MALLVI: A Multi-Agent Framework for Integrated Generalized Robotics Manipulation
Pith reviewed 2026-05-15 20:52 UTC · model grok-4.3
The pith
Multi-agent coordination with vision-language feedback enables closed-loop robotic manipulation that raises zero-shot success rates.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
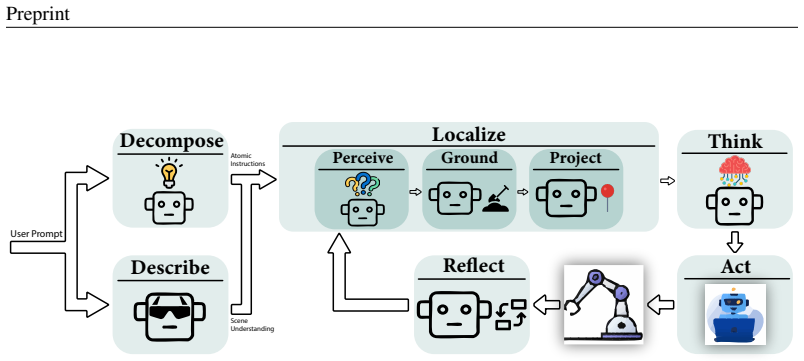
MALLVI coordinates four core agents—Decomposer, Localizer, Thinker, and Reflector—plus an optional Descriptor for visual memory, to turn natural-language instructions and an initial image into executable robot actions. After each action, a vision-language model evaluates the resulting scene and directs the system to repeat relevant steps or proceed. The Reflector enables targeted recovery by reactivating only the agents needed for the detected error, avoiding full replanning. Experiments in both simulation and physical robots demonstrate improved generalization and higher success rates on zero-shot manipulation tasks compared with prior open-loop methods.
What carries the argument
Coordination of specialized agents (Decomposer, Localizer, Thinker, Reflector) with closed-loop vision-language evaluation that supports selective error recovery instead of full replanning.
If this is right
- Higher task completion rates on unseen manipulation instructions in both simulated and physical environments.
- More efficient recovery from partial failures by reactivating only the affected agents rather than restarting the entire plan.
- Improved robustness to environmental changes because feedback occurs after every atomic action.
- Better generalization to new object arrangements and language phrasing without retraining any model.
Where Pith is reading between the lines
- The modular agent design could be extended by inserting new specialized agents for additional skills such as force control or multi-object sequencing.
- Performance gains may depend on pairing the framework with stronger future vision-language models that reduce evaluation mistakes.
- The approach suggests a template for other embodied tasks where language instructions must be grounded in real-time visual feedback.
- Selective reactivation of agents might lower overall compute cost compared with regenerating full plans after every error.
Load-bearing premise
The vision-language model evaluates action outcomes accurately enough to decide repetition or progression without systematic errors in changing real-world scenes.
What would settle it
A controlled trial in which the vision-language model supplies incorrect success/failure judgments on a majority of executed actions, producing no net gain in task completion over a comparable open-loop baseline.
Figures












read the original abstract
Task planning for robotic manipulation with large language models (LLMs) is an emerging area. Prior approaches rely on specialized models, fine tuning, or prompt tuning, and often operate in an open loop manner without robust environmental feedback, making them fragile in dynamic settings. MALLVI presents a Multi Agent Large Language and Vision framework that enables closed-loop feedback driven robotic manipulation. Given a natural language instruction and an image of the environment, MALLVI generates executable atomic actions for a robot manipulator. After action execution, a Vision Language Model (VLM) evaluates environmental feedback and decides whether to repeat the process or proceed to the next step. Rather than using a single model, MALLVI coordinates specialized agents, Decomposer, Localizer, Thinker, and Reflector, to manage perception, localization, reasoning, and high level planning. An optional Descriptor agent provides visual memory of the initial state. The Reflector supports targeted error detection and recovery by reactivating only relevant agents, avoiding full replanning. Experiments in simulation and real-world settings show that iterative closed loop multi agent coordination improves generalization and increases success rates in zero shot manipulation tasks. Code available at https://github.com/iman1234ahmadi/MALLVI .
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents MALLVI, a multi-agent framework combining LLMs and VLMs for closed-loop robotic manipulation. Specialized agents (Decomposer, Localizer, Thinker, Reflector, and optional Descriptor) handle perception, localization, reasoning, and post-action feedback evaluation to generate atomic actions from natural language instructions and images, with the Reflector enabling targeted error recovery by reactivating relevant agents. The central claim is that this iterative coordination improves generalization and raises success rates in zero-shot manipulation tasks, supported by experiments in simulation and real-world settings, with public code released.
Significance. If the empirical claims are substantiated with quantitative validation, the work could advance zero-shot robotic manipulation by showing how structured multi-agent coordination with VLM feedback enables robust closed-loop behavior without fine-tuning or open-loop fragility. Public code availability supports reproducibility and is a clear strength.
major comments (3)
- [Experiments] Experiments section: the abstract and text assert that iterative closed-loop multi-agent coordination increases success rates in zero-shot tasks, yet no quantitative metrics, baselines, error bars, task definitions, success-rate tables, or statistical comparisons are supplied anywhere in the manuscript, rendering the central empirical claim unverifiable from the provided text.
- [Reflector agent] Reflector agent (Section 3.4 and related): the VLM-based outcome evaluation that decides repeat/proceed receives no validation metrics (precision, recall, inter-rater agreement with human labels), no ablation removing the Reflector, and no analysis of failure modes in dynamic scenes; without these, performance gains cannot be attributed to the claimed multi-agent mechanism rather than VLM idiosyncrasies.
- [Framework description] Framework description (Section 3): coordination protocols, exact prompt templates, decision thresholds for the Reflector, and how the optional Descriptor integrates visual memory are described at a high level only, leaving the reproducibility of the closed-loop loop unclear and the novelty relative to prior LLM/VLM planners difficult to assess.
minor comments (2)
- [Abstract] Abstract: the phrase 'increases success rates' is stated without any magnitude, comparison baseline, or reference to specific figures/tables.
- [Figures] Notation and figures: agent interaction diagrams and flowcharts would benefit from clearer labeling of data flows between Decomposer, Thinker, and Reflector to aid reader comprehension.
Simulated Author's Rebuttal
We thank the referee for their detailed and constructive feedback on our manuscript. We appreciate the opportunity to clarify and strengthen the presentation of our work. Below, we provide point-by-point responses to the major comments and outline the revisions we will make.
read point-by-point responses
-
Referee: [Experiments] Experiments section: the abstract and text assert that iterative closed-loop multi-agent coordination increases success rates in zero-shot tasks, yet no quantitative metrics, baselines, error bars, task definitions, success-rate tables, or statistical comparisons are supplied anywhere in the manuscript, rendering the central empirical claim unverifiable from the provided text.
Authors: We agree that the manuscript as presented does not include sufficient quantitative details in the text to fully substantiate the empirical claims. Although experiments were performed in both simulation and real-world settings, the results were summarized qualitatively. In the revised manuscript, we will add comprehensive success-rate tables, comparisons against baselines such as single-agent LLM planners and open-loop methods, error bars from multiple trials, precise task definitions, and statistical significance tests. This will allow readers to verify the improvements from the multi-agent closed-loop approach. revision: yes
-
Referee: [Reflector agent] Reflector agent (Section 3.4 and related): the VLM-based outcome evaluation that decides repeat/proceed receives no validation metrics (precision, recall, inter-rater agreement with human labels), no ablation removing the Reflector, and no analysis of failure modes in dynamic scenes; without these, performance gains cannot be attributed to the claimed multi-agent mechanism rather than VLM idiosyncrasies.
Authors: We acknowledge the importance of validating the Reflector's performance. We will include metrics such as precision and recall for the Reflector's decisions compared to human annotations, an ablation study that removes the Reflector to quantify its contribution, and a discussion of failure modes observed in dynamic scenes. These additions will help attribute the performance gains specifically to the multi-agent coordination. revision: yes
-
Referee: [Framework description] Framework description (Section 3): coordination protocols, exact prompt templates, decision thresholds for the Reflector, and how the optional Descriptor integrates visual memory are described at a high level only, leaving the reproducibility of the closed-loop loop unclear and the novelty relative to prior LLM/VLM planners difficult to assess.
Authors: We will revise Section 3 to provide more detailed descriptions, including the exact coordination protocols between agents, full prompt templates used for each agent (Decomposer, Localizer, Thinker, Reflector, Descriptor), specific decision thresholds for the Reflector (e.g., confidence scores or criteria for repeat/proceed), and a clearer explanation of how the Descriptor maintains and integrates visual memory. This will enhance reproducibility and better highlight the novelty of our structured multi-agent framework compared to prior work. revision: yes
Circularity Check
No circularity: empirical framework with no derivation chain
full rationale
The paper presents a multi-agent LLM/VLM framework for closed-loop robotic manipulation as an empirical design choice, supported by simulation and real-world experiments plus public code. No equations, first-principles derivations, or predictions appear in the manuscript. Claims of improved zero-shot success rates rest on experimental outcomes rather than any reduction to fitted inputs, self-definitions, or self-citation chains. The Reflector agent's role is described as a coordination mechanism validated externally, with no load-bearing ansatz or uniqueness theorem imported from prior author work. This is a standard systems paper whose central claims remain independent of the inputs.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
MALLVi coordinates specialized agents (Decomposer, Localizer, Thinker, Reflector) ... Reflector evaluates environmental feedback and decides whether to repeat or proceed
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
iterative closed-loop multi-agent coordination improves generalization and increases success rates
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
URLhttps://openreview.net/forum?id=Glcsog6zOe. Wenlong Huang, Fei Xia, Ted Xiao, Harris Chan, Jacky Liang, Pete Florence, Andy Zeng, Jonathan Tompson, Igor Mordatch, Yevgen Chebotar, Pierre Sermanet, Tomas Jackson, Noah Brown, Linda Luu, Sergey Levine, Karol Hausman, and brian ichter. Inner monologue: Embodied reasoning through planning with language mode...
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[2]
Yuheng Huang, Jiayang Song, Zhijie Wang, Shengming Zhao, Huaming Chen, Felix Juefei-Xu, and Lei Ma
URLhttps://api.semanticscholar.org/CorpusID:272367253. Yuheng Huang, Jiayang Song, Zhijie Wang, Shengming Zhao, Huaming Chen, Felix Juefei-Xu, and Lei Ma. Look before you leap: An exploratory study of uncertainty analysis for large language models.IEEE Transactions on Software Engineering, 51(2):413–429, February 2025. ISSN 2326-3881. doi: 10.1109/tse.202...
-
[3]
doi: 10.1109/LRA.2024.3471457. Matthias Minderer, Alexey A. Gritsenko, Austin Stone, Maxim Neumann, Dirk Weissenborn, Alexey Dosovitskiy, Aravindh Mahendran, Anurag Arnab, Mostafa Dehghani, Zhuoran Shen, Xiao Wang, Xiaohua Zhai, Thomas Kipf, and Neil Houlsby. Simple open-vocabulary object detection with vision transformers.ArXiv, abs/2205.06230, 2022. Sor...
-
[4]
Ignore Examples or Descriptions • The input may include example sentences or object descriptions at the start (like "This is a red block"). • Ignore everything before the first command verb (pick, place, move, put, etc.). • If there are no commands, return an empty list []. • O
-
[5]
• For novel tasks (novel_noun, novel_adj, novel_adj_and_noun), use only the name, ignore color
Objects • Objects are written as name (color) in the text, e.g., block (red), cube (blue). • For novel tasks (novel_noun, novel_adj, novel_adj_and_noun), use only the name, ignore color. Example: square • For all other tasks, include color in output: red block, blue cube. •
-
[6]
Atomic Actions Use only these formats:
-
[7]
move(<object>object</object>, <object>target</object>, <rotation>0</rotation>)
-
[8]
move(<object>object</object>, <memory>previous location</memory>, <rotation>0</rotation>)
-
[9]
move(<memory>previous neighbor</memory>, <object>target</object>, <rotation>0</rotation>)
-
[10]
move(<object>object</object>, <memory>previous [relationship]</memory>, <rotation>0</rotation>)
-
[11]
move(<memory>previous [relationship]</memory>, <object>target</object>, <rotation>0</rotation>) Rotation: • 0 = no rotation • Positive = clockwise • Negative = counterclockwise •
-
[12]
Memory Rules • <memory>previous location</memory> → return to previous position • <memory>previous neighbor</memory> → move relative to old neighbor • <memory>previous [relationship]</memory> → move relative to previous spatial relation (north, south, left, right, above, below, etc.) Use memory for object or target depending on context
-
[13]
Pick up the block (red) and place it on the table
Output • Return a Python list of strings. • Each string = one atomic move. • No explanations, no extra text. Figure 8: Decomposer prompt 24 Preprint Examples Standard Task: Input: "Pick up the block (red) and place it on the table" Output: ["move(<object>red block</object>, <object>table</object>, <rotation>0</rotation>)"] Input: "Rotate the cube (blue) b...
-
[14]
- Use descriptor_grasp_points_3d and scene_description to find memory objects
Memory detection: - If current_prompt has memory terms (previous, old, neighbor, <memory>...</memory>), source or destination may be memory-based (null). - Use descriptor_grasp_points_3d and scene_description to find memory objects
-
[15]
- Pick object_of_interest, place on not_object_of_interest
No memory: - If current_prompt has no memory terms, use grasp_points_3d only. - Pick object_of_interest, place on not_object_of_interest
-
[16]
Move instruction: - Format: move(source, destination, rotation) - First object = pick object, second = place object - Rotation is always included
-
[17]
Pick & place positions: - Use grasp_points_3d for current objects - Use descriptor_grasp_points_3d for memory objects - Place positions should be on top of destination object (Z adjusted)
-
[18]
Rotation: - Use 0 if none specified - If prompt mentions rotation, extract value
- [19]
- [20]
- [21]
-
[22]
Memory-based operation: { "decision": "SUCCESS", "chosen_grasp_points": [[[2.0, 3.0, 0.5], [1.5, 2.5, 0.7]]], "reasoning": "Source or destination is memory-based. Used scene description and descriptor grasp points.", "rotation_degrees": [0.0] } Figure 12: Thinker prompt 28 Preprint /gid00051/gid00068/gid00198/gid00068/gid00066/gid00083/gid00078/gid00081/g...
-
[23]
Original Task Instruction
-
[24]
Actor’s Execution Report
-
[25]
Image of the current environment Goal: Determine if the task was completed and output JSON only. Output JSON Format { "task_complete": true/false, "verification_result": "Explanation of decision", "confidence": 0.0-1.0 } Verification Rules • Inspect the image to see if the task was done. • Check the actor’s report for success/failure. • Compare the image ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.