Recognition: no theorem link
ScrapeGraphAI-100k: Dataset for Schema-Constrained LLM Generation
Pith reviewed 2026-05-15 21:33 UTC · model grok-4.3
The pith
A dataset of 93,695 real schema-constrained extraction events from ScrapeGraphAI usage lets a 1.7B model track its GPT-5-nano teacher's output distribution while still trailing a larger reference on schema compliance.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that grounding schema-constrained generation training in large-scale, real-world telemetry data enables small models to approximate the structured output behavior of larger teachers in ways that earlier synthetic or text-only corpora could not achieve.
What carries the argument
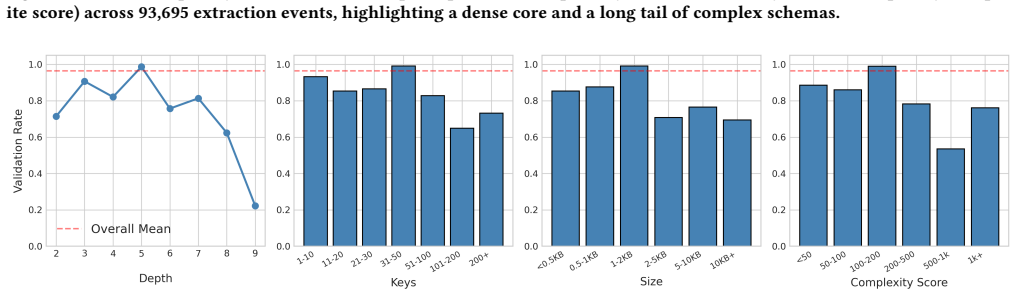
The ScrapeGraphAI-100k dataset of 93,695 deduplicated, schema-balanced extraction events, each containing Markdown content, prompt, schema, response, and structural conformance labels.
If this is right
- Fine-tuning on real practitioner data can produce small models whose structured outputs closely track those of a larger teacher model.
- The dataset supports benchmarking of schema-constrained generation that goes beyond what synthetic corpora allow.
- Performance degrades sharply once schema complexity exceeds identifiable thresholds.
- Scaling data collection from live tool usage provides a viable path for improving structured extraction capabilities.
- Semantic correctness remains out of scope, so the dataset focuses strictly on structural conformance to the supplied JSON schema.
Where Pith is reading between the lines
- Collecting telemetry from production tools may reduce the distribution shift that synthetic datasets introduce for structured generation tasks.
- The same approach could be extended to other tool-use scenarios such as function calling or API orchestration.
- If the structural labels prove reliable, the corpus could serve as a test bed for measuring how schema complexity interacts with model scale.
- Future versions that add raw HTML or semantic verification would further strengthen the resource for end-to-end extraction pipelines.
Load-bearing premise
The opt-in telemetry events collected from ScrapeGraphAI users are representative of diverse real-world schema-constrained tasks without selection bias from the tool's specific user base or usage patterns.
What would settle it
Retraining the 1.7B student on the dataset and measuring that its output distribution no longer matches the GPT-5-nano teacher or that its schema-compliance rate fails to approach the reported level would falsify the distillation result.
Figures




read the original abstract
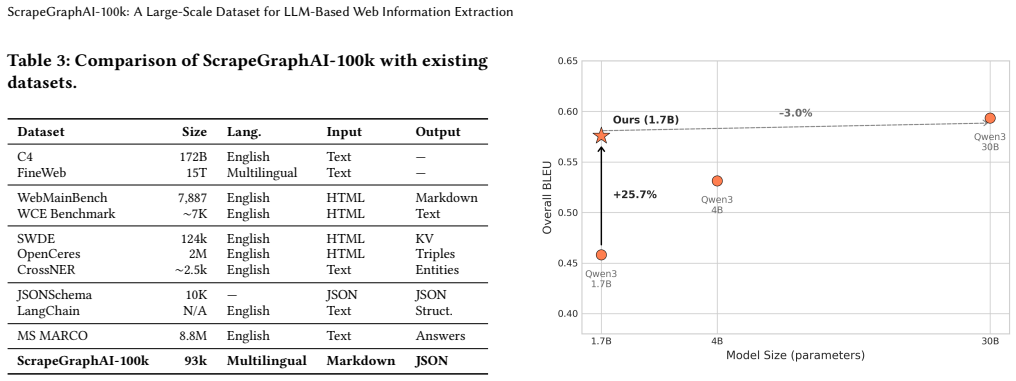
Producing output that conforms to a specified JSON schema underlies tool use, structured extraction, and knowledge base construction in modern large language models. Despite this centrality, public datasets for the task remain small, synthetic, or text-only, and rarely pair real page content with the prompts and schemas used in practice. We introduce ScrapeGraphAI-100k, 93,695 schema-constrained extraction events collected via opt-in ScrapeGraphAI telemetry in Q2--Q3 2025, deduplicated and balanced by schema from 9M raw events. The corpus spans 18 000+ unique schemas across 15 named languages plus a long-tail Other category, with English and Traditional Chinese covering 88% of detected content, each instance pairs Markdown-converted page content with a prompt, schema, LLM response, and per-example jsonschema-rs structural conformance labels (semantic correctness is out of scope, and raw HTML is deferred beyond v1.0). We characterize structural diversity across the corpus and identify sharp failure thresholds as schema complexity grows. As a case study, a 1.7B student fine-tuned on this data closely tracks the output distribution of its GPT-5-nano teacher, though it still trails a 30B-A3B reference (3.3B active parameters) on schema compliance. We offer this distillation result as preliminary evidence that grounding schema-constrained generation in real practitioner workloads at scale enables training and benchmarking that prior synthetic or text-only corpora could not support.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces ScrapeGraphAI-100k, a dataset of 93,695 schema-constrained extraction events collected via opt-in ScrapeGraphAI telemetry (Q2–Q3 2025), deduplicated and balanced by schema from 9M raw events. It spans 18,000+ unique schemas, pairs Markdown page content with prompts/schemas/LLM responses, and supplies jsonschema-rs structural conformance labels (semantic correctness out of scope). A case study shows a 1.7B student model fine-tuned on the data closely tracks its GPT-5-nano teacher’s output distribution while trailing a 30B-A3B reference on schema compliance, offered as preliminary evidence for real-world grounding in schema-constrained generation.
Significance. If the dataset is representative, it would provide a large-scale, real-practitioner resource for training and benchmarking schema-constrained LLM generation that existing synthetic or text-only corpora cannot match. The distillation case study supplies preliminary evidence that grounding in actual workloads can enable effective student-teacher tracking, a strength given the parameter-free nature of the data release itself.
major comments (3)
- [Corpus collection] Corpus collection section: The claim that the 93k deduplicated events support general schema-constrained training and benchmarking rests on the unexamined assumption that opt-in ScrapeGraphAI telemetry is representative; no analysis of user demographics, domain skew, opt-in participation bias, or correlation with schema complexity/task type is provided, directly affecting generalizability as highlighted by the weakest assumption.
- [Case study] Case study section: The central claim that the 1.7B student 'closely tracks' the GPT-5-nano teacher’s output distribution is supported only by qualitative description; no quantitative metrics (exact match rates, schema compliance percentages, or distributional distances) or baselines are reported, weakening the distillation evidence relative to the 30B-A3B reference.
- [Structural labels] Structural labels description: While jsonschema-rs conformance labels are supplied, the manuscript provides no quantitative validation, error analysis, or assessment of label reliability, which is load-bearing because structural conformance is the only labeled signal and semantic correctness is explicitly out of scope.
minor comments (2)
- [Abstract] Abstract: The phrase '30B-A3B reference (3.3B active parameters)' should be expanded on first use to clarify the architecture for readers outside the specific model family.
- [Corpus characterization] Corpus characterization: The reported language distribution (English and Traditional Chinese at 88%) would benefit from an explicit table or figure showing the full 15-language breakdown plus the detection method used.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on representativeness, evaluation metrics, and label validation. We address each major comment below and outline revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Corpus collection] Corpus collection section: The claim that the 93k deduplicated events support general schema-constrained training and benchmarking rests on the unexamined assumption that opt-in ScrapeGraphAI telemetry is representative; no analysis of user demographics, domain skew, opt-in participation bias, or correlation with schema complexity/task type is provided, directly affecting generalizability as highlighted by the weakest assumption.
Authors: We agree this is a valid concern for claims of generalizability. The dataset reflects real opt-in usage of ScrapeGraphAI and is not positioned as a demographically balanced sample. In revision we will add an explicit Limitations section discussing potential biases (e.g., English/Traditional Chinese dominance at 88%, opt-in participation effects, and schema complexity skew), clarify that the corpus is intended to capture practitioner workloads rather than universal coverage, and expand the description of the deduplication and schema-balancing procedure to better bound its scope. revision: yes
-
Referee: [Case study] Case study section: The central claim that the 1.7B student 'closely tracks' the GPT-5-nano teacher’s output distribution is supported only by qualitative description; no quantitative metrics (exact match rates, schema compliance percentages, or distributional distances) or baselines are reported, weakening the distillation evidence relative to the 30B-A3B reference.
Authors: We acknowledge the evaluation is currently qualitative. In the revised manuscript we will add quantitative results: exact match rates on schema fields, schema compliance percentages computed via the supplied jsonschema-rs labels, and distributional metrics (e.g., structural KL divergence or tree-edit distance) comparing the 1.7B student against both the GPT-5-nano teacher and the 30B-A3B reference. These will be reported in a new table alongside the existing qualitative observations. revision: yes
-
Referee: [Structural labels] Structural labels description: While jsonschema-rs conformance labels are supplied, the manuscript provides no quantitative validation, error analysis, or assessment of label reliability, which is load-bearing because structural conformance is the only labeled signal and semantic correctness is explicitly out of scope.
Authors: The labels are produced by the deterministic jsonschema-rs validator, so structural errors are well-defined. We agree an explicit reliability assessment strengthens the release. In revision we will add a subsection detailing the label-generation pipeline, report corpus-wide conformance statistics (e.g., pass rates by schema complexity), and include a brief error analysis of common structural failure modes (type mismatches, missing required fields, etc.) to document label quality. revision: yes
Circularity Check
No circularity in derivation chain
full rationale
The paper introduces a new dataset collected from opt-in telemetry and presents a preliminary fine-tuning case study as empirical evidence. No mathematical derivations, equations, fitted parameters renamed as predictions, or load-bearing self-citations are present. The claims about dataset characteristics and model tracking are descriptive and observational rather than reducing to inputs by construction. This is a standard dataset release paper with no self-referential loops.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 1 Pith paper
-
Web2BigTable: A Bi-Level Multi-Agent LLM System for Internet-Scale Information Search and Extraction
Web2BigTable introduces a bi-level multi-agent system that achieves new state-of-the-art results on wide-coverage and deep web-to-table search benchmarks through orchestration, coordination, and closed-loop reflection.
Reference graph
Works this paper leans on
-
[1]
Janek Bevendorff, Sanket Gupta, Johannes Kiesel, and Benno Stein. 2023. An Empirical Comparison of Web Content Extraction Algorithms. InProceedings of the 46th International ACM SIGIR Conference on Research and Development in Information Retrieval(Taipei, Taiwan)(SIGIR ’23). Association for Computing Machinery, New York, NY, USA, 2594–2603. doi:10.1145/35...
-
[2]
Common Crawl Foundation. 2026. Common Crawl Dataset. https:// commoncrawl.org/ Accessed: 2026-01-06
work page 2026
-
[3]
Domenico Dato, Sean MacAvaney, Franco Maria Nardini, Raffaele Perego, and Nicola Tonellotto. 2022. The Istella22 Dataset: Bridging Traditional and Neural Learning to Rank Evaluation. InProceedings of the 45th International ACM SI- GIR Conference on Research and Development in Information Retrieval(Madrid, Spain)(SIGIR ’22). Association for Computing Machi...
-
[4]
Tim Dettmers, Artidoro Pagnoni, Ari Holtzman, and Luke Zettlemoyer. 2023. QLoRA: Efficient Finetuning of Quantized LLMs. arXiv:arXiv:2305.14314
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[5]
Qiang Hao, Rui Cai, Yanwei Pang, and Lei Zhang. 2011. From One Tree to a Forest: A Unified Solution for Structured Web Data Extraction. InProceedings of the 34th International ACM SIGIR Conference on Research and Development in Information Retrieval(Beijing, China)(SIGIR ’11). ACM, New York, NY, USA, 775–784. doi:10.1145/2009916.2010020
-
[6]
LoRA: Low-Rank Adaptation of Large Language Models
Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. 2021. LoRA: Low-Rank Adaptation of Large Language Models. arXiv:2106.09685 [cs.CL] https://arxiv.org/abs/2106.09685
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[7]
Armand Joulin, Edouard Grave, Piotr Bojanowski, and Tomas Mikolov. 2016. Bag of Tricks for Efficient Text Classification.arXiv preprint arXiv:1607.01759(2016)
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[8]
Saurav Kadavath, Tom Conerly, Amanda Askell, Tom Henighan, Dawn Drain, Ethan Perez, Nicholas Schiefer, Zac Hatfield-Dodds, Nova DasSarma, Eli Tran- Johnson, Scott Johnston, Sheer El-Showk, Andy Jones, Nelson Elhage, Tris- tan Hume, Anna Chen, Yuntao Bai, Sam Bowman, Stanislav Fort, Deep Gan- guli, Danny Hernandez, Josh Jacobson, Jackson Kernion, Shauna Kr...
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[9]
Gonzalez, Hao Zhang, and Ion Stoica
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph E. Gonzalez, Hao Zhang, and Ion Stoica. 2023. Efficient Memory Management for Large Language Model Serving with PagedAtten- tion. InProceedings of the ACM SIGOPS 29th Symposium on Operating Systems Principles
work page 2023
-
[10]
LangChain AI. 2023.LangChain Benchmarks. https://langchain-ai.github.io/ langchain-benchmarks/ Accessed: 2026-01-06
work page 2023
-
[11]
Mengjie Liu, Jiahui Peng, Pei Chu, Jiantao Qiu, Ren Ma, He Zhu, Rui Min, Lindong Lu, Wenchang Ning, Linfeng Hou, Kaiwen Liu, Yuan Qu, Zhenxiang Li, Chao Xu, Zhongying Tu, Wentao Zhang, and Conghui He. 2025. Dripper: Token- Efficient Main HTML Extraction with a Lightweight LM. arXiv:2511.23119 [cs.CL] https://arxiv.org/abs/2511.23119
- [12]
-
[13]
Colin Lockard, Prashant Shiralkar, and Xin Luna Dong. 2019. OpenCeres: When Open Information Extraction Meets the Semi-Structured Web. InProceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), Jill Burstein, Christy Doran, and Thamar S...
work page 2019
-
[14]
Potsawee Manakul, Adian Liusie, and Mark J. F. Gales. 2023. SelfCheckGPT: Zero- Resource Black-Box Hallucination Detection for Generative Large Language Models. arXiv:2303.08896 [cs.CL] https://arxiv.org/abs/2303.08896
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[15]
Tri Nguyen, Mir Rosenberg, Xia Song, Jianfeng Gao, Saurabh Tiwary, Rangan Majumder, and Li Deng. 2016. MS MARCO: A Human Generated MAchine Reading COmprehension Dataset.arXiv preprint arXiv:1611.09268(2016). https: //arxiv.org/abs/1611.09268
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[16]
RouteLLM: Learning to Route LLMs with Preference Data
Isaac Ong, Amjad Almahairi, Vincent Wu, Wei-Lin Chiang, Tianhao Wu, Joseph E. Gonzalez, M Waleed Kadous, and Ion Stoica. 2025. RouteLLM: Learning to Route LLMs with Preference Data. arXiv:2406.18665 [cs.LG] https://arxiv.org/abs/2406. 18665
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[17]
Kishore Papineni, Salim Roukos, Todd Ward, and Wei-Jing Zhu. 2002. Bleu: a Method for Automatic Evaluation of Machine Translation. InProceedings of the 40th Annual Meeting of the Association for Computational Linguistics, Pierre Isabelle, Eugene Charniak, and Dekang Lin (Eds.). Association for Computational Linguistics, Philadelphia, Pennsylvania, USA, 31...
-
[18]
Guilherme Penedo, Hynek Kydlíček, Loubna Ben allal, Anton Lozhkov, Margaret Mitchell, Colin Raffel, Leandro Von Werra, and Thomas Wolf. 2024. The FineWeb Datasets: Decanting the Web for the Finest Text Data at Scale. InThe Thirty-eight Conference on Neural Information Processing Systems Datasets and Benchmarks Track. https://openreview.net/forum?id=n6SCkn2QaG
work page 2024
-
[19]
Marco Perini, Lorenzo Padoan, and Marco Vinciguerra. 2024.Scrapegraph-ai. https://github.com/VinciGit00/Scrapegraph-ai
work page 2024
-
[20]
Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J Liu. 2020. Exploring the limits of transfer learning with a unified text-to-text transformer.Journal of Machine Learning Research21, 140 (2020), 1–67. http://jmlr.org/papers/v21/20-074.html
work page 2020
- [21]
- [22]
-
[23]
Jiejun Tan, Zhicheng Dou, Wen Wang, Mang Wang, Weipeng Chen, and Ji-Rong Wen. 2025. HtmlRAG: HTML is Better Than Plain Text for Modeling Retrieved Knowledge in RAG Systems. InProceedings of the ACM on Web Conference 2025 (WWW ’25). ACM, 1733–1746. doi:10.1145/3696410.3714546
- [24]
-
[25]
Qwen Team. 2025. Qwen3 Technical Report. arXiv:2505.09388 [cs.CL] https: //arxiv.org/abs/2505.09388
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [26]
-
[27]
Lingling Xu, Haoran Xie, Si-Zhao Joe Qin, Xiaohui Tao, and Fu Lee Wang. 2023. Parameter-Efficient Fine-Tuning Methods for Pretrained Language Models: A Critical Review and Assessment. arXiv:2312.12148 [cs.CL] https://arxiv.org/abs/ 2312.12148 A Example Dataset Entry The following JSON object illustrates a complete entry from ScrapeGraphAI- 100k. This exam...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.