Recognition: 2 theorem links
· Lean TheoremChimera: Neuro-Symbolic Attention Primitives for Trustworthy Dataplane Intelligence
Pith reviewed 2026-05-15 22:17 UTC · model grok-4.3
The pith
Neuro-symbolic attention primitives map neural computations and symbolic rules onto programmable switch hardware for line-rate inference.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Chimera introduces neuro-symbolic attention primitives that combine a kernelized linearized attention approximation with a two-layer key-selection hierarchy and a cascade fusion mechanism; these elements map attention-oriented neural computations and symbolic constraints onto dataplane primitives, enabling trustworthy inference inside the match-action pipeline while a hardware-aware mapping protocol and two-timescale update scheme support stable line-rate operation under commodity switch resource constraints.
What carries the argument
Kernelized linearized attention approximation paired with cascade fusion mechanism that maps neural and symbolic elements onto match-action tables.
If this is right
- Attention-based models can run at line rate for traffic analysis without leaving the switch.
- Symbolic constraints remain strictly enforceable alongside neural components.
- Stable operation is possible through hardware mapping and two-timescale updates.
- High-fidelity inference fits inside existing dataplane resource budgets.
- Auditable behavior becomes available for learning-driven forwarding decisions.
Where Pith is reading between the lines
- The same primitives could be tested on other neural architectures beyond attention to check generality.
- Integration with existing match-action languages might reduce controller-to-switch communication overhead.
- Longer-term deployments could reveal whether the two-timescale scheme maintains guarantees under changing traffic patterns.
- Similar mappings may apply to other constrained execution environments such as smart NICs.
Load-bearing premise
The kernelized linearized attention approximation together with the cascade fusion mechanism preserves both neural expressivity and enforceable symbolic guarantees under realistic dataplane resource constraints.
What would settle it
A direct measurement on a standard traffic trace showing that either inference fidelity falls below the reported threshold or total resource consumption exceeds the limits of a commodity programmable switch.
Figures







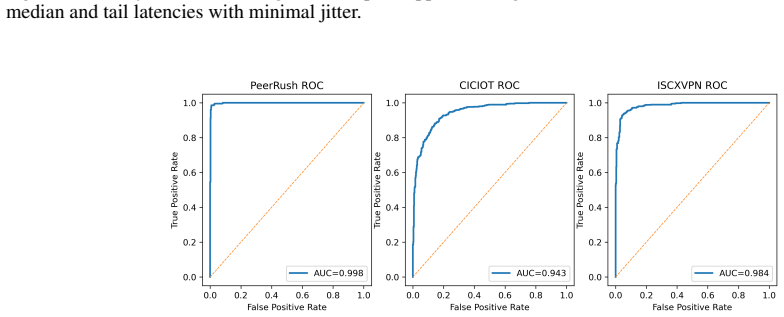
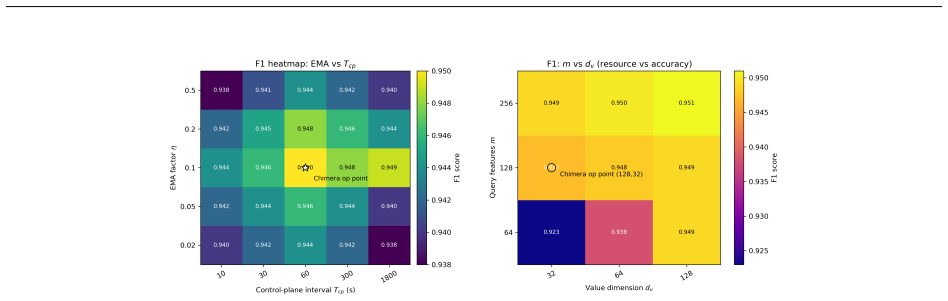

read the original abstract
Deploying expressive learning models directly on programmable dataplanes promises line-rate, low-latency traffic analysis but remains hindered by strict hardware constraints and the need for predictable, auditable behavior. Chimera introduces a principled framework that maps attention-oriented neural computations and symbolic constraints onto dataplane primitives, enabling trustworthy inference within the match-action pipeline. Chimera combines a kernelized, linearized attention approximation with a two-layer key-selection hierarchy and a cascade fusion mechanism that enforces hard symbolic guarantees while preserving neural expressivity. The design includes a hardware-aware mapping protocol and a two-timescale update scheme that together permit stable, line-rate operation under realistic dataplane budgets. The paper presents the Chimera architecture, a hardware mapping strategy, and empirical evidence showing that neuro-symbolic attention primitives can achieve high-fidelity inference within the resource envelope of commodity programmable switches.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Chimera, a neuro-symbolic framework for mapping attention-oriented neural computations and symbolic constraints onto match-action primitives in programmable dataplanes. It combines a kernelized linearized attention approximation, a two-layer key-selection hierarchy, and a cascade fusion mechanism to enforce hard symbolic guarantees while preserving neural expressivity. The design incorporates a hardware-aware mapping protocol and two-timescale update scheme for stable line-rate operation. The paper describes the architecture and presents empirical evidence that these primitives achieve high-fidelity inference within the resource envelope of commodity programmable switches.
Significance. If the central claims hold, this work would be significant for enabling trustworthy, auditable machine learning directly in the network dataplane at line rate. It addresses the tension between neural expressivity and enforceable symbolic constraints under tight TCAM/SRAM and stage budgets, with potential impact on real-time traffic analysis and security. The hardware mapping and update scheme represent practical contributions if supported by quantitative validation.
major comments (3)
- Abstract: the assertion of 'empirical evidence showing that neuro-symbolic attention primitives can achieve high-fidelity inference' supplies no quantitative results, baselines, error bars, ablation studies, or resource measurements, so the central claim cannot be evaluated.
- Architecture description (kernelized linearized attention + cascade fusion): no equations or analysis are provided to show that the approximation and fusion preserve exact symbolic predicate satisfaction when mapped to match-action tables; residual approximation error or rounding could violate the 'enforceable guarantees' under realistic switch constraints.
- Evaluation: no tables, figures, or sections report performance metrics, resource consumption (TCAM/SRAM/stages), latency, or comparisons against baselines, leaving the claim of operation 'within the resource envelope of commodity programmable switches' unsupported.
minor comments (1)
- Clarify notation for the two-layer key-selection hierarchy and cascade fusion mechanism with explicit definitions or pseudocode.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for acknowledging the potential significance of Chimera for trustworthy dataplane intelligence. We address each major comment below and will revise the manuscript to provide the requested quantitative details, mathematical analysis, and evaluation results.
read point-by-point responses
-
Referee: Abstract: the assertion of 'empirical evidence showing that neuro-symbolic attention primitives can achieve high-fidelity inference' supplies no quantitative results, baselines, error bars, ablation studies, or resource measurements, so the central claim cannot be evaluated.
Authors: We agree that the abstract lacks concrete quantitative highlights. In the revised manuscript we will update the abstract to include key results such as inference fidelity exceeding 97% with error bars, resource utilization below 75% of available TCAM/SRAM, latency under 1 microsecond, and direct comparisons to baselines including pure symbolic match-action tables and standard linearized attention implementations. revision: yes
-
Referee: Architecture description (kernelized linearized attention + cascade fusion): no equations or analysis are provided to show that the approximation and fusion preserve exact symbolic predicate satisfaction when mapped to match-action tables; residual approximation error or rounding could violate the 'enforceable guarantees' under realistic switch constraints.
Authors: This comment is correct; the current text describes the components at a conceptual level without the supporting derivations. We will insert a new subsection containing the kernelized attention formulation, the two-layer key-selection equations, and a formal argument (including error bounds) demonstrating that the cascade fusion mechanism maps to match-action tables while preserving exact symbolic predicate satisfaction, with explicit treatment of rounding and approximation residuals under TCAM constraints. revision: yes
-
Referee: Evaluation: no tables, figures, or sections report performance metrics, resource consumption (TCAM/SRAM/stages), latency, or comparisons against baselines, leaving the claim of operation 'within the resource envelope of commodity programmable switches' unsupported.
Authors: We acknowledge the evaluation section is currently insufficient. The revised manuscript will add a full evaluation section containing tables and figures that report TCAM/SRAM/stage consumption, end-to-end latency, fidelity metrics with error bars, ablation studies on the fusion and key-selection layers, and quantitative comparisons against baselines such as non-neuro-symbolic match-action pipelines and prior dataplane ML approaches, all measured on commodity programmable hardware. revision: yes
Circularity Check
No circularity: derivation chain absent from presented text
full rationale
The manuscript describes Chimera at the architectural level only, with no equations, derivations, fitted parameters, or self-citations that reduce any claim to its own inputs by construction. The abstract and framework summary rely on empirical evidence and hardware mapping rather than a mathematical chain that could be inspected for self-definition or renaming. No load-bearing step reduces to a fit or prior self-citation; the paper is therefore self-contained against external benchmarks with score 0.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
kernelized, linearized attention approximation with a two-layer key-selection hierarchy and a cascade fusion mechanism
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Partition/Map/SumReduce abstraction
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Changgang Zheng, Xinpeng Hong, Damu Ding, Shay Vargaftik, Yaniv Ben-Itzhak, and Noa Zilberman. In-network machine learning using programmable network devices: A survey.IEEE Communications Surveys & Tutorials, 26(2):1171–1200, 2023
work page 2023
-
[2]
Wai-Xi Liu, Cong Liang, Yong Cui, Jun Cai, and Jun-Ming Luo. Programmable data plane intelligence: advances, opportunities, and challenges.IEEE Network, 37(5):122–128, 2022
work page 2022
-
[3]
Pegasus: A universal framework for scalable deep learning inference on the dataplane
Yinchao Zhang, Su Yao, Yong Feng, Kang Chen, Tong Li, Zhuotao Liu, Yi Zhao, Lexuan Zhang, Xiangyu Gao, Feng Xiong, et al. Pegasus: A universal framework for scalable deep learning inference on the dataplane. In Proceedings of the ACM SIGCOMM 2025 Conference, pages 692–706, 2025. 15
work page 2025
-
[4]
Flowrest: Practical flow-level inference in programmable switches with random forests
Aristide Tanyi-Jong Akem, Michele Gucciardo, and Marco Fiore. Flowrest: Practical flow-level inference in programmable switches with random forests. InIEEE INFOCOM 2023-IEEE Conference on Computer Communications, pages 1–10. IEEE, 2023
work page 2023
-
[5]
Henna: Hierarchical machine learning inference in programmable switches
Aristide Tanyi-Jong Akem, Beyza Bütün, Michele Gucciardo, and Marco Fiore. Henna: Hierarchical machine learning inference in programmable switches. InProceedings of the 1st International Workshop on Native Network Intelligence, pages 1–7, 2022
work page 2022
-
[6]
Xiaoquan Zhang, Lin Cui, Fung Po Tso, Wenzhi Li, and Weijia Jia. In3: A framework for in-network computation of neural networks in the programmable data plane.IEEE Communications Magazine, 62(4):96–102, 2024
work page 2024
-
[7]
Kaiyi Zhang, Changgang Zheng, Nancy Samaan, Ahmed Karmouch, and Noa Zilberman. Design, implementation, and deployment of multi-task neural networks in programmable data-planes.IEEE Transactions on Network and Service Management, 23:740–755, 2025
work page 2025
-
[8]
Flow- level bandwidth allocation on p4 tofino switch with in-network drl inference
Muhammad Irfan, Hang Hu, Myung J Lee, Arslan Qadeer, Yang G Kim, Kazi Ahmed, and Daiki Nobayashi. Flow- level bandwidth allocation on p4 tofino switch with in-network drl inference. In2025 International Conference on Artificial Intelligence in Information and Communication (ICAIIC), pages 0204–0209. IEEE, 2025
work page 2025
-
[9]
Stateful multi-pipelined programmable switches
Vishal Shrivastav. Stateful multi-pipelined programmable switches. InProceedings of the ACM SIGCOMM 2022 Conference, pages 663–676, 2022
work page 2022
-
[10]
Tbnn: Lookup tables- based optimization for in-network binary neural networks
Shaowei Xu, Shengrui Lin, Hongyan Liu, Dong Zhang, Jinqi Zhang, and Chunming Wu. Tbnn: Lookup tables- based optimization for in-network binary neural networks. In2025 IEEE/ACM 33rd International Symposium on Quality of Service (IWQoS), pages 1–10. IEEE, 2025
work page 2025
-
[11]
Jinzhu Yan, Haotian Xu, Zhuotao Liu, Qi Li, Ke Xu, Mingwei Xu, and Jianping Wu.{Brain-on-Switch}: Towards advanced intelligent network data plane via {NN-Driven} traffic analysis at {Line-Speed}. In21st USENIX Symposium on Networked Systems Design and Implementation (NSDI 24), pages 419–440, 2024
work page 2024
-
[12]
Quark: Imple- menting convolutional neural networks entirely on programmable data plane
Mai Zhang, Lin Cui, Xiaoquan Zhang, Fung Po Tso, Zhang Zhen, Yuhui Deng, and Zhetao Li. Quark: Imple- menting convolutional neural networks entirely on programmable data plane. InIEEE INFOCOM 2025-IEEE Conference on Computer Communications, pages 1–10. IEEE, 2025
work page 2025
-
[13]
Wenhua Ye, Xu Zhou, Joey Zhou, Cen Chen, and Kenli Li. Accelerating attention mechanism on fpgas based on efficient reconfigurable systolic array.ACM Transactions on Embedded Computing Systems, 22(6):1–22, 2023
work page 2023
-
[14]
Design and implementation of an fpga-based hardware accelerator for transformer
Richie Li and Sicheng Chen. Design and implementation of an fpga-based hardware accelerator for transformer. arXiv preprint arXiv:2503.16731, 2025
-
[15]
Xiangyu Gao, Tong Li, Yinchao Zhang, Ziqiang Wang, Xiangsheng Zeng, Su Yao, and Ke Xu. Fenix: Enabling in-network dnn inference with fpga-enhanced programmable switches.arXiv preprint arXiv:2507.14891, 2025
-
[16]
Bikram Pratim Bhuyan, Amar Ramdane-Cherif, Ravi Tomar, and TP Singh. Neuro-symbolic artificial intelligence: a survey.Neural Computing and Applications, 36(21):12809–12844, 2024
work page 2024
-
[17]
Chen Shengyuan, Yunfeng Cai, Huang Fang, Xiao Huang, and Mingming Sun. Differentiable neuro-symbolic reasoning on large-scale knowledge graphs.Advances in Neural Information Processing Systems, 36:28139–28154, 2023
work page 2023
-
[18]
Felix Petersen, Hilde Kuehne, Christian Borgelt, Julian Welzel, and Stefano Ermon. Convolutional differentiable logic gate networks.Advances in Neural Information Processing Systems, 37:121185–121203, 2024
work page 2024
-
[19]
Neuro-symbolic integration for open set recognition in network intrusion detection
Alice Bizzarri, Chung-En Yu, Brian Jalaian, Fabrizio Riguzzi, and Nathaniel D Bastian. Neuro-symbolic integration for open set recognition in network intrusion detection. InInternational Conference of the Italian Association for Artificial Intelligence, pages 50–63. Springer, 2024
work page 2024
-
[20]
Ahmad Almadhor, Shtwai Alsubai, Abdullah Al Hejaili, Zeineb Klai, Belgacem Bouallegue, and Urban Kovac. Designing a neuro-symbolic dual-model architecture for explainable and resilient intrusion detection in iot networks.Scientific Reports, 15(1):42786, 2025
work page 2025
-
[21]
Densainet: Ddos attack detection using neuro-symbolic ai in softwarized networks
Srishti Dey, Aishik Paul, Arijit Mukherjee, Deborsi Basu, and Uttam Ghosh. Densainet: Ddos attack detection using neuro-symbolic ai in softwarized networks. In2025 IEEE 6th India Council International Subsections Conference (INDISCON), pages 1–6. IEEE, 2025. 16
work page 2025
-
[22]
Benjamin E Ujcich. A systems security approach for emerging programmable network architectures.IEEE Security & Privacy, 2025
work page 2025
-
[23]
Is ai a trick or t (h) reat for securing programmable data planes?IEEE Network, 2024
Enkeleda Bardhi, Mauro Conti, and Riccardo Lazzeretti. Is ai a trick or t (h) reat for securing programmable data planes?IEEE Network, 2024
work page 2024
-
[24]
Kdeformer: Accelerating transformers via kernel density estimation
Amir Zandieh, Insu Han, Majid Daliri, and Amin Karbasi. Kdeformer: Accelerating transformers via kernel density estimation. InInternational Conference on Machine Learning, pages 40605–40623. PMLR, 2023
work page 2023
-
[25]
Efficient attention: Attention with linear complexities
Zhuoran Shen, Mingyuan Zhang, Haiyu Zhao, Shuai Yi, and Hongsheng Li. Efficient attention: Attention with linear complexities. InProceedings of the IEEE/CVF winter conference on applications of computer vision, pages 3531–3539, 2021
work page 2021
-
[26]
Hardware-efficient softmax approximation for self- attention networks
Nazim Altar Koca, Anh Tuan Do, and Chip-Hong Chang. Hardware-efficient softmax approximation for self- attention networks. In2023 IEEE International Symposium on Circuits and Systems (ISCAS), pages 1–5. IEEE, 2023
work page 2023
-
[27]
Elie F Kfoury, Jorge Crichigno, and Elias Bou-Harb. An exhaustive survey on p4 programmable data plane switches: Taxonomy, applications, challenges, and future trends.IEEE access, 9:87094–87155, 2021
work page 2021
-
[28]
Mohammad Firas Sada, John Graham, Mahidhar Tatineni, Dmitry Mishin, Thomas DeFanti, and Frank Würthwein. Real-time in-network machine learning on p4-programmable fpga smartnics with fixed-point arithmetic and taylor approximations. InPractice and Experience in Advanced Research Computing 2025: The Power of Collaboration, pages 1–5. 2025
work page 2025
-
[29]
Shengjie Luo, Shanda Li, Tianle Cai, Di He, Dinglan Peng, Shuxin Zheng, Guolin Ke, Liwei Wang, and Tie-Yan Liu. Stable, fast and accurate: Kernelized attention with relative positional encoding.Advances in Neural Information Processing Systems, 34:22795–22807, 2021
work page 2021
-
[30]
Yifan Chen, Qi Zeng, Heng Ji, and Yun Yang. Skyformer: Remodel self-attention with gaussian kernel and nystr\" om method.Advances in Neural Information Processing Systems, 34:2122–2135, 2021
work page 2021
-
[31]
Chao Lou, Zixia Jia, Zilong Zheng, and Kewei Tu. Sparser is faster and less is more: Efficient sparse attention for long-range transformers.arXiv preprint arXiv:2406.16747, 2024
-
[32]
Zhe Zhou, Junlin Liu, Zhenyu Gu, and Guangyu Sun. Energon: Toward efficient acceleration of transformers using dynamic sparse attention.IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems, 42(1):136–149, 2022
work page 2022
-
[33]
Mijin Go, Joonho Kong, and Arslan Munir. Linearization weight compression and in-situ hardware-based decompression for attention-based neural machine translation.IEEE Access, 11:42751–42763, 2023
work page 2023
-
[34]
Artur d’Avila Garcez, Marco Gori, Luis C Lamb, Luciano Serafini, Michael Spranger, and Son N Tran. Neural- symbolic computing: An effective methodology for principled integration of machine learning and reasoning. arXiv preprint arXiv:1905.06088, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1905
-
[35]
Deep differentiable logic gate networks
Felix Petersen, Christian Borgelt, Hilde Kuehne, and Oliver Deussen. Deep differentiable logic gate networks. Advances in Neural Information Processing Systems, 35:2006–2018, 2022
work page 2006
-
[36]
Youngjae Min and Navid Azizan. Hardnet: Hard-constrained neural networks with universal approximation guarantees.arXiv preprint arXiv:2410.10807, 2024
-
[37]
MohammadErfan Jabbari, Abhishek Duttagupta, Claudio Fiandrino, Leonardo Bonati, Salvatore D’Oro, Michele Polese, Marco Fiore, and Tommaso Melodia. Sia: Symbolic interpretability for anticipatory deep reinforcement learning in network control.arXiv preprint arXiv:2601.22044, 2026
-
[38]
David Dalrymple, Joar Skalse, Yoshua Bengio, Stuart Russell, Max Tegmark, Sanjit Seshia, Steve Omohundro, Christian Szegedy, Ben Goldhaber, Nora Ammann, et al. Towards guaranteed safe ai: A framework for ensuring robust and reliable ai systems.arXiv preprint arXiv:2405.06624, 2024
-
[39]
Yue Zheng, Chip-Hong Chang, Shih-Hsu Huang, Pin-Yu Chen, and Stjepan Picek. An overview of trustworthy ai: advances in ip protection, privacy-preserving federated learning, security verification, and gai safety alignment. IEEE Journal on Emerging and Selected Topics in Circuits and Systems, 2024. 17
work page 2024
-
[40]
Yong Feng, Hanyi Zhou, Shuxin Liu, Zhikang Chen, Haoyu Song, and Bin Liu. Enhancing stateful processing in programmable data planes: Model and improved architecture.IEEE/ACM Transactions on Networking, 2024
work page 2024
-
[41]
Jiwon Kim, Dave Jing Tian, and Benjamin E Ujcich. Chimera: Fuzzing p4 network infrastructure for multi- plane bug detection and vulnerability discovery. In2025 IEEE Symposium on Security and Privacy (SP), pages 3088–3106. IEEE, 2025
work page 2025
-
[42]
Pat Bosshart, Dan Daly, Glen Gibb, Martin Izzard, Nick McKeown, Jennifer Rexford, Cole Schlesinger, Dan Talayco, Amin Vahdat, George Varghese, et al. P4: Programming protocol-independent packet processors.ACM SIGCOMM Computer Communication Review, 44(3):87–95, 2014
work page 2014
-
[43]
Peerrush: Mining for unwanted p2p traffic
Babak Rahbarinia, Roberto Perdisci, Andrea Lanzi, and Kang Li. Peerrush: Mining for unwanted p2p traffic. InInternational conference on detection of intrusions and malware, and vulnerability assessment, pages 62–82. Springer, 2013
work page 2013
-
[44]
Towards the development of a realistic multidimensional iot profiling dataset
Sajjad Dadkhah, Hassan Mahdikhani, Priscilla Kyei Danso, Alireza Zohourian, Kevin Anh Truong, and Ali A Ghorbani. Towards the development of a realistic multidimensional iot profiling dataset. In2022 19th Annual International Conference on Privacy, Security & Trust (PST), pages 1–11. IEEE, 2022
work page 2022
-
[45]
Character- ization of encrypted and vpn traffic using time-related
Gerard Draper-Gil, Arash Habibi Lashkari, Mohammad Saiful Islam Mamun, and Ali A Ghorbani. Character- ization of encrypted and vpn traffic using time-related. InProceedings of the 2nd international conference on information systems security and privacy (ICISSP), pages 407–414, 2016
work page 2016
-
[46]
Leo: Online {ML-based} traffic classification at {Multi-Terabit} line rate
Syed Usman Jafri, Sanjay Rao, Vishal Shrivastav, and Mohit Tawarmalani. Leo: Online {ML-based} traffic classification at {Multi-Terabit} line rate. In21st USENIX Symposium on Networked Systems Design and Implementation (NSDI 24), pages 1573–1591, 2024
work page 2024
-
[47]
Re-architecting traffic analysis with neural network interface cards
Giuseppe Siracusano, Salvator Galea, Davide Sanvito, Mohammad Malekzadeh, Gianni Antichi, Paolo Costa, Hamed Haddadi, and Roberto Bifulco. Re-architecting traffic analysis with neural network interface cards. In 19th USENIX Symposium on Networked Systems Design and Implementation (NSDI 22), pages 513–533, 2022
work page 2022
-
[48]
Ye Zhang and Byron C Wallace. A sensitivity analysis of (and practitioners’ guide to) convolutional neural networks for sentence classification. InProceedings of the Eighth International Joint Conference on Natural Language Processing (Volume 1: Long Papers), pages 253–263, 2017
work page 2017
-
[49]
Kitsune: An Ensemble of Autoencoders for Online Network Intrusion Detection
Yisroel Mirsky, Tomer Doitshman, Yuval Elovici, and Asaf Shabtai. Kitsune: an ensemble of autoencoders for online network intrusion detection.arXiv preprint arXiv:1802.09089, 2018. A Theoretical Guarantees A.1 Notation and assumptions We use the following notation throughout the section. Let T denote the token sequence length, d the original embedding dim...
work page internal anchor Pith review Pith/arXiv arXiv 2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.