Recognition: no theorem link
SQuTR: A Robustness Benchmark for Spoken Query to Text Retrieval under Acoustic Noise
Pith reviewed 2026-05-15 22:44 UTC · model grok-4.3
The pith
Even large-scale retrieval models struggle under extreme noise in spoken query to text retrieval.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
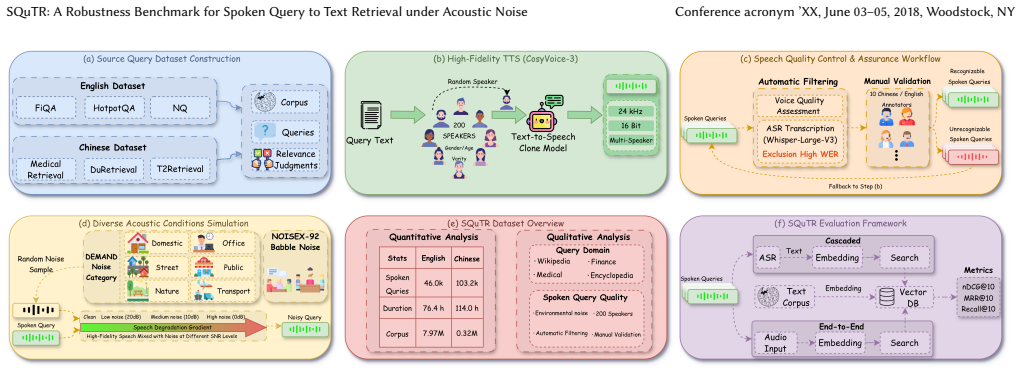
SQuTR aggregates 37,317 unique queries from six text retrieval datasets, synthesizes speech using 200 real speaker profiles, and mixes them with 17 categories of real-world environmental noise at controlled SNR levels. Under a unified evaluation protocol, representative cascaded and end-to-end retrieval systems show decreasing performance as noise increases, with substantially different drops across systems and even large-scale models struggling under extreme noise.
What carries the argument
The SQuTR benchmark dataset together with its speech synthesis from real voice profiles, noise mixing at fixed SNR levels, and unified evaluation protocol for cascaded and end-to-end systems.
If this is right
- Retrieval performance decreases as noise levels increase.
- Cascaded and end-to-end systems exhibit substantially different patterns of performance degradation.
- Large-scale retrieval models still struggle significantly under extreme noise.
- The benchmark enables reproducible robustness evaluation and diagnostic analysis across systems.
Where Pith is reading between the lines
- Voice search applications may require noise-robust training data or architectures to remain usable in typical settings like streets or offices.
- The benchmark could be extended to additional languages or query types to test broader applicability.
- Developers could use SQuTR results to prioritize robustness improvements before deploying spoken retrieval in noisy environments.
Load-bearing premise
The controlled synthesis of speech from text queries using real speaker profiles and the addition of recorded environmental noise at fixed SNR levels accurately represent the acoustic conditions users encounter in real spoken query scenarios.
What would settle it
Collecting real spoken queries from users in uncontrolled noisy environments and checking whether retrieval accuracy on those queries matches the drops observed on the SQuTR benchmark.
Figures




read the original abstract
Spoken query retrieval is an important interaction mode in modern information retrieval. However, existing evaluation datasets are often limited to simple queries under constrained noise conditions, making them inadequate for assessing the robustness of spoken query retrieval systems under complex acoustic perturbations. To address this limitation, we present SQuTR, a robustness benchmark for spoken query retrieval that includes a large-scale dataset and a unified evaluation protocol. SQuTR aggregates 37,317 unique queries from six commonly used English and Chinese text retrieval datasets, spanning multiple domains and diverse query types. We synthesize speech using voice profiles from 200 real speakers and mix 17 categories of real-world environmental noise under controlled SNR levels, enabling reproducible robustness evaluation from quiet to highly noisy conditions. Under the unified protocol, we conduct large-scale evaluations on representative cascaded and end-to-end retrieval systems. Experimental results show that retrieval performance decreases as noise increases, with substantially different drops across systems. Even large-scale retrieval models struggle under extreme noise, indicating that robustness remains a critical bottleneck. Overall, SQuTR provides a reproducible testbed for benchmarking and diagnostic analysis, and facilitates future research on robustness in spoken query to text retrieval.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces SQuTR, a robustness benchmark for spoken query to text retrieval. It aggregates 37,317 unique queries from six English and Chinese text retrieval datasets, synthesizes speech using voice profiles from 200 real speakers, and mixes the audio with 17 categories of real-world environmental noise at controlled SNR levels. Under a unified evaluation protocol, the authors test representative cascaded and end-to-end retrieval systems and report that performance degrades as noise increases, with large-scale models struggling under extreme noise; they conclude that robustness remains a critical bottleneck and position SQuTR as a reproducible testbed for future work.
Significance. If the controlled TTS-plus-additive-noise protocol is shown to be a faithful proxy for real spoken-query acoustics, the benchmark would supply a large-scale, reproducible diagnostic tool for identifying robustness failures across domains and model architectures. The scale (37k queries, 200 speakers, 17 noise categories) and cross-lingual coverage are strengths that could accelerate research on noise-resilient retrieval if the central modeling assumption holds.
major comments (2)
- [§3 (Dataset Construction) and §4 (Evaluation Protocol)] The central claim that 'robustness remains a critical bottleneck' rests on the assumption that performance drops under the SQuTR synthesis protocol (TTS from clean text + fixed-SNR additive noise) generalize to real user scenarios. The manuscript provides no validation experiments comparing synthesized queries against real spoken queries that include disfluencies, variable prosody, microphone distortion, or non-stationary overlapping noise; without such evidence the observed degradation may be an artifact of the synthesis method rather than a general robustness failure.
- [§5 (Experimental Results)] The abstract states that 'retrieval performance decreases as noise increases, with substantially different drops across systems' yet supplies no quantitative metrics, confidence intervals, or statistical tests. The full experimental section must report per-system, per-SNR numbers (e.g., nDCG or Recall@10) together with error bars and significance tests to substantiate the claim that even large-scale models 'struggle under extreme noise'.
minor comments (2)
- [§2 (Related Work) and §3] The abstract lists six source datasets but does not name them or provide citations; the main text should explicitly list the datasets (e.g., MS MARCO, Natural Questions, etc.) with their original references.
- [Figures in §5] Figure captions and axis labels for the noise-SNR plots should include the exact metric (e.g., nDCG@10) and the number of queries per condition to improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our manuscript. We address each major point below, indicating where revisions will be made to improve clarity and completeness while honestly noting limitations of the current work.
read point-by-point responses
-
Referee: [§3 (Dataset Construction) and §4 (Evaluation Protocol)] The central claim that 'robustness remains a critical bottleneck' rests on the assumption that performance drops under the SQuTR synthesis protocol (TTS from clean text + fixed-SNR additive noise) generalize to real user scenarios. The manuscript provides no validation experiments comparing synthesized queries against real spoken queries that include disfluencies, variable prosody, microphone distortion, or non-stationary overlapping noise; without such evidence the observed degradation may be an artifact of the synthesis method rather than a general robustness failure.
Authors: We agree that the benchmark relies on a controlled TTS-plus-additive-noise protocol and does not include direct validation against real spoken queries with disfluencies, variable prosody, microphone effects, or overlapping noise. This is a genuine limitation, as the paper focuses on reproducible, large-scale controlled evaluation rather than real-world data collection. We will add a dedicated limitations subsection in the revised manuscript to explicitly discuss this assumption, its scope, and the need for future real-world validation studies. revision: partial
-
Referee: [§5 (Experimental Results)] The abstract states that 'retrieval performance decreases as noise increases, with substantially different drops across systems' yet supplies no quantitative metrics, confidence intervals, or statistical tests. The full experimental section must report per-system, per-SNR numbers (e.g., nDCG or Recall@10) together with error bars and significance tests to substantiate the claim that even large-scale models 'struggle under extreme noise'.
Authors: We agree that the experimental results require more detailed quantitative reporting. In the revised version we will expand §5 with tables providing per-system and per-SNR values for nDCG@10 and Recall@10, include error bars (standard deviation across speaker groups or runs), and add statistical significance tests (paired t-tests with p-values) to support the degradation claims. These metrics exist in our experimental logs and will be presented clearly. revision: yes
- Validation experiments comparing synthesized queries to real spoken queries that include disfluencies, variable prosody, microphone distortion, or non-stationary overlapping noise
Circularity Check
No circularity: purely empirical benchmark construction
full rationale
The paper aggregates existing text queries, synthesizes speech via TTS using 200 real speaker profiles, mixes 17 real noise categories at fixed SNRs, and evaluates off-the-shelf retrieval systems under a unified protocol. No equations, fitted parameters, predictions, uniqueness theorems, or ansatzes appear. Central claims rest on direct performance measurements rather than any self-referential reduction. This is standard benchmark work with no load-bearing self-citation chains or definitional loops.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Synthesized speech from real speaker profiles mixed with recorded environmental noise at controlled SNR levels accurately simulates real-world spoken queries under acoustic perturbations.
Reference graph
Works this paper leans on
- [1]
- [2]
-
[3]
Payal Bajaj, Daniel Campos, Nick Craswell, Li Deng, Jianfeng Gao, Xiaodong Liu, Rangan Majumder, Andrew McNamara, Bhaskar Mitra, Tri Nguyen, Mir Rosenberg, Xia Song, Alina Stoica, Saurabh Tiwary, and Tong Wang. 2018. MS MARCO: A Human Generated MAchine Reading COmprehension Dataset. arXiv:1611.09268 [cs.CL] https://arxiv.org/abs/1611.09268
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[4]
Jon Barker, Ricard Marxer, Emmanuel Vincent, and Shinji Watanabe. 2015. The third ‘CHiME’speech separation and recognition challenge: Dataset, task and baselines. In2015 IEEE workshop on automatic speech recognition and understand- ing (ASRU). IEEE, 504–511
work page 2015
-
[5]
Jon Barker, Shinji Watanabe, Emmanuel Vincent, and Jan Trmal. 2018. The fifth ’CHiME’ Speech Separation and Recognition Challenge: Dataset, task and baselines. arXiv:1803.10609 [cs.SD] https://arxiv.org/abs/1803.10609 SQuTR: A Robustness Benchmark for Spoken Query to Text Retrieval under Acoustic Noise Conference acronym ’XX, June 03–05, 2018, Woodstock, NY
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[6]
Jianlv Chen, Shitao Xiao, Peitian Zhang, Kun Luo, Defu Lian, and Zheng Liu. 2024. Bge m3-embedding: Multi-lingual, multi-functionality, multi-granularity text embeddings through self-knowledge distillation.arXiv preprint arXiv:2402.03216 4, 5 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[7]
Dayan de França Costa and Nadia Felix Felipe da Silva. 2018. INF-UFG at FiQA 2018 task 1: Predicting sentiments and aspects on financial tweets and news headlines. InCompanion Proceedings of the The Web Conference 2018. 1967–1971
work page 2018
-
[8]
Zhihao Du, Changfeng Gao, Yuxuan Wang, Fan Yu, Tianyu Zhao, Hao Wang, Xiang Lv, Hui Wang, Chongjia Ni, Xian Shi, Keyu An, Guanrou Yang, Yabin Li, Yanni Chen, Zhifu Gao, Qian Chen, Yue Gu, Mengzhe Chen, Yafeng Chen, Shiliang Zhang, Wen Wang, and Jieping Ye. 2025. CosyVoice 3: Towards In-the-wild Speech Generation via Scaling-up and Post-training. arXiv:250...
work page internal anchor Pith review arXiv 2025
-
[9]
Benjamin Elizalde, Soham Deshmukh, Mahmoud Al Ismail, and Huaming Wang
-
[10]
arXiv:2206.04769 [cs.SD] https://arxiv.org/abs/2206.04769
CLAP: Learning Audio Concepts From Natural Language Supervision. arXiv:2206.04769 [cs.SD] https://arxiv.org/abs/2206.04769
- [11]
-
[12]
Georg Heigold, Ehsan Variani, Tom Bagby, Cyril Allauzen, Ji Ma, Shankar Kumar, and Michael Riley. [n. d.]. Massive Sound Embedding Benchmark (MSEB). In The Thirty-ninth Annual Conference on Neural Information Processing Systems Datasets and Benchmarks Track
-
[13]
Heeseung Kim, Che Hyun Lee, Sangkwon Park, Jiheum Yeom, Nohil Park, Sang- won Yu, and Sungroh Yoon. 2025. Does Your Voice Assistant Remember? Analyz- ing Conversational Context Recall and Utilization in Voice Interaction Models. arXiv:2502.19759 [cs.SD] https://arxiv.org/abs/2502.19759
-
[14]
Tom Kwiatkowski, Jennimaria Palomaki, Olivia Redfield, Michael Collins, Ankur Parikh, Chris Alberti, Danielle Epstein, Illia Polosukhin, Jacob Devlin, Kenton Lee, et al. 2019. Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics7 (2019), 453–466
work page 2019
-
[15]
Lin-shan Lee, James Glass, Hung-yi Lee, and Chun-an Chan. 2015. Spoken Content Retrieval—Beyond Cascading Speech Recognition with Text Retrieval. IEEE/ACM Transactions on Audio, Speech, and Language Processing23, 9 (2015), 1389–1420. doi:10.1109/TASLP.2015.2438543
-
[16]
Chyi-Jiunn Lin, Guan-Ting Lin, Yung-Sung Chuang, Wei-Lun Wu, Shang-Wen Li, Abdelrahman Mohamed, Hung-yi Lee, and Lin-Shan Lee. 2024. Speechdpr: End- to-end spoken passage retrieval for open-domain spoken question answering. In ICASSP 2024-2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 12476–12480
work page 2024
-
[17]
Jimmy Lin, Matt Crane, Andrew Trotman, Jamie Callan, Ishan Chattopadhyaya, John Foley, Grant Ingersoll, Craig Macdonald, and Sebastiano Vigna. 2016. Toward reproducible baselines: The open-source IR reproducibility challenge. InEuropean Conference on Information Retrieval. Springer, 408–420
work page 2016
-
[18]
Dingkun Long, Qiong Gao, Kuan Zou, Guangwei Xu, Pengjun Xie, Ruijie Guo, Jian Xu, Guanjun Jiang, Luxi Xing, and Ping Yang. 2022. Multi-cpr: A multi domain chinese dataset for passage retrieval. InProceedings of the 45th International ACM SIGIR Conference on Research and Development in Information Retrieval. 3046–3056
work page 2022
-
[19]
Do June Min, Karel Mundnich, Andy Lapastora, Erfan Soltanmohammadi, Srikanth Ronanki, and Kyu Han. 2025. Speech Retrieval-Augmented Gener- ation without Automatic Speech Recognition. InICASSP 2025 - 2025 IEEE In- ternational Conference on Acoustics, Speech and Signal Processing (ICASSP). 1–5. doi:10.1109/ICASSP49660.2025.10888900
-
[20]
Niklas Muennighoff, Nouamane Tazi, Loïc Magne, and Nils Reimers. 2023. Mteb: Massive text embedding benchmark. InProceedings of the 17th Conference of the European Chapter of the Association for Computational Linguistics. 2014–2037
work page 2023
-
[21]
Vassil Panayotov, Guoguo Chen, Daniel Povey, and Sanjeev Khudanpur. 2015. Librispeech: An ASR corpus based on public domain audio books. In2015 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). 5206–5210. doi:10.1109/ICASSP.2015.7178964
- [22]
- [23]
-
[24]
Alec Radford, Jong Wook Kim, Tao Xu, Greg Brockman, Christine McLeavey, and Ilya Sutskever. 2022. Robust Speech Recognition via Large-Scale Weak Supervision. arXiv:2212.04356 [eess.AS] https://arxiv.org/abs/2212.04356
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[25]
Stephen Robertson, Hugo Zaragoza, et al . 2009. The probabilistic relevance framework: BM25 and beyond.Foundations and trends®in information retrieval 3, 4 (2009), 333–389
work page 2009
-
[26]
Shah, David Solans Noguero, Mikko A
Muhammad A. Shah, David Solans Noguero, Mikko A. Heikkila, Bhiksha Raj, and Nicolas Kourtellis. 2024. Speech Robust Bench: A Robustness Benchmark For Speech Recognition. arXiv:2403.07937 [eess.AS] https://arxiv.org/abs/2403.07937
-
[27]
Xian Shi, Xiong Wang, Zhifang Guo, Yongqi Wang, Pei Zhang, Xinyu Zhang, Zishan Guo, Hongkun Hao, Yu Xi, Baosong Yang, et al . 2026. Qwen3-ASR Technical Report.arXiv preprint arXiv:2601.21337(2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
- [28]
-
[29]
Georgios Sidiropoulos, Svitlana Vakulenko, and Evangelos Kanoulas. 2022. On the impact of speech recognition errors in passage retrieval for spoken question answering. InProceedings of the 31st ACM International Conference on Information & Knowledge Management. 4485–4489
work page 2022
-
[30]
Nandan Thakur, Nils Reimers, Andreas Rücklé, Abhishek Srivastava, and Iryna Gurevych. 2021. Beir: A heterogenous benchmark for zero-shot evaluation of information retrieval models.arXiv preprint arXiv:2104.08663(2021)
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[31]
Joachim Thiemann, Nobutaka Ito, and Emmanuel Vincent. 2013. The diverse environments multi-channel acoustic noise database (demand): A database of multichannel environmental noise recordings. InProceedings of Meetings on Acoustics, Vol. 19. Acoustical Society of America, 035081
work page 2013
-
[32]
Christophe Van Gysel. 2023. Modeling spoken information queries for virtual assistants: Open problems, challenges and opportunities. InProceedings of the 46th International ACM SIGIR Conference on Research and Development in Information Retrieval. 3335–3338
work page 2023
-
[33]
Andrew Varga and Herman JM Steeneken. 1993. Assessment for automatic speech recognition: II. NOISEX-92: A database and an experiment to study the effect of additive noise on speech recognition systems.Speech communication12, 3 (1993), 247–251
work page 1993
-
[34]
Henrique Schechter Vera, Sahil Dua, Biao Zhang, Daniel Salz, Ryan Mullins, Sindhu Raghuram Panyam, Sara Smoot, Iftekhar Naim, Joe Zou, Feiyang Chen, et al. 2025. Embeddinggemma: Powerful and lightweight text representations. arXiv preprint arXiv:2509.20354(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [35]
-
[36]
Liang Wang, Nan Yang, Xiaolong Huang, Linjun Yang, Rangan Majumder, and Furu Wei. 2024. Multilingual e5 text embeddings: A technical report.arXiv preprint arXiv:2402.05672(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[37]
Wenhui Wang, Furu Wei, Li Dong, Hangbo Bao, Nan Yang, and Ming Zhou
-
[38]
Minilm: Deep self-attention distillation for task-agnostic compression of pre-trained transformers.Advances in neural information processing systems33 (2020), 5776–5788
work page 2020
-
[39]
Shinji Watanabe, Takaaki Hori, Shigeki Karita, Tomoki Hayashi, Jiro Nishitoba, Yuya Unno, Nelson Enrique Yalta Soplin, Jahn Heymann, Matthew Wiesner, Nanxin Chen, Adithya Renduchintala, and Tsubasa Ochiai. 2018. ESPnet: End- to-End Speech Processing Toolkit. InInterspeech 2018. 2207–2211. doi:10.21437/ Interspeech.2018-1456
work page 2018
-
[40]
Shitao Xiao, Zheng Liu, Peitian Zhang, Niklas Muennighoff, Defu Lian, and Jian-Yun Nie. 2024. C-pack: Packed resources for general chinese embeddings. InProceedings of the 47th international ACM SIGIR conference on research and development in information retrieval. 641–649
work page 2024
-
[41]
Xiaohui Xie, Qian Dong, Bingning Wang, Feiyang Lv, Ting Yao, Weinan Gan, Zhijing Wu, Xiangsheng Li, Haitao Li, Yiqun Liu, et al . 2023. T2ranking: A large-scale chinese benchmark for passage ranking. InProceedings of the 46th International ACM SIGIR Conference on Research and Development in Information Retrieval. 2681–2690
work page 2023
-
[42]
Mengyao Xu, Wenfei Zhou, Yauhen Babakhin, Gabriel Moreira, Ronay Ak, Radek Osmulski, Bo Liu, Even Oldridge, and Benedikt Schifferer. 2025. Omni-Embed- Nemotron: A Unified Multimodal Retrieval Model for Text, Image, Audio, and Video. arXiv:2510.03458 [cs.CL] https://arxiv.org/abs/2510.03458
-
[43]
Zhilin Yang, Peng Qi, Saizheng Zhang, Yoshua Bengio, William Cohen, Ruslan Salakhutdinov, and Christopher D Manning. 2018. HotpotQA: A dataset for diverse, explainable multi-hop question answering. InProceedings of the 2018 conference on empirical methods in natural language processing. 2369–2380
work page 2018
-
[44]
Aohan Zeng, Xin Lv, Qinkai Zheng, Zhenyu Hou, Bin Chen, Chengxing Xie, Cunxiang Wang, Da Yin, Hao Zeng, Jiajie Zhang, et al. 2025. Glm-4.5: Agentic, reasoning, and coding (arc) foundation models.arXiv preprint arXiv:2508.06471 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [45]
-
[46]
Qwen3 Embedding: Advancing Text Embedding and Reranking Through Foundation Models
Yanzhao Zhang, Mingxin Li, Dingkun Long, Xin Zhang, Huan Lin, Baosong Yang, Pengjun Xie, An Yang, Dayiheng Liu, Junyang Lin, et al. 2025. Qwen3 Embedding: Advancing Text Embedding and Reranking Through Foundation Models.arXiv preprint arXiv:2506.05176(2025). Conference acronym ’XX, June 03–05, 2018, Woodstock, NY Li et al. A Mathematical Formulation of Ac...
work page internal anchor Pith review Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.