures
























read the original abstract
Recent advancements in Multimodal Large Language Models (MLLMs) have enabled complex reasoning. However, existing remote sensing (RS) benchmarks remain heavily biased toward perception tasks, such as object recognition and scene classification. This limitation hinders the development of MLLMs for cognitively demanding RS applications. To address this, we propose a Vision Language ReaSoning Benchmark (VLRS-Bench), which is the first benchmark exclusively dedicated to complex RS reasoning. Structured across the three core dimensions of Cognition, Decision, and Prediction, VLRS-Bench comprises 2,000 question-answer pairs with an average question length of 130.19 words, spanning 14 tasks and up to eight temporal phases. VLRS-Bench is constructed via a specialized pipeline that integrates RS-specific priors and expert knowledge to ensure geospatial realism and reasoning complexity. Experimental results reveal significant bottlenecks in existing state-of-the-art MLLMs, providing critical insights for advancing multimodal reasoning within the remote sensing community. The project repository is available at https://github.com/MiliLab/VLRS-Bench.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces VLRS-Bench, presented as the first benchmark exclusively for complex vision-language reasoning in remote sensing. It contains 2,000 QA pairs (average question length 130.19 words) spanning 14 tasks across Cognition, Decision, and Prediction dimensions, with up to eight temporal phases. The benchmark is built via a specialized pipeline that incorporates RS-specific priors and expert knowledge to achieve geospatial realism and reasoning complexity. Experiments on state-of-the-art MLLMs demonstrate significant performance bottlenecks, and the dataset and code are released at the provided GitHub repository.
Significance. If the benchmark's questions demonstrably require multi-step geospatial reasoning rather than extended perception, VLRS-Bench would address a clear gap in existing RS-VQA resources and supply a reusable testbed for advancing MLLM capabilities in cognitively demanding remote-sensing applications. The public release of the 2,000 QA pairs and associated code supports immediate community use and reproducibility.
major comments (3)
- [§3] §3 (Benchmark Construction): The claim that the specialized pipeline produces questions with genuine multi-step geospatial reasoning and high complexity rests on the integration of RS priors and expert knowledge, yet the manuscript provides no quantitative validation such as average required inference steps per question, expert-rated reasoning-depth scores, or inter-annotator agreement on complexity labels. Without these metrics, it remains unclear whether the 2,000 pairs exceed the reasoning demands of prior RS-VQA datasets.
- [§4] §4 (Experiments) and Table 2: The reported MLLM bottlenecks are presented as evidence of the benchmark's utility, but the evaluation lacks a direct head-to-head comparison of reasoning-step counts or error types against existing RS benchmarks; this weakens the assertion that VLRS-Bench uniquely exposes limitations in complex reasoning rather than in longer-form perception.
- [§2.2] §2.2 (Related Work): The positioning of VLRS-Bench as the first exclusive complex-RS-reasoning benchmark requires a more systematic tabulation of reasoning depth (e.g., number of inference hops) across prior datasets; the current qualitative contrast is insufficient to support the exclusivity claim.
minor comments (2)
- [Abstract] The average question length is stated as 130.19 words; please also report the standard deviation and range to characterize length variability.
- [Figure 1] Figure 1 (pipeline diagram) would benefit from explicit annotation of the expert-knowledge injection points and the filtering criteria applied to generated questions.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We address each major point below and describe the revisions we will incorporate to strengthen the manuscript.
read point-by-point responses
-
Referee: [§3] §3 (Benchmark Construction): The claim that the specialized pipeline produces questions with genuine multi-step geospatial reasoning and high complexity rests on the integration of RS priors and expert knowledge, yet the manuscript provides no quantitative validation such as average required inference steps per question, expert-rated reasoning-depth scores, or inter-annotator agreement on complexity labels. Without these metrics, it remains unclear whether the 2,000 pairs exceed the reasoning demands of prior RS-VQA datasets.
Authors: We agree that explicit quantitative validation would strengthen the presentation. In the revised manuscript we will add a dedicated analysis subsection that reports (i) the average number of inference steps per question, obtained via expert annotation on a stratified sample of 200 questions, (ii) mean expert-rated reasoning-depth scores on a 1–5 scale, and (iii) inter-annotator agreement (Cohen’s κ) for both step counts and complexity labels. These additions will directly demonstrate that VLRS-Bench questions require more multi-step geospatial reasoning than prior RS-VQA resources. revision: yes
-
Referee: [§4] §4 (Experiments) and Table 2: The reported MLLM bottlenecks are presented as evidence of the benchmark's utility, but the evaluation lacks a direct head-to-head comparison of reasoning-step counts or error types against existing RS benchmarks; this weakens the assertion that VLRS-Bench uniquely exposes limitations in complex reasoning rather than in longer-form perception.
Authors: We acknowledge that a quantitative head-to-head comparison of reasoning-step counts would be ideal. Because existing RS-VQA datasets lack compatible step-level annotations, a fully quantitative comparison is not feasible without re-annotating those corpora. In the revision we will therefore add (i) a qualitative error analysis contrasting failure modes on VLRS-Bench versus a sampled subset of RSVQA and RS-VQA, and (ii) a discussion of why longer question length and multi-phase temporal structure in VLRS-Bench shift the performance bottleneck from perception to reasoning. We believe this addresses the core concern while remaining within the limits of available annotations. revision: partial
-
Referee: [§2.2] §2.2 (Related Work): The positioning of VLRS-Bench as the first exclusive complex-RS-reasoning benchmark requires a more systematic tabulation of reasoning depth (e.g., number of inference hops) across prior datasets; the current qualitative contrast is insufficient to support the exclusivity claim.
Authors: We will expand §2.2 with a new comparison table that systematically tabulates estimated reasoning depth (number of inference hops) for all cited prior RS-VQA datasets, derived from their published task definitions and example questions. The table will also list average question length and presence of temporal or multi-step elements, thereby providing a quantitative basis for the claim that VLRS-Bench is the first benchmark exclusively focused on complex RS reasoning. revision: yes
Circularity Check
No circularity: benchmark construction paper without derivations, fits, or self-referential claims
full rationale
The paper introduces VLRS-Bench as a new dataset of 2,000 QA pairs constructed via a specialized pipeline that incorporates RS priors and expert knowledge. No equations, parameter fitting, or predictive derivations are present that could reduce to inputs by construction. The 'first benchmark exclusively dedicated to complex RS reasoning' claim is a novelty assertion resting on comparison to prior perception-focused RS-VQA datasets rather than any self-citation chain or definitional loop. The pipeline description and experimental results on MLLM bottlenecks constitute independent content; the GitHub release provides external artifacts. No patterns from the enumerated circularity kinds apply.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Choice: Benchmarking the remote sensing capabilities of large vision-language models
Xiao An, Jiaxing Sun, Zihan Gui, and Wei He. Choice: Benchmarking the remote sensing capabilities of large vision-language models. InThe Thirty-ninth Annual Con- ference on Neural Information Processing Systems Datasets and Benchmarks Track, 2025. 2, 3
work page 2025
-
[2]
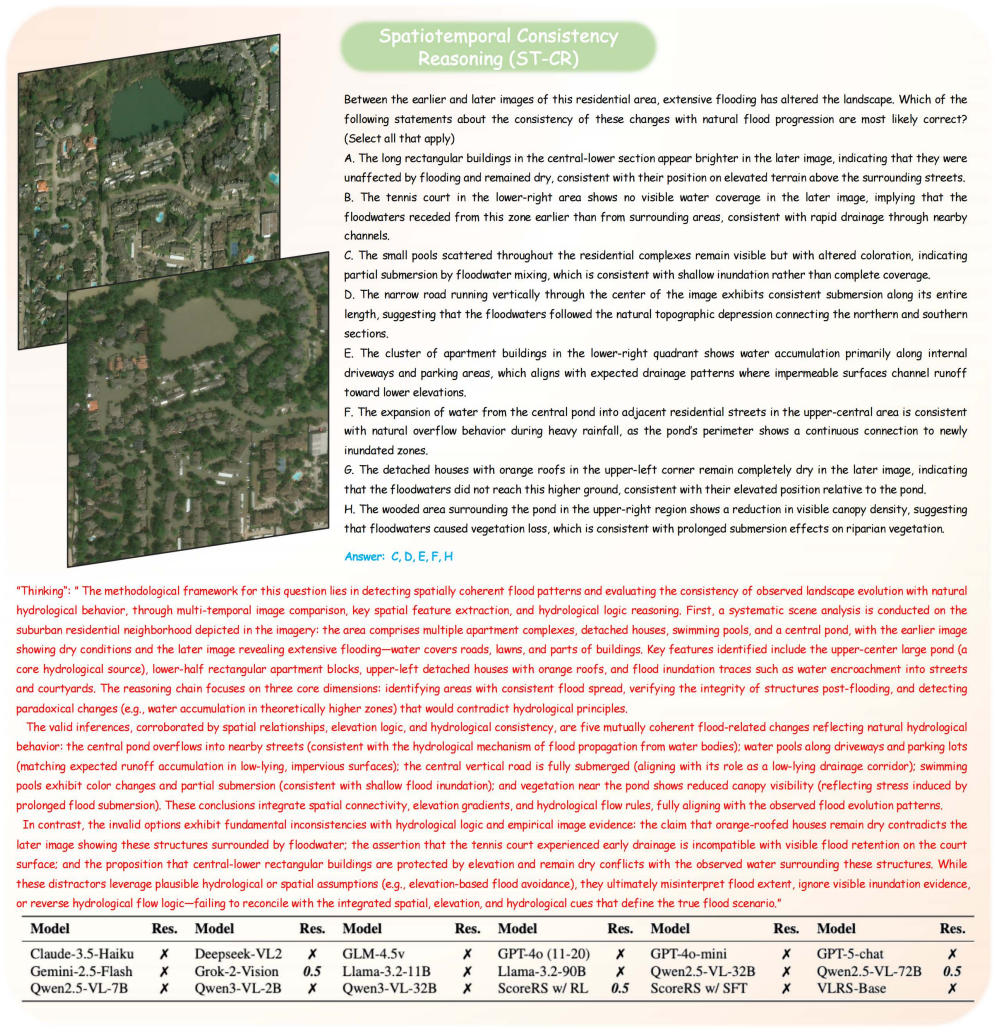
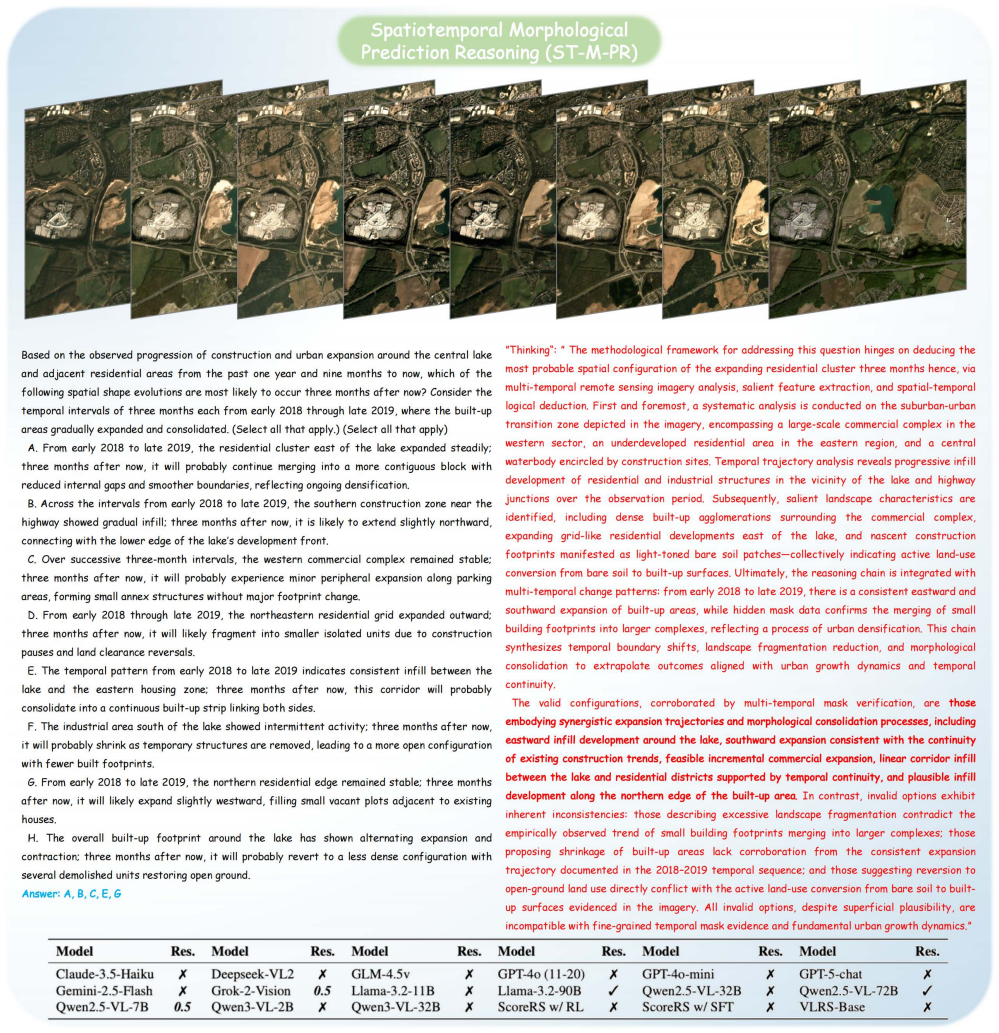
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, et al. Qwen2. 5-vl technical report.arXiv preprint arXiv:2502.13923, 2025. 6
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Dota 2 with Large Scale Deep Reinforcement Learning
Christopher Berner, Greg Brockman, Brooke Chan, Vicki Cheung, Przemysław D˛ ebiak, Christy Dennison, David Farhi, Quirin Fischer, Shariq Hashme, Chris Hesse, et al. Dota 2 with large scale deep reinforcement learning.arXiv preprint arXiv:1912.06680, 2019. 5
work page internal anchor Pith review Pith/arXiv arXiv 1912
-
[4]
Towards injecting medical vi- sual knowledge into multimodal llms at scale
Junying Chen, Chi Gui, Ruyi Ouyang, Anningzhe Gao, Shu- nian Chen, Guiming Hardy Chen, Xidong Wang, Zhenyang Cai, Ke Ji, Xiang Wan, et al. Towards injecting medical vi- sual knowledge into multimodal llms at scale. InProceed- ings of the 2024 conference on empirical methods in natural language processing, pages 7346–7370, 2024. 2
work page 2024
-
[5]
Are We on the Right Way for Evaluating Large Vision-Language Models?
Lin Chen, Jinsong Li, Xiaoyi Dong, Pan Zhang, Yuhang Zang, Zehui Chen, Haodong Duan, Jiaqi Wang, Yu Qiao, Dahua Lin, et al. Are we on the right way for evaluating large vision-language models?arXiv preprint arXiv:2403.20330,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Noveen Sachdeva, Inderjit Dhillon, Marcel Blis- tein, Ori Ram, Dan Zhang, Evan Rosen, et al. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities.arXiv preprint arXiv:2507.06261, 2025. 6
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[7]
Geobench-vlm: Benchmarking vision-language models for geospatial tasks
Muhammad Danish, Muhammad Akhtar Munir, Syed Roshaan Ali Shah, Kartik Kuckreja, Fahad Shahbaz Khan, Paolo Fraccaro, Alexandre Lacoste, and Salman Khan. Geobench-vlm: Benchmarking vision-language models for geospatial tasks. InProceedings of the IEEE/CVF Interna- tional Conference on Computer Vision, pages 7132–7142,
-
[8]
Xinpeng Ding, Jianhua Han, Hang Xu, Wei Zhang, and Xi- aomeng Li. Hilm-d: Enhancing mllms with multi-scale high- resolution details for autonomous driving.International Journal of Computer Vision, pages 1–17, 2025. 2
work page 2025
-
[9]
The llama 3 herd of models.arXiv e-prints, pages arXiv–2407,
Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Ab- hishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Amy Yang, Angela Fan, et al. The llama 3 herd of models.arXiv e-prints, pages arXiv–2407,
-
[10]
Adam Van Etten, Dave Lindenbaum, and Todd M. Bacas- tow. Spacenet: A remote sensing dataset and challenge se- ries, 2019. 5
work page 2019
-
[11]
Excerpt from datasheets for datasets
Timnit Gebru, Jamie Morgenstern, Briana Vecchione, Jen- nifer Wortman Vaughan, Hanna Wallach, Hal Daumé, and Kate Crawford. Excerpt from datasheets for datasets. In Ethics of Data and Analytics, pages 148–156. Auerbach Pub- lications, 2022. 21
work page 2022
-
[12]
ChatGLM: A Family of Large Language Models from GLM-130B to GLM-4 All Tools
Team GLM, Aohan Zeng, Bin Xu, Bowen Wang, Chenhui Zhang, Da Yin, Dan Zhang, Diego Rojas, Guanyu Feng, Hanlin Zhao, et al. Chatglm: A family of large language models from glm-130b to glm-4 all tools.arXiv preprint arXiv:2406.12793, 2024. 6
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[13]
Creating xbd: A dataset for assessing building damage from satellite imagery
Ritwik Gupta, Bryce Goodman, Nirav Patel, Ricky Hosfelt, Sandra Sajeev, Eric Heim, Jigar Doshi, Keane Lucas, Howie Choset, and Matthew Gaston. Creating xbd: A dataset for assessing building damage from satellite imagery. InPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, 2019. 5
work page 2019
-
[14]
Foundation models for remote sensing: An analysis of mllms for object localization
Darryl Hannan, John Cooper, Dylan White, Timothy Doster, Henry Kvinge, and Yijing Watkins. Foundation models for remote sensing: An analysis of mllms for object localization. InProceedings of the Computer Vision and Pattern Recogni- tion Conference, pages 3028–3037, 2025. 2
work page 2025
-
[15]
Yuan Hu, Jianlong Yuan, Congcong Wen, Xiaonan Lu, Yu Liu, and Xiang Li. Rsgpt: A remote sensing vision language model and benchmark.ISPRS Journal of Photogrammetry and Remote Sensing, 224:272–286, 2025. 1, 2, 3
work page 2025
-
[16]
Xijie Huang, Xinyuan Wang, Hantao Zhang, Yinghao Zhu, Jiawen Xi, Jingkun An, Hao Wang, Hao Liang, and Cheng- wei Pan. Medical mllm is vulnerable: Cross-modality jail- break and mismatched attacks on medical multimodal large language models. InProceedings of the AAAI Conference on Artificial Intelligence, pages 3797–3805, 2025. 2
work page 2025
-
[17]
Aaron Hurst, Adam Lerer, Adam P Goucher, Adam Perel- man, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Weli- hinda, Alan Hayes, Alec Radford, et al. Gpt-4o system card. arXiv preprint arXiv:2410.21276, 2024. 6
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[18]
Scaling up visual and vision-language representa- tion learning with noisy text supervision
Chao Jia, Yinfei Yang, Ye Xia, Yi-Ting Chen, Zarana Parekh, Hieu Pham, Quoc Le, Yun-Hsuan Sung, Zhen Li, and Tom Duerig. Scaling up visual and vision-language representa- tion learning with noisy text supervision. InInternational conference on machine learning, pages 4904–4916. PMLR,
-
[19]
Cognitive computational neuroscience.Nature neuroscience, 21(9): 1148–1160, 2018
Nikolaus Kriegeskorte and Pamela K Douglas. Cognitive computational neuroscience.Nature neuroscience, 21(9): 1148–1160, 2018. 2
work page 2018
-
[20]
Geochat: Grounded large vision-language model for remote sensing
Kartik Kuckreja, Muhammad Sohail Danish, Muzammal Naseer, Abhijit Das, Salman Khan, and Fahad Shahbaz Khan. Geochat: Grounded large vision-language model for remote sensing. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 27831– 27840, 2024. 2, 3
work page 2024
-
[21]
Seed-bench: Bench- marking multimodal large language models
Bohao Li, Yuying Ge, Yixiao Ge, Guangzhi Wang, Rui Wang, Ruimao Zhang, and Ying Shan. Seed-bench: Bench- marking multimodal large language models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pat- tern Recognition (CVPR), pages 13299–13308, 2024. 3
work page 2024
-
[22]
Ke Li, Gang Wan, Gong Cheng, Liqiu Meng, and Junwei Han. Object detection in optical remote sensing images: A survey and a new benchmark.ISPRS journal of photogram- metry and remote sensing, 159:296–307, 2020. 5
work page 2020
-
[23]
Hrvqa: A visual question answering benchmark for high-resolution aerial images, 2023
Kun Li, George V osselman, and Michael Ying Yang. Hrvqa: A visual question answering benchmark for high-resolution aerial images, 2023. 3 9
work page 2023
-
[24]
Xiang Li, Jian Ding, and Mohamed Elhoseiny. Vrsbench: A versatile vision-language benchmark dataset for remote sens- ing image understanding.Advances in Neural Information Processing Systems, 37:3229–3242, 2024. 2, 3
work page 2024
-
[25]
Microsoft coco: Common objects in context
Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Dollár, and C Lawrence Zitnick. Microsoft coco: Common objects in context. In European conference on computer vision, pages 740–755. Springer, 2014. 2
work page 2014
-
[26]
Chenyang Liu, Keyan Chen, Haotian Zhang, Zipeng Qi, Zhengxia Zou, and Zhenwei Shi. Change-agent: Toward interactive comprehensive remote sensing change interpre- tation and analysis.IEEE Transactions on Geoscience and Remote Sensing, 62:1–16, 2024. 3
work page 2024
-
[27]
Visual instruction tuning, 2023
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning, 2023. 2
work page 2023
-
[28]
Yuan Liu, Haodong Duan, Yuanhan Zhang, Bo Li, Songyang Zhang, Wangbo Zhao, Yike Yuan, Jiaqi Wang, Conghui He, Ziwei Liu, et al. Mmbench: Is your multi-modal model an all-around player? InEuropean conference on computer vi- sion, pages 216–233. Springer, 2024. 3
work page 2024
-
[29]
Rsvqa: Visual question answering for remote sensing data
Sylvain Lobry, Diego Marcos, Jesse Murray, and Devis Tuia. Rsvqa: Visual question answering for remote sensing data. IEEE Transactions on Geoscience and Remote Sensing, 58 (12):8555–8566, 2020. 2, 3
work page 2020
-
[30]
DeepSeek-VL: Towards Real-World Vision-Language Understanding
Haoyu Lu, Wen Liu, Bo Zhang, Bingxuan Wang, Kai Dong, Bo Liu, Jingxiang Sun, Tongzheng Ren, Zhuoshu Li, Hao Yang, et al. Deepseek-vl: towards real-world vision- language understanding.arXiv preprint arXiv:2403.05525,
work page internal anchor Pith review Pith/arXiv arXiv
-
[31]
Junwei Luo, Zhen Pang, Yongjun Zhang, Tingzhu Wang, Linlin Wang, Bo Dang, Jiangwei Lao, Jian Wang, Jingdong Chen, Yihua Tan, et al. Skysensegpt: A fine-grained in- struction tuning dataset and model for remote sensing vision- language understanding.arXiv preprint arXiv:2406.10100,
-
[32]
Lhrs-bot: Empowering remote sensing with vgi-enhanced large multimodal language model
Dilxat Muhtar, Zhenshi Li, Feng Gu, Xueliang Zhang, and Pengfeng Xiao. Lhrs-bot: Empowering remote sensing with vgi-enhanced large multimodal language model. InECCV (74), pages 440–457, 2024. 2, 3
work page 2024
-
[33]
Quality-driven curation of remote sensing vision-language data via learned scoring models
Dilxat Muhtar, Enzhuo Zhang, Zhenshi Li, Feng Gu, Yanglangxing He, Pengfeng Xiao, and Xueliang Zhang. Quality-driven curation of remote sensing vision-language data via learned scoring models. InThe Thirty-ninth An- nual Conference on Neural Information Processing Systems,
- [34]
-
[35]
Vhm: Versatile and honest vision language model for remote sensing image analysis
Chao Pang, Xingxing Weng, Jiang Wu, Jiayu Li, Yi Liu, Ji- axing Sun, Weijia Li, Shuai Wang, Litong Feng, Gui-Song Xia, et al. Vhm: Versatile and honest vision language model for remote sensing image analysis. InProceedings of the AAAI Conference on Artificial Intelligence, pages 6381– 6388, 2025. 3
work page 2025
-
[36]
Learning transferable visual models from natural language supervi- sion
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervi- sion. InInternational conference on machine learning, pages 8748–8763. PmLR, 2021. 2
work page 2021
-
[37]
Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks
Nils Reimers and Iryna Gurevych. Sentence-bert: Sentence embeddings using siamese bert-networks.arXiv preprint arXiv:1908.10084, 2019. 6
work page internal anchor Pith review Pith/arXiv arXiv 1908
-
[38]
Franz Rottensteiner, Gunho Sohn, Jaewook Jung, Markus Gerke, Caroline Baillard, Sebastien Benitez, and Uwe Bre- itkopf. The isprs benchmark on urban object classifica- tion and 3d building reconstruction.Göttingen: Copernicus GmbH, 2012. 5
work page 2012
-
[39]
Geopixel: Pixel grounding large multimodal model in remote sens- ing
Akashah Shabbir, Mohammed Zumri, Mohammed Ben- namoun, Fahad Shahbaz Khan, and Salman Khan. Geopixel: Pixel grounding large multimodal model in remote sens- ing. InForty-second International Conference on Machine Learning, 2025. 3
work page 2025
-
[40]
Earthdial: Turning multi-sensory earth observations to interactive dialogues
Sagar Soni, Akshay Dudhane, Hiyam Debary, Mustansar Fiaz, Muhammad Akhtar Munir, Muhammad Sohail Danish, Paolo Fraccaro, Campbell D Watson, Levente J Klein, Fa- had Shahbaz Khan, et al. Earthdial: Turning multi-sensory earth observations to interactive dialogues. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 14303–14313, 2025. 3
work page 2025
-
[41]
Xian Sun, Peijin Wang, Zhiyuan Yan, Feng Xu, Ruiping Wang, Wenhui Diao, Jin Chen, Jihao Li, Yingchao Feng, Tao Xu, et al. Fair1m: A benchmark dataset for fine- grained object recognition in high-resolution remote sens- ing imagery.ISPRS Journal of Photogrammetry and Remote Sensing, 184:116–130, 2022. 5
work page 2022
-
[42]
Forms of prediction in the nervous system.Nature Reviews Neuroscience, 21(4): 231–242, 2020
Christoph Teufel and Paul C Fletcher. Forms of prediction in the nervous system.Nature Reviews Neuroscience, 21(4): 231–242, 2020. 2
work page 2020
-
[43]
Hi- ucd: A large-scale dataset for urban semantic change detec- tion in remote sensing imagery, 2020
Shiqi Tian, Ailong Ma, Zhuo Zheng, and Yanfei Zhong. Hi- ucd: A large-scale dataset for urban semantic change detec- tion in remote sensing imagery, 2020. 5
work page 2020
-
[44]
Xin-Yi Tong, Gui-Song Xia, Qikai Lu, Huangfeng Shen, Shengyang Li, Shucheng You, and Liangpei Zhang. Land- cover classification with high-resolution remote sensing im- ages using transferable deep models.Remote Sensing of En- vironment, doi: 10.1016/j.rse.2019.111322, 2020. 5
-
[45]
Di Wang, Qiming Zhang, Yufei Xu, Jing Zhang, Bo Du, Dacheng Tao, and Liangpei Zhang. Advancing plain vision transformer toward remote sensing foundation model.IEEE Transactions on Geoscience and Remote Sensing, 61:1–15,
-
[46]
Di Wang, Jing Zhang, Bo Du, Minqiang Xu, Lin Liu, Dacheng Tao, and Liangpei Zhang. Samrs: Scaling-up re- mote sensing segmentation dataset with segment anything model.Advances in Neural Information Processing Systems, 36:8815–8827, 2023. 5
work page 2023
-
[47]
Fengxiang Wang, Mingshuo Chen, Yueying Li, Di Wang, Haotian Wang, Zonghao Guo, Zefan Wang, Boqi Shan, Long Lan, Yulin Wang, et al. Geollava-8k: Scaling remote-sensing multimodal large language models to 8k resolution.arXiv preprint arXiv:2505.21375, 2025. 1, 3
-
[48]
Fengxiang Wang, Hongzhen Wang, Zonghao Guo, Di Wang, Yulin Wang, Mingshuo Chen, Qiang Ma, Long Lan, Wenjing Yang, Jing Zhang, et al. Xlrs-bench: Could your multimodal 10 llms understand extremely large ultra-high-resolution remote sensing imagery? InProceedings of the Computer Vision and Pattern Recognition Conference, pages 14325–14336,
-
[49]
Loveda: A remote sensing land-cover dataset for domain adaptive semantic segmentation
Junjue Wang, Zhuo Zheng, Xiaoyan Lu, Yanfei Zhong, et al. Loveda: A remote sensing land-cover dataset for domain adaptive semantic segmentation. InThirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 2). 5
-
[50]
Junjue Wang, Zhuo Zheng, Zihang Chen, Ailong Ma, and Yanfei Zhong. Earthvqa: Towards queryable earth via re- lational reasoning-based remote sensing visual question an- swering. InProceedings of the AAAI conference on artificial intelligence, pages 5481–5489, 2024. 2, 3
work page 2024
-
[51]
Gpt-4v (ision) is a human-aligned evaluator for text-to-3d genera- tion
Tong Wu, Guandao Yang, Zhibing Li, Kai Zhang, Ziwei Liu, Leonidas Guibas, Dahua Lin, and Gordon Wetzstein. Gpt-4v (ision) is a human-aligned evaluator for text-to-3d genera- tion. InProceedings of the IEEE/CVF conference on com- puter vision and pattern recognition, pages 22227–22238,
-
[52]
Grok-2 vision (grok-1212), 2024
xAI. Grok-2 vision (grok-1212), 2024. Accessed: 2025-07-
work page 2024
-
[53]
Dota: A large-scale dataset for object detection in aerial images
Gui-Song Xia, Xiang Bai, Jian Ding, Zhen Zhu, Serge Be- longie, Jiebo Luo, Mihai Datcu, Marcello Pelillo, and Liang- pei Zhang. Dota: A large-scale dataset for object detection in aerial images. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 3974–3983,
-
[54]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025. 6
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[55]
Semantic change detection with asymmetric siamese networks, 2021
Kunping Yang, Gui-Song Xia, Zicheng Liu, Bo Du, Wen Yang, Marcello Pelillo, and Liangpei Zhang. Semantic change detection with asymmetric siamese networks, 2021. 5
work page 2021
-
[56]
Rsvg: Exploring data and models for visual grounding on remote sensing data
Yang Zhan, Zhitong Xiong, and Yuan Yuan. Rsvg: Exploring data and models for visual grounding on remote sensing data. IEEE Transactions on Geoscience and Remote Sensing, 61: 1–13, 2023. 3
work page 2023
-
[57]
Rsvg: Exploring data and models for visual grounding on remote sensing data
Yang Zhan, Zhitong Xiong, and Yuan Yuan. Rsvg: Exploring data and models for visual grounding on remote sensing data. IEEE Transactions on Geoscience and Remote Sensing, 61: 1–13, 2023. 2, 3
work page 2023
-
[58]
Vldrive: Vision-augmented lightweight mllms for efficient language- grounded autonomous driving
Ruifei Zhang, Wei Zhang, Xiao Tan, Sibei Yang, Xi- ang Wan, Xiaonan Luo, and Guanbin Li. Vldrive: Vision-augmented lightweight mllms for efficient language- grounded autonomous driving. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 5923–5933, 2025. 2
work page 2025
-
[59]
Rsvlm-qa: A benchmark dataset for remote sensing vision language model-based question answering
Xing Zi, Jinghao Xiao, Yunxiao Shi, Xian Tao, Jun Li, Ali Braytee, and Mukesh Prasad. Rsvlm-qa: A benchmark dataset for remote sensing vision language model-based question answering. InProceedings of the 33rd ACM In- ternational Conference on Multimedia, pages 12905–12911,
-
[60]
The appendix is organized as follows: • Sec
Overview of the Appendix This appendix supplements the proposed VLRS-Bench with additional experimental results and details excluded from the main paper due to space constraints. The appendix is organized as follows: • Sec. 2: More Analysis of L-2 Tasks in VLRS-Bench. • Sec. 3: More Details of VLRS-Bench. • Sec. 4: VLRS-Bench Pipeline Details • Sec. 5: Vi...
-
[61]
More Analysis of L-1 and L-2 Dimensions in VLRS-Bench. To comprehensively evaluate the remote sensing reason- ing capabilities of various MLLMs within the VLRS-Bench framework, we extend our analysis to the aggregated L-1 and L-2 dimensions, uncovering macroscopic performance patterns that reveal the fundamental cognitive strengths and limitations of curr...
work page 2024
-
[62]
More details of VLRS-Bench This appendix section presents the statistical specifications of VLRS-Bench and provides comprehensive definitions for the fine-grained L-3 reasoning capabilities. 2 3.1. Configuration and Statistics of VLRS-Bench Table 2 provides a detailed overview of our proposed VLRS-Bench, the first benchmark specifically designed to evalua...
-
[63]
VLRS-Bench Pipeline Details 4.1. Data collection FAIR1M.FAIR1M is designed for fine-grained object recognition in high-resolution remote sensing imagery. It integrates data from the Gaofen satellite series and Google Earth, with a spatial resolution ranging from 0.3 m to 0.8 m. The dataset contains approximately 15,000 images and more than one million ann...
work page 2017
-
[64]
We present additional example of our VLRS-Bench in Fig- ure 10-23
Visualizations of Random Sampling Cases. We present additional example of our VLRS-Bench in Fig- ure 10-23. It can be seen that our VLRS-Bench poses great challenges to existing MLLMs. 5.1. Visualization Examples of Spatial Cognition (SC) As shown in Fig 10-13, SC tasks evaluate whether a model can transform a static remote sensing image into a coher- ent...
-
[65]
For what purpose was the dataset created?
Datasheets In this section, we document essential details about the proposed datasets and benchmarks following the CVPR Dataset and Benchmark guidelines and the template pro- vided by [11]. 6.1. Motivation The questions in this section are primarily intended to en- courage dataset creators to clearly articulate their reasons for creating the dataset and t...
-
[66]
Limitation and Potential Societal Impact In this section, we discuss the limitations and potential so- cietal impact of this work. 7.1. Potential Limitations WhileVLRS-Benchprovides a comprehensive benchmark for evaluating the reasoning capabilities of MLLMs in re- mote sensing, there are several limitations to consider: •Scope of Sensors:Although our ben...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.