Recognition: 2 theorem links
· Lean TheoremSocial Life of Code: Modeling Evolution through Code Embedding and Opinion Dynamics
Pith reviewed 2026-05-15 22:02 UTC · model grok-4.3
The pith
Integrating semantic code embeddings with an opinion dynamics model tracks developer influence and consensus in open-source projects.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
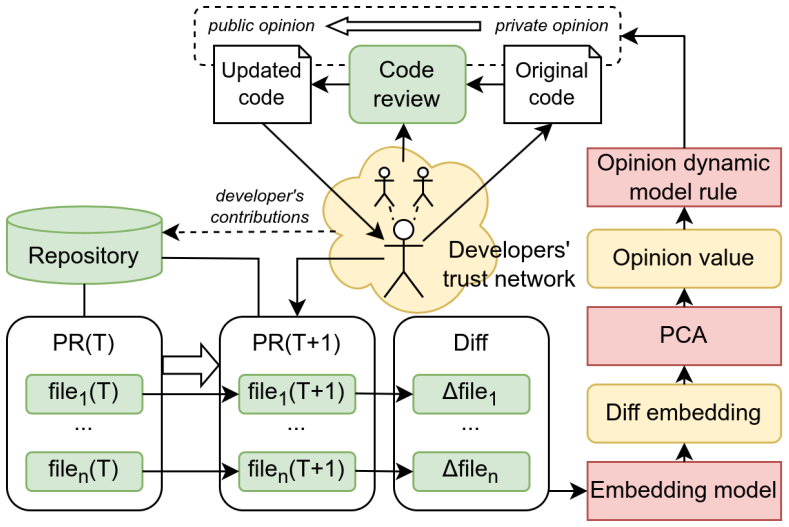
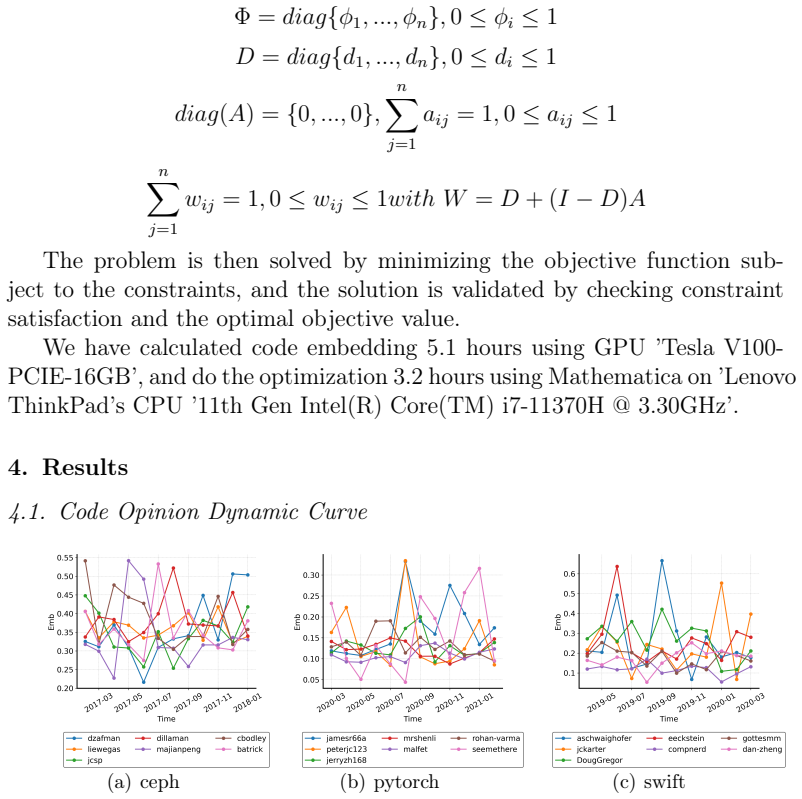
By encoding code snippets into high-dimensional vectors that preserve syntactic and semantic features, applying PCA for dimensionality reduction and normalization, and then modeling the resulting data with the EPO framework, the approach derives trust matrices and opinion trajectories. These trajectories are claimed to reflect consensus formation, influence propagation, and evolving alignment or divergence within developer communities, as demonstrated through evaluation on data from three prominent open-source GitHub repositories that reveal interpretable behavioral trends and variations in interactions.
What carries the argument
Semantic code embeddings reduced via PCA and input to the Expressed-Private Opinion (EPO) model, which computes trust matrices and opinion trajectories from temporal sequences of code modifications.
If this is right
- Opinion trajectories can identify periods of increasing alignment or growing divergence across development cycles.
- Trust matrices derived from embeddings can quantify the relative influence of individual developers on the codebase.
- Long-term patterns in consensus formation can inform assessments of project sustainability and maintenance needs.
- Implicit knowledge-sharing mechanisms become visible through the modeled propagation of alignment within the community.
Where Pith is reading between the lines
- If the embedding-to-opinion mapping holds, the framework could be extended to forecast project forks by detecting sustained divergence thresholds.
- The same pipeline might apply to other collaborative text artifacts such as documentation edits or issue discussions to reveal analogous social dynamics.
- Direct validation against developer self-reported opinions would test whether embedding distances reliably proxy the required opinion distances.
Load-bearing premise
Distances in the PCA-reduced code embedding space correspond to actual differences in developers' private opinions and the influence relations required by the EPO model.
What would settle it
An experiment that finds no statistical correlation between the model's predicted opinion alignments or trust values and independent measures such as pull-request acceptance rates, commit-message sentiment, or direct developer surveys on agreement would falsify the central mapping.
Figures





read the original abstract
Software repositories provide a detailed record of software evolution by capturing developer interactions through code-related activities such as pull requests and modifications. To better understand the underlying dynamics of codebase evolution, we introduce a novel approach that integrates semantic code embeddings with opinion dynamics theory, offering a quantitative framework to analyze collaborative development processes. Our approach begins by encoding code snippets into high-dimensional vector representations using state-of-the-art code embedding models, preserving both syntactic and semantic features. These embeddings are then processed using Principal Component Analysis (PCA) for dimensionality reduction, with data normalized to ensure comparability. We model temporal evolution using the Expressed-Private Opinion (EPO) model to derive trust matrices and track opinion trajectories across development cycles. These opinion trajectories reflect the underlying dynamics of consensus formation, influence propagation, and evolving alignment (or divergence) within developer communities -- revealing implicit collaboration patterns and knowledge-sharing mechanisms that are otherwise difficult to observe. By bridging software engineering and computational social science, our method provides a principled way to quantify software evolution, offering new insights into developer influence, consensus formation, and project sustainability. We evaluate our approach on data from three prominent open-source GitHub repositories, demonstrating its ability to reveal interpretable behavioral trends and variations in developer interactions. The results highlight the utility of our framework in improving open-source project maintenance through data-driven analysis of collaboration dynamics.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a framework that encodes code snippets from GitHub repositories into semantic vector representations using code embedding models, applies PCA for dimensionality reduction and normalization, and feeds the results into the Expressed-Private Opinion (EPO) model to derive trust matrices and track opinion trajectories over development cycles. It claims this reveals implicit collaboration patterns, consensus formation, influence propagation, and alignment/divergence in developer communities, providing quantitative insights into software evolution and project sustainability. The approach is evaluated on data from three prominent open-source repositories, demonstrating interpretable behavioral trends.
Significance. If the embedding-to-opinion mapping is shown to be faithful, the work could provide a useful bridge between software engineering metrics and computational social science models, enabling data-driven analysis of collaboration dynamics beyond commit counts or PR graphs. The use of real repository data and the EPO model for temporal trajectories offers potential for falsifiable predictions about influence and sustainability, though the current presentation supplies no quantitative benchmarks or external validation to establish this utility.
major comments (1)
- [Abstract / Methodology] Abstract and methodology description: The claim that PCA-reduced code embeddings faithfully encode private opinions and influence relations for the EPO model is load-bearing for all downstream results (trust matrices, opinion trajectories, consensus metrics). No independent validation is provided, such as correlation with commit co-occurrence networks, pull-request interaction graphs, or external influence labels; without this, the derived quantities may simply reflect embedding geometry rather than social dynamics.
minor comments (1)
- [Abstract] The abstract supplies no quantitative results, error bars, baseline comparisons (e.g., against simple co-commit graphs), or ablation checks on the PCA step or EPO parameters, which would be needed to support the evaluation claims on the three repositories.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which help clarify the need for stronger validation of our core mapping. We address the single major comment below and commit to revisions that directly respond to the concern without overstating the current manuscript.
read point-by-point responses
-
Referee: [Abstract / Methodology] Abstract and methodology description: The claim that PCA-reduced code embeddings faithfully encode private opinions and influence relations for the EPO model is load-bearing for all downstream results (trust matrices, opinion trajectories, consensus metrics). No independent validation is provided, such as correlation with commit co-occurrence networks, pull-request interaction graphs, or external influence labels; without this, the derived quantities may simply reflect embedding geometry rather than social dynamics.
Authors: We agree that the mapping from PCA-reduced code embeddings to the opinion vectors used in the EPO model is foundational and requires explicit support. The manuscript currently justifies the mapping by noting that state-of-the-art code embeddings preserve semantic and syntactic features of contributions, which we treat as proxies for aligned or divergent developer perspectives; the EPO dynamics are then run on these vectors to produce trajectories. While the resulting patterns on the three repositories are interpretable, we acknowledge that no quantitative check against independent social signals is reported. We will add a dedicated validation subsection to the Evaluation section that extracts commit co-occurrence networks from the same GitHub histories and reports Pearson and Spearman correlations between the derived trust-matrix entries and co-commit frequencies. We will also note the absence of external influence labels as a limitation and flag it for future work. These additions will be included in the revised manuscript. revision: yes
Circularity Check
EPO model parameters fitted to same embeddings then used to derive trust matrices and opinion trajectories
specific steps
-
fitted input called prediction
[Abstract (modeling temporal evolution paragraph)]
"We model temporal evolution using the Expressed-Private Opinion (EPO) model to derive trust matrices and track opinion trajectories across development cycles."
The EPO model is parameterized by fitting to the PCA-reduced code embeddings extracted from the identical repository data; the resulting trust matrices and trajectories are therefore direct outputs of that fit rather than independent predictions of software evolution dynamics.
full rationale
The derivation chain encodes code snippets, applies PCA, fits EPO model parameters to those reduced embeddings, and then outputs trust matrices and opinion trajectories as the central results. No external benchmark, parameter-free derivation, or independent validation (e.g., correlation with commit graphs) is supplied, so the derived quantities reduce to the fitting process on the input embeddings.
Axiom & Free-Parameter Ledger
free parameters (1)
- EPO trust-matrix scaling factors
axioms (2)
- domain assumption Semantic code embeddings preserve developer opinion signals that can be interpreted as private and expressed opinions
- domain assumption PCA-reduced embeddings remain comparable across development cycles
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquationwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We employ the EPO model... X(t+1)=diag(W)X(t)+(W-diag(W))X_e(t); X_e(t)=ΦX(t)+(I-Φ)AX_e(t-1)
-
IndisputableMonolith/Foundation/AbsoluteFloorClosureabsolute_floor_iff_bare_distinguishability unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
PCA... reduced the data to a one-dimensional representation
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
code2seq: Generating Sequences from Structured Representations of Code
Alon, U., Brody, S., Levy, O., Yahav, E., 2019. code2seq: Generat- ing sequences from structured representations of code. URL:https: //arxiv.org/abs/1808.01400,arXiv:1808.01400
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[2]
code2vec: Learning Distributed Representations of Code
Alon, U., Zilberstein, M., Levy, O., Yahav, E., 2018. code2vec: Learning distributed representations of code. URL:https://arxiv.org/abs/ 1803.09473,arXiv:1803.09473
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[3]
Github: Factors influencing project activity levels, in: ICEB 2017 Proceedings (Dubai, UAE), p
Alshomali, M.A., Hamilton, J.R., Holdsworth, J., Tee, S., 2017. Github: Factors influencing project activity levels, in: ICEB 2017 Proceedings (Dubai, UAE), p. 14. URL:https://aisel.aisnet.org/iceb2017/ 14/. 18
work page 2017
-
[4]
A Literature Study of Embeddings on Source Code
Chen, Z., Monperrus, M., 2019. A literature study of embed- dings on source code. URL:https://arxiv.org/abs/1904.03061, arXiv:1904.03061
work page internal anchor Pith review Pith/arXiv arXiv 2019
- [5]
-
[6]
URL:https://pages.ucsd.edu/~aronatas/project/academic/ degroot%20consensus.pdf
-
[7]
CodeBERT: A Pre-Trained Model for Programming and Natural Languages
Feng, Z., Guo, D., Tang, D., Duan, N., Feng, X., Gong, M., Shou, L., Qin, B., Liu, T., Jiang, D., Zhou, M., 2020. Codebert: A pre- trained model for programming and natural languages. URL:https: //arxiv.org/abs/2002.08155,arXiv:2002.08155
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[8]
Fischer, G., Lusiardi, J., WolffvonGudenberg, J., 2007. Abstractsyntax trees - and their role in model driven software development, in: Inter- national Conference on Software Engineering Advances (ICSEA 2007), pp. 38–38. doi:10.1109/ICSEA.2007.12
-
[9]
Fluri, B., Wursch, M., Gall, H.C., 2007. Do code and comments co- evolve? on the relation between source code and comment changes, in: 14th Working Conference on Reverse Engineering (WCRE 2007), pp. 70–79. doi:10.1109/WCRE.2007.21
-
[10]
Social influence and opin- ions
Friedkin, N., Johnsen, E., 1990. Social influence and opin- ions. journal of mathematical sociology. Automatica 15(3-4), 193–
work page 1990
-
[11]
URL:https://www.sciencedirect.com/science/article/pii/ S0005109819302870, doi:10.1080/0022250x.1990.9990069
-
[12]
GraphCodeBERT: Pre-training Code Representations with Data Flow
Guo, D., Ren, S., Lu, S., Feng, Z., Tang, D., Liu, S., Zhou, L., Duan, N., Svyatkovskiy, A., Fu, S., Tufano, M., Deng, S.K., Clement, C., Drain, D., Sundaresan, N., Yin, J., Jiang, D., Zhou, M., 2021. Graphcodebert: Pre-trainingcoderepresentationswithdataflow. URL:https://arxiv. org/abs/2009.08366,arXiv:2009.08366
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[13]
Opinion dynamics mod- els for sentiment evolution in weibo blogs
He, Y., Proskurnikov, A.V., Sedakov, A., 2025. Opinion dynamics mod- els for sentiment evolution in weibo blogs. URL:https://arxiv.org/ abs/2511.15303,arXiv:2511.15303
-
[14]
Jurafsky, D., Martin, J., 2008. Speech and Language Processing: An In- troduction to Natural Language Processing, Computational Linguistics, and Speech Recognition. volume 2. 19
work page 2008
-
[15]
Nonlinear dimensionality reduction
Lee, J.A., Verleysen, M., 2007. Nonlinear dimensionality reduction. Springer Science & Business Media
work page 2007
-
[16]
Coir: A comprehensive benchmark for code infor- mation retrieval models
Li, X., Dong, K., Lee, Y.Q., Xia, W., Zhang, H., Dai, X., Wang, Y., Tang, R., 2025. Coir: A comprehensive benchmark for code infor- mation retrieval models. URL:https://arxiv.org/abs/2407.02883, arXiv:2407.02883
-
[17]
Knowledge-oriented models based on developer-artifact and developer- developer interactions
Lucas, E.M., Oliveira, T.C., Schneider, D., Alencar, P.S.C., 2020. Knowledge-oriented models based on developer-artifact and developer- developer interactions. IEEE Access 8, 218702–218719. doi:10.1109/ ACCESS.2020.3042429
-
[18]
88.6 million developer comments from github
Meyers, B.S., Meneely, A., 2021. 88.6 million developer comments from github. URL:https://zenodo.org/doi/10.5281/zenodo.5603093, doi:10.5281/ZENODO.5603093
-
[19]
Namgay, P., Johnson, D., 2024. Towards modelling and simulation of organisational routines, in: Franco, L., de Mulatier, C., Paszynski, M., Krzhizhanovskaya, V.V., Dongarra, J.J., Sloot, P.M.A. (Eds.), Compu- tational Science – ICCS 2024, Springer Nature Switzerland, Cham. pp. 367–379. doi:10.1007/978-3-031-63783-4_27
-
[20]
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A.N., Kaiser, L., Polosukhin, I., 2023. Attention is all you need. URL: https://arxiv.org/abs/1706.03762,arXiv:1706.03762
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[21]
Neighborhood preservation in nonlinear pro- jectionmethods: Anexperimentalstudy
Venna, J., Kaski, S., 2001. Neighborhood preservation in nonlinear pro- jectionmethods: Anexperimentalstudy. doi:10.1007/3-540-44668-0_ 68
-
[22]
Text Embeddings by Weakly-Supervised Contrastive Pre-training
Wang, L., Yang, N., Huang, X., Jiao, B., Yang, L., Jiang, D., Ma- jumder, R., Wei, F., 2024. Text embeddings by weakly-supervised contrastive pre-training. URL:https://arxiv.org/abs/2212.03533, arXiv:2212.03533
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[23]
Ye, M., Qin, Y., Govaert, A., Anderson, B.D., Cao, M.,
-
[24]
An influence network model to study discrepancies in expressed and private opinions. Automatica 107, 371–
-
[25]
URL:https://www.sciencedirect.com/science/article/pii/ S0005109819302870, doi:10.1016/j.automatica.2019.05.059. 20
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.