Evaluating LLM-Generated ACSL Annotations for Formal Verification
Pith reviewed 2026-05-15 22:12 UTC · model grok-4.3
The pith
Rule-based methods produce more reliable ACSL annotations than one-shot LLM outputs for C program verification.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
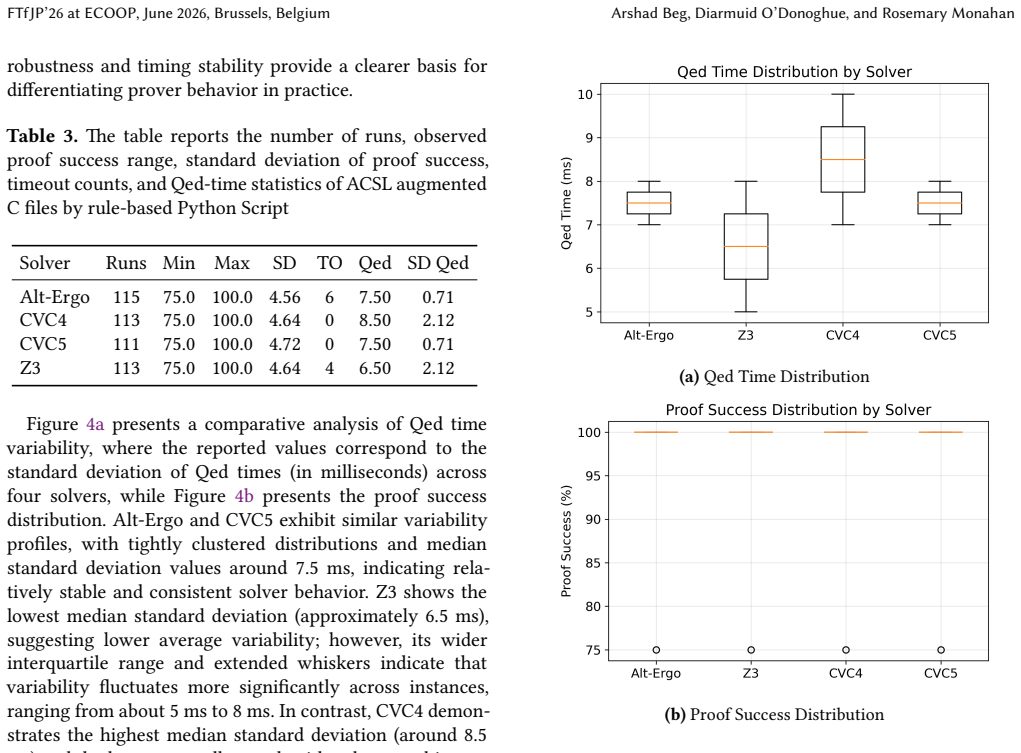
Through one-shot generation on the filtered CASP benchmark, the paper shows that rule-based annotation methods achieve higher rates of successful proofs under Frama-C's WP plugin and SMT solvers than the outputs produced by DeepSeek-V3.2, GPT-5.2, or OLMo 3.1 32B Instruct, with the latter exhibiting greater variability in both success and solver behavior.
What carries the argument
The one-shot annotation generation comparison, executed via Frama-C WP on the filtered CASP benchmark and measured by proof success rates across multiple SMT solvers.
If this is right
- Rule-based scripts remain the safer default choice when high assurance verification of C code is required.
- LLM outputs can still serve as starting points but need post-processing or additional checks to reach reliable proof rates.
- One-shot LLM annotation generation is currently insufficient as a standalone replacement for established automation in formal verification pipelines.
- Further prompt refinement or hybrid rule-plus-LLM workflows would be needed before LLMs become primary tools for ACSL specification.
Where Pith is reading between the lines
- A hybrid pipeline that lets LLMs propose annotations and then applies rule-based refinement could combine the strengths of both approaches.
- The performance gap observed here suggests that benchmarks focused on verification outcomes, rather than annotation similarity alone, should guide future LLM training for specification tasks.
- Expanding the evaluation to include iterative interaction with the verifier or fine-tuning on verification traces could narrow the reliability difference between LLMs and rule-based methods.
- These results point toward treating LLMs as assistive rather than autonomous components in formal methods toolchains for the near term.
Load-bearing premise
The filtered CASP subset represents typical real-world C programs and that one-shot prompting supplies a fair head-to-head test of the methods.
What would settle it
Running the same generation methods on an unfiltered or larger CASP collection, or repeating the comparison with multi-shot or engineered prompts, and finding that any LLM then matches or exceeds the rule-based proof success rate.
Figures






read the original abstract
Formal specifications are crucial for building verifiable and dependable software systems, yet generating accurate and verifiable specifications for real-world C programs remains challenging. This paper presents an empirical evaluation of automated ACSL annotation generation strategies for C programs, comparing a rule-based Python script, Frama-C's RTE plugin, and three large language models (DeepSeek-V3.2, GPT-5.2, and OLMo 3.1 32B Instruct). The study focuses on one-shot annotation generation, assessing how these approaches perform when directly applied to verification tasks. Using a filtered subset of the CASP benchmark, we evaluate generated annotations through Frama-C's WP plugin with multiple SMT solvers, analyzing proof success rates, solver timeouts, and internal processing time. Our results show that rule-based approaches remain more reliable for verification success, while LLM-based methods exhibit more variable performance. These findings highlight both the current limitations and the potential of LLMs as complementary tools for automated specification generation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. This paper presents an empirical evaluation of ACSL annotation generation for C programs, comparing a rule-based Python script, Frama-C's RTE plugin, and three LLMs (DeepSeek-V3.2, GPT-5.2, OLMo 3.1 32B Instruct) using one-shot prompting on a filtered CASP benchmark subset. Annotations are assessed for verifiability via Frama-C's WP plugin with multiple SMT solvers, focusing on proof success rates, solver timeouts, and processing time. The central claim is that rule-based methods are more reliable for verification success while LLM-based methods show greater variability.
Significance. If the results hold under fair conditions, the work provides concrete empirical data on the relative strengths of established rule-based tools versus current LLMs for generating verifiable specifications in C. This is useful for practitioners in formal verification, as it quantifies performance gaps using public benchmarks and standard tools like Frama-C, and could inform hybrid approaches. The direct measurement of proof outcomes via external solvers adds grounding to the comparative assessment.
major comments (1)
- [Evaluation setup (abstract and methods)] The one-shot prompting strategy for LLMs (as described in the abstract) may not constitute a fair apples-to-apples comparison with the rule-based script and Frama-C RTE, which are purpose-built for ACSL/C. Without few-shot examples, chain-of-thought, or task-specific instructions, any observed variability in LLM performance could stem from unequal prompting effort rather than fundamental limitations, especially if the filtered CASP subset contains patterns already well-handled by rules. This assumption is load-bearing for the headline claim that rule-based approaches remain more reliable.
minor comments (3)
- [Abstract] The abstract provides no details on the exact prompt templates used for the three LLMs or the specific filtering criteria applied to the CASP benchmark subset; these should be documented to allow replication.
- [Results] No statistical significance tests are mentioned for differences in proof success rates or timeouts across methods; adding these would strengthen the comparative claims.
- [Evaluation] Clarify the exact versions or configurations of the SMT solvers and Frama-C WP plugin used, as these can affect timeout and success metrics.
Simulated Author's Rebuttal
We thank the referee for their thoughtful and detailed review. We address the single major comment below.
read point-by-point responses
-
Referee: [Evaluation setup (abstract and methods)] The one-shot prompting strategy for LLMs (as described in the abstract) may not constitute a fair apples-to-apples comparison with the rule-based script and Frama-C RTE, which are purpose-built for ACSL/C. Without few-shot examples, chain-of-thought, or task-specific instructions, any observed variability in LLM performance could stem from unequal prompting effort rather than fundamental limitations, especially if the filtered CASP subset contains patterns already well-handled by rules. This assumption is load-bearing for the headline claim that rule-based approaches remain more reliable.
Authors: We appreciate the referee's concern regarding fairness. Our study is explicitly scoped to one-shot prompting for the LLMs, as stated in the abstract and methods, to establish a baseline for direct, minimally prompted application of current models. The rule-based script and Frama-C RTE are specialized tools by design, and the comparison is intended to quantify their reliability relative to LLMs under standard one-shot conditions rather than to claim optimality for LLMs. The manuscript does not assert that LLMs cannot improve with advanced prompting; it reports observed performance gaps in the evaluated setting. We therefore maintain that the central claim holds for the conditions described, while acknowledging that further prompting engineering lies beyond the paper's stated objectives. revision: no
Circularity Check
No circularity in empirical evaluation
full rationale
The paper reports direct experimental measurements of annotation generation success rates and verification outcomes using external tools (Frama-C WP, SMT solvers) on a benchmark subset. No mathematical derivations, fitted parameters renamed as predictions, self-definitional constructs, or load-bearing self-citations appear in the described methodology or results. All claims rest on observable tool outputs rather than internal redefinitions or ansatzes, satisfying the criteria for a self-contained empirical study.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Our results show that rule-based approaches remain more reliable for verification success, while LLM-based methods exhibit more variable performance.
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanLogicNat ≃ Nat recovery unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Using a filtered subset of the CASP benchmark, we evaluate generated annotations through Frama-C’s WP plugin with multiple SMT solvers
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Arshad Beg, Diarmuid O’Donoghue, and Rosemary Monahan. 2025. Leveraging LLMs for Formal Software Requirements: Challenges and Prospects. In Proceedings of OVERLAY 2025: Artificial Intelligence and Formal Verification, Logic, Automata, and Synthesis (CEUR Workshop Proceedings, Vol. 4142) . CEUR-WS.org, 95–105. https://ceur-ws.org /Vol-4142/paper11.pdf Eval...
work page 2025
-
[2]
Arshad Beg, Diarmuid O’Donoghue, and Rosemary Monahan. 2025. Traceable and Verifiable Software Requirements: A Synthesis of AI- Enabled Formal Methods. Journal of Software Testing, Verification and Reliability (2025). doi:10.5281/zenodo.17772835 Submitted; Version v1 available on Zenodo
- [3]
- [4]
-
[5]
Wenji Fang, Mengming Li, Min Li, Zhiyuan Yan, Shang Liu, Hongce Zhang, and Zhiyao Xie. 2024. AssertLLM: Generating Hardware Ver- ification Assertions from Design Specifications via Multi-LLMs. In 2024 IEEE LLM Aided Design Workshop (LAD) . 1–1. doi:10.1109/LA D62341.2024.10691792
work page doi:10.1109/la 2024
-
[6]
George Granberry, Wolfgang Ahrendt, and Moa Johansson
-
[7]
In Integrated Formal Methods , Nikolai Kosma- tov and Laura Kovács (Eds.)
Specify What? Enhancing Neural Specification Synthesis by Symbolic Methods. In Integrated Formal Methods , Nikolai Kosma- tov and Laura Kovács (Eds.). Springer Nature Switzerland, Cham, 307–325
-
[8]
George Granberry, Wolfgang Ahrendt, and Moa Johansson. 2025. To- wards Integrating Copiloting and Formal Methods. In Leveraging Ap- plications of Formal Methods, Verification and Validation. Specifica- tion and Verification , Tiziana Margaria and Bernhard Steffen (Eds.). Springer Nature Switzerland, Cham, 144–158
work page 2025
-
[9]
Niclas Hertzberg, Merlijn Sevenhuijsen, Liv Kåreborn, and Anna Lokrantz. 2025. CASP: An Evaluation Dataset for Formal Verification of C Code. In Bridging the Gap Between AI and Reality - Third Interna- tional Conference on Bridging the Gap between AI and Reality, AISoLA 2025, Rhodes, Greece, November 1-5, 2025, Selected Papers (Lecture Notes in Computer S...
work page 2025
-
[10]
doi:10.1007/978-3-032-07132-3_5
-
[11]
Lahiri, Akash Lal, Aseem Rastogi, Subhajit Roy, and Rahul Sharma
Adharsh Kamath, Aditya Senthilnathan, Saikat Chakraborty, Pantazis Deligiannis, Shuvendu K. Lahiri, Akash Lal, Aseem Rastogi, Subha- jit Roy, and Rahul Sharma. 2023. Finding Inductive Loop Invari- ants using Large Language Models. CoRR abs/2311.07948 (2023). arXiv:2311.07948 doi:10.48550/ARXIV.2311.07948
-
[12]
Minghai Lu, Benjamin Delaware, and Tianyi Zhang. 2024. Proof Automation with Large Language Models. In Proceedings of the 39th IEEE/ACM International Conference on Automated Software Engineer- ing, ASE 2024, Sacramento, CA, USA, October 27 - November 1, 2024 , Vladimir Filkov, Baishakhi Ray, and Minghui Zhou (Eds.). ACM, 1509–
work page 2024
-
[13]
doi:10.1145/3691620.3695521
- [14]
-
[15]
Anmol Nayak, Hari Prasad Timmapathini, Vidhya Murali, Karthikeyan Ponnalagu, Vijendran Gopalan Venkoparao, and Amalinda Post. 2022. Req2Spec: Transforming Software Require- ments into Formal Specifications Using Natural Language Processing. In Requirements Engineering: Foundation for Software Quality: 28th International Working Conference, REFSQ 2022, Bir...
work page 2022
-
[16]
Sv-llm: An agentic approach for soc security verification using large language models,
Dipayan Saha, Shams Tarek, Hasan Al Shaikh, Khan Thamid Hasan, Pavan Sai Nalluri, Md. Ajoad Hasan, Nashmin Alam, Jingbo Zhou, Sujan Kumar Saha, Mark Tehranipoor, and Farimah Farahmandi. 2025. SV-LLM: An Agentic Approach for SoC Security Verification using Large Language Models. (2025). arXiv: 2506.20415 [cs.CR] https: //arxiv.org/abs/2506.20415
-
[17]
Merlijn Sevenhuijsen, Khashayar Etemadi, and Mattias Nyberg. 2025. VeCoGen: Automating Generation of Formally Verified C Code With Large Language Models. In 13th IEEE/ACM International Conference on Formal Methods in Software Engineering, FormaliSE@ICSE 2025, Ot- tawa, ON, Canada, April 27-28, 2025 . IEEE, 101–112. doi:10.1109/FO RMALISE66629.2025.00017
work page doi:10.1109/fo 2025
-
[18]
Sumanth Varambally, Thomas Voice, Yanchao Sun, Zhifeng Chen, Rose Yu, and Ke Ye. 2025. Hilbert: Recursively Building For- mal Proofs with Informal Reasoning. CoRR abs/2509.22819 (2025). arXiv:2509.22819 doi:10.48550/ARXIV.2509.22819
-
[19]
Weiqi Wang, Marie Farrell, Lucas C. Cordeiro, and Liping Zhao. 2025. Supporting Software Formal Verification with Large Language Mod- els: An Experimental Study. In 33rd IEEE International Requirements Engineering Conference, RE 2025, Valencia, Spain, September 1-5, 2025 . IEEE, 423–431. doi:10.1109/RE63999.2025.00049
-
[20]
Cheng Wen, Jialun Cao, Jie Su, Zhiwu Xu, Shengchao Qin, Mengda He, Haokun Li, Shing-Chi Cheung, and Cong Tian. 2024. Enchant- ing Program Specification Synthesis by Large Language Models Using Static Analysis and Program Verification. In Computer Aided Verifica- tion - 36th International Conference, CA V 2024, Montreal, QC, Canada, July 24-27, 2024, Proce...
- [21]
-
[22]
Yedi Zhang, Sun Yi Emma, Annabelle Lee Jia En, and Jin Song Dong
-
[23]
RvLLM: LLM Runtime Verification with Domain Knowledge. CoRR abs/2505.18585 (2025). arXiv: 2505.18585 doi:10.48550/ARXIV.2 505.18585
-
[24]
Yihang Zhao. 2025. Leveraging Large Language Models for Ontology Requirements Engineering. In The Semantic Web: ESWC 2025 Satellite Events - Portoroz, Slovenia, June 1-5, 2025, Proceedings (Lecture Notes in Computer Science, Vol. 15832) , Edward Curry, Valentina Presutti, John P. McCrae, Mehwish Alam, Pieter Colpaert, Josiane Xavier Par- reira, Diego Coll...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.